






学习像素级视频对应的细粒度特征。CVPR2023
目录
3.1. Fine-Grained Feature Learning
3.2. Efficient Fine-grained Probabilistic Mapping
Abstract
解决了建立像素级对应的特征学习问题。用带标签的合成视频+无标签的真实世界视频来学习细粒度表示。采用对抗性学习方案来增强学习特征的泛化能力。设计了一个由粗到细的框架,实现高效的细粒度概率映射。
1. Introduction
基本问题:学习跨空间和时间的视觉对应关系。根据粒度分为三类:第一类是对象级对应关系,存在于视频中粗略定位的边界框之间;第二类是组级对应关系,表示群体层面上的映射,通常应用于视频对象分割等下游任务;第三类是像素级对应关系,最细粒度的视频帧之间的像素级关系。
本文探讨了如何学习细粒度表示来满足像素级视频对应关系的需求。
首先研究了如何利用合成数据进行细粒度特征学习。具体而言,对于给定的查询像素,合成视频中的监督只提供一对一映射,即一个运动向量,表示像素与下一帧中的另一个像素的确定性对应关系。然而,像素级特征在空间和时间上演化缓慢,表明对应关系具有软分布。直接使用合成监督作为硬标签会导致较差的表示,并且学到的特征无法识别不同空间位置和时间段的像素级差异。为了解决这个问题,提出使用一个外部预训练的2D编码器根据光流推导软监督进行优化。
还将自我监督特征学习应用于无标签真实数据,以减轻真实场景中的泛化问题。首先,通过自我监督的重构学习,通过时序一致性假设学习时序持久特征,其中每个查询像素可以通过利用相邻帧中的信息进行重构。此外,给定合成和真实数据,通过引入梯度反转层和鉴别器进行对抗训练来学习对应关系。进一步增强学习到的细粒度特征。
获取细粒度特征之间的密集匹配结果需要更长的时间。因此,采用粗到细的框架来解决这个问题。将复杂的特征匹配放在粗粒度的特征图上,然后通过可学习的上采样层获得细粒度的结果。这样,在性能和效率之间取得了良好的平衡。总之,本文的主要贡献在于:
- 通过特征学习方法解决了建立像素级视频对应关系的问题。
- 提出了一种方法,从合成和无标签视频中学习细粒度特征,并设计了一个框架来提高效率。
- 在基于对应关系的任务中进行验证。准确性和效果方面都优于现有的最先进方法。
2. Related work
视频对应关系的表示学习。
最近的研究集中在以自我监督的方式学习无标签视频对应关系的密集表示,主要有两个不同的方向:基于重构的方法和基于循环一致性的技术。在第一类方法中,根据时间一致性假设,从相邻帧中重构查询像素,而第二类方法通过执行前后追踪来减少循环不一致性。此外,VFS提出了通过逐帧对比损失来学习表示的方法。SFC通过两个不同的模型,使用两个流结构来学习语义和细粒度特征,但无法准确识别空间和时间上的像素级差异=。
视频对应关系的光流估计。
利用合成图形数据进行监督训练的方法已经开始探索预测两帧之间每个像素的运动的光流估计问题。大多数方法使用成本体积来找到像素匹配。RAFT通过其多尺度相关性体积和迭代流细化脱颖而出,然而,使用合成计算机图形数据学习确定性模型限制了在真实视频中的泛化能力和鲁棒性。
自我监督学习的无监督域自适应。
通过利用无监督域自适应,来减少真实数据和合成数据之间的分布差异。一种有效的实现方式是通过对抗训练。最近的研究通过学习一个区分来自不同分布的学习特征的领域分类器(鉴别器),利用对抗性损失增加领域混淆。同时,自我监督学习通过设计不同的预训练任务和无标签数据获得令人印象深刻的性能,并展示出良好的泛化能力。
3. Approach
解决了估计一对视频帧之间逐像素对应关系的问题,通过学习用于匹配的细粒度特征来实现。目标:设计不同的学习目标函数,使编码器θ学习细粒度特征空间ϕ,来预测概率映射。
概率映射。给定一对视频帧 、
∈
,对于
中的所有像素,目标是预测概率映射
。其中
表示在有限范围r内 i 在帧
中映射到 j 的概率,这编码了 i 在帧
中的离散条件概率分布。
概率映射可以通过 使用学习到的细粒度特征计算特征相似性 来实现。首先提取稠密特征。然后,通过计算与每个键 j 在
中的局部窗口相关性来获取离散的概率映射:

K(i)是以 i 为中心的局部窗口中的索引集合,τ是温度。
3.1. Fine-Grained Feature Learning
细粒度特征学习。设计了用于 带有合成和真实世界视频的概率映射 的学习目标函数。
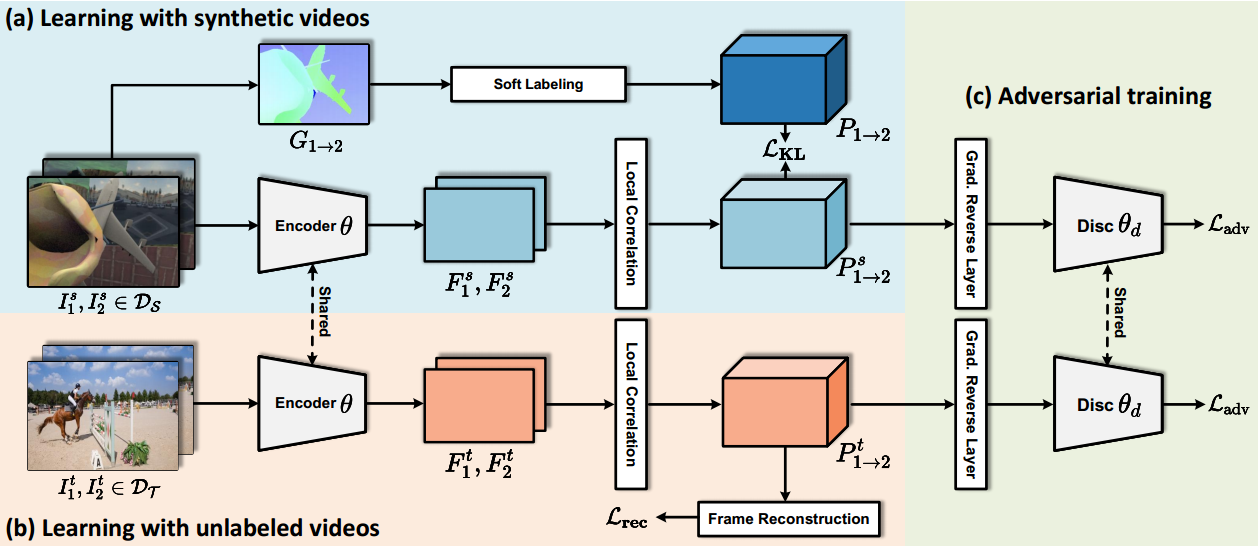
图2:细粒度特征学习框架概述。将无标签视频的自监督学习集成到有标签合成视频的监督学习中来促进细粒度的特征学习。对于合成数据DS的学习,设计了一个软标注模块,将运动向量表示的硬标注转换为软标注。为了学习更多可概括的特征,利用无标签视频DT的自由监督,目的是帧重建。此外,提出了对抗损失(以及梯度反向层和鉴别器)来促进域不变表示。
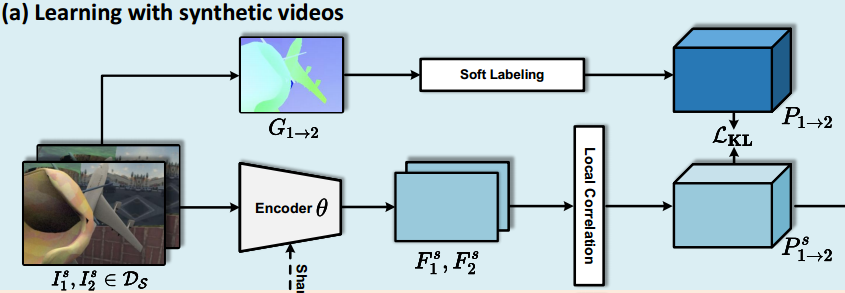
(a)用合成视频学习。给定一对渲染的视频帧 、
,合成数据
提供像素级运动向量,即光流
。真实世界的视频中很难获得确定性的对应关系,因此转换为软(概率)对应关系。本文设计了以下几个变体:
(i) Dirac分布:如图3(a)所示,直接将运动向量转换为Dirac分布,以描述真实映射。
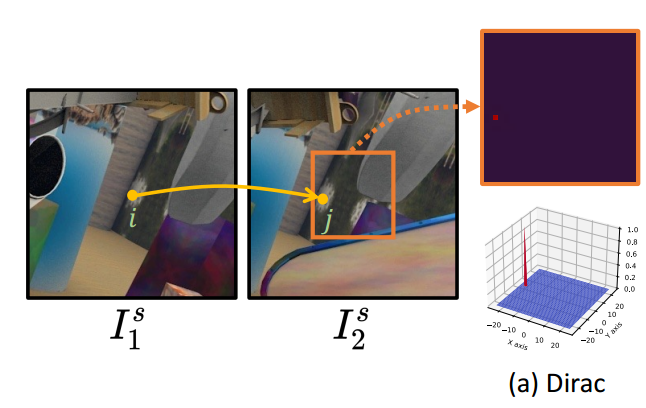
然后,定义了学习目标函数,即和
之间的Kullback-Leibler散度:
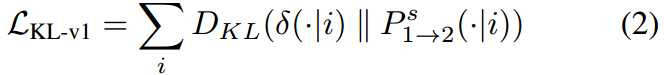
(ii) 高斯分布:查询像素 i 的特征在空间和时间上变化平滑,这表明潜在位置在下一帧中具有软分布。Dirac分布不提供任何关于背景中相对概率的知识,使得难以使用合成视频学习具有区分能力的特征来识别细粒度差异。因此设计了使用高斯分布生成概率映射的方法,其中引入了一个以真实坐标为中心的软分布:
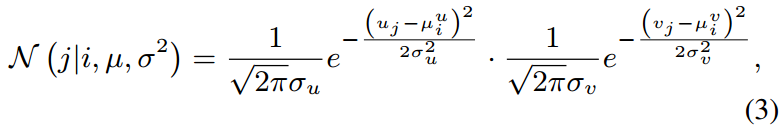
其中表示
中像素 i 的2D坐标,
表示j的2D坐标。定义损失函数为:

(iii) 软标签:高斯先验仅考虑坐标的欧氏距离,对于建模复杂分布的能力有限。合成监督已经提供了时间线索(即中的 i 移动到
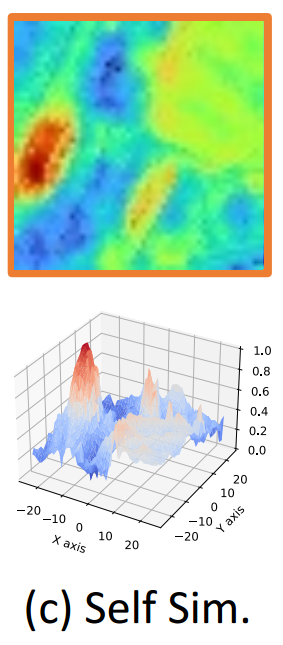
中的 j ),空间上的软分布可以通过使用预训练的2D视觉编码器θself计算 j 的自相似性来逼近。
如图3(c)所示,对于移动到 j 的 i ,获取查询 i 的特征(记为),该特征位于
(由θself计算的
的特征图)中的位置 j 。
然后计算和
之间的特征相似性
,其中K(i)是以 i 为中心的局部窗口中的索引集合。将
进一步归一化(通过softmax)以获得离散概率分布
:
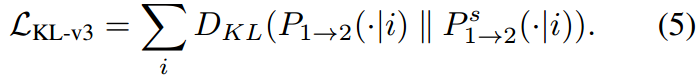
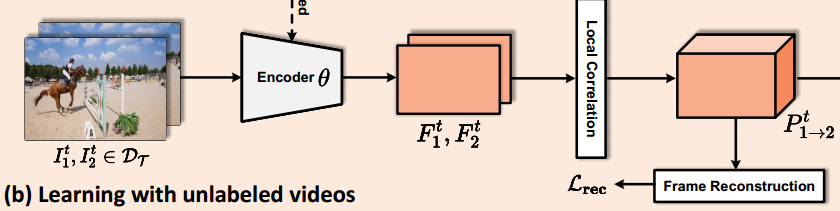
(b)用无标签视频学习。合成视频上学习到的特征往往泛化能力不足。通过引入自我监督特征学习来改进学习到的细粒度特征。像素重复,支持通过重构学习来学习细粒度特, 中的每个像素都可以利用
中的信息进行重构。为了实现这一点,首先通过编码器θ将视频帧
、
投影到像素嵌入
、
中,然后对于
中的每个查询 i ,用Eq.(1)计算其概率映射
。然后就可以通过K(i)中的像素加权和来重构
中的查询 i :

自监督训练的重构loss定义为 和
之间的L1距离。这样训练,可以获得 在真实场景中具有良好泛化性能的 时序持久特征。
然而像素重复不适用于被遮挡像素,因此从重构损失中排除了被遮挡的像素,以避免学习错误的特征。遵循前后一致性假设来检测被遮挡的像素,定义遮挡标志O1→2违反约束时为1,否则为0:
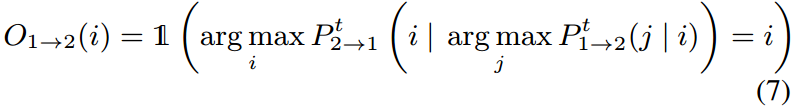
重构学习的损失定义如下: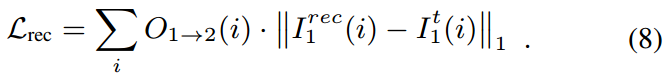
(遮挡标志二元值 x 重构值与真实值的L1距离)
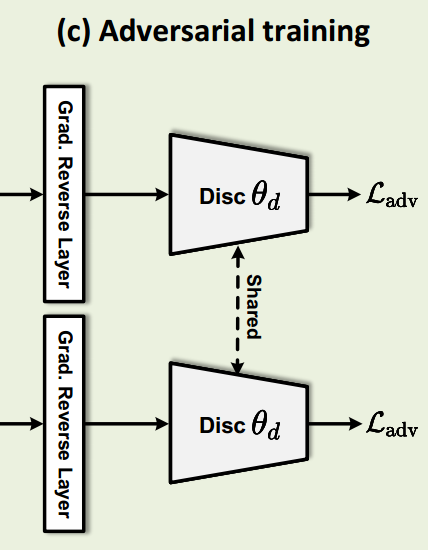
(c)对抗训练。旨在通过对抗训练来弥合合成视频DS和真实视频DT之间的域转移所造成的差距。方法:使用梯度反转层(GRL)。额外训练一个判别器θD,用于判断概率映射来自合成视频还是真实视频,并定义了对抗性训练的损失函数Ladv。

用Ladv更新编码器θ的参数时,在反向传播的过程中反转梯度方向:

GRL允许同时训练判别器和编码器,并且对抗性训练有助于学习域不变模式。
总体训练目标。学习细粒度特征的总体训练目标被表述为一个多任务损失:
每个损失视为同等重要。
3.2. Efficient Fine-grained Probabilistic Mapping
高效的细粒度概率映射 。为了获得细粒度的概率映射,需要计算与局部窗口中每个查询像素的所有关键像素的相似性,计算昂贵。本节设计了一个粗到细的框架。如图4所示,首先在粗粒度特征上计算相关性,然后上采样以获得细粒度的概率映射。
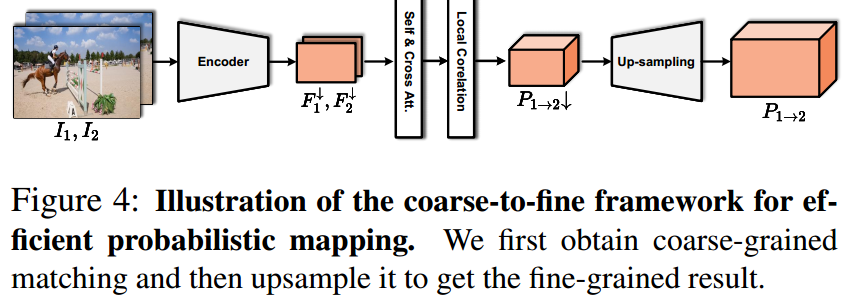
图4:首先得到粗粒度匹配,然后上采样得到细粒度匹配结果。
自注意力和交叉注意力层。首先提取粗粒度特征图![]() ,并通过引入自注意力和交叉注意力层与位置编码来增强粗粒度特征。然后,通过公式(1)计算得到粗粒度的概率映射
,并通过引入自注意力和交叉注意力层与位置编码来增强粗粒度特征。然后,通过公式(1)计算得到粗粒度的概率映射![]()
![]() 。
。
上采样。设计了一个上采样层,用于获得细粒度的概率映射,可以通过像素混洗或使用双线性插值的卷积层来实现。
4. Experiments
4.1. 实现细节
主干网络。用ResNet18作为编码器θ。将步幅减小到res4层以获得1/2原始图像尺寸的特征用于训练。在粗到细框架中,将编码器的步幅增加到8,用于粗粒度特征匹配。
训练细节。在合成数据集FlyingThings和收集自真实世界的YouTube-VOS的训练集上进行。采样一对帧,将其调整为256×256大小,并用通道级的dropout将其转换为Lab颜色空间作为信息瓶颈。概率映射中的局部范围r设置为24/6,用于细粒度特征(h^2 × w^2(步长=2))或粗粒度特征(h^8 × w^8(步长=8))。首先使用重构损失(公式(8))在FlyingThings上对编码器进行训练,批大小为32,训练30个epoch,然后将其作为软标签中的θself进一步利用。然后,使用提出的三种损失共同训练最终模型θ,每个数据集的批大小为16,共训练30个epoch。在使用合成光流进行训练时,通过前后检查过滤掉超出局部范围或被遮挡的点。τ设置为1。使用Adam作为优化器,初始学习率为1e-3,并使用余弦(半周期)学习率调度表对每个阶段进行学习率衰减。
评估。在没有任何微调的情况下,直接利用预训练的编码器θ提取带有空间分辨率h/s × w/s(s表示编码器的步幅)的特征Fi、Fj,用于计算通过公式(1)得到的概率映射Pi→j。基于概率映射Pi→j,采用循环推理策略,将第一帧的目标点或语义标签以及先前的预测传播到当前帧 It。
4.2. 点追踪结果
首先对点追踪进行比较,因为它需要对学习到的特征进行最精细的粒度划分。
BADJA/JHMDB上的结果。用PCK作为评估指标。如果每个点与真实位置的距离在0.1√ A之内,其中A是关键点之间的距离(对于JHMDB)或帧上地面真值分割掩模的面积(对于BADJA),则该点被认为是正确的。在表1中,我们的方法达到了67.2%/66.8%的准确率,超过了所有最先进的方法。此外,我们的粗粒度到细粒度设计相对于MAST仍然有1.1%和2.2%的绝对改进。与使用双流网络寻找对应关系的SFC相比,显示出更好的效率。
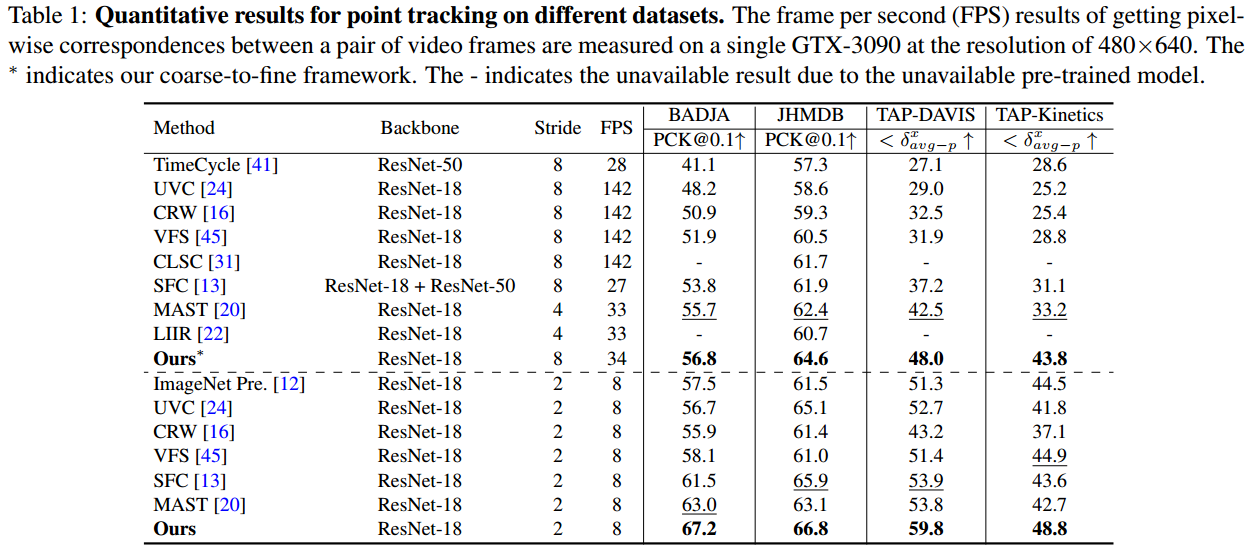
TAP-Vid上的结果。在整个TAP-Vid-DAVIS数据集和TAP-Vid-Kinetics的测试集上进行测试。采用TAP-vid中的“first fashion”设置,仅追踪未来。所有可见点()的平均位置准确性被采用作为评估指标。学习到的细粒度特征在TAP-Vid-DAVIS/TAP-Vid-Kinetics上分别达到了59.8%/48.8%的准确率,相对于最先进的方法明显改进了5.9%/3.9%。此外,提出的粗粒度到细粒度框架分别达到了48.0%/43.8%的准确率,超过MAST 5.5%/10.6%。
与特定任务方法的比较。专门用于点追踪的方法如RAFT、PIPs 、TAPNet和Thin-Slicing Net是使用人工注释进行训练。表2中进行了性能比较。
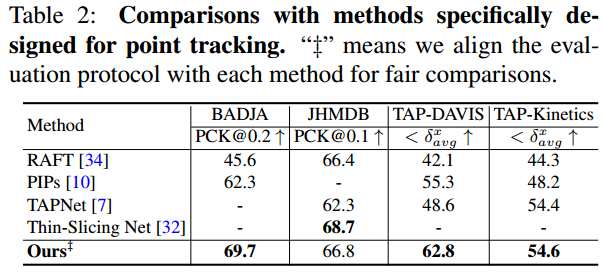
为了使评估与这些方法保持一致,除JHMDB之外,首先计算每个视频的或PCK,以获得视频级结果,然后对所有视频取平均来获得最终结果。我们的性能甚至超过了BADJA/TAP-DAVIS/TAP-Kinetics上这些方法的7.4%/7.5%/0.2%。

图5:在TAP-Vid-DAVIS上进行的点追踪的可视化结果。给定第一帧中的目标,使用粉色到黄色的映射来可视化估计的轨迹。与VFS、MAST和RAFT相比,即使面临剧烈的外观变化和形变,我们的方法可以输出更平滑、更准确的轨迹,接近于稀疏可视化的真实轨迹。
4.3. 视频对象分割结果
评估半监督视频对象分割方法。使用区域相似性Jm的均值、轮廓准确性Fm的均值以及它们的平均值J&Fm作为评估指标。
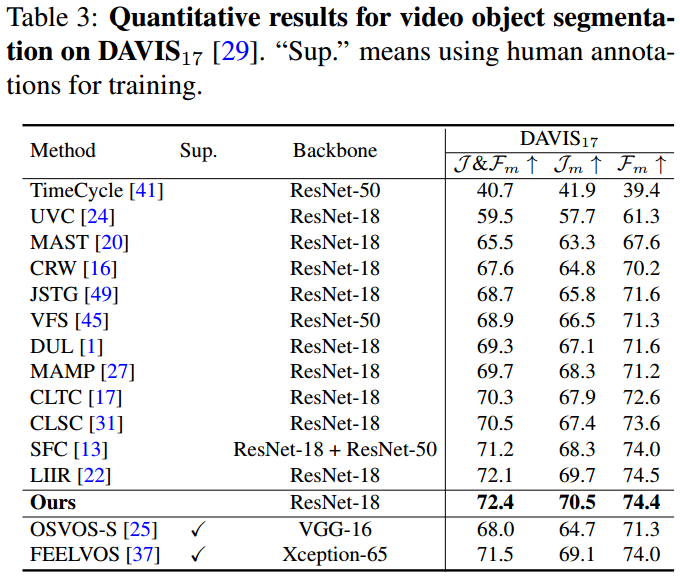
表3:DAVIS17上视频对象分割的定量结果。" Sup. "的意思是使用人工注释进行训练。

图6:视频对象分割的定性结果。给定第一帧的语义掩码,显示目标帧上的传播结果。
我们的方法在目标区域周围产生了紧密的边界,并获得了更细粒度的结果,尤其是对于小型物体。例如,在图6的第一列中,人的小臂仍然可以被分割出来,这进一步证明了学习视频对应关系的细粒度特征的优势。
然而,我们发现,细粒度特征可能会阻碍以对象为中心的特征学习,因为它可能更依赖于低层次的模式(如纹理、颜色等),这在一定程度上降低了视频对象分割的性能。这视为未来的工作方向。
4.4. 消融实验
在TAP-Vid-DAVIS [7]数据集上进行了点追踪的割除研究。
用合成视频学习。研究使用Eq. (2)、Eq. (4)和Eq. (5)中定义的三种不同方式来学习合成视频的细粒度特征的效果。表4显示了这三种目标函数之间的性能比较。
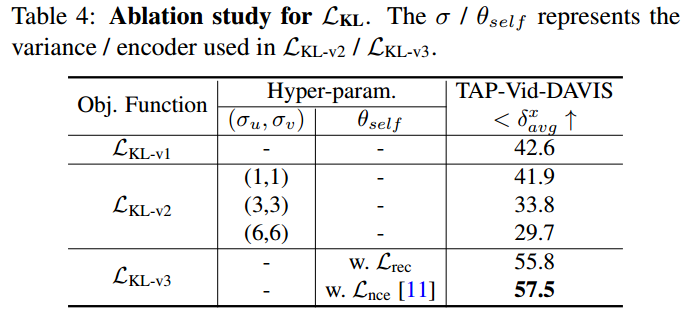
用dirac分布生成标签的loss LKL-v1性能较差。我们认为合成视频上给定了确定性标签,导致学到的特征在真实世界视频上不够稳健。
发现在LKL-v2中引入高斯分布会导致性能下降。当逐渐增加方差时,性能大幅下降,这可能是因为高斯分布无法逼近真实的概率分布,因为真实分布非常复杂。
仅通过使用Eq. (8)对θself进行预训练,所提出的软标签将性能从42.6%提升到55.8%。
此外尝试了在ImageNet上使用对比损失Lnce预训练的另一个2D编码器,它具有更强的捕捉空间差异特征的能力。结果进一步提高到了57.5%,这激励我们利用一个更强大的2D特征提取器来获得软标签。
不同的训练目标函数。
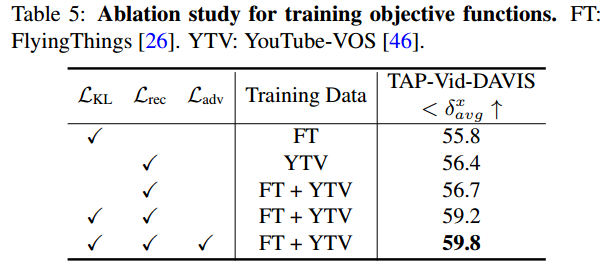
LKL、Lrec和Ladv表示Eq. (5)、Eq. (8)和Eq. (9)中定义的损失。
使用Lrec在未标记的真实世界视频上训练的模型获得了更好的结果,这表明自监督特征学习具有更好的泛化能力。通过同时利用合成和真实世界视频的LKL和Lrec,性能进一步提高到59.2%。使用Ladv来解决域不匹配问题可以提高0.6%的性能。通过融合这三个损失,性能达到了59.8%。
结果一致表明,与仅使用合成数据训练的模型相比,将自我监督和对抗性训练与未标记数据结合在一起显示出性能提升。
5. Conclusions
本文通过学习细粒度特征,解决像素级视频对应关系问题。提出利用未标记的真实世界视频进行特征学习。
1.首先研究了如何利用合成监督来进行特征学习,并发现直接利用运动向量会导致学到的特征退化。因此提出了软标签来解决这个问题。
2.为了改善泛化能力,引入了自监督重构学习,并通过对抗性训练进一步增强特征。
3.提出了一个粗粒度到细粒度的框架来缓解计算效率的问题。在下游任务上进行大量实验证明了所提出的特征学习方法和高效设计的有效性。















 909
909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









