爬虫学习:☠️
一.爬虫基础知识
1.1爬虫开发使用的开发环境
"""
Python3.7
系统环境:Mac(windows、linux都行)
编辑器:Pycharm
网页下载:requests
网页解析:BeautifulSoup/bs4
网页分析:chrome浏览器(用到了EditThisCookie插件)
"""
1.2 cmd安装对应的第三方包
"requests"
C:\Users\xxq\AppData\Local\Programs\Python\Python37\python.exe -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests
"BeautifulSoup4"
C:\Users\xxq\AppData\Local\Programs\Python\Python37\python.exe -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple BeautifulSoup4
"selenium"
C:\Users\xxq\AppData\Local\Programs\Python\Python37\python.exe -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple selenium
import requests
from bs4 import BeautifulSoup
import selenium
print("ok")
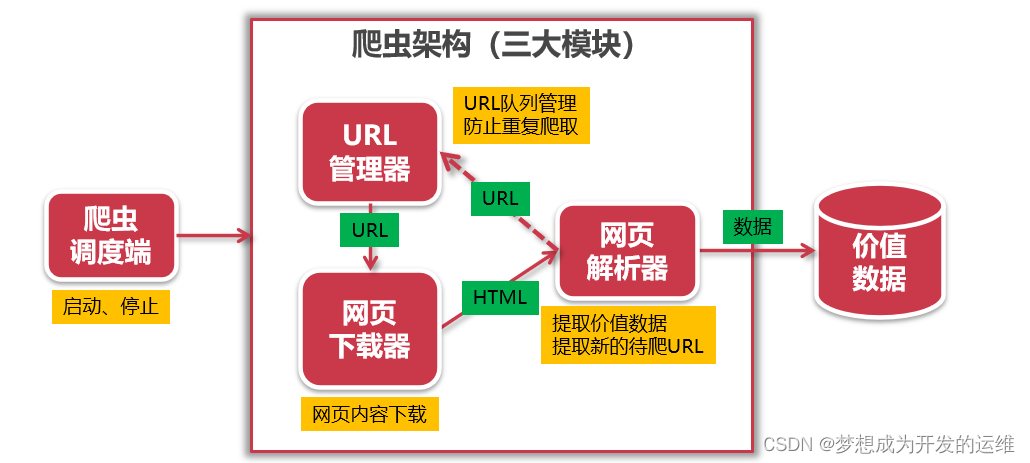
1.3 爬虫架构(三大模块)
1.URL管理器:通过set存储已爬取网页的url,防止陷入死循环
2.网页下载器:通过网页下载器获取url对应的内容,已经根据不同的前端页面例如反爬、java动态验证等页面,爬取后生成html
3.网页解析器:网页下载器将url中的内容爬取完成后生成对应的html,通过解析html获取有用内容或新的url传入url管理器,爬取新的数据
4.爬虫调度端:针对爬虫程序进行管理,生命周期由它进行拓展和维护!
5.价值数据:将网页解析器获取到的数据,写入到mysql或redis等数据库中进行存储!
二.爬虫的重要组件
2.1 request网页下载库
1.python程序如何通过request到达网页服务器?
2.2 发送request请求
发送request请求
2.3 接收response响应
接收response响应
// 查看状态码,如果等于200代表请求成功
// 可以查看当前编码,以及变更编码
// (重要!requests会根据Headers推测编码,推测不到则设置为ISO-8859-1可能导致乱码)
// 查看返回的网页内容
// 查看返回的HTTP的headers
// 查看实际访问的URL
// 以字节的方式返回内容,比如用于下载图片
// 服务端要写入本地的cookies数据
2.4 爬取简单网站
import requests
url = "http://www.crazyant.net"
r = requests.get(url)
print(r.status_code)
print(r.headers)
print(r.text)
print(r.encoding)
print(r.cookies)
import requests
url = "http://www.httpcn.com"
r = requests.get(url)
print(r.status_code)
print(r.headers)
r.encoding="utf-8"
print(r.text)
2.5 URL管理器
1.对爬取URL进行管理,防止重复和循环爬取,支持新增URL和取出URL
1.需要对外提供俩个api接口
2.中层实现逻辑
3.数据存储
分为三种方式:
01:python内存方式--待爬取的url为set集合:防止重复、已爬取的url也为set集合:一致性
02:redis:缓存数据库中进行存储
03:mysql中利用关系型数据库进行存储url的状态

2.6 url管理器py
1.新增python软件包(因为url管理器,比较常用所以写完python软件包.方便调用)
Dictionary
Python package
2.因为url管理器比较典型,其中包含了数据和不同状态的url集合,以及对外暴漏接口.所以要封装为class
class UrlManager():
"""
url管理器
"""
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_url(self,url):
if url is None or len(url) == 0:
return
if url in self.new_urls or url in self.old_urls:
return
else:
self.new_urls.add(url)
def add_new_urls(self,urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
def get_url(self):
if self.has_new_url():
url = self.new_urls.pop()
self.old_urls.add(url)
return url
else:
return None
def has_new_url(self):
return len(self.new_urls) > 0
if __name__ == "__main__":
"""
简单来说,该语句用来当文件当作脚本运行时候,就执行代码;但是当文件被当做Module被import的时候,就不执行相关代码。
最顶层的__name__,将会被设置成了__main__,导入的模块中的__name__就被设置成了模块的名称
因此也可以用if __name__ == “__main__”来判断你的模块代码是不是被当作最顶层模块在使用。
--单独执行此脚本,可以用上方的写法.会执行下放的内容,如果是引入的方式则不会执行下发的内容,会返回false
"""
url_manger = UrlManager()
url_manger.add_new_url("url1")
url_manger.add_new_urls(['url1','url2','url3'])
print(url_manger.new_urls,url_manger.old_urls)
print("#" * 30)
new_url = url_manger.get_url()
print(url_manger.new_urls,url_manger.old_urls)
print("#" * 30)
new_url = url_manger.get_url()
print(url_manger.new_urls, url_manger.old_urls)
print("#" * 30)
new_url = url_manger.get_url()
print(url_manger.new_urls, url_manger.old_urls)
print("#" * 30)
print(url_manger.has_new_url())























 9562
9562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











