







1.剑指offer:04题.二维数组中的查找
力扣 https://leetcode.cn/problems/er-wei-shu-zu-zhong-de-cha-zhao-lcof/
https://leetcode.cn/problems/er-wei-shu-zu-zhong-de-cha-zhao-lcof/
方法:二分法
因为题目中提到有序数组,那么我们首先想到二分法。
自己写的二分法总有遗漏,看到K神的算法,瞬间明白,以下思路借鉴了K神。
在此感谢力扣大佬K神@Krahets!

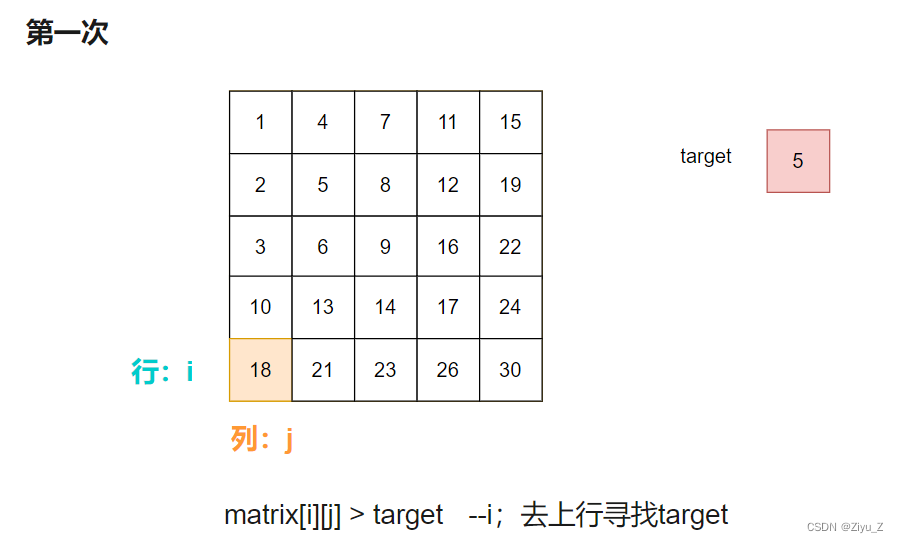
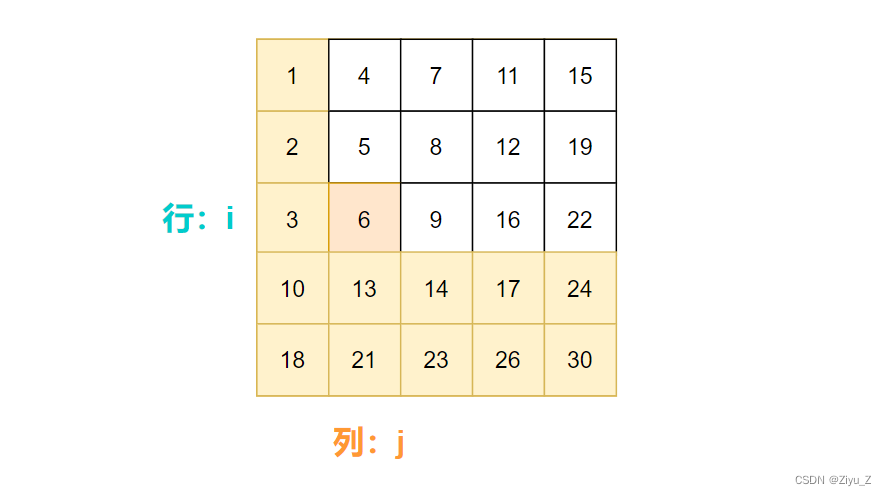
从图中可看出矩阵从上到下,从左到右依次递增,所以可以同时移动指针 i 和 j。
最后一行开始用首列元素与targe比较,
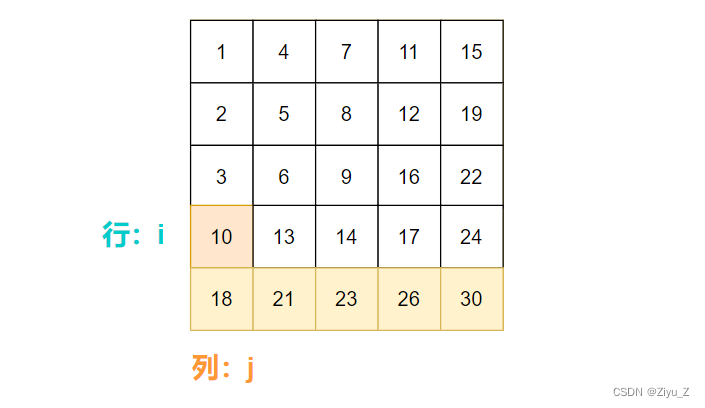
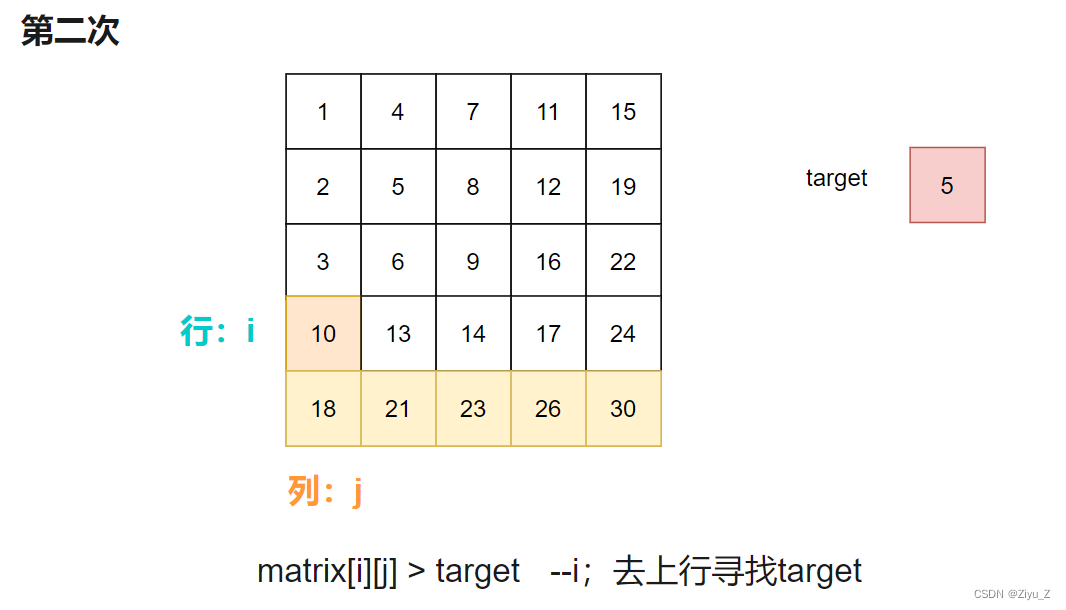
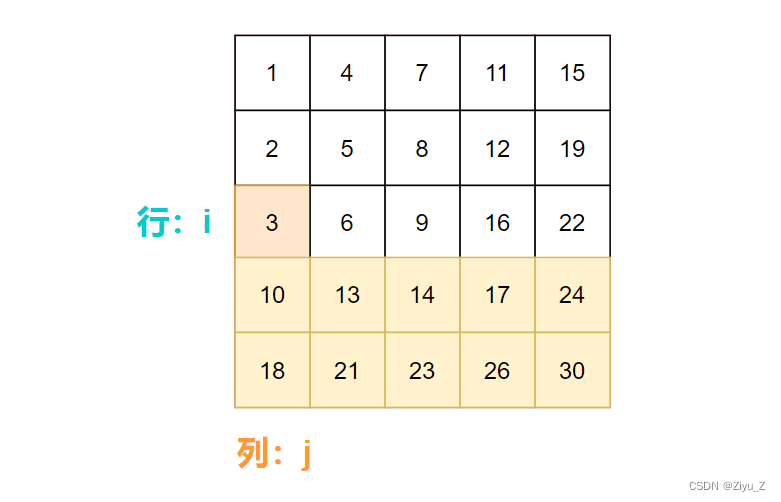
如果targe小,意味着target在当前行的上方,所以向上移动行指针 i 。
反之,target在当前列右方,所以向右移动列指针 j 。
直至找到target,返回true。如果没有找到,返回false。
算法思路:
1. 确定 行指针 i 在最后一行, 列指针 j 在第一列。
2. 在矩阵的长宽范围内循环,将 i 行的 j 列元素 与 target 比较大小。
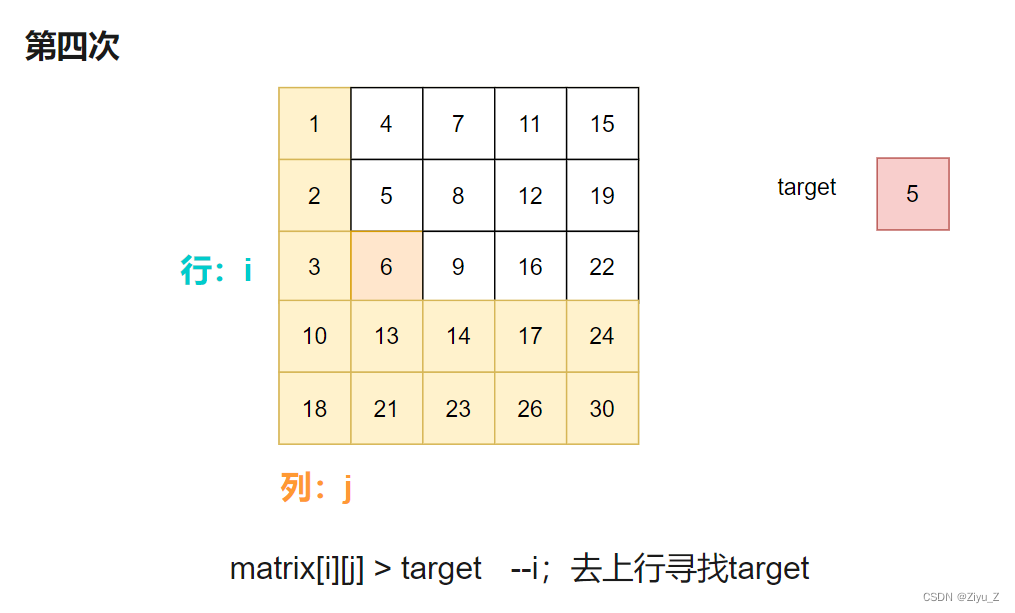
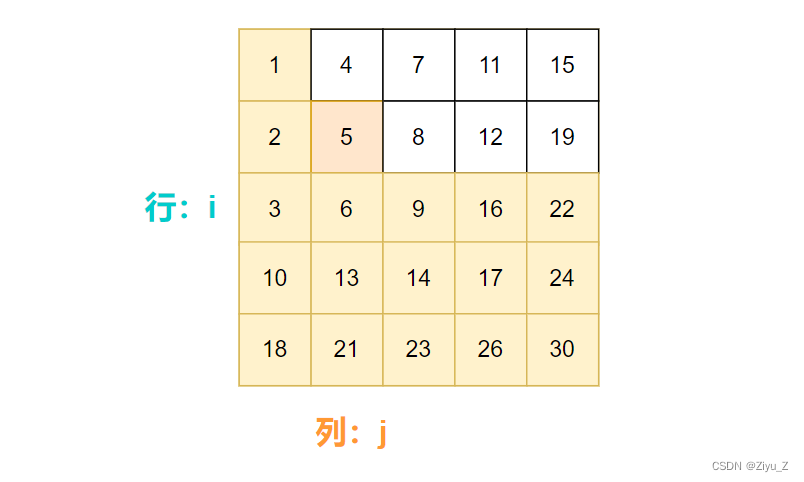
matrix[i][j] > target 说明此时target在 i 行上方,所以去 i - 1 行继续。
matrix[i][j] < target 说明此时target在 i 行,移动列指针 j 与target比较。
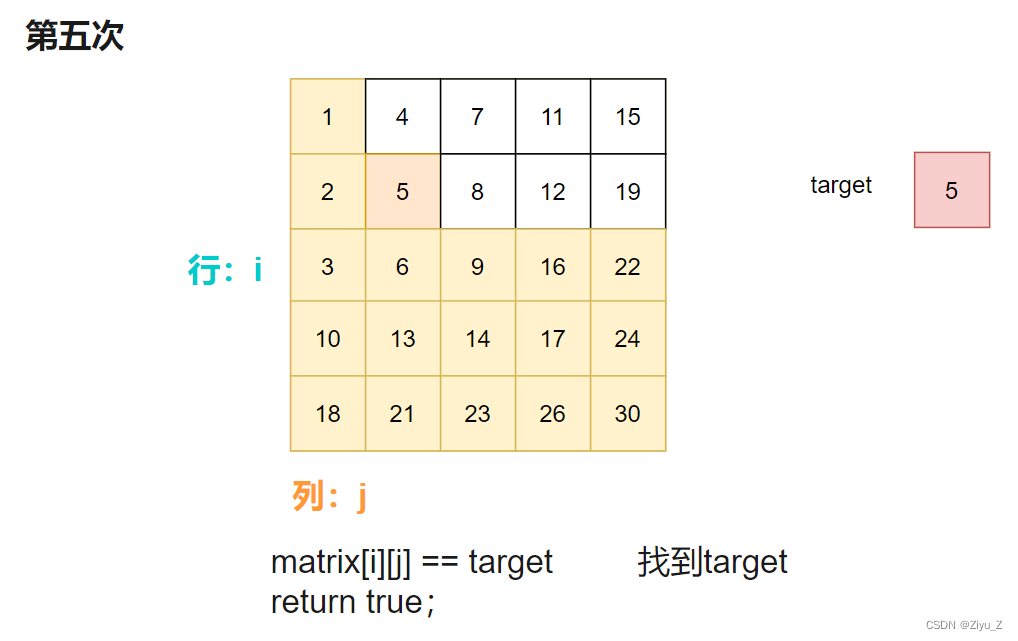
matrix[i][j] == target 说明此时找到target,返回true。
3. 跳出循环,说明矩阵中没找到target,返回false。

复杂度分析:
时间复杂度:O(logN)。二分法的时间复杂度。
空间复杂度:O(1)。利用常数项额外空间。
bool findNumberIn2DArray(vector<vector<int>>& matrix, int target) {
int i = matrix.size() - 1, j = 0; // 行指针从最底层开始,列指针从首列开始
while(i >= 0 && j < matrix[0].size()){
if(matrix[i][j] > target) --i; // 移动行指针
else if(matrix[i][j] < target) ++j; // 移动列指针
else return true; // 找到target
}
return false; // 没找到target
}2.剑指offer:11题.旋转数组的最小数字力扣https://leetcode.cn/problems/xuan-zhuan-shu-zu-de-zui-xiao-shu-zi-lcof/
方法:二分法
题目中提及有序数组,所以想到二分法。
其实该题有多种简单算法,但为了追求时间更优,故在此讲解二分法。
将旋转后的数组分为:左部分和右部分。
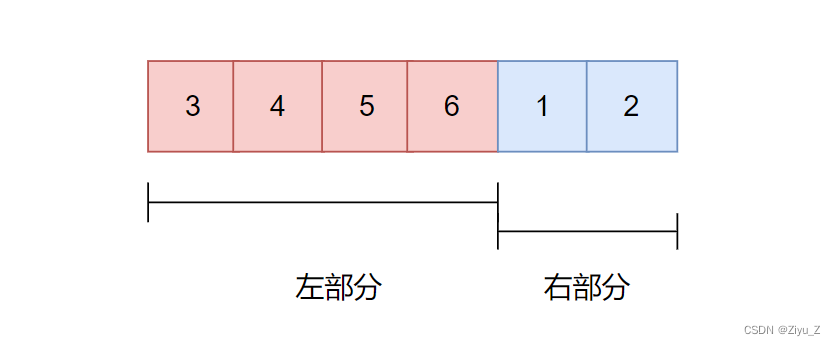
左部分:较大的数组; 右部分:较小的数组,首元素为我们需要的元素。
利用mid不断缩小寻找区间,关键:左部分元素>=右部分元素
算法思路:
1. 确定左右边界,在左闭右开区间循环。
2. 只比较numbers[mid] 和 numbers[j]。
不比较指针i的元素,是因为我们已知旋转后的右部分靠右。
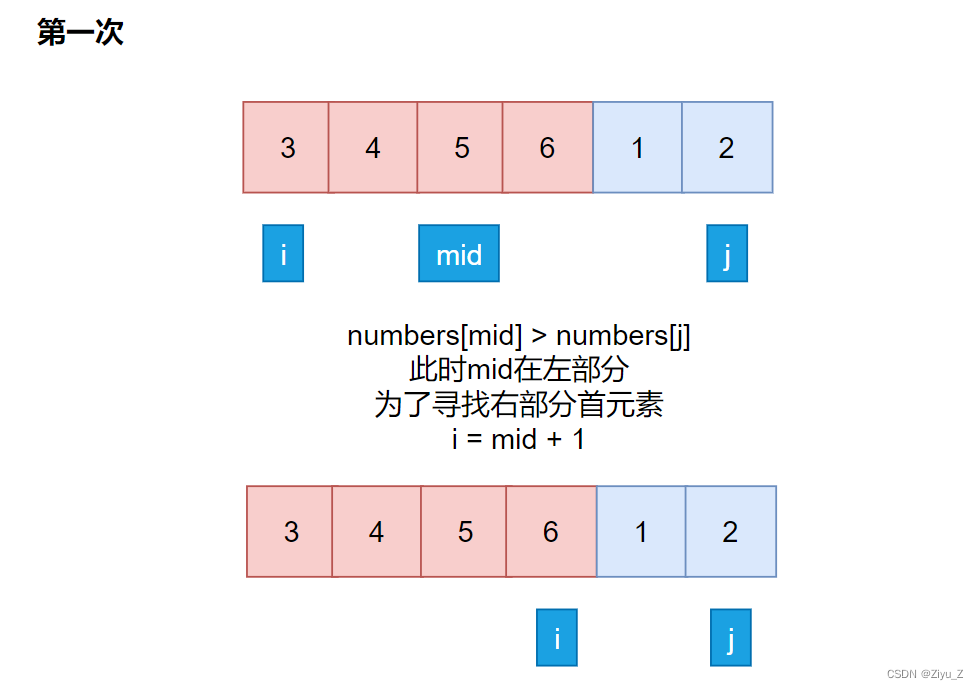
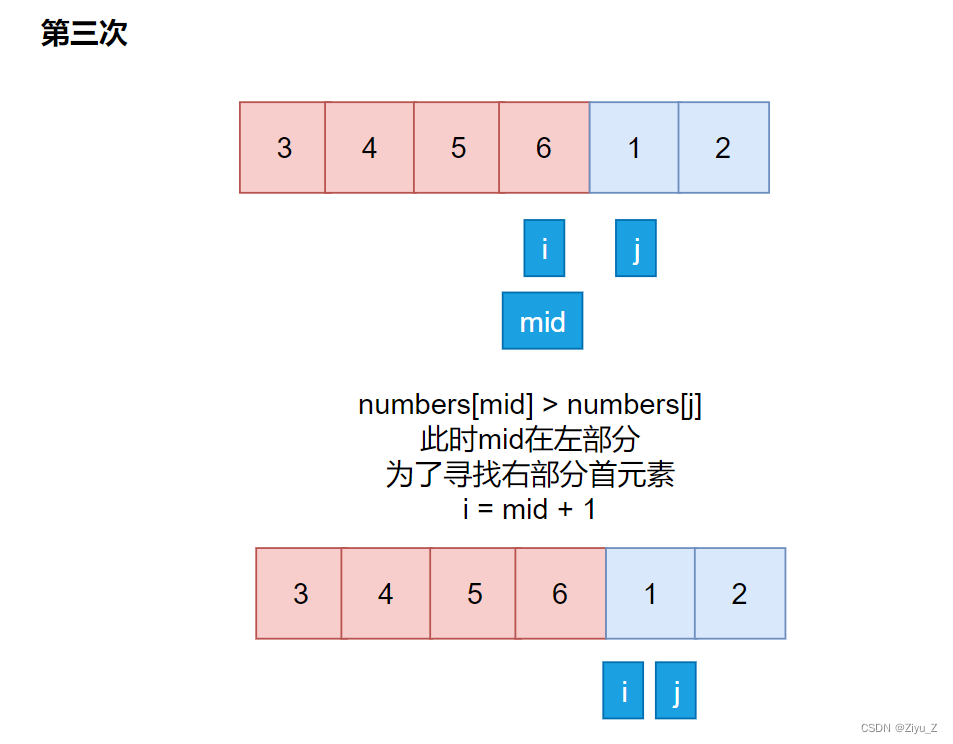
1> numbers[mid] < numbers[j] mid在右部分,缩小区间让 j = mid。
注意,此时j不是mid+1,是因为我们循环的区间为左开右闭。
2> numbers[mid] > numbers[j] mid在左部分,缩小区间让 i = mid + 1。
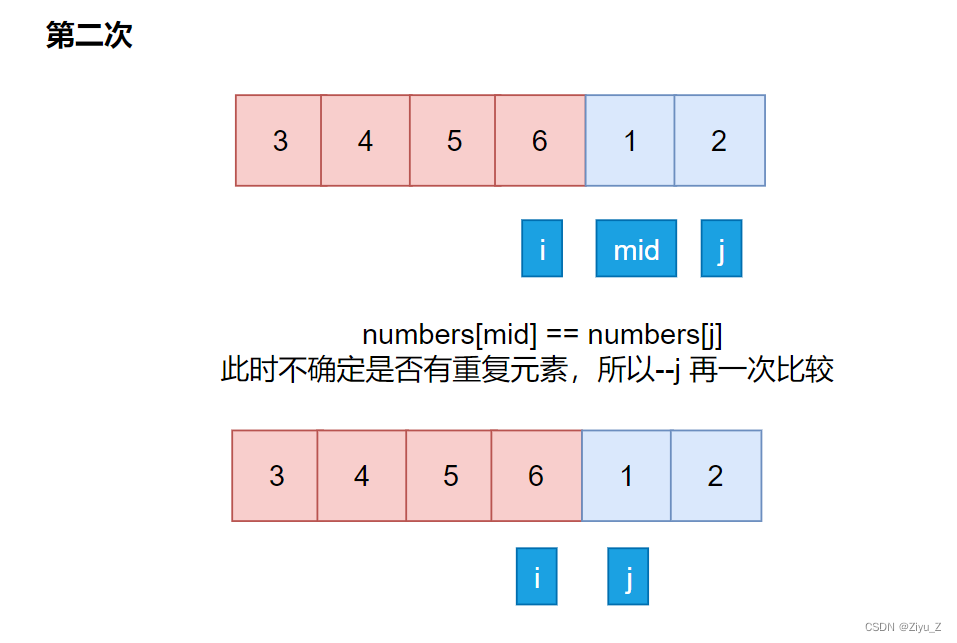
3> numbers[mid] == numbers[j] 可能存在重复数字,不能确定为右区间首元素。
所以需要 --j 继续循环。
3. 跳出循环,返回指针i所指向的元素。

复杂度分析:
时间复杂度:O(logN)。二分法的时间复杂度为logN。
空间复杂度:O(1)。利用常数项额外空间。
int minArray(vector<int>& numbers) {
int i = 0, j = numbers.size() - 1; // 确定区间
while(i < j){
int mid = i + (j - i) / 2;
if(numbers[mid] < numbers[j]) // mid在右部分
j = mid;
else if(numbers[mid] > numbers[j]) // mid在左部分
i = mid + 1;
else // 此时可能有重复元素,故进一步缩小范围比较
--j;
}
return numbers[i]; // 返回右部分首元素
}3.剑指offer:50题.第一次只出现一次的字符
力扣https://leetcode.cn/problems/di-yi-ge-zhi-chu-xian-yi-ci-de-zi-fu-lcof/
方法:哈希表
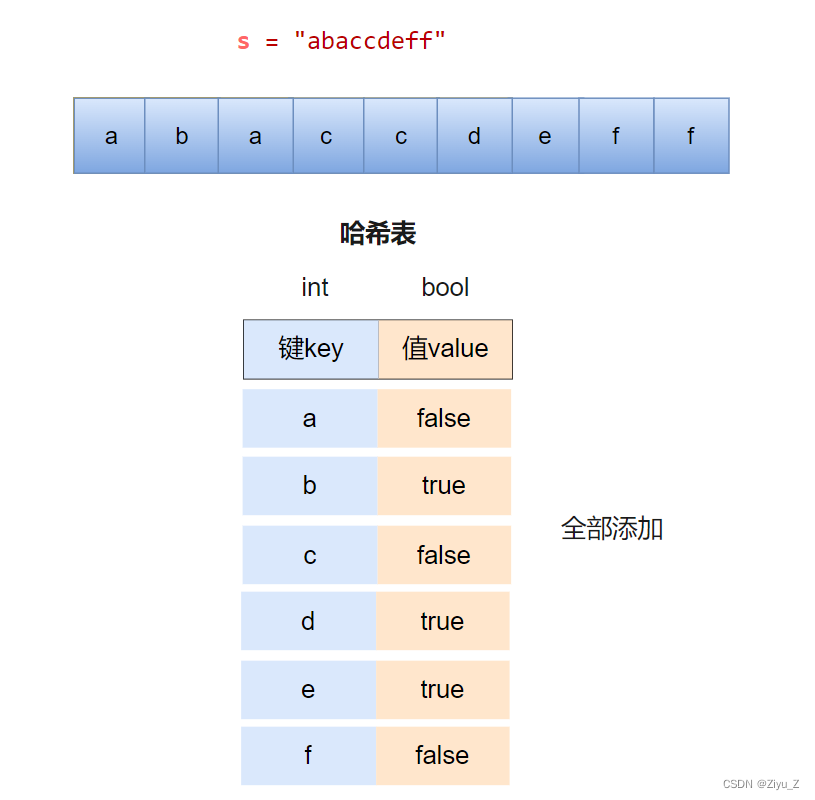
因为一个字符可能出现多次,
所以需要一个容器来储存字符和字符的出现次数或者是字符是否出现过。
字符的出现次数需要int型变量储存,而判断字符是否出现过用boolean型。
两种情况相比,使用boolean型不需要总是累加次数,故优先使用boolean型。
再是利用两次循环,
一次用来储存字符和字符出现情况,
一次用来查找只出现一次的字符,并返回。
最后,如果没找到返回‘ ’。
算法思路:
1. 设置一个哈希表,用来储存字符和字符是否出现,出现表示true,否则false。
2. 第一次循环:将字符与字符出现情况一一对应。
3. 第二次循环:找出只出现过一次的字符,并返回该字符。
4. 没有只出现过一次的字符,返回‘ ’。




复杂度分析:
时间复杂度:O(N)。
分别利用了两次for循环,时间复杂度为O(N),哈希表查找只用了O(1)。
空间复杂度:O(1)。
由于题目中提出只有小写字母,所以哈希表最多有26个可能,O(26) = O(1)。
char firstUniqChar(string s) {
unordered_map<char,bool> map; // 设置哈希表
for(char a:s) // 循环记录字符及其出现情况
map[a] = map.find(a) == map.end(); // 逐个添加记录
for(char b:s) // 循环查找只出现一次的字符
if(map[b] == 1)
return b;
return ' '; // 没有只出现一次的字符,返回空格
}注意:对map.find(a) == map.end()的理解
1. end函数表示刚溢出数组的第一位下标。
假设数组长度为5,那么最后元素的下标为4,end()返回最后一位的下一位,即5。
2. find函数返回当前哈希表中a的迭代器(可理解为下标)。如果没找到,返回end()。
3. map.find(a) == map.end()
1> 如果当前哈希表中不存在a
表示a第一次出现,那么无法在表中查找到。
find()返回end(),即该表达式为真,值为true。
2> 如果当前哈希表中存在a
即此次a是重复出现,可在表中查找到。
find()返回一个非end()值,即该表达式为假,值为false。
因此,不需要担心同一个字符出现的次数过多,
只要是重复出现,就会赋值为false。
23.1.4 第五次
每次在力扣题解区总能看到大佬@Krahets,深深为其精简的算法所折服,能感觉到刷题的吃力,也享受到了其中的乐趣。点进大佬主页,发现他还写了一本算法书,有网页版,已经看过几章内容,很受用,向大家推荐: hello-algo.com![]() http://hello-algo.com
http://hello-algo.com
不知道大家在写刷题博客时是怎么样的,笔者感觉确实累。。
写算法步骤,自己会想为什么这样写?是否能那样写?这样写和那样写的区别是什么?
再是制作算法图,更是耗时,但制作过程也会发现自己一些问题。
有时候会嫌累和耗时,会怀疑是否有必要每天都写这个博客呢?
不可忽视的是,写博客确实能让自己更进一步了解算法的由来和过程,也能坚持刷题。
只能说,但行好事,莫问前程,与君共勉!
最后,本文如有错误,欢迎斧正!















 117
117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









