






一、数据集(150)
具体数据如下(如果不能运行,尝试在末尾加回车)
5.1 3.5 1.4 0.2 1
4.9 3 1.4 0.2 1
4.7 3.2 1.3 0.2 1
4.6 3.1 1.5 0.2 1
5 3.6 1.4 0.2 1
5.4 3.9 1.7 0.4 1
4.6 3.4 1.4 0.3 1
5 3.4 1.5 0.2 1
4.4 2.9 1.4 0.2 1
4.9 3.1 1.5 0.1 1
5.4 3.7 1.5 0.2 1
4.8 3.4 1.6 0.2 1
4.8 3 1.4 0.1 1
4.3 3 1.1 0.1 1
5.8 4 1.2 0.2 1
5.7 4.4 1.5 0.4 1
5.4 3.9 1.3 0.4 1
5.1 3.5 1.4 0.3 1
5.7 3.8 1.7 0.3 1
5.1 3.8 1.5 0.3 1
5.4 3.4 1.7 0.2 1
5.1 3.7 1.5 0.4 1
4.6 3.6 1 0.2 1
5.1 3.3 1.7 0.5 1
4.8 3.4 1.9 0.2 1
5 3 1.6 0.2 1
5 3.4 1.6 0.4 1
5.2 3.5 1.5 0.2 1
5.2 3.4 1.4 0.2 1
4.7 3.2 1.6 0.2 1
4.8 3.1 1.6 0.2 1
5.4 3.4 1.5 0.4 1
5.2 4.1 1.5 0.1 1
5.5 4.2 1.4 0.2 1
4.9 3.1 1.5 0.1 1
5 3.2 1.2 0.2 1
5.5 3.5 1.3 0.2 1
4.9 3.1 1.5 0.1 1
4.4 3 1.3 0.2 1
5.1 3.4 1.5 0.2 1
5 3.5 1.3 0.3 1
4.5 2.3 1.3 0.3 1
4.4 3.2 1.3 0.2 1
5 3.5 1.6 0.6 1
5.1 3.8 1.9 0.4 1
4.8 3 1.4 0.3 1
5.1 3.8 1.6 0.2 1
4.6 3.2 1.4 0.2 1
5.3 3.7 1.5 0.2 1
5 3.3 1.4 0.2 1
7 3.2 4.7 1.4 2
6.4 3.2 4.5 1.5 2
6.9 3.1 4.9 1.5 2
5.5 2.3 4 1.3 2
6.5 2.8 4.6 1.5 2
5.7 2.8 4.5 1.3 2
6.3 3.3 4.7 1.6 2
4.9 2.4 3.3 1 2
6.6 2.9 4.6 1.3 2
5.2 2.7 3.9 1.4 2
5 2 3.5 1 2
5.9 3 4.2 1.5 2
6 2.2 4 1 2
6.1 2.9 4.7 1.4 2
5.6 2.9 3.6 1.3 2
6.7 3.1 4.4 1.4 2
5.6 3 4.5 1.5 2
5.8 2.7 4.1 1 2
6.2 2.2 4.5 1.5 2
5.6 2.5 3.9 1.1 2
5.9 3.2 4.8 1.8 2
6.1 2.8 4 1.3 2
6.3 2.5 4.9 1.5 2
6.1 2.8 4.7 1.2 2
6.4 2.9 4.3 1.3 2
6.6 3 4.4 1.4 2
6.8 2.8 4.8 1.4 2
6.7 3 5 1.7 2
6 2.9 4.5 1.5 2
5.7 2.6 3.5 1 2
5.5 2.4 3.8 1.1 2
5.5 2.4 3.7 1 2
5.8 2.7 3.9 1.2 2
6 2.7 5.1 1.6 2
5.4 3 4.5 1.5 2
6 3.4 4.5 1.6 2
6.7 3.1 4.7 1.5 2
6.3 2.3 4.4 1.3 2
5.6 3 4.1 1.3 2
5.5 2.5 4 1.3 2
5.5 2.6 4.4 1.2 2
6.1 3 4.6 1.4 2
5.8 2.6 4 1.2 2
5 2.3 3.3 1 2
5.6 2.7 4.2 1.3 2
5.7 3 4.2 1.2 2
5.7 2.9 4.2 1.3 2
6.2 2.9 4.3 1.3 2
5.1 2.5 3 1.1 2
5.7 2.8 4.1 1.3 2
6.3 3.3 6 2.5 3
5.8 2.7 5.1 1.9 3
7.1 3 5.9 2.1 3
6.3 2.9 5.6 1.8 3
6.5 3 5.8 2.2 3
7.6 3 6.6 2.1 3
4.9 2.5 4.5 1.7 3
7.3 2.9 6.3 1.8 3
6.7 2.5 5.8 1.8 3
7.2 3.6 6.1 2.5 3
6.5 3.2 5.1 2 3
6.4 2.7 5.3 1.9 3
6.8 3 5.5 2.1 3
5.7 2.5 5 2 3
5.8 2.8 5.1 2.4 3
6.4 3.2 5.3 2.3 3
6.5 3 5.5 1.8 3
7.7 3.8 6.7 2.2 3
7.7 2.6 6.9 2.3 3
6 2.2 5 1.5 3
6.9 3.2 5.7 2.3 3
5.6 2.8 4.9 2 3
7.7 2.8 6.7 2 3
6.3 2.7 4.9 1.8 3
6.7 3.3 5.7 2.1 3
7.2 3.2 6 1.8 3
6.2 2.8 4.8 1.8 3
6.1 3 4.9 1.8 3
6.4 2.8 5.6 2.1 3
7.2 3 5.8 1.6 3
7.4 2.8 6.1 1.9 3
7.9 3.8 6.4 2 3
6.4 2.8 5.6 2.2 3
6.3 2.8 5.1 1.5 3
6.1 2.6 5.6 1.4 3
7.7 3 6.1 2.3 3
6.3 3.4 5.6 2.4 3
6.4 3.1 5.5 1.8 3
6 3 4.8 1.8 3
6.9 3.1 5.4 2.1 3
6.7 3.1 5.6 2.4 3
6.9 3.1 5.1 2.3 3
5.8 2.7 5.1 1.9 3
6.8 3.2 5.9 2.3 3
6.7 3.3 5.7 2.5 3
6.7 3 5.2 2.3 3
6.3 2.5 5 1.9 3
6.5 3 5.2 2 3
6.2 3.4 5.4 2.3 3
5.9 3 5.1 1.8 3
二、代码
import math # 数学
import random # 随机
def sigmoid(x):
return 1 / (1 + math.exp(-x))
def BP(x1, y, by, b, xb, c, u_1, u_2, t):
e_h = [0, 0, 0, 0] # 储存b的梯度eh
g_j = [0, 0, 0] # 储存y的梯度gj
for n in range(c): # 循环:c次
for i in range(len(x1[0])): # 对每个样例
# 重置变量
b_a = [0, 0, 0, 0] # 储存b的输入αh
b_h = [0, 0, 0, 0] # 储存b的输出bh
y_b = [0, 0, 0] # 储存y的输入βj
y_j = [0, 0, 0] # 储存y的输出yj
for j in range(len(b)): # 每个隐藏层节点
for k in range(len(x1) - 1): # 每个属性
b_a[j] += x1[k][i] * xb[k][j] # 计算出所有的b_a(隐藏层的输入)
b_h[j] = sigmoid(b_a[j] - b[j]) # 激活(隐藏层的输出)
for k in range(len(y)): # 每个输出节点
y_b[k] += b_h[j] * by[k][j] # 输出层的输入
for j in range(len(y)): # 每个输出节点
y_j[j] = sigmoid(y_b[j] - y[j]) # 激活(输出层的输出)
g_j[j] = y_j[j] * (1 - y_j[j]) * (x1[4][i][j] - y_j[j]) # 计算输出层梯度
for j in range(len(b)): # 每个隐藏层节点
e = 0 # 初始化e
for k in range(len(y)): # 每个输出节点
e += g_j[k] * by[k][j]
e_h[j] = b_h[j] * (1 - b_h[j]) * e # 计算隐藏层梯度
for j in range(len(b)): # 每个隐藏层节点
for k in range(len(x1) - 1): # 每个属性
xb[k][j] += u_1 * e_h[j] * x1[k][i] # 更新输入到隐层
for k in range(len(y)): # 每个输出节点
by[k][j] += u_2 * g_j[k] * b_h[j] # 更新隐层到输出
b[j] += -u_1 * e_h[j] # 更新隐藏层阈值
for j in range(len(y)): # 每个输出节点
y[j] += -u_2 * g_j[j] # 更新输出层阈值
if n % t == 0: # 计算当前误差
print('第', n, '轮,误差为:', ceshi(x1, y, by, b, xb), '%')
def ceshi(x1, y, by, b, xb):
sum = 0 # 错误输出数
for i in range(len(x1[0])): # 对每个样例
# 重置变量
b_a = [0, 0, 0, 0] # 储存b的输入αh
b_h = [0, 0, 0, 0] # 储存b的输出bh
y_b = [0, 0, 0] # 储存y的输入βj
y_j = [0, 0, 0] # 储存y的输出yj
for j in range(len(b)): # 每个隐藏层节点
for k in range(len(x1) - 1): # 每个属性
b_a[j] += x1[k][i] * xb[k][j] # 计算出所有的b_a(隐藏层的输入)
b_h[j] = sigmoid(b_a[j] - b[j]) # 激活(隐藏层的输出)
for k in range(len(y)): # 每个输出节点
y_b[k] += b_h[j] * by[k][j] # 输出层的输入
for j in range(len(y)): # 每个输出节点
y_j[j] = sigmoid(y_b[j] - y[j]) # 激活(输出层的输出)
if x1[4][i][y_j.index(max(y_j))] == 0: # 输出向量最大的数下标对应在x0中不为1
sum += 1; # 错误数+1
return (sum / len(x1[0])) * 100
# 主函数=======================================================
f = open('Iris.txt', 'r') # 读文件
x = [[], [], [], [], []] # 花朵属性,(0,1,2,3),花朵种类
while 1:
yihang = f.readline() # 读一行
if len(yihang) <= 1: # 读到末尾结束
break
fenkai = yihang.split('\t') # 按\t分开
for i in range(4): # 分开的四个值
x[i].append(eval(fenkai[i])) # 化为数字加到x中
if (eval(fenkai[4]) == 1): # 将标签化为向量形式
x[4].append([1, 0, 0])
else:
if (eval(fenkai[4]) == 2):
x[4].append([0, 1, 0])
else:
x[4].append([0, 0, 1])
print('\n数据集=======================================================')
print(len(x[0])) # 数据大小
for i in range(len(x)):
print(x[i])
x1 = x[:]
print('\n\n全训练BP神经网络==============================================')
cycles = 1000 # 循环次数
u1 = 0.1 # 学习率输入到隐层
u2 = 0.1 # 学习率隐层到输出
t = 100 # t轮计算一次当前误差
y = [] # 输出层阈值
by = [[], [], []] # 隐藏层到输出层权值
b = [] # 隐藏层阈值
xb = [[], [], [], []] # 输入层到隐藏层权值
# 随机化阈值权值开始========================
for i in range(4): # 隐藏层节点4个
b.append(random.random()) # 隐藏层阈值
for j in range(3): # 隐藏层到3个输出层节点
by[j].append(random.random()) # 隐藏层到输出层权值
for j in range(4): # 4个输入层节点到隐藏层
xb[i].append(random.random()) # 输入层到隐藏层权值
for i in range(3): # 输出层节点3个
y.append(random.random()) # 输出层阈值
# 随机化阈值权值完成========================
l = list(range(150)) # 得到一个顺序序列
random.shuffle(l) # 打乱序列
x1 = [[], [], [], [], []] #初始化
for i in l: # 训练集
for j in range(len(x)): # D属性遍历
x1[j].append(x[j][i]) # D的属性加到x1上
BP(x1, y, by, b, xb, cycles, u1, u2, t) # 开始训练
print('\n全训练BP神经网络在训练集误差率:', ceshi(x1, y, by, b, xb), '%')
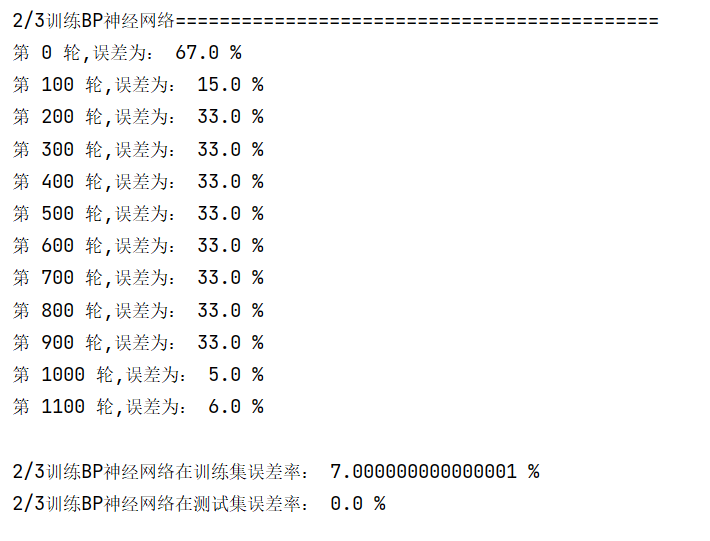
print('\n\n2/3训练BP神经网络============================================')
cycles = 1200 # 循环次数
u1 = 0.01 # 学习率输入到隐层
u2 = 0.01 # 学习率隐层到输出
t = 100 # t轮计算一次当前误差
y = [] # 输出层阈值
by = [[], [], []] # 隐藏层到输出层权值
b = [] # 隐藏层阈值
xb = [[], [], [], []] # 输入层到隐藏层权值
# 随机化阈值权值开始========================
for i in range(4): # 隐藏层节点4个
b.append(random.random()) # 隐藏层阈值
for j in range(3): # 隐藏层到3个输出层节点
by[j].append(random.random()) # 隐藏层到输出层权值
for j in range(4): # 4个输入层节点到隐藏层
xb[i].append(random.random()) # 输入层到隐藏层权值
for i in range(3): # 输出层节点3个
y.append(random.random()) # 输出层阈值
# 随机化阈值权值完成========================
l = list(range(150)) # 得到一个顺序序列
random.shuffle(l) # 打乱序列
x1 = [[], [], [], [], []] #初始化x1
x2 = [[], [], [], [], []] #初始化x2
for i in l[0:100]: # 截取部分训练集
for j in range(len(x)): # D属性遍历
x1[j].append(x[j][i]) # D的属性加到v1上
for i in l[100:150]: # 截取部分训练集
for j in range(len(x)): # D属性遍历
x2[j].append(x[j][i]) # D的属性加到v1上
BP(x1, y, by, b, xb, cycles, u1, u2, t) # 开始训练
print('\n2/3训练BP神经网络在训练集误差率:', ceshi(x1, y, by, b, xb), '%')
print('2/3训练BP神经网络在测试集误差率:', ceshi(x2, y, by, b, xb), '%')
三、结果及分析
由于随机选取数据,训练误差可能不一样


训练结果具有偶然性,可以考虑在每轮训练前都对训练集进行随机处理,使得结果更具有统计学意义。
由于初始权值阈值都随机取得,为避免陷入局部最优解,可以考虑训练多个模型,将每次训练结果保存下来,最后取最优模型。
全训练误差率经常在2%徘徊,可以考虑是否为学习率过大,使得取值在最优质附近震荡,可以尝试更改学习率。为避免步长过小,训练轮数过多,可以考虑将学习率于训练轮数相关,开始较大,随训练轮数逐渐减少。
此次训练有大量冗余运算,可以考虑将训练结束条件由轮数改为误差率,在误差小于某个值后停止训练。
可以看出BP算法容易过拟合,训练集上效果好不一定测试集上效果同样好,可以考虑增加训练停止条件,在测试集误差率上升时提前停止训练。
此结果为多次训练取结果较好者。若你的训练结果误差率较高(高于10%),可以尝试更改代码中的循环次数和学习率,重新训练。期待你能尝试出更好的训练次数以及学习率。
其他训练结果:
















 1615
1615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









