










代码:KwaiVGI/LivePortrait: Make one portrait alive! (github.com)
介绍
动机:基于扩散的方法计算成本高,并且缺乏精确的可控制性。因此作者探索并扩展了基于隐式关键点的视频驱动框架,平衡了泛化性、计算效率和可控性。
训练数据为6900万高质量帧,采用混合图像-视频训练策略,升级网络架构,并设计了更好的运动变换和优化目标。此外,我们发现紧凑的隐式关键点可以有效地表示一种混合形状,并提出了拼接和两个重定向模块,这些模块利用一个具有可忽略计算开销的小型MLP,以增强可控性。
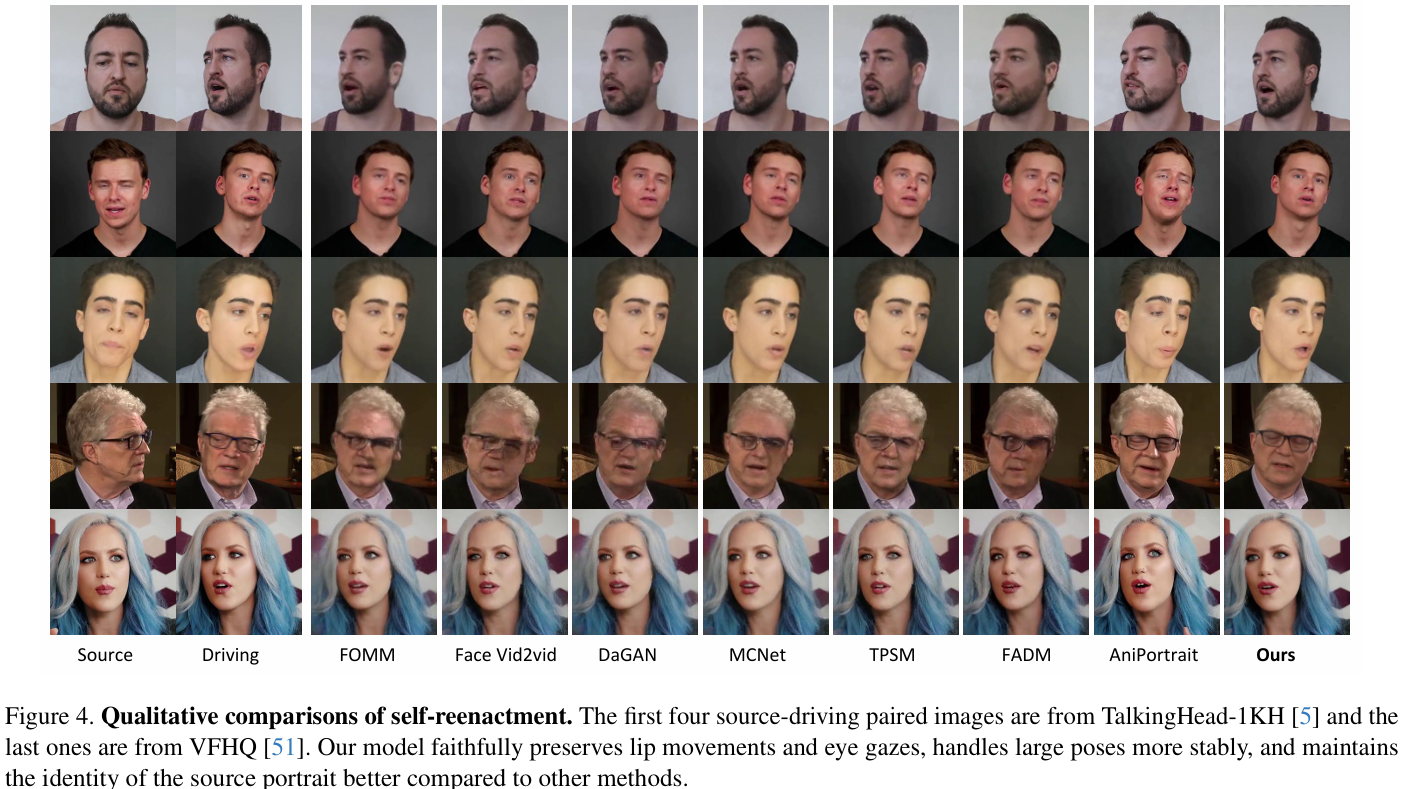
图1,定性肖像动画结果。给定静态肖像图像作为输入,模型可以生动地使其动画化,确保无缝拼接并提供对眼睛和嘴唇运动的精确控制。

原理

作者选择face vid2vid作为基本模型。改进包括:高质量的数据管理、混合图像和视频训练策略、升级的网络架构、可扩展的运动转换、地标引导的隐式关键点优化和级联损失项。这些改进大大提高了动画的表现力和模型的泛化能力。
第一阶段:基础模型训练
第一个训练阶段的pipeline如图2所示,基础模型训练,优化了外观和运动提取器F和M、翘曲模块W和解码器G。
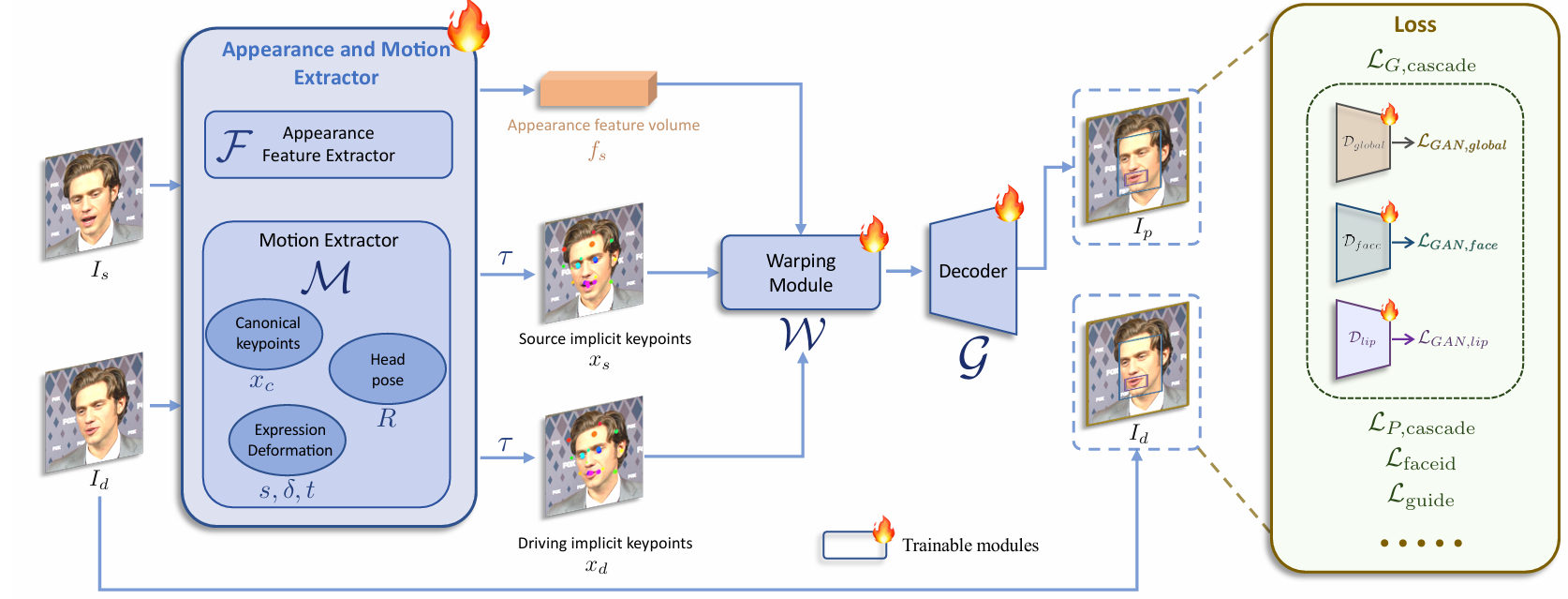
混合图像和视频训练。仅在逼真人像视频上训练的模型在人像方面表现良好,但在风格化人像(如动漫)上的泛化能力较差。风格化人像视频稀缺,我们仅收集了大约1300个来自不到100个身份的视频剪辑。相比之下,高质量的风格化人像图像更为丰富;我们收集了大约6万张图像,每张图像代表一个独特的身份,提供了多样的身份信息。为了利用这两种数据类型,我们将单一图像视为一帧视频剪辑,并在图像和视频上训练模型。这种混合训练提高了模型的泛化能力。
升级的网络架构。将原始的规范隐式关键点检测器L、头部姿态估计网络H和表情变形估计网络∆统一为一个单一的模型M,使用ConvNeXt-V2-Tiny作为骨干网络,直接预测输入图像的规范关键点、头部姿态和表情变形。此外,我们按照[43]使用SPADE解码器作为生成器G,这比face vid2vid中的原始解码器更强大。扭曲特征体积 𝑓𝑠fs 被精细地馈送到SPADE解码器中,特征体积的每个通道作为语义图用于生成动画图像。为了提高效率,我们在G的最后一层插入了一个PixelShuffle层,将分辨率从256×256上采样到512×512。
可扩展的运动变换。原始的隐式关键点变换在公式1中忽略了缩放因子,这往往将缩放纳入表情变形中,增加了训练难度。为了解决这个问题,我们在运动变换中引入了缩放因子,更新后的变换τ的公式如下:
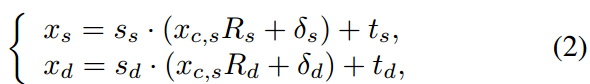
基于标志点的隐式关键点优化。原始的 face vid2vid [5, 43] 似乎缺乏生动驱动面部表情(如眨眼和眼球运动)的能力。尤其是,生成的人像的眼睛注视方向受头部姿态限制,并与其保持平行,这一局限性在我们的复现实验中也有所观察。
我们将这些局限性归因于无监督学习中学习细微面部表情(如眼球运动)的困难。为了解决这个问题,我们引入了捕捉微表情的2D标志点,使用它们作为指导来优化隐式关键点的学习。标志点指导损失 𝐿guide 的公式如下:

其中,𝑁 是所选标志点的数量,𝑙𝑖li 是第 𝑖i 个标志点,𝑥𝑠,𝑖,:2 和 𝑥𝑑,𝑖,:2 分别代表对应隐式关键点的前两个维度,并且采用 Wing 损失函数[46]。在我们的实验中,𝑁 设置为10,选取的标志点来自眼睛和嘴唇。
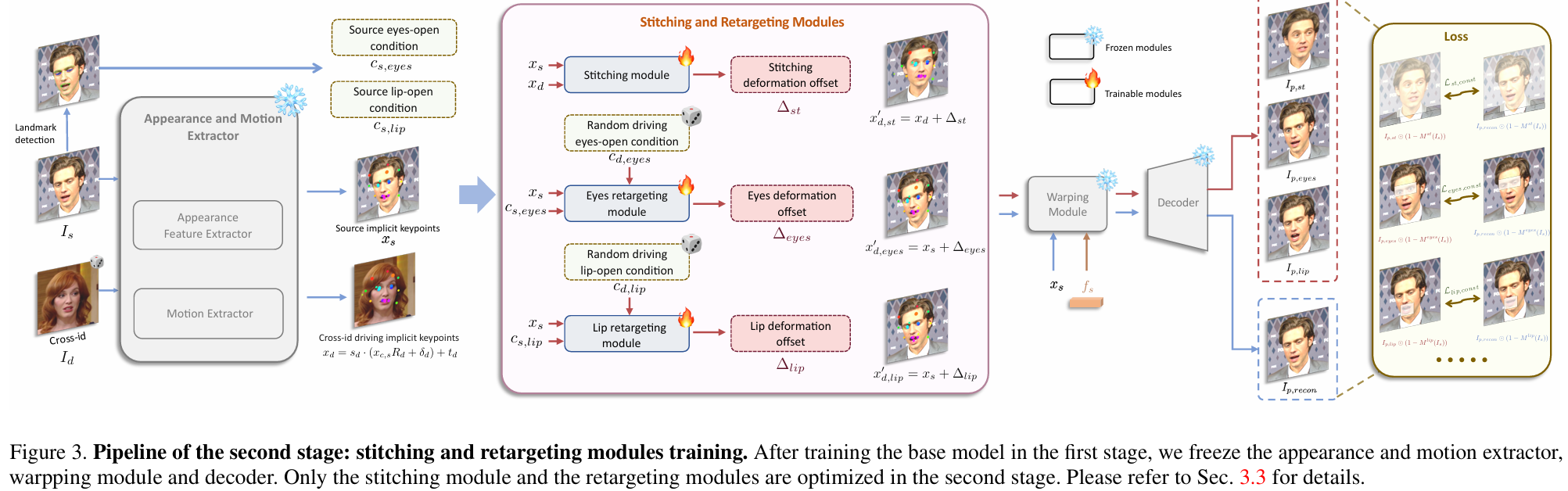
第二阶段:缝合和重定位
在第一阶段对基础模型进行训练后,我们冻结了外观和运动提取器、翘曲模块和解码器。在第二阶段只对拼接模块和重定向模块进行优化。




















 158
158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









