







参考李沐老师的教材写的。
通过函数与0的距离来衡量函数的复杂度。
但是怎么精确的确定一个函数和0之间的举例呢?没有一个正确答案。
一种简单的方法是通过线性函数中的权重向量的某个范数来度量其复杂性,例如
。要保证权重向量比较小,最常用方法是将其范数作为惩罚项加到最小化损失的问题中。
将原来的训练目标*最小化训练标签上的预测损失*,调整为*最小化预测损失和惩罚项之和*。现在,如果我们的权重向量增长的太大,我们的学习算法可能会更集中于最小化权重范数 。这正是我们想要的。
在线性回归中,我们的损失函数为下式
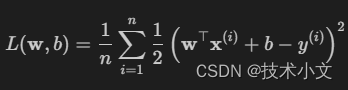
x(i)为样本i的特征,y(i)为样本i的标签,(w,b)为权重和偏置参数。为了惩罚权重向量的大小,我们必须在损失函数上填加,并且需要平衡这个新的额外惩罚损失。
我们通过正则化常数来描述这种权衡:

这里采用平方范数并且呈上二分之一是为了计算方便。L2正则化回归的小批量随机梯度下降更新为:
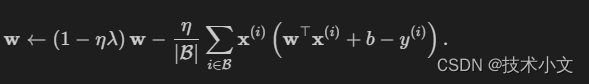
通过一个简单的例子来演示一下。
import torch
from torch import nn
from d2l import torch as d2l生成一些数据,生成公式如下:

我们选择标签是关于输入的线性函数。标签同时被均值为0,标准差为0.01高斯噪声破坏。为了使过拟合的效果更加明显,我们可以将问题的维数增加到d = 200,并使用一个只包含20个样本的小训练集。
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05
train_data = d2l.synthetic_data(true_w, true_b, n_train)
train_iter = d2l.load_array(train_data, batch_size)
test_data = d2l.synthetic_data(true_w, true_b, n_test)
test_iter = d2l.load_array(test_data, batch_size, is_train=False)
#初始化模型参数
def init_params():
w = torch.normal(0, 1, size=(num_inputs, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
return [w, b]
#定义L2范数惩罚项
def l2_penalty(w):
return torch.sum(w.pow(2)) / 2 #w.pow(2)即为w的平方
下面是训练代码
def train(lambd):
w, b = init_params()
net, loss = lambda X: d2l.linreg(X, w, b), d2l.squared_loss
num_epochs, lr = 100, 0.003
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
# 增加了L2范数惩罚项,
# 广播机制使l2_penalty(w)成为一个长度为batch_size的向量
l = loss(net(X), y) + lambd * l2_penalty(w)
l.sum().backward()
d2l.sgd([w, b], lr, batch_size)
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数是:', torch.norm(w).item())
首先用lambd = 0来训练,忽略权重衰退看训练结果。
train(lambd=0)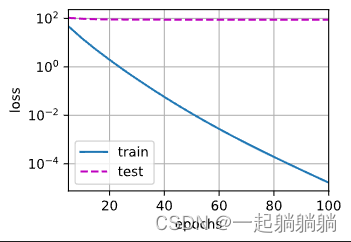
很明显,严重过拟合。
下面使用权重衰减。
train(lambd=3)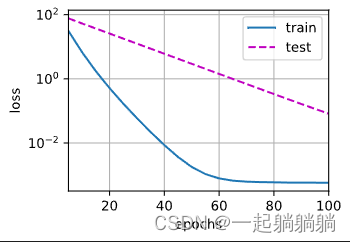
有明显的防止过拟合的效果。















 2841
2841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









