









 文章探讨了如何通过修改Eureka和Ribbon的配置,实现在服务下线后快速更新Ribbon缓存,避免负载均衡到已下线的服务实例。作者提供了两次尝试的方法,包括手动同步和使用Redis进行跨进程通信,以及后续的优化建议。
文章探讨了如何通过修改Eureka和Ribbon的配置,实现在服务下线后快速更新Ribbon缓存,避免负载均衡到已下线的服务实例。作者提供了两次尝试的方法,包括手动同步和使用Redis进行跨进程通信,以及后续的优化建议。
前言
在上文的基础上,通过压测的结果可以看出,使用DiscoveryManager下线服务之后进行压测是不会出现异常情况的,但唯一缺点就是下线服务的方式是取消注册与续约,之后并没有结束进程。也就使得在调用api下线后的服务其实是还存在处理请求的能力的。加之eureka三种级别的缓存同步需要一定时间,Eureka-Client从三级缓存中拉取的并不是实时的服务列表,进而使得Ribbon从Eureka-Client拉取的也不是实时的服务列表。最终导致Ribbon负载均衡到了已经下线的服务实例,并且此时该实例(进程还未关闭)刚好能处理请求!就造成了下线了两个端口的服务实例,但是却还是被负载均衡到来处理请求!
按照这个思路,再去看这张图:
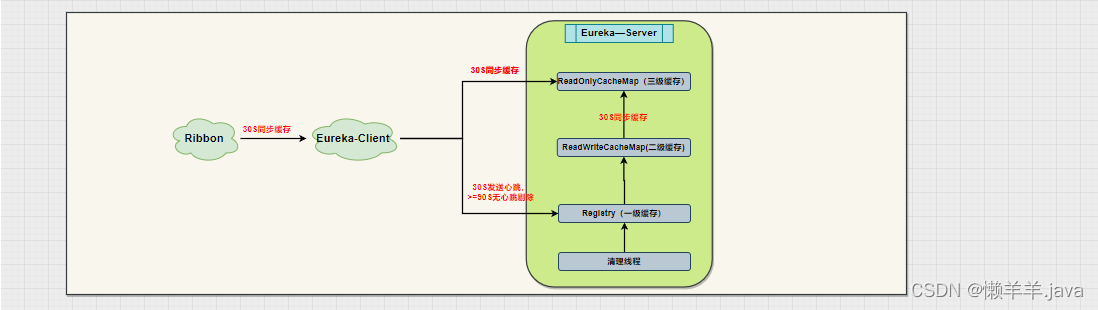
可不可以通过某种手段,当服务下线后去越过三级缓存直接去更新Ribbon缓存来缩短感知时间?
我先说答案——是可以的
1.第一次尝试
1.1服务被调用方更新
手动从Eureka-Client同步服务缓存信息:
在之前分析Ribbon源码的时候,说到了接口路径从http://服务名称/接口路径——>http://服务地址/接口路径,这个过程中调用方的请求被Ribbon拦截器拦截,并且通过负载均衡最终被改写成为了一个准确的服务地址,其中有一个非常重要的方法,getLoadBalancer(“服务名称”)

可见,他通过服务名称就拿到了该服务名称下的所有服务列表(allServerList)和可用服务列表(upServerList),我们通过这个操作可不可以直接获取到最新一手的可用服务列表并且手动去set进Ribbon的可用服务列表缓存里,让他不再去每过30S同步?
Tips:在我们的SpringCloud项目中有一个非常重要的组件SpringClientFactory是Spring Cloud中用于管理和获取客户端实例的工厂类。在这里面可以获取特定服务的负载均衡器(即ILoadBalancer)
于是,便有了下面的操作,专门配置一个Bean去更新Ribbon缓存,每当调用服务下线接口去下线指定服务后就去自动同步Ribbon缓存,不用再Ribbon每隔30S去自动同步:
@Configuration
@Slf4j
public class ClearRibbonCache {
public void clearRibbonCache(SpringClientFactory clientFactory, List<Integer> portParams) {
// 获取指定服务的负载均衡器
ILoadBalancer loadBalancer = clientFactory.getLoadBalancer("user-service");
//在主动拉取可用列表,而不是走拦截器被动的方式——这里
List<Server> reachableServers = loadBalancer.getReachableServers();//这里从客户端获取,会等待客户端同步三级缓存
// 在某个时机需要清除Ribbon缓存
((BaseLoadBalancer) loadBalancer).setServersList(ableServers); // 清除Ribbon负载均衡器的缓存
}
}
于是在下线服务的接口中,就多了一步自动更新缓存的操作(不熟悉这个接口的可以去看上一篇文章):
@GetMapping(value = "/service-down-list")
public String offLine(@RequestParam List<Integer> portParams) {
List<Integer> successList = new ArrayList<>();
//得到服务信息
List<InstanceInfo> instances = eurekaClient.getInstancesByVipAddress(appName, false);
List<Integer> servicePorts = instances.stream().map(InstanceInfo::getPort).collect(Collectors.toList());
//去服务列表里挨个下线
OkHttpClient client = new OkHttpClient();
log.error("开始时间:{}", System.currentTimeMillis());
portParams.parallelStream().forEach(temp -> {
if (servicePorts.contains(temp)) {
String url = "http://" + ipAddress + ":" + temp + "/control/service-down";
try {
Response response = client.newCall(new Request.Builder().url(url).build()).execute();
if (response.code() == 200) {
log.debug(temp + "服务下线成功");
successList.add(temp);
} else {
log.debug(temp + "服务下线失败");
}
} catch (IOException e) {
log.error(e.toString());
}
}
});
log.debug("开始清除Ribbon缓存");
clearRibbonCache.clearRibbonCache(clientFactory,portParams);
return successList + "优雅下线成功";
}
1.2压测第一次尝试
同样我们采用(100线程-3S)的JMeter压测模型去在调用服务下线接口后的15S,30S后压测,压测的接口即为一个普通的跨服务调用接口
下线服务:

下线服务的15S:

此时,观察控制台的日志输出可以发现,已经下线的服务实例还是被负载均衡到了(已下线但进程未退出),好像更新了缓存没有任何效果诶。
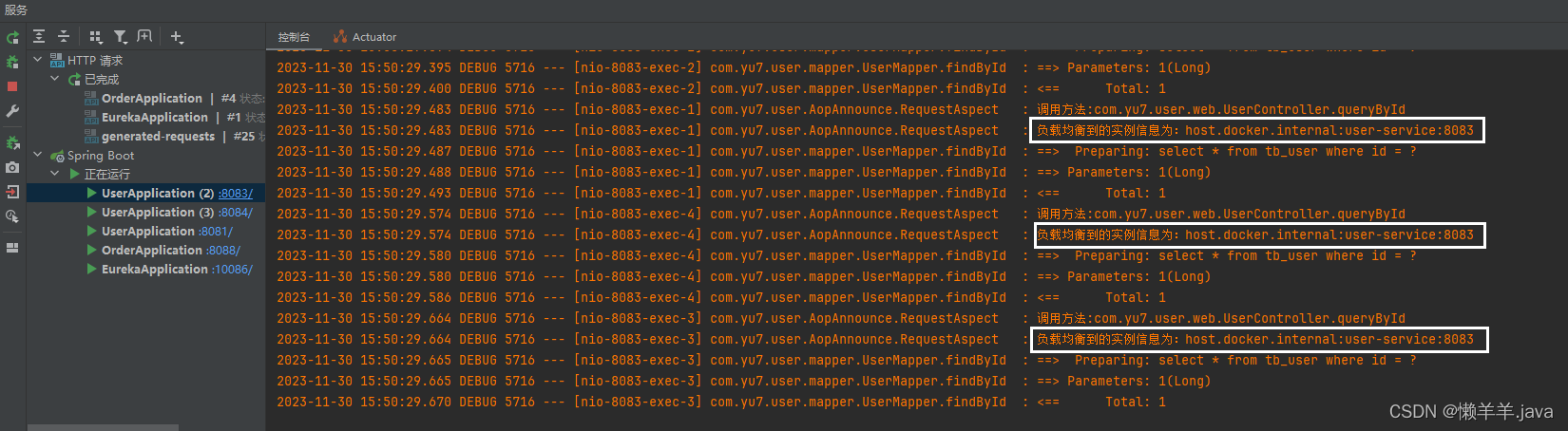
下线服务的30S:

情况和15S如出一辙,并且请求负载均衡到了已下线但进程未退出的服务上。
下线服务的45S:


可见调用api下线服务直到45S左右,已经下线的服务才从每层缓存信息中完全清除,这个时间是非常致命的!
1.3 问题分析
在服务发布的场景就会出现这样一个业务问题:开发调用api下线了某个服务,通知运维可以去关闭这个服务进程了,运维kill-9杀掉了这个进程准备发布新服务。但此时客户端(用户)向服务端发送了请求,刚好该请求涉及跨服务调用,并且由于Ribbon同步Eureka-Client缓存,Eureka-Client同步Eurek-Server中的三级缓存需要一定时间,Ribbon缓存中的可用服务列表不是最新的,同步过来已下线(进程也被kill)的服务。最后请求受到Ribbon负载均衡落到了一个开发通过api下线的服务实例,分发到了一个运维kill-9的服务实例上,造成接口返回500、404、connect time out、connect refused…等错误,造成频繁告警。
1.4 同步的不是最新列表
透过现象看本质:
为什么手动同步Ribbon缓存没有起到效果?是不是同步的内容出了问题?下面打断点开启debug,看看服务下线后到底拿到的是什么服务列表:

意外发现,曾经天真以为可以拿到的实时的服务列表,到头来确实一场空,小丑竟是我自己。明明8083已经下线可为什么还在可用服务列表里,并且还set到了Ribbon缓存中
原来啊,通过那个方法获取服务列表是从Eureka-client拿的,而这其实就是client去三级缓存那里同步的问题。 你说到为什么手动更新了缓存还是会有一段同步时间? 那就是client从三级缓存同步来的服务列表还存在没下线的服务,所以导致手动更新到ribbon缓存里的列表也还存在没下线的服务。看到这里,Eureka的“牺牲一致性保证高可用”是不是体现的淋漓尽致呢?
这个一致性难道真的不能解决了吗?
其实我还有一招
同时结合Eureka-Ribbon架构的服务调用链路,其实在服务调用方去更新Ribbon缓存才能更好保证Ribbon负载均衡的服务列表是我所控制的!
PS:(这里节省了一次尝试,即在服务被调用方去引入过滤操作,尝试过压测结果还是和以前一样,所以就忽略了。直接去服务调用方尝试)
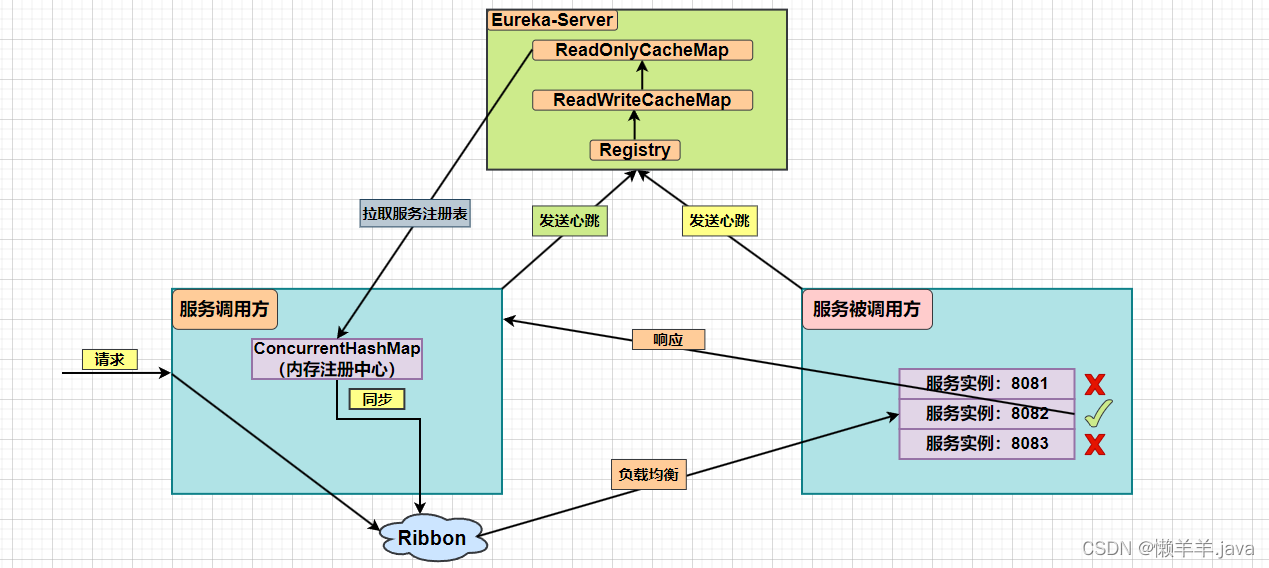
图析:
关于Eureka-Client,Eureka-Server,Ribbon三者间的关系补充:Eureka-Client会定时向Eureka-Server发送心跳注册续约,并且会定时向Eureka-Server拉取服务列表(可以通过registry-fetch-interval-seconds属性来配置时间间隔),与此同时Ribbon也会定时同步Eureka-Client那里来的服务信息存储到Ribbon缓存中。也就是说,Ribbon的服务列表是从Eureka-Server间接获取的。
2.第二次尝试
2.1调用方过滤下线服务
从拿到的服务列表中过滤下线服务,并且在调用方执行:
在调用方执行?那被调用方下线的端口信息怎么让调用方知道呢,跨进程通信你选择MQ?还是Redis?这里我选择Redis
在上述更新缓存的操作中稍作更改,把更新操作移动到服务调用方,并且引入Redis来作为通信支持(这里采用hash的数据结结构),那么被调用方现在所需要的就是更新下线的端口信息到redis中:

@GetMapping(value = "/service-down-list")
public String offLine(@RequestParam List<Integer> portParams) {
List<Integer> successList = new ArrayList<>();
//得到服务信息
List<InstanceInfo> instances = eurekaClient.getInstancesByVipAddress(appName, false);
List<Integer> servicePorts = instances.stream().map(InstanceInfo::getPort).collect(Collectors.toList());
//去服务列表里挨个下线
OkHttpClient client = new OkHttpClient();
log.error("开始时间:{}", System.currentTimeMillis());
portParams.parallelStream().forEach(temp -> {
if (servicePorts.contains(temp)) {
String url = "http://" + ipAddress + ":" + temp + "/control/service-down";
try {
Response response = client.newCall(new Request.Builder().url(url).build()).execute();
if (response.code() == 200) {
log.debug(temp + "服务下线成功");
successList.add(temp);
} else {
log.debug(temp + "服务下线失败");
}
} catch (IOException e) {
log.error(e.toString());
}
}
});
// todo Redis通知
stringRedisTemplate.opsForHash().put("port-map","down-ports",portParams.toString());
return successList + "优雅下线成功";
}
并且以前更新Ribbon可用服务列表操作也有稍微变化,即新增了一个手动过滤操作:
@Configuration
@Slf4j
public class ClearRibbonCache {
/**
* 削减
*/
public static boolean cutDown(List<Integer> ports, Server index) {
return ports.contains(index.getPort());
}
public void clearRibbonCache(SpringClientFactory clientFactory, String portParams) {
// 获取指定服务的负载均衡器
ILoadBalancer loadBalancer = clientFactory.getLoadBalancer("user-service");
//在主动拉取可用列表,而不是走拦截器被动的方式——这里
List<Server> reachableServers = loadBalancer.getReachableServers();//这里从客户端获取,会等待客户端同步三级缓存
//过滤掉已经下线的端口,符合条件端口的服务过滤出来
List<Integer> portList = StringChange.stringToList(portParams);
List<Server> ableServers = reachableServers.stream().filter(temp -> !cutDown(portList, temp)).collect(Collectors.toList());
log.debug("可用服务列表:{}", ableServers);
// 在某个时机需要清除Ribbon缓存
((BaseLoadBalancer) loadBalancer).setServersList(ableServers); // 清除Ribbon负载均衡器的缓存
}
}
在服务调用方,每次进行跨服务调用前都去从Redis中获取出实时下线的端口并且去更新Ribbon缓存:

2.2压测第二次尝试
当下线完服务,立即进行压测,可以看到所有的跨服务调用请求都落在了还未下线的实例上,并且已下线但进程未关闭的服务实例没有再处理请求,并且测试结果完全没有异常:

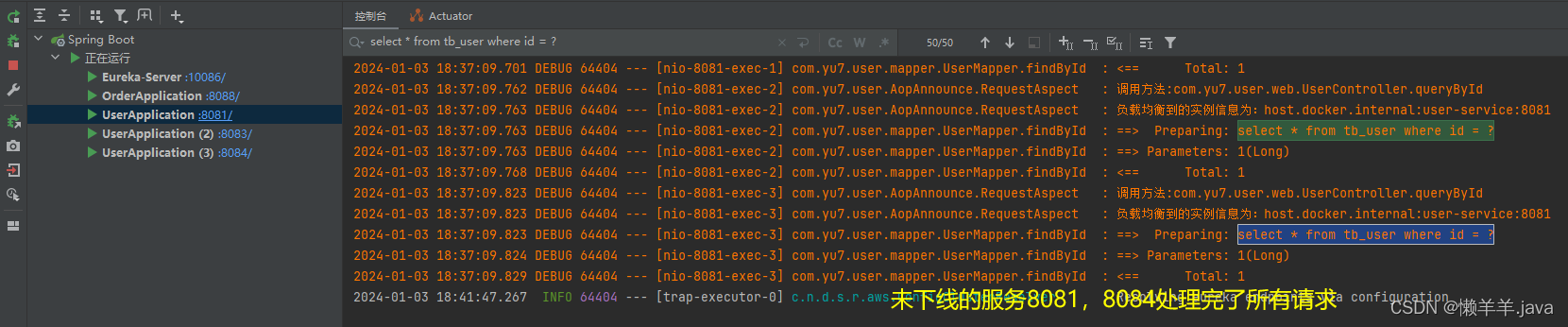
并且15S,30S的时间节点上,也没有任何异常:
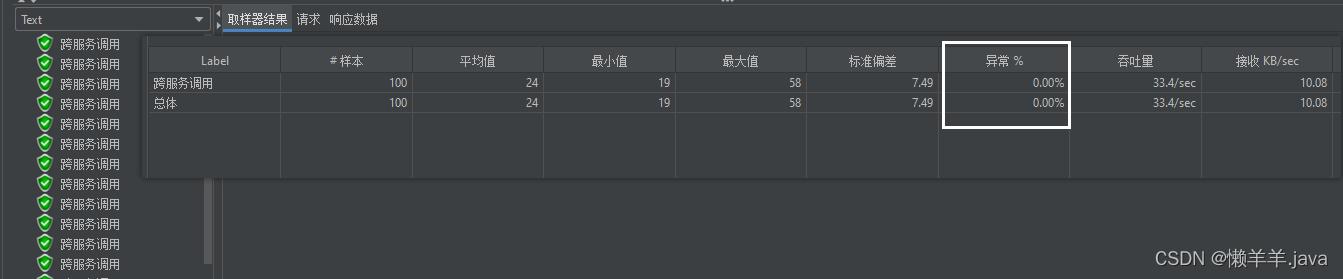
可见通过此种方式来主动更新Ribbon可用服务列表确实可行,特别是在运维那边发布新服务的一个特定场景下可以解决Eureka感知下线服务迟钝从而影响Ribbon负载到不可用的服务实例上这一问题。
2.3优化
其实,如果每次在新发布服务的场景下告警的接口都可以精确定位到,并且数量不多的情况我觉得在那几个业务接口里去手动同步一下Ribbon缓存没有什么大问题也可以解决问题。但是如果每次告警的接口有很多,并且不固定那上述的方法就显得有些许臃肿。而且这也是一种入侵式编程,我其实是不推荐的!
说起入侵式编程不禁就会想到无入侵式编程——Aop
直接把出现错误的模块作为切面,并把更新Ribbon的操作作为切入点写到表达式里,就完美做到了不改变已有业务而实现了更新功能,就像这样:
@Aspect
@Component
@Slf4j
public class RequestAspect {
@Resource
SpringClientFactory springClientFactory;
@Resource
ClearRibbonCacheBean clearRibbonCacheBean;
@Resource
private StringRedisTemplate stringRedisTemplate;
@Before(value = "execution(* com.yu7.order.web.*.*(..))")
public void refreshBefore(JoinPoint joinPoint) {
String ports = (String) stringRedisTemplate.opsForHash().get("port-map", "down-ports");
log.debug("从Redis获取的端口为:{}", ports);
//下线了才会有值,没有值说明没下线不用更新
if (ObjectUtils.isNotEmpty(ports)) {
clearRibbonCacheBean.clearRibbonCache(springClientFactory, ports);
}
}
}
进行压测,结果和预期完全一致~
写到最后
我想说:其实我的方案只是相当于提出了一个大体框架和构想,粗略地实现了基于Eureka的微服务架构中服务状态感知的问题,当业务里存在不止一种调用关系,下线服务类型不一致,服务断断续续下线会造成value值丢失…方案就需要进一步细化(还存在硬编码问题,嘻嘻),并且为了切面不影响业务还应该给存到Redis的数据加上TTL等其他保险措施,总而言之也欢迎大家提出建议,共同精进,一起解决这一难题!



















 2510
2510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











