






2023年就快结束了,在这一年,对代码进行漏洞扫描,不仅可以利用传统的静态分析工具,还可以使用基于深度学习的AI分析技术,更重要的是我们拥有了大语言模型(LLM)加成的代码分析技术。程序员在这个时代确实很幸运,不过我们不禁要问,有没有什么严谨的评估来测试一下这些技术的高下?

首先我们要看看VulBench的一些细节,这个数据集包括了四个此前(2019年-2021年)研究工作所维护的数据集,
-
MAGMA 数据集
-
Ahmad Hazimeh, Adrian Herrera, and Mathias Payer. Magma: A Ground-Truth Fuzzing Benchmark. Proceedings of the ACM on Measurement and Analysis of Computing Systems, 4(3):1–29, November 2020. ISSN 2476-1249. doi: 10.1145/3428334
-
-
D2A 数据集
-
Yunhui Zheng, Saurabh Pujar, Burn Lewis, Luca Buratti, Edward Epstein, Bo Yang, Jim Laredo, Alessandro Morari, and Zhong Su. D2a: A dataset built for ai-based vulnerability detection methods using differential analysis. In Proceedings of the 43rd International Conference on Software Engineering: Software Engineering in Practice, ICSE-SEIP ’21, pp. 111–120. IEEE Press, 2021. ISBN 9780738146690. doi: 10.1109/ICSE-SEIP52600.2021.00020. URL https://doi.org/10.1109/ICSE-SEIP52600.2021.00020
-
-
Devign 数据集
-
Yaqin Zhou, Shangqing Liu, Jingkai Siow, Xiaoning Du, and Yang Liu. Devign: Effective Vulnerability Identification by Learning Comprehensive Program Semantics via Graph Neural Networks. Curran Associates Inc., Red Hook, NY, USA, 2019.
-
-
Big-Vul 数据集
-
Jiahao Fan, Yi Li, Shaohua Wang, and Tien N. Nguyen. A C/C++ Code Vulnerability Dataset with Code Changes and CVE Summaries. In Proceedings of the 17th International Conference on Mining Software Repositories, pp. 508–512, Seoul Republic of Korea, June 2020. ACM. ISBN 978-1-4503-7517-7. doi: 10.1145/3379597.3387501
-
除此之外,作者还从在线CTF平台BUUCTF(https://buuoj.cn/ 访问这里)上搜集了108道pwn题目,加入到了VulBench数据集中,同时考虑到LLM的使用,作者还反编译了那些没有提供源码的题目的二进制代码,并手工整理和修复了反编译代码。举个例子,下面这个函数代码是从一道题目反编译得到的,除了函数本身的代码,还加入了一些用到的全局变量以及对应的结构体信息(struct Note):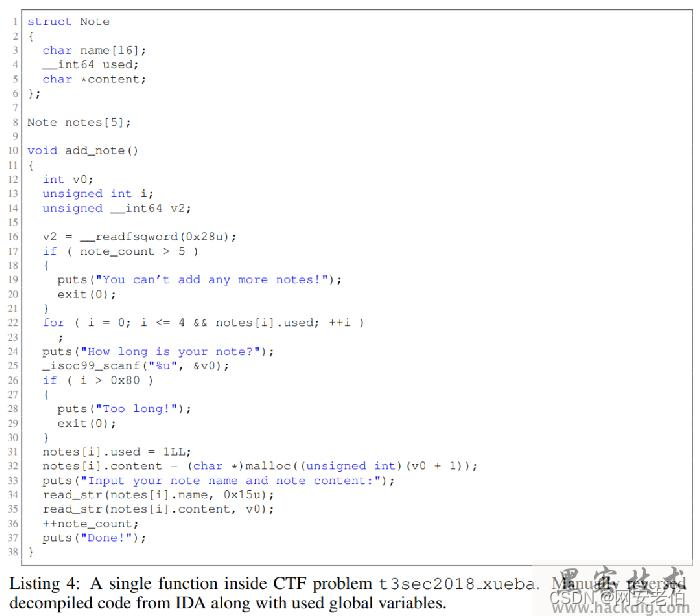
除了有漏洞的代码本身,每个测试用例都配上了用自然语言撰写的标注(下面是一个示例),这样:
最后整个VulBench数据集的构成如下表所示: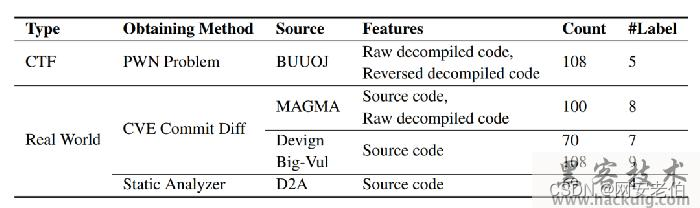
在VulBench数据集中,包含的不同的漏洞类型具体包括: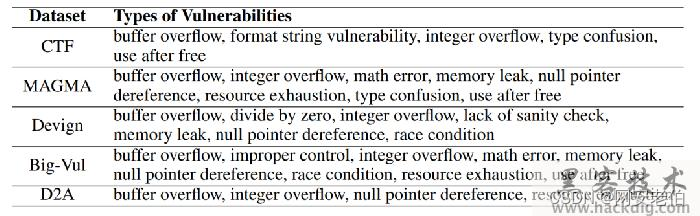
接下来是作者选择的LLM,以及作者在这里赤裸裸地炫耀“We host the models on 48 A800 GPUs across 6 nodes”,嗯~
为了统一整个测试流程,作者也设计了一套“调教”LLM的规范,让被测试的LLM输出格式一致的结果。下面的内容就是让LLM做判断题(binary classification)和多选题(multi-class classification)时分别的提示:

让我们来看看测试结果(下面两幅图分别是针对数据集里面CTF类型的漏洞用例和真实世界代码漏洞用例的结果),在针对比较简单的CTF类型的漏洞时,又是商业大模型赢了~ 而且只要给CTF赛题的反编译结果进行一定的注释后,GPT4能够更好地判断漏洞,这是不是也说明了CTF题目是可以“背答案”解决的,而赛棍们你们的最大对手也许以后就是LLM了!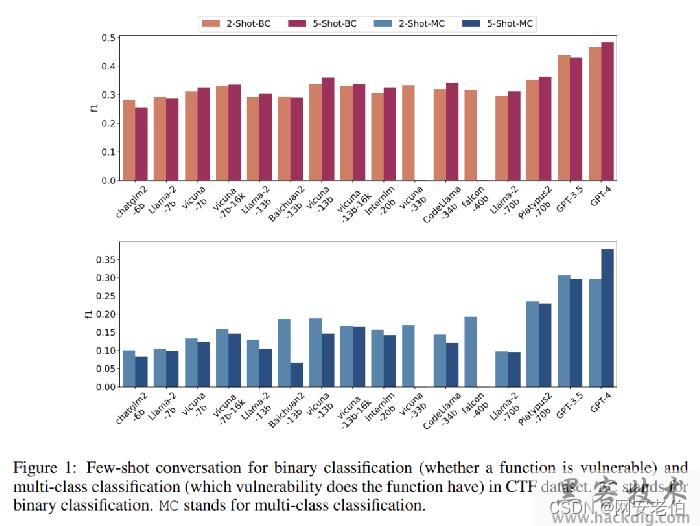
然而到了真实世界的漏洞代码测试中,LLM表现就没那么理想了,因为这时候往往涉及到复杂的上下文,而大部分的LLM目前还不太容易“投喂”进去相关的上下文信息(这一点上静态代码分析工具就有明显的优势)。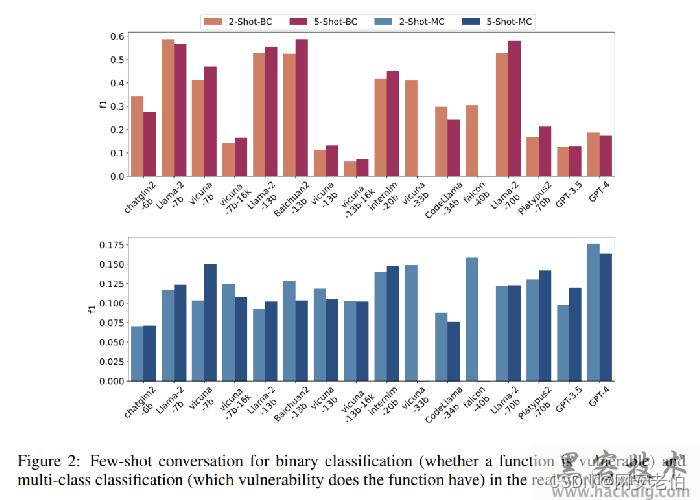
如果你也想学习黑客技术?
可以看一下我自己录制的190节网络攻防教程,只要你用心学习,即使是零基础也能成为高手,需要的话我可以无偿芬享,能不能学会就看你自己了。


















 114
114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









