






1.获取网站url
由于版权原因这里就不贴网址了,随便一个网址都可以,然后获取它的url
2.寻找网站的User-Agent
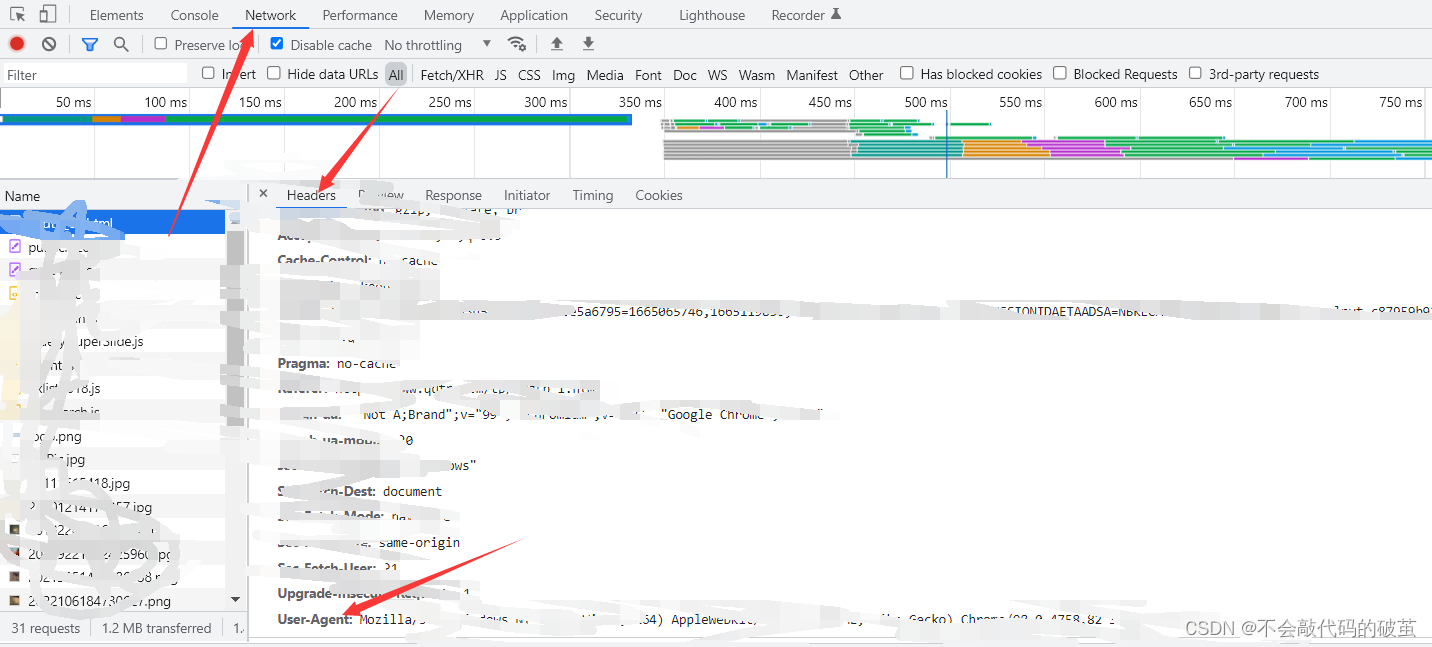
3.代码
import urllib.request
url = 'https://xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
# 反爬手段
headers = {
'User-Agent': 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
}
# 请求对象的定制
request = urllib.request.Request(url=url, headers=headers)
# 获取响应数据
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')//注意网站的编码可能不一样
# 数据下载到本地
fp = open('douban.json', 'w', encoding='utf-8')//生成douban.json文件
fp.write(content)
4.效果图


















 1657
1657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











