






1.问题:
当样本拥有许多的指标,我们想要知道那些指标是影响比较大,就可以采用熵权法
2.原理:
熵权法就是根据一项指标的变化程度来分配权重的,举个例子:小张和小王是两个高中生,小张学习好回回期末考满分,小王学习不好考试常常不及格。在一次考试中,小张还是考了满分,而小王也考了满分。那就很不一样了,小王这里包含的信息就非常大,所对应的权重也就高一些。
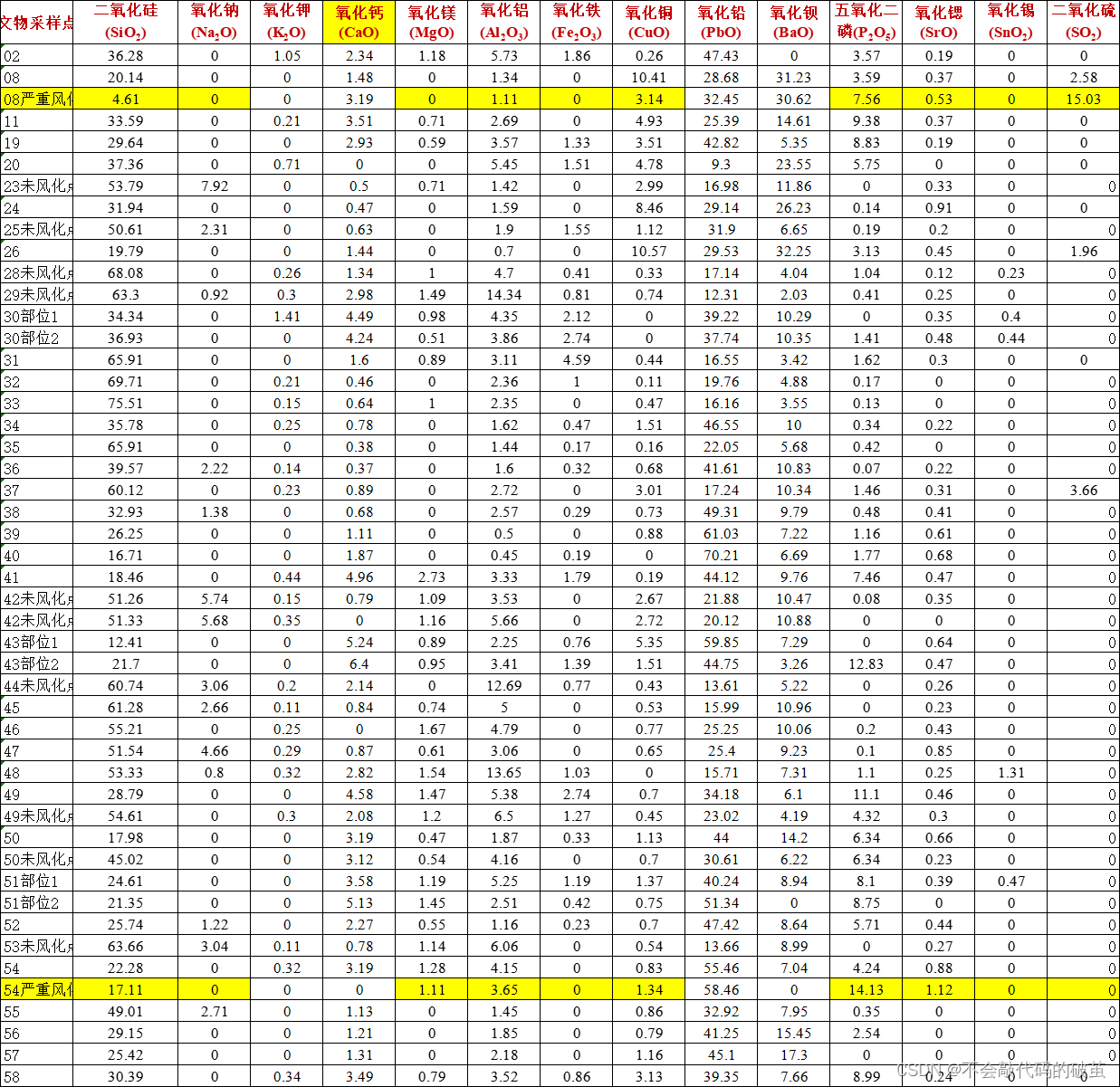
3.数据:
4.结果:
14个指标分别得分为:
56.9435
12.7426
100.0000
80.1075
23.7401
24.2841
14.2703
19.2238
44.6097
34.9496
22.4646
32.3667
3.6757
3.8831
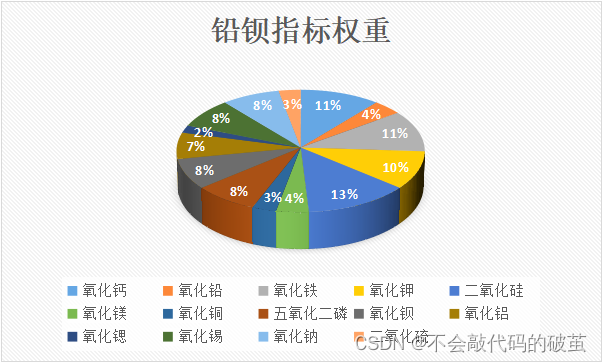
转换成百分制:
(https://img-blog.csdnimg.cn/09588190060b4bf1a5993b0781db0442.png)
用excel换成三维圆饼图:
5.代码:
function test11()
%读取数据
data=xlsread('F:\铅钡1');
data1=data;
%%越小越优型处理
index1=[3,4];%越小越优指标位置
for i=1:length(index1)
data1(:,index1(i))=max(data(:,index1(i)))-data(:,index1(i));
end
%%某点最优型指标处理
index1=[5];
a=90;%最优型数值
for i=1:length(index1)
data1(:,index1(i))=1-abs(data(:,index1(i))-a)/max(abs(data(:,index1(i))-a));
end
%数据标准化 mapminmax对行进行标准化,所以转置一下
data2=mapminmax(data1',0.002,1); %标准化到0.002-1区间
%得到信息熵
[m,n]=size(data2);
p=zeros(m,n);
for j=1:n
p(:,j)=data2(:,j)/sum(data2(:,j));
end
for j=1:n
E(j)=-1/log(m)*sum(p(:,j).*log(p(:,j)));
end
%计算权重
w=(1-E)/sum(1-E);
%计算得分
s=data2*w';
Score=100*s/max(s);
disp('14个指标分别得分为:')
disp(Score)

















 5271
5271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











