







查询
全列查询
指定列查询
查询字段并添加自定义表达式
自定义表达式重命名
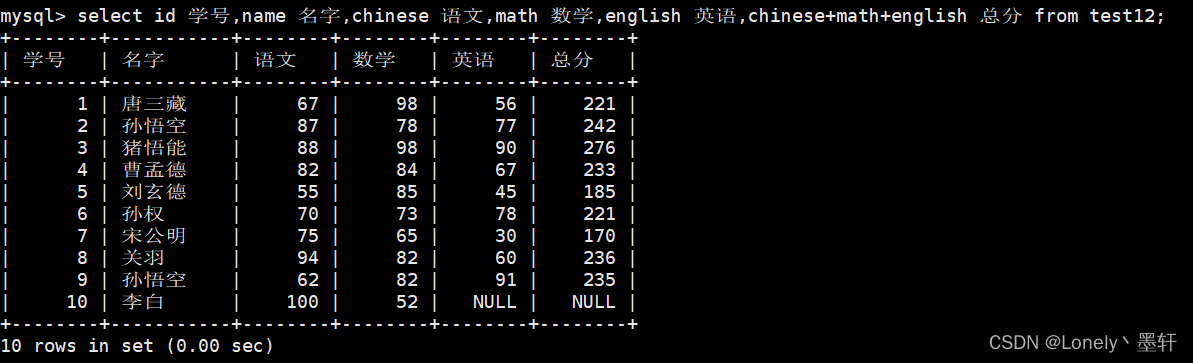
查询指定列并去重
select distinct 列名 from 表名

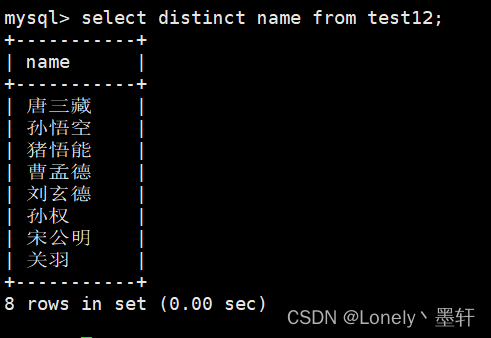
where条件
查询列数据为null的 null与' '(空串)是不同的!
附:一般null不参与查询。
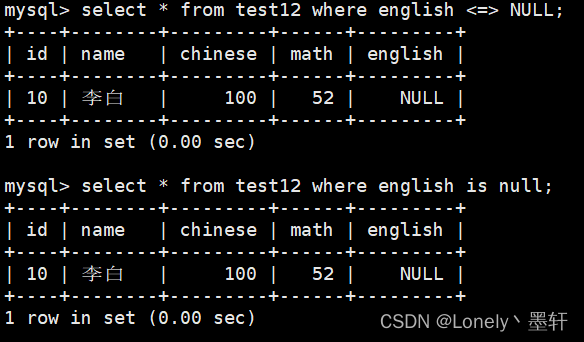
查询列数据不为null的

查询某列数据指定范围
select * from 表名 where 列名 between 起点 and 末尾;
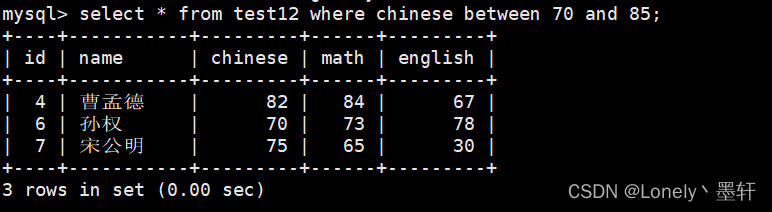
若未指定,其他不满足的数据也会显示,因为本身命令没要求他们不显示,其次也没要求他们不显示。
查询某列数据指定范围并且指定显示
select 列名... from 表名 where 列名 between 起点 and 末尾
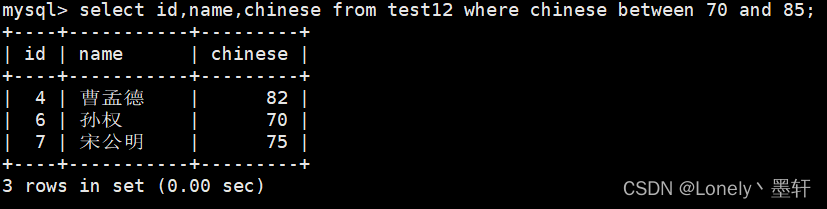
select 列名... from 表名 where 列名>范围 and 列名<范围
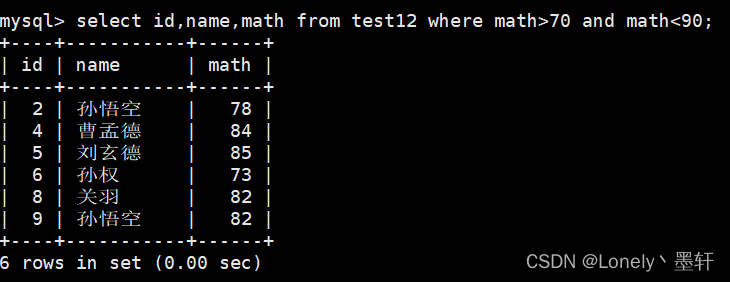
select 列名... from 表名 where 列命 in(指定范围)

查找列指定数据

模糊匹配
查找第一个为孙的
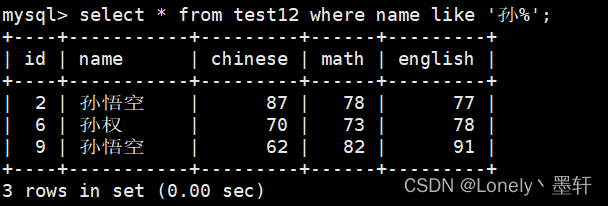
查找以孙开头两个字的
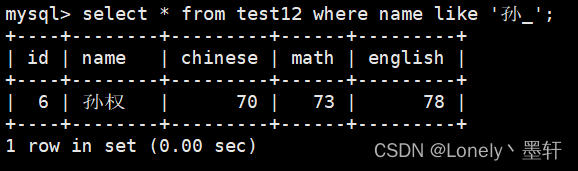
查找以孙开头三个字的
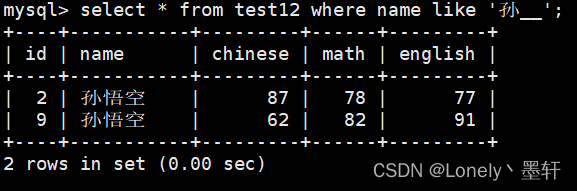
查找不以孙字开头的

查找两个列比较大小的
查找语文>数学
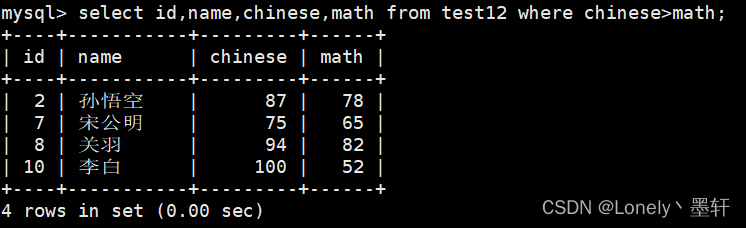
查找语文大于80并且name不以孙字开头的
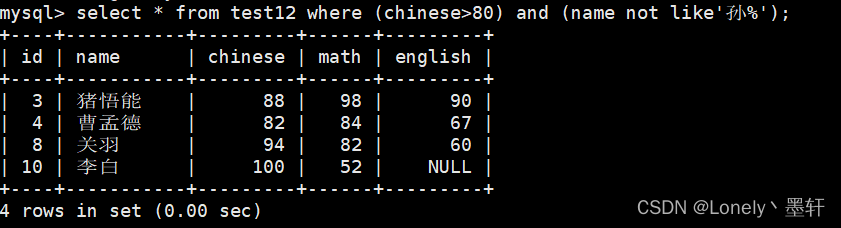
查找总分>200的

为什么这里用别名会报错?
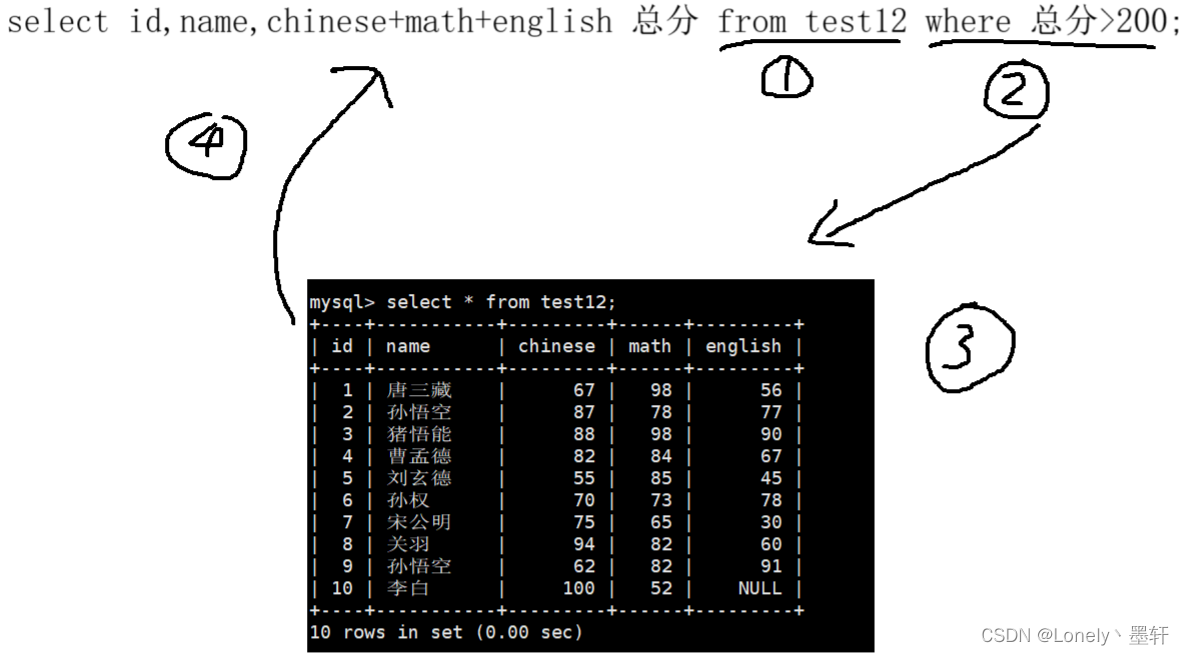
可以看到select的执行顺序,先找到表,其次是条件,再去表里查找,而条件是 ’总分' 但并没用这个条件,因为总分是在第四次才开始重命名的,所以报错了。
正确做法
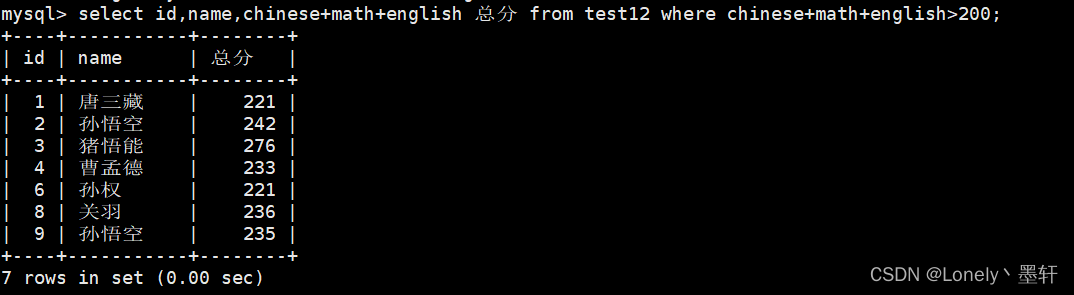
结果排序
升序 ascending order 简asc
降序 descending order 简desc
查询chinese的升序
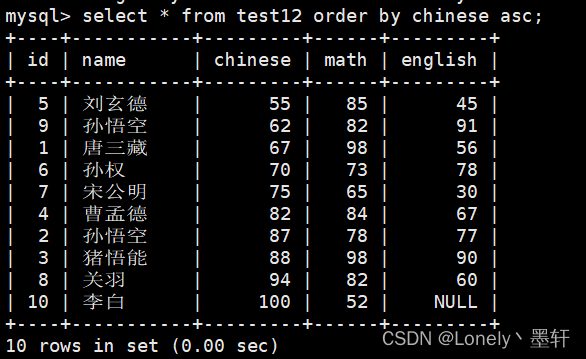
查询chinese的降序
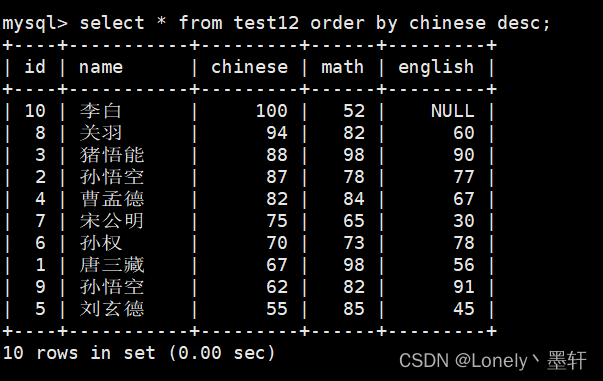
查询以数学降序,英语升序,语文升序的方式显示
以数学为key先排 如果数学数据相同,以英语来排,如果英语数据也相同,以语文来排。
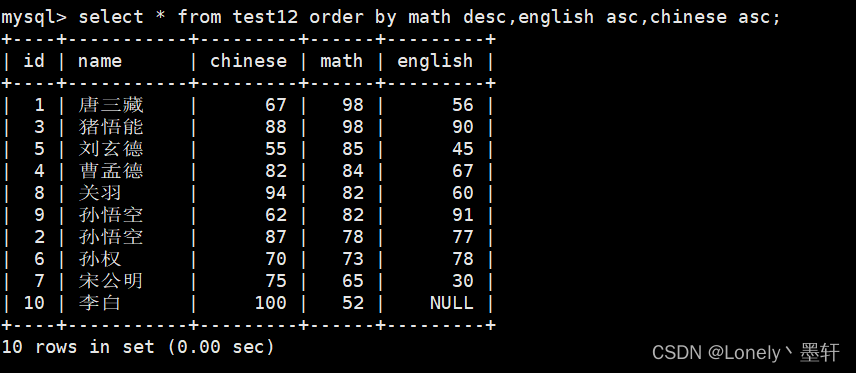
附:NULL默认为最小
查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示

以总分排降序
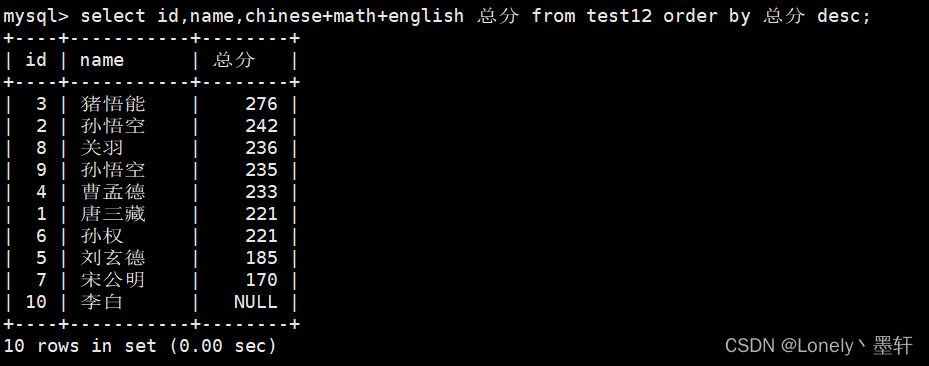
为什么这里用别名可以,而where不行?这也跟select执行顺序有关
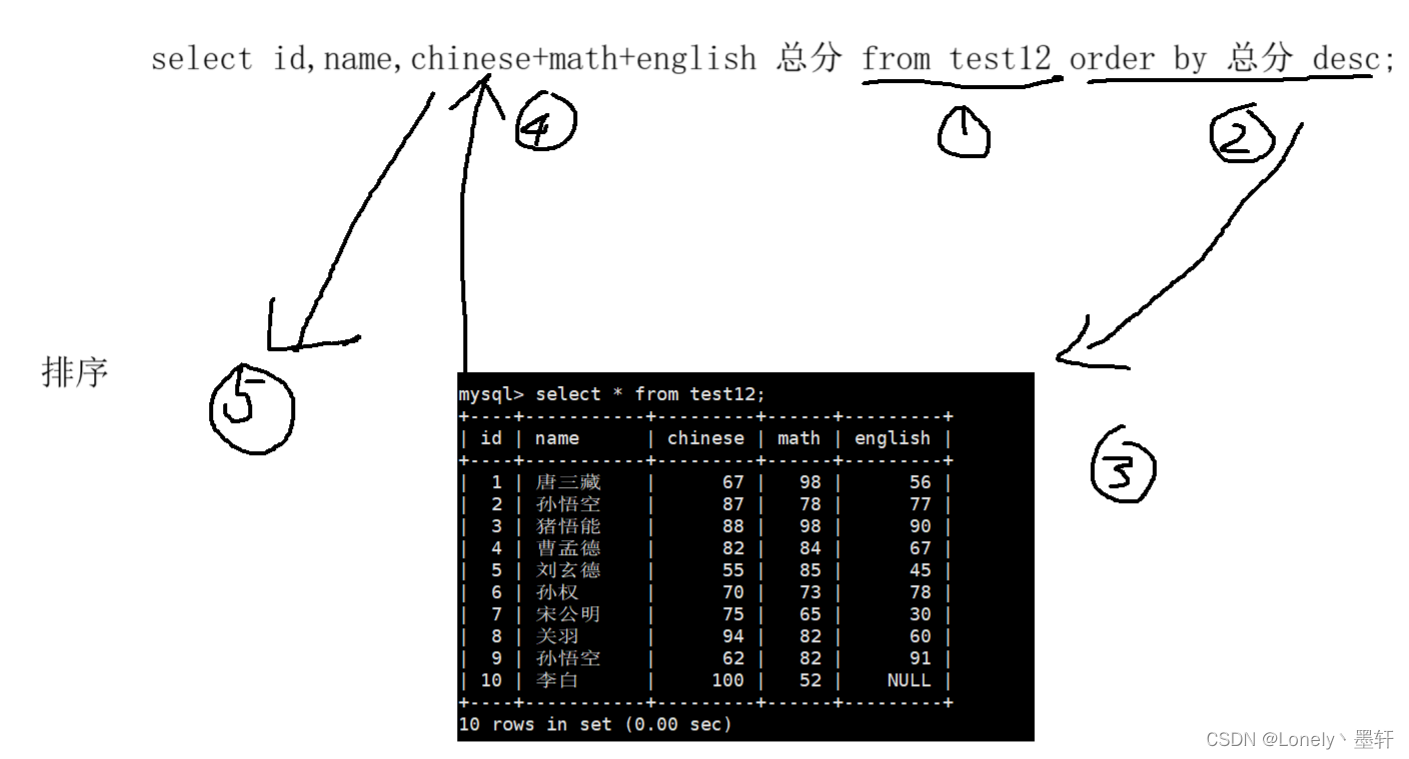
因为排序是最后才执行的,所以第二步时其实并没用用到 ‘总分' ,执行排序时,排序是第五梯队,而重命名是第四梯队,所以排序时总分已经重命名了,即可以使用,不会报错。
查询总分降序并且只显示前三个。
limit 3 取得结果后的前三行
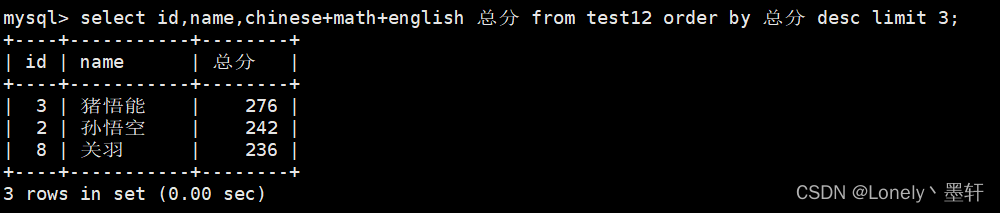
limit s,n 取第s个到n个

更新
update 表名 set 修改的数据 where 条件
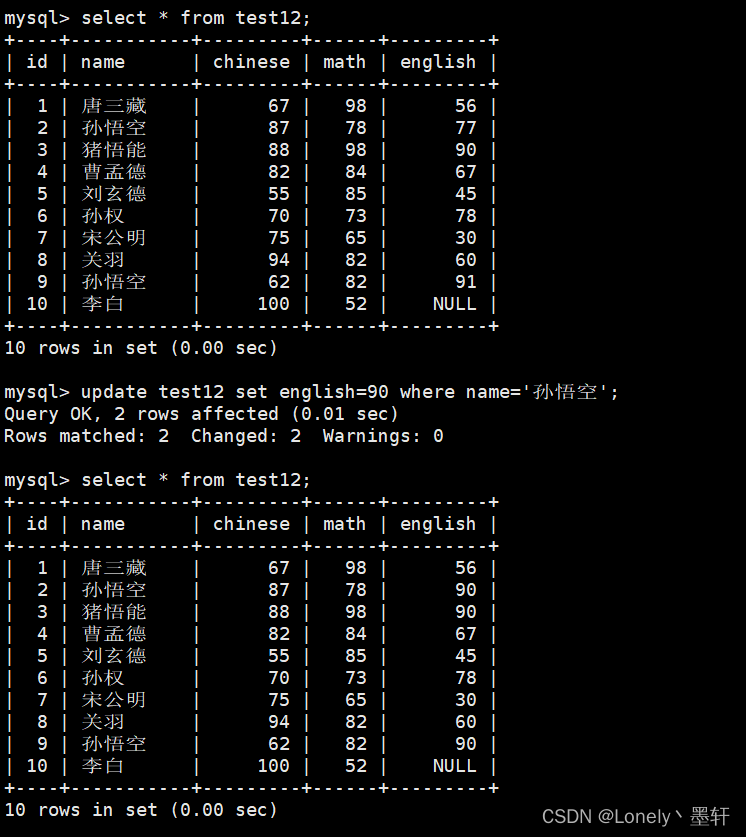
将孙悟空的英语修改为90
update test12 set chinese=80; 谨慎使用!
将数据内chinese所有数据都修改为80
将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
update 表名 set 条件 order by 排序的分数 desc limit n(要修改的n行)
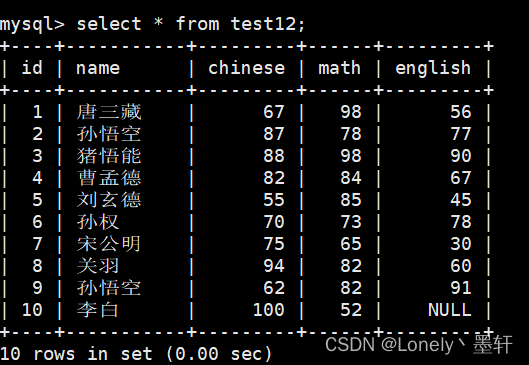
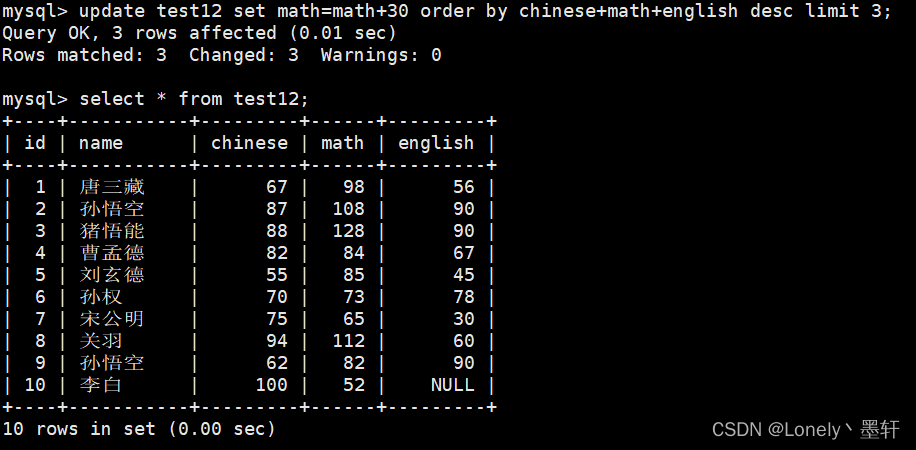
附:math+=30 这种在mysql是不能用的。
删除
delete from 表名 where 条件
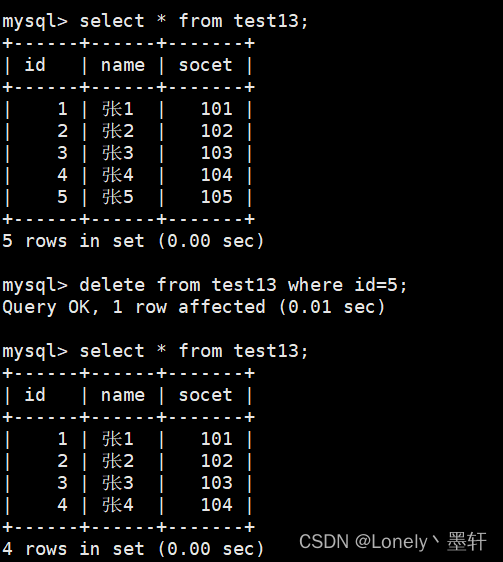
delete from 表名 order by 总分 limit n(要删除n行)
delete from 表名 truncate 表名
都是清空表数据 delete不会重置auto_increment(自增长) truncate会重置auto_increment(自增长)
truncate不能回滚。truncate只能做清空表数据操作
聚合函数
count()返回查询到的数据的数量
统计name有几个
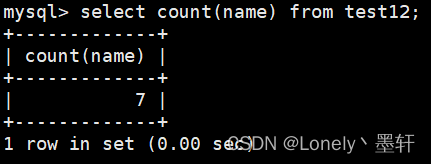
统计name有几个并去重
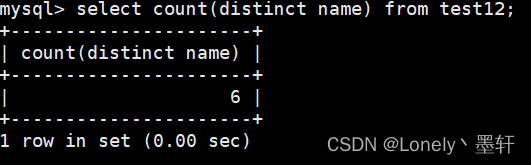
统计英语成绩大于60分的有几个
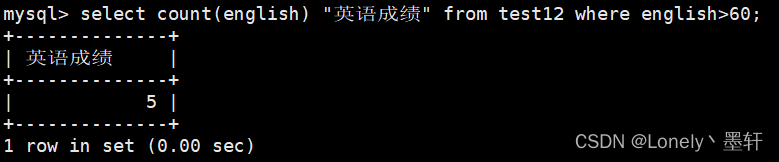
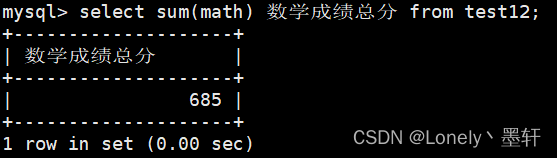
sum()返回查询到的数据的总和(对列方向的计算)
计算数学成绩的总和
计算数学成绩小于90分的总和
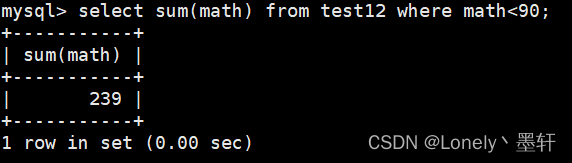
avg()返回查询到的数据平均值
计算英语的平均分
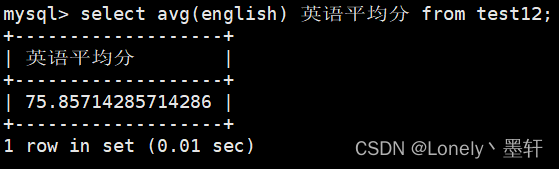
计算总分的平均分
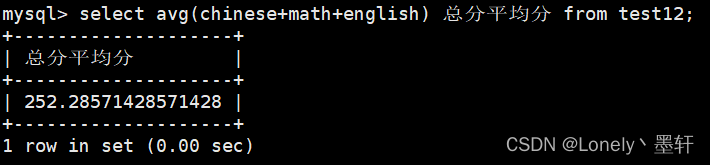
计算英语大于60分的平均分
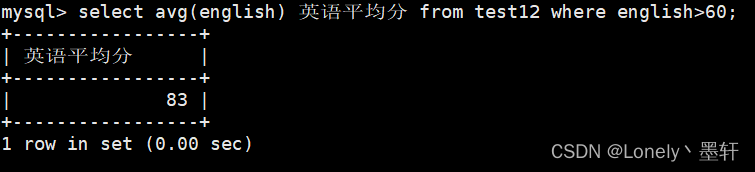
max()返回查询到的数据的最大值
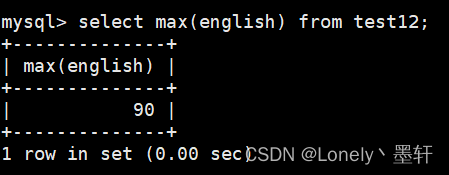
计算英语的最大值
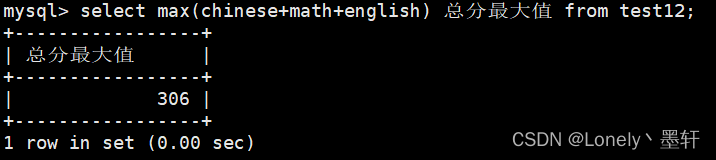
计算总分的最大值
min()返回查询到的数据的最小值
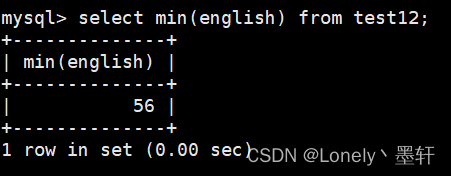
计算英语的最小值
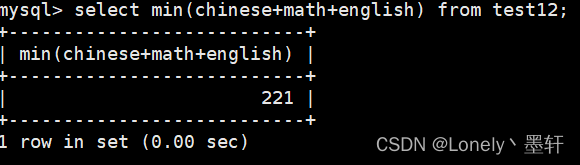
计算总分的最小值
group by
在select中使用group by子句可以对指定列进行分组查询
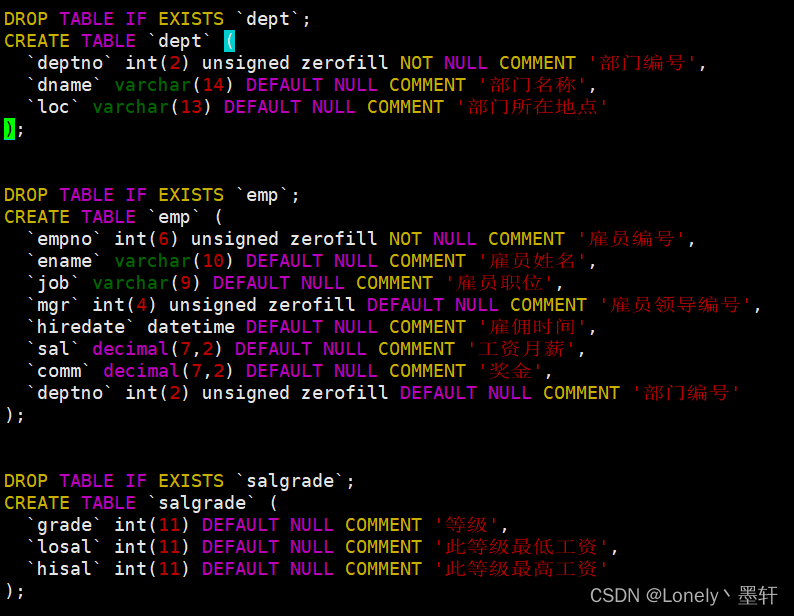
对部门编号进行分组,再进行计算平均值,和最大值。
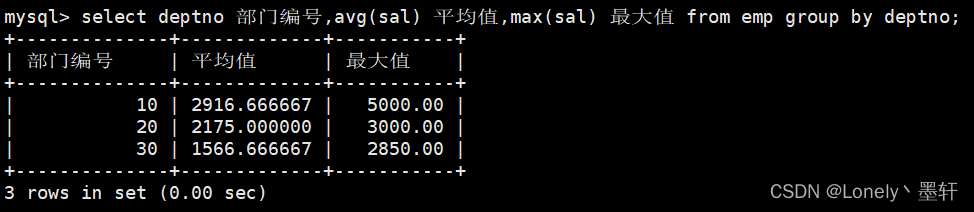
附:group by可以分多个组
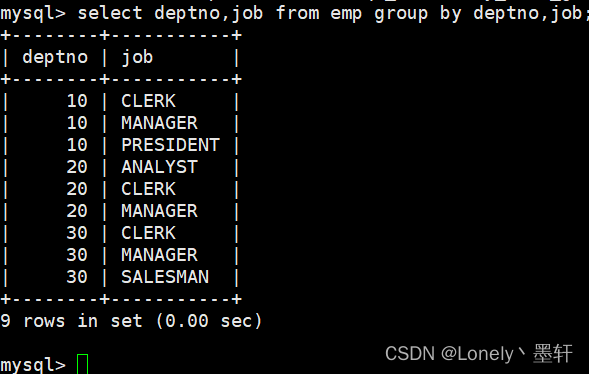

为什么会报错?
ename未进行分组,group没有进行分钟的列,无法在select显示
where avg(sal)
报错,where本质是以条件来筛数据的。而avg是聚合函数,它要有数据后才能工作。而这个where的条件竟然是一个没数据的聚合函数。出现了矛盾。
显示部门平均工资低于2000的

select执行顺序
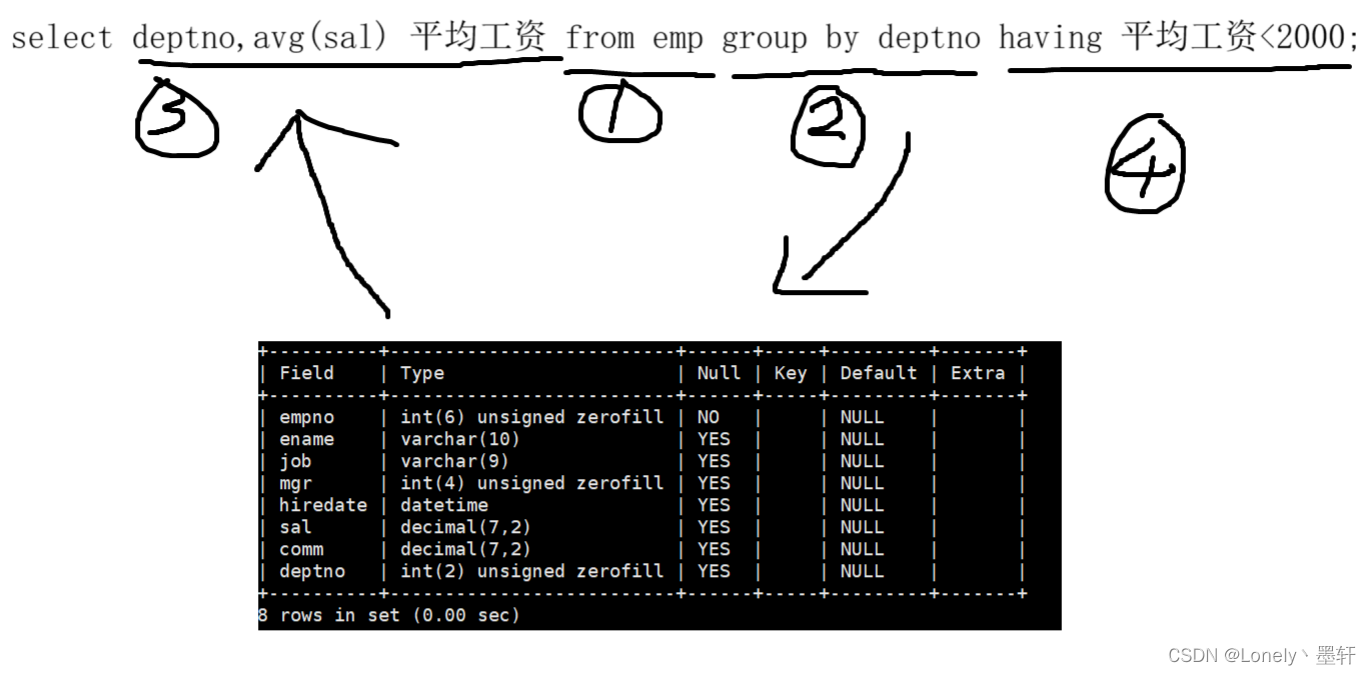
having是对聚合后的数据进行筛选
工资大于1000的,平均工资大于2000的部门。

执行顺序

先找到表,where进行初步筛选,筛选后进行分组,分组后进行聚合函数,最后having对组进行最后筛选
group by总结
- group by不仅仅只是分组,group by是通过分组,为未来的聚合函数提供数据的,所以group by一定是配合聚合函数的。
- group by后面跟的都是分组的字段依据,只有group by后面出现的字段,未来在聚合统计时,select才能出现,其他字段不允许出现。
3.where与having
3.1他们都是筛选条件,但它们不冲突,而是互相补充的。
3.2where是在表的初步筛选时使用。
3.3having是在聚合统计后,对组进行筛选
3.4他们的顺序时不一样的。
3.5他们的顺序不同,一个在前,一个在后,一个进行初步筛选,一个进行统计后筛选。一个对象是表数据,一个对象是组数据。是相互补充的。
SQL查询中各个关键字的执行先后顺序 from > on> join > where > group by > with > having > select > distinct > order by > limit
训练
查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为大写的J
select ename from emp where (sal>500 and job='MANAGER') and ename like 'J%';

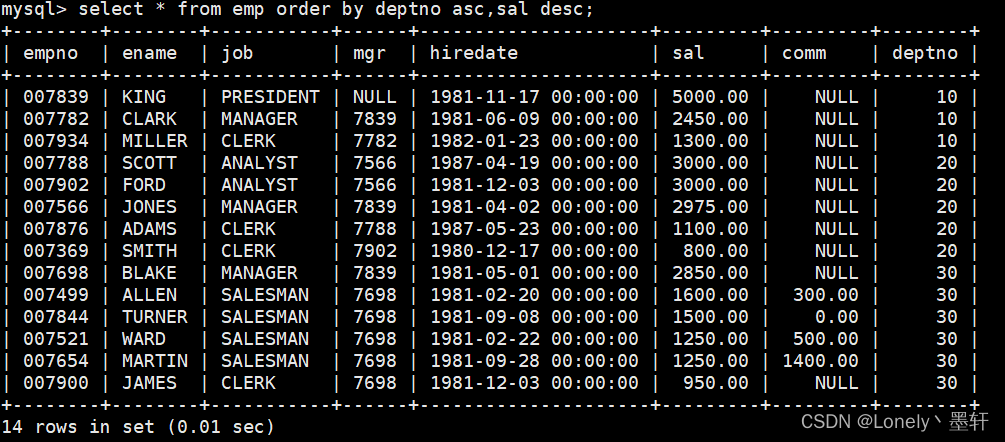
按照部分号升序而雇员的工资降序排序
select * from emp order by deptno asc,sal desc;
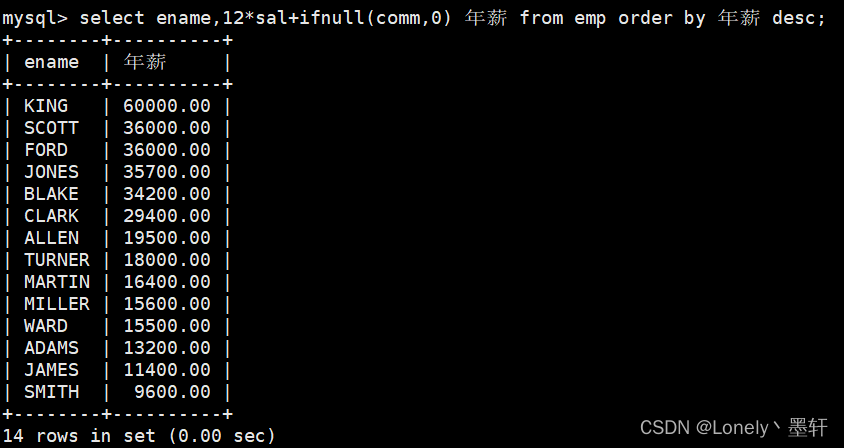
使用年薪进行降序排序
select ename,12*sal+ifnull(comm,0) 年薪 from emp order by 年薪 desc;
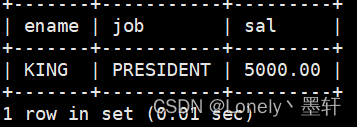
显示工资最高的员工的名字和工作岗位
select ename,job,sal from emp order by sal desc limit 1;
select ename,job,sal from emp where sal=(select max(sal) from emp);
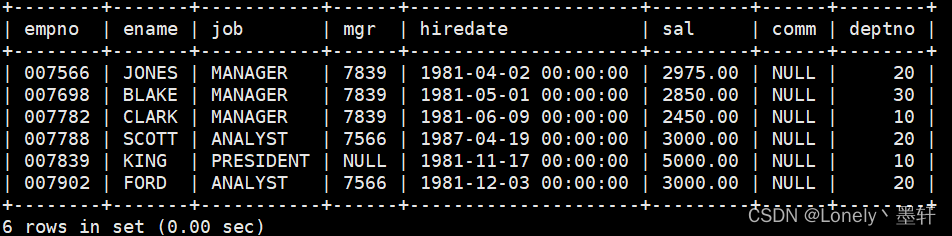
显示工资高于平均工资的员工信息
select * from emp where sal>(select avg(sal) from emp);
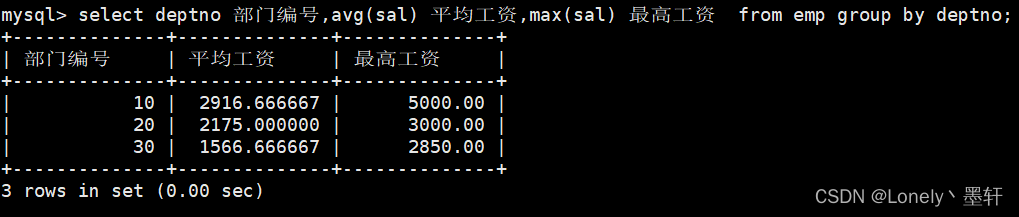
显示每个部门的平均工资和最高工资
select deptno 部门编号,avg(sal) 平均工资,max(sal) 最高工资 from emp group by deptno;
显示平均工资低于2000的部门号和它的平均工资
select deptno,avg(sal) 平均工资 from emp group by deptno having 平均工资<2000;

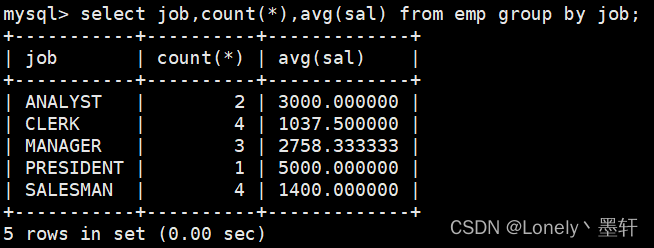
显示每种岗位的雇员总数,平均工资
select job,count(*),avg(sal) from emp group by job;
















 995
995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









