







背景
在进行机器学习的任务中,我们的训练数据往往是有限的,在有限的数据集上获得较好的模型训练结果,我们不仅要在模型结构上下功夫,另一方面也需要对数据集进行数据增强
图片数据增强
图像数据增强是一种在训练机器学习和深度学习模型时常用的策略,尤其是在计算机视觉领域。具体而言,它通过创建和原始图像稍有不同的新图像来扩大训练集。 数据增强的主要目标有以下几点:
- 解决过拟合:过拟合是指模型在训练集上表现得过于优秀,但是在测试集(即未见过的新数据)上表现差的现象。一个常见的解决过拟合的策略是增加训练数据。数据增强通过在原有训练数据的基础上增加各种变化的数据,有效地增大了训练集。
- 提高模型的泛化能力:一些数据增强手段(如旋转、缩放、平移等)可以模拟一些真实场景中会产生的视觉变化,有助于训练模型对这些场景变化更具有鲁棒性,从而提高模型的泛化能力。
- 引入可控制的噪声:一些数据增强方法,如随机裁剪、像素值噪声、颜色偏移等,可以在一定程度上模拟真实环境中的噪声。以这样的方式引入的噪声可以使模型更健壮,并且增强模型的噪声容忍力。
- 视觉不变性:通过像翻转、旋转这样的变换,数据增强可以帮助模型在任何视觉角度下都能正确地识别出相同的对象,输入图像进行各种方式的扭曲后仍能被模型准确识别出来,增强了模型的视觉不变性。 总的来说,图片数据增强可以让模型学习到更多样性的数据,可以在一定程度上提升模型的识别准确率,更好的适应实际环境中样本的多样性,从而提高模型的泛化能力。
代码实现
我们使用torchvision的transforms库对图片数据进行数据增强,使用一张卡比巴拉的图片

首先读取图片数据,以下是准备工作
from PIL import Image
import numpy as np
import torchvision.transforms as tfs
import matplotlib.pyplot as plt
img_path = r"D:\CSDN_point\1_4\kabibala.jpg"
img = Image.open(img_path)
print("the shape of img is {}".format(np.array(img).shape))图片伸缩
img_re = tfs.Resize((500,1000))(img)
plt.imshow(img_re)
plt.show()tfs.Reszie((500,1000))把图像的高和宽分别拉伸到500像素和1000像素

图片裁剪
img_crop = tfs.RandomCrop(500)(img)
plt.imshow(img_crop)
plt.show()tfs.RandomCrop(500)随机截取图片大小的区域

中心裁剪
img_crop_cen = tfs.CenterCrop(700)(img)
plt.imshow(img_crop_cen)
plt.show()tfs.CenterCrop(700)裁剪图片中心位置大小的区域

随机水平翻转
# 随机水平翻转,概率是0.5
img_hori = tfs.RandomHorizontalFlip()(img)
# 随机垂直翻转,概率是0.5
img_ver = tfs.RandomVerticalFlip()(img)
plt.subplot(1,2,1)
plt.imshow(img_hori)
plt.title("RandomHorizontalFlip")
plt.subplot(1,2,2)
plt.imshow(img_ver)
plt.title("RandomVerticalFlip")
plt.show()
随机改变图片亮度、对比度和色相
img_j = tfs.ColorJitter(brightness=0.5,contrast=0.5,hue=0.5)(img)
plt.imshow(img_j)
plt.show()tfs.ColorJitter(brightness=0.5,contrast=0.5,hue=0.5)中参数的含义:
-
brightness=0.5:亮度的浮点数系数,brightness系数在 [max(0, 1 - brightness), 1 + brightness] 的范围内随机选择。例如,brightness=0.5,就表明亮度在 [0.5, 1.5] 的范围内随机选择。 -
contrast=0.5:对比度的浮点数系数。对比度系数在 [max(0, 1 - contrast), 1 + contrast] 的范围内随机选择。例如,contrast=0.5,就表明对比度在 [0.5, 1.5] 的范围内随机选择。 -
hue=0.5:色相的浮点数系数。色相系数在 [-hue, hue] 的范围内随机选择。例如,hue=0.5,就表明色相在 [-0.5, 0.5] 的范围内随机选择。

多变换整合
可以使用Compose模块将多个变换进行整合
# 将多个变换整合到my_trans
my_trans = tfs.Compose([tfs.Resize(800),tfs.RandomHorizontalFlip(),tfs.RandomCrop(500),tfs.RandomVerticalFlip(),tfs.ColorJitter(brightness=0.5,contrast=0.5,hue=0.5)])
_,fig = plt.subplots(3,3)
for i in range(3):
for j in range(3):
fig[i][j].imshow(my_trans(img))
plt.axis('off')
plt.show()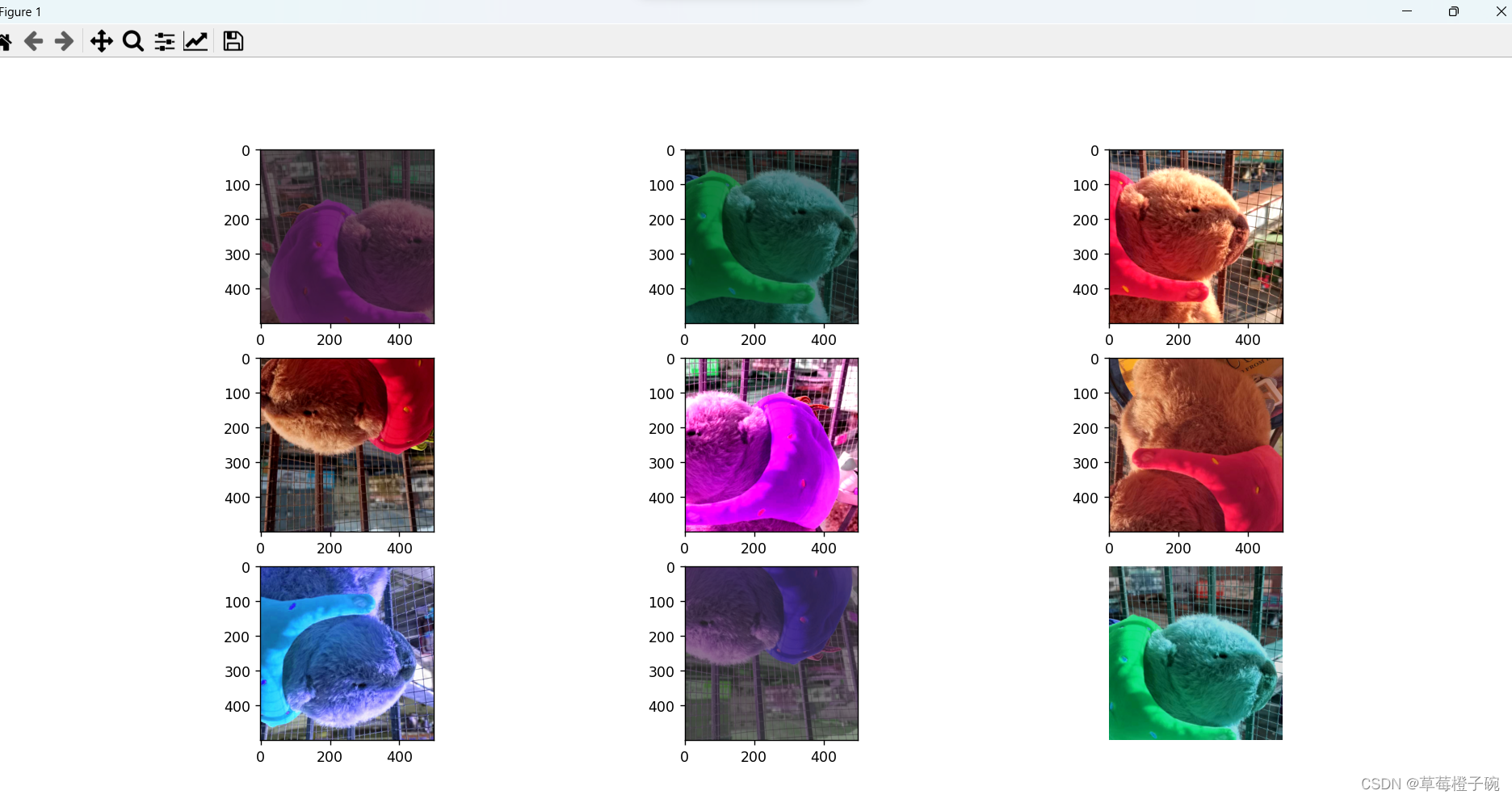
欢迎大家讨论交流~














 1840
1840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









