






前言
今天我们来聊聊selenium -- xpath定位方法,我们都知道selenium有八大定位策略分别是id、name、class name、tag name、link text、partial link text、xpath、css 。那么我们今天呢主要来讲讲八大定位策略中的xpath的定位方法,废话不多说我们直接开始吧。下面主要介绍一下xpath:
一、xpath基本定位用法
1.1 使用id定位 -- driver.find_element_by_xpath('//input[@id="kw"]')

1.2 使用class定位 -- driver.find_element_by_xpath('//input[@class="s_ipt"]')

1.3 当然 通过常用的8种方式结合xpath均可以定位(name、tag_name、link_text、partial_link_text)以上只列举了2种常用方式哦。
二、xpath相对路径/绝对路径定位
2.1 相对定位 -- 以// 开头 如://form//input[@name="phone"]

2.2 绝对定位 -- 以/ 开头,但是要从根目录开始,比较繁琐,一般不建议使用 如:/html/body/div/a

三、xpath文本、模糊、逻辑定位
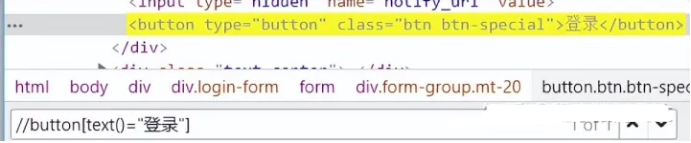
3.1【文本定位】使用text()元素的text内容 如://button[text()="登录"]
3.2 【模糊定位】使用contains() 包含函数 如://button[contains(text(),"登录")]、//button[contains(@class,"btn")] 除了contains不是=等于 多用于display属性

3.3 【模糊定位】使用starts-with -- 匹配以xx开头的属性值;ends-with -- 匹配以xx结尾的属性值 如://button[starts-with(@class,"btn")]、//input[ends-with(@class,"-special")]
3.4 使用逻辑运算符 -- and、or;如://input[@name="phone" and @datatype="m"]
四、xpath轴定位
4.1 轴运算
ancestor:祖先节点 包括父
parent:父节点
preceding-sibling:当前元素节点标签之前的所有兄弟节点
preceding:当前元素节点标签之前的所有节点
following-sibling:当前元素节点标签之后的所有兄弟节点
following:当前元素节点标签之后的所有节点
使用语法: 轴名称 :: 节点名称
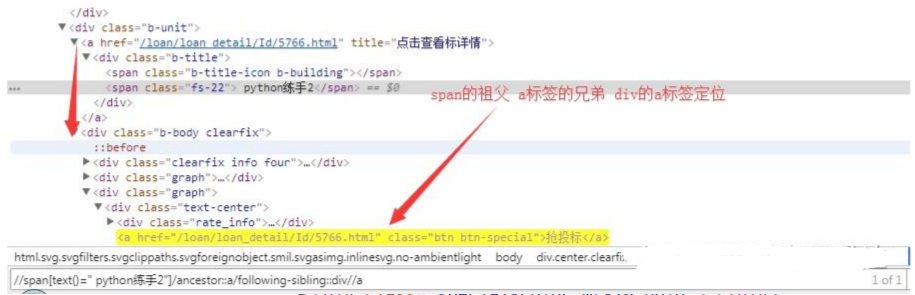
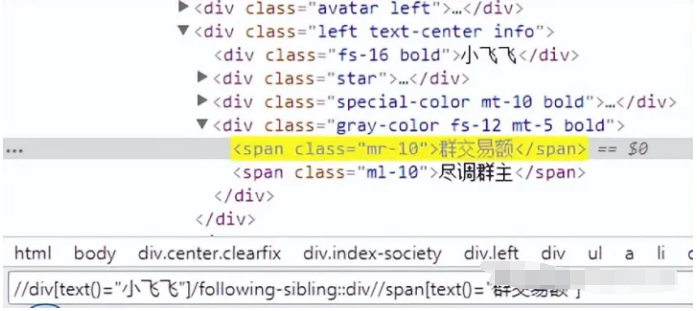
使用较多场景:页面显示为一个表格样式的数据列
如:
注意:
#定位 找到元素 -- 做到唯一识别
#优先使用id
#舍弃:有下标的出现、有绝对定位的出现、id动态变化时舍弃
from selenium import webdriver
import time
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")
driver.maximize_window()
time.sleep(3)
# 定位百度搜索框
driver.find_element_by_id("kw").send_keys("python")
time.sleep(3)
driver.find_element_by_id("su").click()
time.sleep(5)
# 找到这个元素
ele = driver.find_element_by_xpath('//a[text()="_百度百科"]')
# 拖动元素到可见区域--scrollIntoView() 拉到顶部显示,有可能会被导航栏遮挡,定位不到而报错;scrollIntoView(false)可视区域底部对齐
driver.execute_script("arguments[0].scrollIntoView(false);", ele)
time.sleep(5)
driver.quit()定位后的常见操作
get(url) 打开网页
send_keys(str) 输入
click() 点击
clear() 清空
text 获取标签文本内容
get_attribute('属性') 获取元素属性值
close() 关闭当前标签页
quit() 关闭浏览器,释放进程
FAQ
- 脚本结束如果没有调用quit()方法,chromedriver进程会在后台继续运行。大概占用4M空间。如果创建多了不关,会导致电脑卡。
__import__('os').system("taskkill /f /t /im chromedriver.exe")
最后:下面是配套学习资料,对于做【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!

软件测试面试小程序
被百万人刷爆的软件测试题库!!!谁用谁知道!!!全网最全面试刷题小程序,手机就可以刷题,地铁上公交上,卷起来!
涵盖以下这些面试题板块:
1、软件测试基础理论 ,2、web,app,接口功能测试 ,3、网络 ,4、数据库 ,5、linux
6、web,app,接口自动化 ,7、性能测试 ,8、编程基础,9、hr面试题 ,10、开放性测试题,11、安全测试,12、计算机基础

















 174
174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











