






因为AdelaiDet和detectron2这两个库都是基于Linux系统的,要改在win上运行老费事了,网上虽然有一点教程,但有很多零碎修改的地方,比如将Linux才有的系统文件改为win上的。这里就直接贴几个修改教程网址,
Win10编译Detectron2和TensorMask - 知乎
Windows安装AdelaiDet的血与泪_adelaidet教程-CSDN博客
windows10+detectron2完美安装教程_detectron2安装-CSDN博客
基于Detectron2的BlendMask训练 BlendMask环境配置 COCO数据集_no module named 'detectron2-CSDN博客
自己要能运行它的demo就问题不大。
数据集
使用COCO2017数据集,但只保留人的图片和人实例,用下面代码来对数据集进行类别过滤。:
# 这个文件是用来从原始的COCO数据集中提取出仅关于“人”的标注
# 就是生成训练集,测试集用的,正式使用时不会用到。
# ps:后来将=anaconda3环境名称从detectron2改为了Ai_AdelaiDet,但那时已经生成过数据集了,所以就没改
import json
import os
import shutil
from pycocotools.coco import COCO
import time
start = time.perf_counter() # 记录开始时间
# 输入
# 加载COCO数据集的标注
coco_root = 'C:/Users/86135/anaconda3/envs/detectron2/Lib/site-packages/AdelaiDet-master/datasets/coco/' # 这是我解压的数据集路径
dataType = 'train2017' # 训练集
# dataType = 'val2017' # 验证集
# 拼接出文件路径,annotations是标注文件夹名,
annotations_input = os.path.join(coco_root, 'annotations', 'instances_{}.json'.format(dataType))
# 输出
# 设置输出目录
output_dir = 'C:/Users/86135/anaconda3/envs/detectron2/Lib/site-packages/AdelaiDet-master/datasets/coco_person/'
annotations_output = os.path.join(output_dir, 'annotations', 'instances_{}.json'.format(dataType))
images_output = os.path.join(output_dir, dataType) # 就不变文件名字了
# 确保输出目录存在
os.makedirs(os.path.join(output_dir, 'annotations'), exist_ok=True)
os.makedirs(images_output, exist_ok=True)
# 开始
images_input = os.path.join(coco_root, dataType) # 图片
coco = COCO(annotations_input) # 创建COCO数据集实例
filtered_annotations = {'images': [], 'annotations': [], 'categories': coco.dataset['categories']}
# 遍历所有图片
for img_id in coco.imgs.keys(): # 训练集 18G 测试集6G,我的电脑训练集要用3min左右,耐心一点处理后训练集大概10G,留足空间
img_info = coco.loadImgs([img_id])[0] # 图片信息字典
img_file_name = img_info['file_name'] # 图片名
# 加载图片的所有标注
ann_ids = coco.getAnnIds(imgIds=img_id, iscrowd=None)
anns = coco.loadAnns(ann_ids) # 获得图片标注列表
# 过滤出只包含人的标注
person_anns = [ann for ann in anns if ann['category_id'] == 1] # 类别ID为1的是人
if person_anns: # 如果这张图片有人
shutil.copy2(os.path.join(images_input, img_file_name), images_output) # 复制图像文件
# 更新标注
filtered_annotations['images'].append(img_info)
filtered_annotations['annotations'].extend(person_anns) # 添加人的标注
# 将过滤后的标注保存为新的JSON文件
with open(annotations_output, 'w') as f:
json.dump(filtered_annotations, f)
print(f"标注已保存到 {annotations_output}")
print(f"图片已保存到 {images_output}")
end = time.perf_counter() # 记录结束时间
execution_time = end - start # 计算运行时间(单位为秒)
print(f"总用时:{execution_time}s")
数据集训练
按README.md文件里说的操作就行。这里用BLendMask模型,因为他又快又准。‘】https://github.com/aim-uofa/AdelaiDet/blob/master/datasets/README.md#blendmask-instance-detection
先使用这两个文件生成所需的注释文件
然后自己仿照他的配置文件写一个自己的训练计划
_BASE_: "DLA_34_syncbn_4x.yaml"
SOLVER:
IMS_PER_BATCH: 4
STEPS: (100000, 110000)
MAX_ITER: 120000
OUTPUT_DIR: "output/blendmask/My_BlendMask"
最后用train_net训练就行
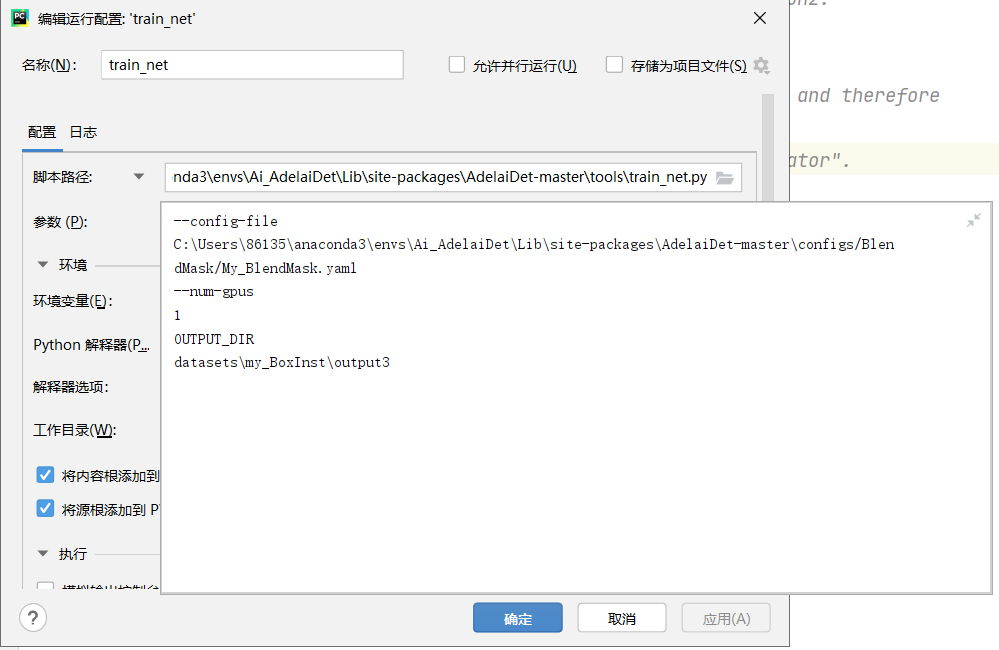

这边在自己的笔记本RTX2060上训练了10.5h,最后AP39.0
系统
源码有注释,我挑点有意思的说

你在设置里可以修改其他实例分割模型,只要是基于detectron2的都行,给的压缩包里有俩,第一组是My_BlendMask.yaml和model_final.pth我训练的,第二组是R_101_dcni3_5x.yaml和R_101_dcni3_5x.pth,AdelaiDet demo里的。

视频处理左键点视频可以使用你系统的默认播放器播放,注意是系统的默认播放器,没设置就不清楚了,

我使用两个屏幕,这里的屏幕选择可以跨屏幕选择区域,仿照qq截屏的想法,后来想起来用透明窗口采用录屏类似的操作,但已经写完了,就没改。
众所周知,CV2读网络摄像头会随着时间增长逐渐叠加延迟,所以我在系统内维护了一个缓冲区读图片。并借鉴了这个里面的ip摄像头
方便你们不想下载文件的借鉴这里粘贴一下系统的代码。

Load_My_model.py
# 这里没有使用onnx模型,而是pth模型进行处理
import time
import cv2
import torch
from detectron2.data import MetadataCatalog
from detectron2.engine.defaults import DefaultPredictor
from detectron2.utils.video_visualizer import VideoVisualizer
from detectron2.utils.visualizer import ColorMode, Visualizer
class Visualization(object): # 可视化组件,用这个进行模型的处理
def __init__(self, cfg):
self.metadata = MetadataCatalog.get(
cfg.DATASETS.TEST[0] if len(cfg.DATASETS.TEST) else "__unused"
) # 获取元数据
self.cfg = cfg
self.cpu_device = torch.device("cpu") # 为了可视化,转到CPU显示
self.instance_mode = ColorMode.IMAGE # 设置颜色模式
self.predictor = DefaultPredictor(cfg) # 创建预测器
def _frame_from_video(self, video): # 从视频,摄像头获取帧
while video.isOpened():
success, frame = video.read()
if success:
yield frame
else:
break
def _frame_from_screen(self, screen): # 从屏幕获取的帧
while True:
success, frame = screen.next()
if success:
yield frame
else:
break
def run_model_image(self, image, visualization=True): # 图片处理,第三个变量是否输出可视化结果
predictions = self.predictor(image)
if visualization:
visualizer = Visualizer(image, self.metadata, instance_mode=self.instance_mode) # 初始化可视器
instances = predictions["instances"].to(self.cpu_device)
vis_output = visualizer.draw_instance_predictions(predictions=instances) # 使用实例分割可视化
return predictions, vis_output # 返回预测结果和可视化输出
else:
return predictions, []
def run_model_video(self, video, visualization=True,screen = False): # 视频处理,第三个变量是否输出可视化结果
def process_predictions(frame, predictions):
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
predictions = predictions["instances"].to(self.cpu_device)
vis_frame = video_visualizer.draw_instance_predictions(frame, predictions)
vis_frame = cv2.cvtColor(vis_frame.get_image(), cv2.COLOR_RGB2BGR)
return vis_frame
video_visualizer = VideoVisualizer(self.metadata, self.instance_mode) # 初始化视频可视器
if screen:
frame_gen = self._frame_from_screen(video)
else:
frame_gen = self._frame_from_video(video)
for frame in frame_gen:
yield process_predictions(frame, self.predictor(frame))
Setup_cfg.py
# 设置配置文件,同时在直接运行时当demo使用(注意更改运行目录为项目根目录)
import time
from start_up.Load_My_model import Visualization
from adet.config import get_cfg
import tqdm # 显示进度条
from detectron2.data.detection_utils import read_image
from mss import mss
import numpy as np
import cv2
def setup_cfg(path_pth, path_yaml, threshold=0.3):
cfg = get_cfg() # 设置配置
cfg.merge_from_file(path_yaml) # 配置文件
cfg.merge_from_list(['MODEL.WEIGHTS', path_pth]) # 模型文件
# cfg.merge_from_file("data/R_101_dcni3_5x.yaml") # 配置文件
# cfg.merge_from_list(['MODEL.WEIGHTS', "data/R_101_dcni3_5x.pth"]) # 模型文件
cfg.MODEL.RETINANET.SCORE_THRESH_TEST = threshold # 得分阈值
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = threshold
cfg.MODEL.FCOS.INFERENCE_TH_TEST = threshold
cfg.MODEL.MEInst.INFERENCE_TH_TEST = threshold
cfg.MODEL.PANOPTIC_FPN.COMBINE.INSTANCES_CONFIDENCE_THRESH = threshold
cfg.freeze()
return cfg
if __name__ == "__main__":
cfg = setup_cfg("data/model_final.pth", "data/My_BlendMask.yaml")
visualization = Visualization(cfg) # 初始化可视化器(内部加载过model)
str = ["视频", "屏幕"]
# str = ["视频", "屏幕"]
if str[0] == "图片":
img = read_image("data/test1.jpg", format="BGR") # 换颜色模式
predictions, visualized_output = visualization.run_model_image(img)
cv2.namedWindow("COCO detections", cv2.WINDOW_NORMAL) # 创建一个窗口,可手动调整大小
cv2.imshow("COCO detections", visualized_output.get_image()[:, :, ::-1])
while 1:
if cv2.waitKey(0) == 27:
break # esc退出
elif str[0] == "视频": # 视频
if str[1] == "文件":
video = cv2.VideoCapture(
"C:\\Users\\86135\\Videos\\Captures\\Ratopia 2024-03-13 19-10-32.mp4")
for vis in tqdm.tqdm(visualization.run_model_video(video)):
cv2.namedWindow("COCO detections", cv2.WINDOW_NORMAL) # 创建一个窗口,可手动调整大小
cv2.imshow("COCO detections", vis) # 视频显示
if cv2.waitKey(1) == 27:
break # esc to quit
video.release() # 解除占用
elif str[1] == "屏幕":
# 没有摄像头,整个截屏吧
sct = mss() # 创建一个屏幕捕获对象
width = 640
height = 480
scale_factor = 1 # 缩放系数
new_width = int(width * scale_factor)
new_height = int(height * scale_factor)
monitor = {"top": 0, "left": 0, "width": width, "height": height} # 定义捕获的屏幕区域
# now_time = time.time()
while True:
screenshot = np.uint8(sct.grab(monitor)) # 捕获屏幕截图
screenshot = cv2.resize(screenshot, (new_width, new_height)) # 修改大小
screenshot = cv2.cvtColor(screenshot, cv2.COLOR_RGB2BGR) # 将截图转换为OpenCV格式(BGR)
# print(time.time() - now_time)
# now_time = time.time()
predictions, visualized_output = visualization.run_model_image(screenshot)
cv2.namedWindow("Screen", cv2.WINDOW_NORMAL) # 创建一个窗口,可手动调整大小
cv2.imshow("Screen", cv2.resize(visualized_output.get_image()[:, :, ::-1], (width, height)))
cv2.waitKey(100)
# from UI.screen_recognition_window import Screen
# screen = Screen(monitor,scale_factor)
# now_time = time.time()
# for vis in visualization.run_model_video(screen,screen=True):
# print(time.time() - now_time)
# now_time = time.time()
# cv2.namedWindow("Screen", cv2.WINDOW_NORMAL) # 创建一个窗口,可手动调整大小
# cv2.imshow("Screen", cv2.resize(cv2.cvtColor(vis,cv2.COLOR_BGR2RGB), (width, height)))
# cv2.waitKey(100)
# 销毁所有OpenCV窗口
cv2.destroyAllWindows()
main_window.py
import os
import numpy as np
from tkinter import ttk
from mss import mss
import tqdm # 显示进度条
import pickle # 保存变量用
import tkinter as tk # gui用
import tkinter.messagebox # 弹出来的对话框
import tkinter.filedialog # 文件相关窗口
import cv2
from PIL import Image, ImageTk
from set_up_window import SetUpWindow
from more_operations_window import MoreOperationsWindow
from screen_recognition_window import ScreenRecognitionWindow, SelectScreenArea, Screen
from detectron2.data.detection_utils import read_image
from start_up.Setup_cfg import setup_cfg
from start_up.Load_My_model import Visualization
from threading import Thread # 进程
class MainWindow(tk.Tk):
# 主窗口内有三种功能:图片,视频,实时(屏幕和网络摄像头)
def __init__(self):
super().__init__()
self.path = "data/path_data.txt"
self.default_path = [] # 默认模型位置,型配置位置和文件保存位置
# 子窗口有设置、更多操作、视频播放(改为调用软件播放,已经废除)、屏幕处理,每种同时只能存在一个
self.now_window = {"Set_Up_Window": None, "More_Operations_Window": None,
"Screen_Recognition_Window": None} # 当前存在的子窗口
self.title("i道i的实例分割系统") # 给主窗口起一个名字
self.geometry("1280x720+200+100") # 大小
self.config(menu=self.Generate_Menu()) # 生成菜单栏,窗口与菜单关联
self.now_num = -1 # 当前选择的功能
self.l_frame = tk.LabelFrame(self, text="功能", bg='gainsboro') # 左边功能栏
# 功能栏的按钮
self.l_frame.button_all = [
tk.Button(self.l_frame, text="图\n片", font=("NSimSun", 20, "bold"), command=lambda i=0: self.Goto_Ui(i)),
tk.Button(self.l_frame, text="视\n频", font=("NSimSun", 20, "bold"), command=lambda i=1: self.Goto_Ui(i)),
tk.Button(self.l_frame, text="实\n时", font=("NSimSun", 20, "bold"), command=lambda i=2: self.Goto_Ui(i))]
self.l_frame.columnconfigure(0, weight=1)
for i in range(len(self.l_frame.button_all)):
self.l_frame.button_all[i].grid(row=i, column=0, sticky="nsew", padx=10, pady=4)
self.l_frame.rowconfigure(i, weight=1)
self.l_frame.grid(row=0, column=0, sticky="nsew")
self.r_frame = tk.LabelFrame(self, text="数据", ) # 右边的数据栏框架
self.data_ui = [tk.Frame(self.r_frame), tk.Frame(self.r_frame), tk.Frame(self.r_frame)] # 三个数据集UI
for i in range(3):
self.data_ui[i].rowconfigure(0, weight=1)
self.data_ui[i].rowconfigure(1, weight=25)
self.data_ui[i].columnconfigure(0, weight=1)
self.data_ui[2].rowconfigure(1, weight=1)
# 第一个,图片处理========================================================================================
# 三个功能各不相同,第一个为图片处理,三个部分(顶部的步骤栏,下面的图片栏和操作栏)
# 先是步骤栏
self.up_frame_image = tk.LabelFrame(self.data_ui[0], text="步骤")
self.up_frame_image.rowconfigure(0, weight=1)
self.up_frame_image.columnconfigure(0, weight=1)
self.up_frame_image.columnconfigure(1, weight=1)
self.up_frame_image.columnconfigure(2, weight=1)
# 图片 功能:选择,处理,保存
self.now_image_step = -1 # 当前处于哪个功能框架中
self.now_image = [ImageTk.PhotoImage(Image.new('RGB', (0, 0))), None, None] # 当前图片,第一个是输入的原图,第二个是能直接扔进模型的图片
self.now_image_output = [None, None] # 当前图片处理结果
self.up_frame_image.buttons = [
tk.Button(self.up_frame_image, text="选择图片", command=lambda i=0: self.Goto_Image_Step(i)), # 第一步,选择图片
tk.Button(self.up_frame_image, text="开始处理", command=lambda i=1: self.Goto_Image_Step(i)), # 第二部,处理
tk.Button(self.up_frame_image, text="保存结果", command=lambda i=2: self.Goto_Image_Step(i)), # 第三步,保存
]
self.up_frame_image.buttons[1]['state'] = 'disabled' # 先禁用后两个,选了图片才能进去
self.up_frame_image.buttons[2]['state'] = 'disabled'
for i in range(len(self.up_frame_image.buttons)):
self.up_frame_image.buttons[i]['background'] = "black" # 背景颜色
self.up_frame_image.buttons[i]['foreground'] = "white" # 文字颜色
self.up_frame_image.buttons[i].config(font=("NSimSun", 14, "bold")) # 修改文字样式
self.up_frame_image.buttons[i].grid(row=0, column=i, sticky="wesn", padx=4, pady=4)
self.up_frame_image.buttons[0]['background'] = "orange"
self.up_frame_image.grid(row=0, column=0, sticky="wesn")
# 下面的图片栏和操作栏
self.down_frame_image = tk.Frame(self.data_ui[0])
# 图片栏
self.down_frame_image.l_frame = tk.LabelFrame(self.down_frame_image, text="图片")
self.down_frame_image.scrollbar_x = tk.Scrollbar(self.down_frame_image.l_frame, orient=tk.HORIZONTAL) # 滚动条x
self.down_frame_image.scrollbar_y = tk.Scrollbar(self.down_frame_image.l_frame, orient=tk.VERTICAL) # 滚动条y
self.down_frame_image.image_canvas = tk.Canvas(self.down_frame_image.l_frame,
xscrollcommand=self.down_frame_image.scrollbar_x.set,
yscrollcommand=self.down_frame_image.scrollbar_y.set, )
self.down_frame_image.image_canvas.image_id = \
self.down_frame_image.image_canvas.create_image(0, 0, anchor="nw",
image=ImageTk.PhotoImage(Image.new('RGB', (0, 0)))) # 先不放图片
self.down_frame_image.image_canvas.configure(scrollregion=(0, 0, 0, 0)) # 更新Canvas的滚动区域
self.down_frame_image.image_canvas.update() # 更新canvas以显示新图片
self.down_frame_image.scrollbar_x.pack(side=tk.BOTTOM, fill=tk.X) # 靠下,拉满x
self.down_frame_image.scrollbar_x.config(command=self.down_frame_image.image_canvas.xview)
self.down_frame_image.scrollbar_y.pack(side=tk.RIGHT, fill=tk.Y) # 靠右,拉满y
self.down_frame_image.scrollbar_y.config(command=self.down_frame_image.image_canvas.yview)
self.down_frame_image.image_canvas.pack(fill=tk.BOTH, expand=True) # 中间,且不扩充父框架大小
self.down_frame_image.l_frame.grid(row=0, column=0, sticky="wesn")
# 操作栏
self.down_frame_image.r_frame = tk.LabelFrame(self.down_frame_image, text="操作", bg='gainsboro')
# 第一步,选择图片
self.down_frame_image.button_select_image = tk.Button(self.down_frame_image.r_frame, text="选\n择\n图\n片\n",
font=("Microsoft YaHei", 18,),
command=self.Select_Image) # 选择图片按钮
# 第二步,进行处理
self.down_frame_image.button_start_segmentation = tk.Button(self.down_frame_image.r_frame, text="开始\n分割",
font=("Microsoft YaHei", 10,),
command=self.Start_Segmentation_Image)
# 分割结束后,如果要更多操作,转到更多操作弹窗处理
self.down_frame_image.button_more_operations = tk.Button(self.down_frame_image.r_frame, text="更多\n操作",
font=("Microsoft YaHei", 10,),
command=self.More_Operations) # 分割结束后
self.down_frame_image.button_more_operations['state'] = 'disabled' # 更多操作开始是禁用状态
# 第三步,输出
self.down_frame_image.button_save = tk.Button(self.down_frame_image.r_frame, text="保存\n结果",
font=("Microsoft YaHei", 10,),
command=self.Save_Image) # 打开一个文件保存对话框
self.down_frame_image.button_open_save_path = tk.Button(self.down_frame_image.r_frame, text="打开\n默认\n保存\n位置",
font=("Microsoft YaHei", 10,),
command=self.Open_Default_Save_Path) # 打开默认保存位置
self.down_frame_image.r_frame.rowconfigure(0, weight=1)
self.down_frame_image.r_frame.rowconfigure(1, weight=1)
self.down_frame_image.r_frame.columnconfigure(0, weight=1)
self.down_frame_image.r_frame.columnconfigure(1, weight=1)
self.down_frame_image.r_frame.grid(row=0, column=1, sticky="wesn")
self.down_frame_image.rowconfigure(0, weight=1)
self.down_frame_image.columnconfigure(0, weight=5)
self.down_frame_image.columnconfigure(1, weight=1)
self.down_frame_image.grid(row=1, column=0, sticky="wesn")
# 第二个,视频处理========================================================================================
# 和图片处理极其相似,去除更多操作按钮。增加取消分割功能(因为时间太长)
# 先是步骤栏
self.up_frame_video = tk.LabelFrame(self.data_ui[1], text="步骤")
self.up_frame_video.rowconfigure(0, weight=1)
self.up_frame_video.columnconfigure(0, weight=1)
self.up_frame_video.columnconfigure(1, weight=1)
self.up_frame_video.columnconfigure(2, weight=1)
# 视频 功能:选择,处理,保存
self.now_video_step = -1 # 当前处于哪个功能框架中
self.now_video = [None, None]
self.now_video_output = [None, None] # 视频处理结果
self.up_frame_video.buttons = [
tk.Button(self.up_frame_video, text="选择视频", command=lambda i=0: self.Goto_Video_Step(i)), # 第一步,选择图片
tk.Button(self.up_frame_video, text="开始处理", command=lambda i=1: self.Goto_Video_Step(i)), # 第二部,处理
tk.Button(self.up_frame_video, text="保存结果", command=lambda i=2: self.Goto_Video_Step(i)), # 第三步,保存
]
self.up_frame_video.buttons[1]['state'] = 'disabled' # 先禁用后两个,选了视频才能进去
self.up_frame_video.buttons[2]['state'] = 'disabled'
for i in range(len(self.up_frame_video.buttons)):
self.up_frame_video.buttons[i]['background'] = "black" # 背景颜色
self.up_frame_video.buttons[i]['foreground'] = "white" # 文字颜色
self.up_frame_video.buttons[i].config(font=("NSimSun", 14, "bold")) # 修改文字样式
self.up_frame_video.buttons[i].grid(row=0, column=i, sticky="wesn", padx=4, pady=4)
self.up_frame_video.buttons[0]['background'] = "orange"
self.up_frame_video.grid(row=0, column=0, sticky="wesn")
# 下面的视频栏和操作栏
self.down_frame_video = tk.Frame(self.data_ui[1])
# 视频栏
self.down_frame_video.l_frame = tk.LabelFrame(self.down_frame_video, text="视频")
# 做一个Canvas,绑定左键点击事件,左键点击后播放视频
self.down_frame_video.video_canvas = tk.Canvas(self.down_frame_video.l_frame, )
self.down_frame_video.video_canvas.image_id = \
self.down_frame_video.video_canvas.create_image(0, 0, anchor="nw",
image=ImageTk.PhotoImage(Image.new('RGB', (0, 0)))) # 先不放图片
self.down_frame_video.video_canvas.pack(fill=tk.BOTH, expand=True)
self.down_frame_video.l_frame.grid(row=0, column=0, sticky="wesn")
self.down_frame_video.video_canvas.bind("<Button-1>", self.Play_Video)
# 操作栏
self.down_frame_video.r_frame = tk.LabelFrame(self.down_frame_video, text="操作", bg='gainsboro')
# 第一步,选择视频
self.down_frame_video.button_select_video = tk.Button(self.down_frame_video.r_frame, text="选\n择\n视\n频",
font=("Microsoft YaHei", 18,),
command=self.Select_Video) # 选择图片按钮
# 第二步,进行处理
self.down_frame_video.button_start_segmentation = tk.Button(self.down_frame_video.r_frame, text="开始\n分割",
font=("Microsoft YaHei", 10,),
command=self.Start_Segmentation_Video)
# 打开默认保存位置
self.down_frame_video.button_open_save_path = tk.Button(self.down_frame_video.r_frame, text="打开\n默认\n保存\n位置",
font=("Microsoft YaHei", 10,),
command=self.Open_Default_Save_Path) # 打开默认保存位置
self.down_frame_video.r_frame.rowconfigure(0, weight=1)
self.down_frame_video.r_frame.rowconfigure(1, weight=1)
self.down_frame_video.r_frame.columnconfigure(0, weight=1)
self.down_frame_video.r_frame.columnconfigure(1, weight=1)
self.down_frame_video.r_frame.grid(row=0, column=1, sticky="wesn")
self.down_frame_video.rowconfigure(0, weight=1)
self.down_frame_video.columnconfigure(0, weight=5)
self.down_frame_video.columnconfigure(1, weight=1)
self.down_frame_video.grid(row=1, column=0, sticky="wesn")
# 第三个功能,屏幕处理========================================================================================
# 选择屏幕区域,开始处理。或者链接ip摄像头(因为电脑不带摄像头)
# 屏幕处理,选择屏幕区域按钮和文本框,开始处理按钮,缩放系数滑条,两种方式单选框
# 选择屏幕区域
def validate_number(P): # 判断是否为数字
if P.isdigit() or (P == '' and P is not None):
return True
return False
self.vcmd = (self.register(validate_number), '%P') # 验证输入是否为数字
self.up_frame_screen = tk.LabelFrame(self.data_ui[2], text="屏幕")
# 屏幕位置关联变量,top,left,width,height
self.up_frame_screen.position = [tk.IntVar(), tk.IntVar(), tk.IntVar(), tk.IntVar()]
self.up_frame_screen.position_label = [tk.Label(self.up_frame_screen, text="top:"),
tk.Label(self.up_frame_screen, text="left:"),
tk.Label(self.up_frame_screen, text="width:"),
tk.Label(self.up_frame_screen, text="height:"), ]
self.up_frame_screen.position_entry = [] # 截屏范围文本框
for i in range(2):
for j in range(2):
self.up_frame_screen.position_entry.append(
tk.Entry(self.up_frame_screen, exportselection=0, validate="key",
validatecommand=self.vcmd, # 表示每次按键时都会调用验证函数
textvariable=self.up_frame_screen.position[2 * i + j]))
self.up_frame_screen.position_label[2 * i + j].grid(row=i, column=2 * j)
self.up_frame_screen.position_entry[2 * i + j].grid(row=i, column=2 * j + 1, sticky="we")
def Open_SelectScreenArea(): # 打开选择屏幕区域窗口
SelectScreenArea(self)
self.up_frame_screen.select_screen_range = tk.Button(self.up_frame_screen, text="选择屏\n幕范围",
command=Open_SelectScreenArea, )
self.up_frame_screen.select_screen_range.grid(row=0, column=4, )
# cv2 模式
# 创建一个 IntVar 对象来存储开关的状态
self.up_frame_screen.switch_var = tk.IntVar()
self.up_frame_screen.switch_var.set(0)
self.up_frame_screen.cv2_checkbutton = tk.Checkbutton(self.up_frame_screen, text="cv2窗口模式",
variable=self.up_frame_screen.switch_var)
self.up_frame_screen.cv2_checkbutton.grid(row=1, column=4, )
# 单选处理模式
self.up_frame_screen.processing_mode = tk.IntVar() # 单选按钮的值,用.get()可以取出来,初始0
self.up_frame_screen.processing_mode_radiobutton = [
tk.Radiobutton(self.up_frame_screen, text="图片式处理", variable=self.up_frame_screen.processing_mode,
value=0),
tk.Radiobutton(self.up_frame_screen, text="流式处理", variable=self.up_frame_screen.processing_mode,
value=1)]
self.up_frame_screen.processing_mode_radiobutton[0].grid(row=2, column=0, )
self.up_frame_screen.processing_mode_radiobutton[1].grid(row=2, column=1, )
# 缩放系数滑条
def Update_Scale_Value(event):
# 获取滑条当前的值
current_value = self.up_frame_screen.scale_factor_scale.get()
self.up_frame_screen.scale_factor = current_value
self.up_frame_screen.scale_factor = 0.5
self.up_frame_screen.scale_factor_label = tk.Label(self.up_frame_screen, text="缩放系数:")
self.up_frame_screen.scale_factor_scale = tk.Scale(self.up_frame_screen, from_=0.1, to=1, resolution=0.1,
orient='horizontal', command=Update_Scale_Value)
self.up_frame_screen.scale_factor_scale.set(self.up_frame_screen.scale_factor) # 设置初始值
self.up_frame_screen.scale_factor_label.grid(row=2, column=2, )
self.up_frame_screen.scale_factor_scale.grid(row=2, column=3, sticky="we")
# 开始处理
self.up_frame_screen.start_processing = tk.Button(self.up_frame_screen, text="开始处理", command=self.Play_Screen)
self.up_frame_screen.start_processing.grid(row=2, column=4, )
self.up_frame_screen.rowconfigure(0, weight=1)
self.up_frame_screen.rowconfigure(1, weight=1)
self.up_frame_screen.rowconfigure(2, weight=1)
for i in range(5):
self.up_frame_screen.columnconfigure(i, weight=1)
self.up_frame_screen.grid(row=0, column=0, sticky="wesn")
# ip摄像头,ip文本框,开始处理按钮
self.down_frame_screen = tk.LabelFrame(self.data_ui[2], text="网络摄像头")
self.down_frame_screen.rowconfigure(0, weight=1)
self.down_frame_screen.columnconfigure(0, weight=1)
self.down_frame_screen.grid(row=1, column=0, sticky="wesn")
self.down_frame_screen.ip_l = [tk.Label(self.down_frame_screen, text="ip地址:"),
tk.Label(self.down_frame_screen, text="用户名:"),
tk.Label(self.down_frame_screen, text="密码:")]
self.down_frame_screen.ip_e = [tk.Entry(self.down_frame_screen, exportselection=0),
tk.Entry(self.down_frame_screen, exportselection=0),
tk.Entry(self.down_frame_screen, exportselection=0, show="*"), ]
self.down_frame_screen.ip_e[0].insert(0, "192.168.31.133:8081")
self.down_frame_screen.ip_e[1].insert(0, "admin")
self.down_frame_screen.ip_e[2].insert(0, "admin")
self.down_frame_screen.ip_l[0].grid(row=1, column=0)
self.down_frame_screen.ip_e[0].grid(row=1, column=1, sticky="we", columnspan=2, )
self.down_frame_screen.ip_l[1].grid(row=0, column=0)
self.down_frame_screen.ip_e[1].grid(row=0, column=1, sticky="we")
self.down_frame_screen.ip_l[2].grid(row=0, column=2)
self.down_frame_screen.ip_e[2].grid(row=0, column=3, sticky="we")
# 开始摄像头处理
self.down_frame_screen.start_processing = tk.Button(self.down_frame_screen, text="开始处理",
command=lambda ip=True: self.Play_Screen(ip))
self.down_frame_screen.start_processing.grid(row=1, column=3, )
tk.Label(self.down_frame_screen, text="处理模式,窗口模式,缩放系数延用屏幕处理部分,如果摄像头未打开,会受到阻塞,是正常现象").grid(row=2, column=0,
columnspan=4, )
self.down_frame_screen.rowconfigure(0, weight=1)
self.down_frame_screen.rowconfigure(1, weight=1)
self.down_frame_screen.rowconfigure(2, weight=1)
for i in range(5):
self.down_frame_screen.columnconfigure(i, weight=1)
# 结束
self.r_frame.rowconfigure(0, weight=1)
self.r_frame.columnconfigure(0, weight=1)
self.r_frame.grid(row=0, column=1, sticky="nsew")
self.columnconfigure(0, weight=1)
self.columnconfigure(1, weight=10)
self.rowconfigure(0, weight=1)
self.Initialize_Model() # 初始化模型
# 设置按钮的回调
def Set_Up_Callback(self):
# 没设置窗口或者窗口已经不存在
if self.now_window["Set_Up_Window"] is None or not self.now_window["Set_Up_Window"].winfo_exists():
set_up_window = SetUpWindow(main_window) # 生成设置窗口
self.now_window["Set_Up_Window"] = set_up_window # 变量添加到存在的子窗口中
else: # 有窗口了
self.now_window["Set_Up_Window"].deiconify() # 取消最小化
self.now_window["Set_Up_Window"].lift() # 置于所有窗口顶端
# 创建菜单栏,暂时只有一个设置按钮
def Generate_Menu(self):
menubar = tk.Menu(self) # 菜单栏
menubar.add_command(label='设置', command=self.Set_Up_Callback) # 菜单添加设置项(设置使用的模型默认文件保存位置)
return menubar
# 读取文件中的默认位置,并且加载模型。
def Initialize_Model(self, repeat=False):
# 保存的文件我都设在同一目录下吧
try:
file = open(self.path, 'rb') # 读取配置文件
data = pickle.load(file)
self.default_path = data
file.close() # 关闭文件
except FileNotFoundError: # 文件未找到
# 使用默认路径创建一个新文件
if repeat: # 重建路径文件后还不行
tk.messagebox.showwarning(title='警告!', message='路径文件错误,无法重建路径文件')
exit(-1)
else:
self.Change_Path_Data(["data\model_final.pth", "data\My_BlendMask.yaml", "out_put"])
self.Initialize_Model(True) # 重新初始化
return 0
# 读取完配置文件了,加载一下模型
try:
self.cfg = setup_cfg(self.default_path[0], self.default_path[1]) # 导入配置文件和模型文件
self.visualization = Visualization(self.cfg) # 初始化可视化器
except:
tk.messagebox.showwarning(title='警告!', message='无法导入配置文件和模型文件')
def Change_Path_Data(self, list): # 修改路径文件,将list列表保存到path_data.txt中
try:
file = open(self.path, 'wb') # 东西少,直接覆盖
pickle.dump(list, file)
file.close()
except:
print("错误")
exit(-1)
def Resetting_Data_Bar(self): # 重置数据栏,遍历所有控件,取消显示
for i in self.r_frame.grid_slaves():
i.grid_forget()
def Goto_Ui(self, num): # 选择功能
if self.now_num == num: # 当前播放窗口一致,直接不管
return
else:
self.now_num = num
self.Resetting_Data_Bar() # 取消显示数据栏中的控件
self.data_ui[num].grid(row=0, column=0, sticky="wesn") # 将需求的控件显示出来
def Goto_Image_Step(self, num): # 选择图片处理步骤
if num != self.now_image_step: # 和当前窗口不一致才继续
for i in self.down_frame_image.r_frame.grid_slaves(): # 遍历所有控件,取消显示
i.grid_forget()
if num == 0:
# 显示选择图片按钮
self.down_frame_image.button_select_image.grid(row=0, column=0, columnspan=2, rowspan=2, sticky="wesn",
padx=10, pady=4)
# 取消显示图片
self.down_frame_image.image_canvas.itemconfig(self.down_frame_image.image_canvas.image_id,
image=ImageTk.PhotoImage(Image.new('RGB', (0, 0))))
self.down_frame_image.image_canvas.configure(scrollregion=(0, 0, 0, 0)) # 更新Canvas的滚动区域
self.down_frame_image.image_canvas.update() # 更新canvas以显示新图片
self.up_frame_image.buttons[1]['state'] = 'disabled' # 禁用后两个,选了图片才能进去
self.up_frame_image.buttons[2]['state'] = 'disabled'
self.up_frame_image.buttons[1]['background'] = "black"
self.up_frame_image.buttons[2]['background'] = "black"
self.up_frame_image.buttons[0]['background'] = "green"
self.down_frame_image.button_start_segmentation['state'] = 'normal' # 启用开始分割按钮
self.down_frame_image.button_more_operations['state'] = 'disabled' # 禁用更多操作按钮
elif num == 1:
self.down_frame_image.button_start_segmentation.grid(row=0, column=0, columnspan=2, sticky="wesn",
padx=10, pady=4)
self.down_frame_image.button_more_operations.grid(row=1, column=0, columnspan=2, sticky="wesn", padx=10,
pady=4)
elif num == 2:
self.down_frame_image.button_save.grid(row=0, column=0, columnspan=2, sticky="wesn", padx=10, pady=4)
self.down_frame_image.button_open_save_path.grid(row=1, column=0, columnspan=2, sticky="wesn", padx=10,
pady=4)
self.now_image_step = num
def Select_Image(self): # 选择图片按钮的回调
file_path = tk.filedialog.askopenfilename(filetypes=[("图片文件", '*.jpeg;*.jpg;*.png')],) # 文件选择对话框
if file_path.strip() != '': # 是空的时候,往往没有选择,直接关闭窗口
try:
self.now_image[0] = Image.open(file_path) # 窗口中显示的图片
self.now_image[1] = read_image(file_path, format="BGR") # 要送进模型的图片
self.down_frame_image.image_canvas.image = ImageTk.PhotoImage(self.now_image[0])
self.down_frame_image.image_canvas.itemconfig(self.down_frame_image.image_canvas.image_id,
image=self.down_frame_image.image_canvas.image)
self.down_frame_image.image_canvas.configure(
scrollregion=(0, 0, self.down_frame_image.image_canvas.image.width(),
self.down_frame_image.image_canvas.image.height())) # 更新Canvas的滚动区域
self.down_frame_image.image_canvas.update() # 更新canvas以显示新图片
except:
tk.messagebox.showwarning(title='警告!', message='图片文件错误,无法读取图片文件')
self.up_frame_image.buttons[1]['state'] = 'disabled' # 禁用后两个,防止没有图片
self.up_frame_image.buttons[2]['state'] = 'disabled'
self.up_frame_image.buttons[1]['background'] = "black"
self.up_frame_image.buttons[2]['background'] = "black"
return
# 走到这表明没问题了,解除禁用
self.up_frame_image.buttons[1]['state'] = 'normal'
self.up_frame_image.buttons[1]['background'] = "green" # 进行开始处理步骤
self.up_frame_image.buttons[0]['background'] = "royalblue" # 完成图片选择
# 转到开始处理
self.Goto_Image_Step(1)
def Start_Segmentation_Image(self): # 开始分割图片
def Segmentation_Image():
try:
# 对图片进行处理
self.now_image_output[0], self.now_image_output[1] = self.visualization.run_model_image(
self.now_image[1])
except:
tk.messagebox.showwarning(title='警告!', message='模型错误,无法使用模型处理图片')
return
# 得到处理结果了
self.now_image[1] = Image.fromarray(self.now_image_output[1].get_image()[:, :, ::-1])
self.now_image[2] = ImageTk.PhotoImage(self.now_image[1])
self.down_frame_image.image_canvas.itemconfig(self.down_frame_image.image_canvas.image_id,
image=self.now_image[2]) # 替换图片为处理好的结果
self.down_frame_image.image_canvas.configure(
scrollregion=(0, 0, self.now_image[2].width(), self.now_image[2].height())) # 更新Canvas的滚动区域
self.down_frame_image.image_canvas.update() # 更新canvas以显示新图片
self.down_frame_image.button_start_segmentation['state'] = 'disabled' # 禁用开始分割按钮,
self.down_frame_image.button_more_operations['state'] = 'normal' # 恢复更多操作按钮和保存结果按钮
self.up_frame_image.buttons[2]['state'] = 'normal'
self.up_frame_image.buttons[2]['background'] = "green"
self.up_frame_image.buttons[1]['background'] = "royalblue"
self.waiting_dialog.destroy() # 执行完毕,销毁等待对话框
try:
self.Waiting_Dialog()
thread = Thread(target=Segmentation_Image)
thread.start() # 启用新线程分割,避免阻塞窗口
except:
tk.messagebox.showwarning(title='警告!', message='图片分割失败,无法处理')
def More_Operations(self): # 更多操作按钮回调
# 没更多操作窗口或者窗口已经不存在
if self.now_window["More_Operations_Window"] is None or not self.now_window[
"More_Operations_Window"].winfo_exists():
more_operations_window = MoreOperationsWindow(main_window) # 生成更多操作
self.now_window["More_Operations_Window"] = more_operations_window # 变量添加到存在的子窗口中
else: # 有窗口了
self.now_window["More_Operations_Window"].deiconify() # 取消最小化
self.now_window["More_Operations_Window"].lift() # 置于所有窗口顶端
def Save_Image(self, img=None, variable=None): # 保存图片
if img is None and variable is None:
img = self.now_image[1]
variable = self.now_image_output[0]
file_img = tk.filedialog.asksaveasfilename(filetypes=[("图片文件", '*.jpeg;*.jpg;*.png')], defaultextension=".jpeg",
initialfile="分割图片",initialdir =self.default_path[2] )
if file_img.strip() != '': # 是空的时候,往往没有选择,直接关闭窗口
img.save(file_img) # 保存图片
if variable is not None: # 给出了模型输出
file_v = tk.filedialog.asksaveasfilename(filetypes=[("模型输出", '*.bin'), ], defaultextension=".bin",
initialfile="模型输出",initialdir =self.default_path[2])
if file_v.strip() != '': # 是空的时候,往往没有选择,直接关闭窗口
file = open(file_v, 'wb')
pickle.dump(variable, file)
file.close()
def Open_Default_Save_Path(self): # 打开默认保存位置
os.startfile(self.default_path[2])
# 缩放图片大小,proportion为调整到的大小比例,size为调整到的大小,size优先级更高
def Zoom_Image(self, img, proportion=None, size=None):
width, height = img.size
if size is None:
size = [0, 0]
if not proportion is None:
size[0] = int(width * proportion)
size[1] = int(height * proportion)
resized_image = img.resize(size)
return resized_image
def Goto_Video_Step(self, num): # 选择视频处理的步骤
if num != self.now_video_step: # 和当前窗口不一致才继续
for i in self.down_frame_video.r_frame.grid_slaves(): # 遍历所有控件,取消显示
i.grid_forget()
if num == 0:
# 显示选择图片按钮
self.down_frame_video.button_select_video.grid(row=0, column=0, columnspan=2, rowspan=2, sticky="wesn",
padx=10, pady=4)
# 取消显示图片
self.down_frame_video.video_canvas.itemconfig(self.down_frame_video.video_canvas.image_id,
image=ImageTk.PhotoImage(Image.new('RGB', (0, 0))))
self.now_video[1] = None # 删除地址字符串
self.down_frame_video.video_canvas['cursor'] = 'arrow' # 鼠标样式更改
self.down_frame_video.video_canvas.update() # 更新canvas以显示新图片
self.up_frame_video.buttons[1]['state'] = 'disabled' # 禁用后两个,选了图片才能进去
self.up_frame_video.buttons[2]['state'] = 'disabled'
self.up_frame_video.buttons[1]['background'] = "black"
self.up_frame_video.buttons[2]['background'] = "black"
self.up_frame_video.buttons[0]['background'] = "green"
elif num == 1:
# 放入开始分割按钮
self.down_frame_video.button_start_segmentation.grid(row=0, column=0, columnspan=2, rowspan=2,
sticky="wesn", padx=10, pady=4)
elif num == 2:
self.down_frame_video.button_open_save_path.grid(row=0, column=0, columnspan=2, rowspan=2,
sticky="wesn", padx=10, pady=4)
self.now_video_step = num
def Select_Video(self): # 选择视频
file_path = tk.filedialog.askopenfilename(filetypes=[("视频文件", '*.mp4;*.mkv')],) # 文件选择对话框
if file_path.strip() != '': # 是空的时候,往往没有选择,直接关闭窗口
try:
self.now_video[1] = file_path # 读取的视频文件位置
video = cv2.VideoCapture(file_path)
ret, frame = video.read() # 读取一帧
video.release() # 释放VideoCapture对象
if ret: # 成功读取
# OpenCV图像是BGR格式的,转换为RGB并转为Tkinter可以使用的格式,顺便修改一下大小
self.now_video[0] = ImageTk.PhotoImage(self.Zoom_Image(Image.fromarray(
cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)), size=[self.down_frame_video.l_frame.winfo_width(),
self.down_frame_video.l_frame.winfo_height()]))
self.down_frame_video.video_canvas.itemconfig(self.down_frame_video.video_canvas.image_id,
image=self.now_video[0])
self.down_frame_video.video_canvas.update() # 更新canvas以显示新图片
self.down_frame_video.video_canvas['cursor'] = 'hand2'
self.down_frame_video.button_start_segmentation['state'] = 'normal' # 启用开始分割按钮
except:
tk.messagebox.showwarning(title='警告!', message='视频文件错误,无法读取视频文件')
self.up_frame_video.buttons[1]['state'] = 'disabled' # 禁用后两个,防止没有图片
self.up_frame_video.buttons[2]['state'] = 'disabled'
self.up_frame_video.buttons[1]['background'] = "black"
self.up_frame_video.buttons[2]['background'] = "black"
self.now_video[1] = None # 删除地址字符串
self.down_frame_video.video_canvas['cursor'] = 'arrow' # 鼠标样式更改
return
# 走到这表明没问题了,解除禁用
self.up_frame_video.buttons[1]['state'] = 'normal'
self.up_frame_video.buttons[1]['background'] = "green" # 进行开始处理步骤
self.up_frame_video.buttons[0]['background'] = "royalblue" # 完成图片选择
# 转到开始处理
self.Goto_Video_Step(1)
def Start_Segmentation_Video(self): # 开始分割视频
def Segmentation_Video():
try:
# 对视频进行处理
video = cv2.VideoCapture(self.now_video[1])
width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))
frames_per_second = video.get(cv2.CAP_PROP_FPS) # 帧率
num_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT)) # 总帧数
output_fname = \
os.path.splitext(os.path.join(self.default_path[2], os.path.basename(self.now_video[1])))[
0] + "_out.mkv" # 文件输出位置,输出到默认输出位置,名字和输入文件名字相同,后缀改为mkv
# 不避免覆盖
output_file = cv2.VideoWriter( # 创建视频写入器
filename=output_fname,
fourcc=cv2.VideoWriter_fourcc(*"MPEG"), # 或者MPEG
fps=float(frames_per_second),
frameSize=(width, height),
isColor=True,
)
num = 0
for vis in tqdm.tqdm(self.visualization.run_model_video(video)):
output_file.write(vis)
num += 1
self.waiting_dialog.progress_var.set(int(num / num_frames * 100)) # 进度条
if not self.waiting_dialog.winfo_exists(): # 对话框关闭后终止运行
break
video.release() # 解除占用
output_file.release()
except:
tk.messagebox.showwarning(title='警告!', message='模型错误,无法使用模型处理图片')
return
# 得到处理结果了
# 显示图片
video = cv2.VideoCapture(output_fname)
ret, frame = video.read() # 读取一帧
video.release() # 释放VideoCapture对象
if ret: # 成功读取
self.now_video[1] = output_fname # 更改点击播放的视频
self.now_video[0] = ImageTk.PhotoImage(self.Zoom_Image(Image.fromarray( # 更改显示的图片
cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)), size=[self.down_frame_video.l_frame.winfo_width(),
self.down_frame_video.l_frame.winfo_height()]))
self.down_frame_video.video_canvas.itemconfig(self.down_frame_video.video_canvas.image_id,
image=self.now_video[0])
self.down_frame_video.video_canvas.update() # 更新canvas以显示新图片
self.up_frame_video.buttons[2]['state'] = 'normal'
self.up_frame_video.buttons[2]['background'] = "green"
self.up_frame_video.buttons[1]['background'] = "royalblue"
self.down_frame_video.button_start_segmentation['state'] = 'disabled' # 禁用开始分割按钮
self.waiting_dialog.destroy() # 执行完毕,销毁等待对话框
self.Goto_Video_Step(2) # 去往保存位置步骤
try:
self.Waiting_Dialog(video=True)
thread = Thread(target=Segmentation_Video)
thread.start() # 启用新线程分割,避免阻塞窗口
except:
tk.messagebox.showwarning(title='警告!', message='视频分割失败,无法处理')
def Play_Video(self, event): # 播放视频
if not self.now_video[1] is None: # 有视频路径
if os.path.exists(self.now_video[1]):
# 使用默认播放器打开视频文件
os.startfile(self.now_video[1])
def Play_Screen(self, ip=False): # 屏幕处理
# 没屏幕处理窗口或者窗口已经不存在
if self.up_frame_screen.switch_var.get() == 1: # 进行cv2模式
self.Handle(ip)
else:
if self.now_window["Screen_Recognition_Window"] is None or not self.now_window[
"Screen_Recognition_Window"].winfo_exists():
screen_recognition_window = ScreenRecognitionWindow(main_window, ip) # 生成屏幕处理窗口
self.now_window["Screen_Recognition_Window"] = screen_recognition_window # 变量添加到存在的子窗口中
else: # 有窗口了
self.now_window["Screen_Recognition_Window"].deiconify() # 取消最小化
self.now_window["Screen_Recognition_Window"].lift() # 置于所有窗口顶端
def Waiting_Dialog(self, video=False): # 一个等待框
self.waiting_dialog = tk.Toplevel(self) # 一个等待对话框
self.waiting_dialog.grab_set() # 设置模态,阻止用户与其他窗口交互
self.waiting_dialog.transient(self) # 设置为临时窗口,随主窗口关闭而关闭
self.waiting_dialog.title("正在处理")
self.waiting_dialog.geometry("%dx%d+%d+%d" % (400, 300, self.winfo_x() + 100, self.winfo_y() + 100))
self.waiting_dialog.resizable(False, False) # 禁止缩放
if video:
waiting_label = tk.Label(self.waiting_dialog, text="请稍候,正在处理...,\n关闭此框将会结束视频分割")
self.waiting_dialog.progress_var = tk.StringVar()
self.waiting_dialog.progress_var.set(0)
self.waiting_dialog.progress = ttk.Progressbar(self.waiting_dialog, orient='horizontal', length=200,
mode='determinate',
variable=self.waiting_dialog.progress_var)
self.waiting_dialog.progress.pack(pady=50)
else:
waiting_label = tk.Label(self.waiting_dialog, text="请稍候,正在处理...")
waiting_label.pack(pady=20)
def Handle(self, ip=False):
if ip:
try:
if cv2.getWindowProperty('Screen', 0) >= 0:
return
except cv2.error:
pass
ip = f"http://{self.down_frame_screen.ip_e[1].get()}:{self.down_frame_screen.ip_e[2].get()}@{self.down_frame_screen.ip_e[0].get()}/"
capture = cv2.VideoCapture(ip)
# 尝试读取一帧
ret, img = capture.read()
if not ret:
tk.messagebox.showwarning(title='警告!', message='无法从摄像头中读取图片')
return
monitor = {"top": 0
, "left": 0
, "width": img.shape[1]
, "height": img.shape[0]}
scale_factor = self.up_frame_screen.scale_factor # 缩放系数
screen = Screen(monitor, scale_factor, ip=capture)
if self.up_frame_screen.processing_mode.get() == 0:
while True:
try:
ret, img = screen.next()
if not ret: # 没读取成功图片
break
_, visualized_output = self.visualization.run_model_image(img)
cv2.namedWindow("Screen", cv2.WINDOW_NORMAL) # 创建一个窗口,可手动调整大小
cv2.imshow("Screen", cv2.resize(visualized_output.get_image()[:, :, ::-1],
(monitor["width"], monitor["height"])))
cv2.waitKey(100)
if cv2.getWindowProperty('Screen', 0) < 0: # 窗口关闭
cv2.destroyAllWindows()
break
except cv2.error:
break
elif self.up_frame_screen.processing_mode.get() == 1:
for vis in self.visualization.run_model_video(screen, screen=True):
try:
cv2.namedWindow("Screen", cv2.WINDOW_NORMAL) # 创建一个窗口,可手动调整大小
cv2.imshow("Screen", cv2.resize(cv2.cvtColor(vis, cv2.COLOR_BGR2RGB),
(monitor["width"], monitor["height"])))
cv2.waitKey(100)
if cv2.getWindowProperty('Screen', 0) < 0:
cv2.destroyAllWindows()
break
except cv2.error:
break
capture.release()
else:
try:
if cv2.getWindowProperty('Screen', 0) >= 0:
return
except cv2.error:
pass
monitor = {"top": self.up_frame_screen.position[0].get()
, "left": self.up_frame_screen.position[1].get()
, "width": self.up_frame_screen.position[2].get()
, "height": self.up_frame_screen.position[3].get()}
scale_factor = self.up_frame_screen.scale_factor # 缩放系数
new_width = int(monitor["width"] * scale_factor) # 缩放后的大小
new_height = int(monitor["height"] * scale_factor)
if self.up_frame_screen.processing_mode.get() == 0:
sct = mss() # 创建一个屏幕捕获对象
while True:
try:
screenshot = np.uint8(sct.grab(monitor)) # 捕获屏幕截图
screenshot = cv2.resize(screenshot, (new_width, new_height)) # 修改大小
screenshot = cv2.cvtColor(screenshot, cv2.COLOR_RGB2BGR) # 将截图转换为OpenCV格式(BGR)
_, visualized_output = self.visualization.run_model_image(screenshot)
cv2.namedWindow("Screen", cv2.WINDOW_NORMAL) # 创建一个窗口,可手动调整大小
cv2.imshow("Screen", cv2.resize(visualized_output.get_image()[:, :, ::-1],
(monitor["width"], monitor["height"])))
cv2.waitKey(100)
if cv2.getWindowProperty('Screen', 0) < 0:
cv2.destroyAllWindows()
break
except cv2.error:
break
elif self.up_frame_screen.processing_mode.get() == 1:
screen = Screen(monitor, scale_factor)
for vis in self.visualization.run_model_video(screen, screen=True):
try:
cv2.namedWindow("Screen", cv2.WINDOW_NORMAL) # 创建一个窗口,可手动调整大小
cv2.imshow("Screen", cv2.resize(cv2.cvtColor(vis, cv2.COLOR_BGR2RGB),
(monitor["width"], monitor["height"])))
cv2.waitKey(100)
if cv2.getWindowProperty('Screen', 0) < 0:
cv2.destroyAllWindows()
break
except cv2.error:
break
if __name__ == "__main__":
main_window = MainWindow() # 创建主窗口
main_window.mainloop() # 开启主循环,让窗口处于显示状态
more_operations_window.py
# 更多操作窗口类,用于对分割后的图片进行更多处理
import tkinter as tk # gui用
from tkinter import colorchooser
import numpy as np
import random
from PIL import Image, ImageTk, ImageDraw, ImageFilter
class MoreOperationsWindow(tk.Toplevel):
def __init__(self, master):
super().__init__(master) # 父类调用,
self.master = master
self.grab_set() # 独占焦点
self.title("更多操作")
# 设置大小和位置(相对于父窗口左上角)
self.geometry("%dx%d+%d+%d" % (1024, 768, master.winfo_x() + 128, master.winfo_y() + 0))
self.image = self.master.now_image[0] # 原始图片
self.now_image = self.image # 当前处理的图片
self.look_image = ImageTk.PhotoImage(self.now_image) # 显示的图片
self.instance_image = master.now_image_output[0]['instances'] # 实例分割的结果
self.none_image = ImageTk.PhotoImage(Image.new('RGB', (0, 0)))
# 左边的图片栏
self.l_frame = tk.LabelFrame(self, text="图片")
self.scrollbar_x = tk.Scrollbar(self.l_frame, orient=tk.HORIZONTAL) # 滚动条x
self.scrollbar_y = tk.Scrollbar(self.l_frame, orient=tk.VERTICAL) # 滚动条y
self.image_canvas = tk.Canvas(self.l_frame,
xscrollcommand=self.scrollbar_x.set,
yscrollcommand=self.scrollbar_y.set, )
self.image_id = self.image_canvas.create_image(0, 0, anchor="nw",
image=self.look_image)
self.image_canvas.configure(scrollregion=(0, 0, self.look_image.width(),
self.look_image.height())) # 更新Canvas的滚动区域
self.image_canvas.update() # 更新canvas以显示新图片
self.scrollbar_x.pack(side=tk.BOTTOM, fill=tk.X) # 靠下,拉满x
self.scrollbar_x.config(command=self.image_canvas.xview)
self.scrollbar_y.pack(side=tk.RIGHT, fill=tk.Y) # 靠右,拉满y
self.scrollbar_y.config(command=self.image_canvas.yview)
self.image_canvas.pack(fill=tk.BOTH, expand=True)
self.l_frame.grid(row=0, column=0, sticky="wesn")
# 右边的操作栏
self.r_frame = tk.LabelFrame(self, text="操作")
self.r_frame.grid(row=0, column=1, sticky="wesn")
self.display_mask = tk.IntVar() # 显示掩膜
self.display_mask.set(1)
# 分辨率+-,选择保留的实例,背景虚化,背景替换纯色
# 缩放系数滑条
def Update_Scale_Value(event):
# 获取滑条当前的值
current_value = self.scale_factor_scale.get()
self.scale_factor = current_value
def Change_Scale(i): # 缩放按钮的回调
new_scale_factor = self.scale_factor + i
if new_scale_factor < self.scale_factor_scope[0] or new_scale_factor > self.scale_factor_scope[1]:
return
else:
self.scale_factor = new_scale_factor
self.scale_factor_scale.set(self.scale_factor)
self.Scale_Image()
img_size = max(self.image.size) # 左边图片栏近似看成750大小的正方形,
self.scale_factor = round((750 / img_size) / 0.05) * 0.05 # 初始缩放系数,让图片正正好显示
self.scale_factor_scope = [self.scale_factor, self.scale_factor * 6] # 动态比例,最小让图片正好显示,最大放大六倍,防止卡顿
if self.scale_factor_scope[0] > 1: # 缩放比范围微调
self.scale_factor_scope[0] = 1
if self.scale_factor_scope[1] < 1:
self.scale_factor_scope[1] = 1
self.scale_factor_scale = tk.Scale(self.r_frame, from_=self.scale_factor_scope[0],
to=self.scale_factor_scope[1],
resolution=0.05,
orient='horizontal', command=Update_Scale_Value)
self.scale_factor_scale.set(self.scale_factor) # 设置初始值
self.scale_factor_scale.bind('<ButtonRelease-1>', self.Scale_Image) # 松开才执行图片修改,防止大量修改图片卡顿
self.image_up_b = tk.Button(self.r_frame, text="+", command=lambda i=0.05: Change_Scale(i))
self.image_down_b = tk.Button(self.r_frame, text="-", command=lambda i=-0.05: Change_Scale(i))
self.image_down_b.grid(row=0, column=0)
self.scale_factor_scale.grid(row=0, column=1, columnspan=2)
self.image_up_b.grid(row=0, column=3)
# 选择保存的实例
def Select_Instance(i): # <和>按钮的回调
if self.now_instances < 0:
return
if i == 1:
if self.now_instances + 1 < self.instances_num:
self.now_instances += 1
else:
self.now_instances = 0
else:
if self.now_instances - 1 > -1:
self.now_instances -= 1
else:
self.now_instances = self.instances_num - 1
self.Select_Instance() # 按当前选中的实例设置gui
def Change_Checkbutton(): # 复选框回调
if self.now_instances < 0:
return
if self.hold.get() == 1: # 勾选了
self.hold_list[self.now_instances] = True
else: # 没有勾选
self.hold_list[self.now_instances] = False
if not self.now_mode.get() == 0:
self.Goto_Modle()
self.Select_Masks(self.now_instances)
self.instances_num = len(self.instance_image) # 总实例数目
self.hold_list = [False] * self.instances_num # 每个实例是否保留
self.masks = [] # 每个实例的掩膜
self.look_masks = [] # 显示的掩膜
self.masks_imgid = [] # 每个掩膜绘制后索引的id
self.instances_l_b = tk.Button(self.r_frame, text="<", command=lambda i=0: Select_Instance(i))
self.instances_r_b = tk.Button(self.r_frame, text=">", command=lambda i=1: Select_Instance(i))
self.hold = tk.IntVar() # 是否保留该实例
self.hold.set(0)
self.hold_b = tk.Checkbutton(self.r_frame, text="保留", variable=self.hold, command=Change_Checkbutton) # 保留实例选择框
self.instances_position = [tk.StringVar(), tk.StringVar(), tk.StringVar()] # 实例位置关联变量,实例序号,实例起始点,实例结束点
self.instances_position_l = [tk.Label(self.r_frame, textvariable=self.instances_position[0], anchor="w"),
tk.Label(self.r_frame, textvariable=self.instances_position[1], anchor="w"),
tk.Label(self.r_frame, textvariable=self.instances_position[2],
anchor="w")] # 三个标签来显示当前选中的实例位置
if not self.instances_num == 0: # 只有检测出实例的才执行,否则不执行
self.now_instances = 0
self.Select_Instance()
else:
self.now_instances = -1
def Display_Mask():
if self.display_mask.get() == 0: # 不显示:
self.image_canvas.delete("Select")
for i in range(self.instances_num):
self.image_canvas.itemconfig(self.masks_imgid[i], state="hidden")
else: # 显示:
self.show_Select()
for i in range(self.instances_num):
self.image_canvas.itemconfig(self.masks_imgid[i], state="normal")
self.image_canvas.update()
self.display_mask_b = tk.Checkbutton(self.r_frame, text="显示掩膜", variable=self.display_mask,
command=Display_Mask) # 保留实例选择框
self.instances_l_b.grid(row=1, column=0)
self.hold_b.grid(row=1, column=1, columnspan=2)
self.instances_r_b.grid(row=1, column=3)
self.display_mask_b.grid(row=2, column=0, columnspan=3)
tk.Label(self.r_frame, text=f"总实例数:{self.instances_num}").grid(row=2, column=2, columnspan=2)
self.instances_position_l[0].grid(row=3, column=0, columnspan=4)
self.instances_position_l[1].grid(row=4, column=0, columnspan=4)
self.instances_position_l[2].grid(row=5, column=0, columnspan=4)
# 选择模式,正常模式就是正常进行实例选择
self.now_mode = tk.IntVar()
self.now_mode.set(0)
# 正常模式
self.normal_mode = tk.Radiobutton(self.r_frame, text='正常模式', variable=self.now_mode, value=0,
command=self.Goto_Modle)
# 背景模糊
def Update_Ambiguity_Value(event):
# 获取滑条当前的值
current_value = self.ambiguity_scale.get()
self.ambiguity = current_value
def Whether_Goto_Modle(i):
if i == self.now_mode.get():
self.Goto_Modle()
self.background_blurred = tk.Radiobutton(self.r_frame, text='背景模糊', variable=self.now_mode, value=1,
command=self.Goto_Modle)
self.ambiguity = 20 # 模糊度
self.ambiguity_scale = tk.Scale(self.r_frame, from_=1, to=100, resolution=0.5, orient='horizontal',
command=Update_Ambiguity_Value)
self.ambiguity_scale.set(self.ambiguity) # 设置初始值
self.ambiguity_scale.bind('<ButtonRelease-1>', lambda e, i=1: Whether_Goto_Modle(i)) # 松开才执行
# 背景替换纯色
def select_color():
# 颜色选择对话框
color = colorchooser.askcolor()
if color:
_, self.background_color = color
Whether_Goto_Modle(2)
self.background_color = "#000000"
self.background_replacement = tk.Radiobutton(self.r_frame, text='背景纯色', variable=self.now_mode, value=2,
command=self.Goto_Modle)
# 选择替换纯色的颜色
self.choose_color = tk.Button(self.r_frame, text="选择颜色", command=select_color)
# 保存当前图片
def Save_Img():
self.master.Save_Image(img=self.now_image)
self.save_b = tk.Button(self.r_frame, text="保存当前图片", command=Save_Img)
self.open_save_path = tk.Button(self.r_frame, text="打开默认保存位置",
command=self.master.Open_Default_Save_Path) # 打开默认保存位置
self.normal_mode.grid(row=6, column=0, columnspan=2)
self.background_blurred.grid(row=7, column=0, columnspan=2)
self.ambiguity_scale.grid(row=7, column=2, columnspan=2)
self.background_replacement.grid(row=8, column=0, columnspan=2)
self.choose_color.grid(row=8, column=2, columnspan=2)
self.save_b.grid(row=10, column=0, columnspan=4)
self.open_save_path.grid(row=11, column=0, columnspan=4)
for i in range(12):
self.r_frame.rowconfigure(i, weight=1)
self.r_frame.rowconfigure(9, weight=5)
for i in range(4):
self.r_frame.columnconfigure(i, weight=1)
self.rowconfigure(0, weight=1)
self.columnconfigure(0, weight=5)
self.columnconfigure(1, weight=1)
self.Generating_Masks() # 生成掩膜
self.Scale_Image() # 显示图片
# 修改image_canvas显示的图片
def Change_Img(self, img):
self.look_image = ImageTk.PhotoImage(img) # 显示的图片
self.image_canvas.itemconfig(self.image_id, image=self.look_image)
self.image_canvas.configure(scrollregion=(0, 0, self.look_image.width(),
self.look_image.height())) # 更新Canvas的滚动区域
def Scale_Image(self, event=None): # 根据缩放系数显示图片以及掩膜
self.Change_Img(self.master.Zoom_Image(self.now_image, proportion=self.scale_factor))
if self.display_mask.get() == 0: # 不显示掩膜
pass
else:
for i in range(self.instances_num):
self.Select_Masks(i) # 显示掩膜
self.show_Select() # 显示当前实例红框
def Select_Masks(self, i): # 更新掩膜,如果显示按比例生成要显示的掩膜,并显示出来,否则替换显示为空白图片
if self.hold_list[i]: # 该实例要显示
self.look_masks[i] = ImageTk.PhotoImage( # 按当前比例生成掩膜
self.master.Zoom_Image(self.masks[i], proportion=self.scale_factor))
self.image_canvas.itemconfig(self.masks_imgid[i], image=self.look_masks[i], tag="mask") # 显示掩膜
else:
self.image_canvas.itemconfig(self.masks_imgid[i], image=self.none_image)
def Select_Instance(self): # 按当前选中的实例设置gui
pred_boxes = self.instance_image[self.now_instances].get("pred_boxes").tensor[0]
self.instances_position[0].set(f"当前实例:{self.now_instances + 1}")
self.instances_position[1].set(f"起始坐标:{int(pred_boxes[0])},{int(pred_boxes[1])}")
self.instances_position[2].set(f"结束坐标:{int(pred_boxes[2])},{int(pred_boxes[3])}")
if self.hold_list[self.now_instances]:
self.hold.set(1)
else:
self.hold.set(0)
self.show_Select()
def show_Select(self): # 显示当前选中的实例,一个外面的红边框
if self.now_instances >= 0:
self.image_canvas.delete("Select")
pred_boxes = self.instance_image[self.now_instances].get("pred_boxes").tensor[0]
self.image_canvas.create_rectangle(int(pred_boxes[0] * self.scale_factor),
int(pred_boxes[1] * self.scale_factor),
int(pred_boxes[2] * self.scale_factor),
int(pred_boxes[3] * self.scale_factor), outline="red", fill=None,
tag="Select")
# 生成每个实例的掩膜
def Generating_Masks(self):
for i in range(self.instances_num): # 每个实例生成一个掩膜
colour = (random.randint(0, 255), random.randint(0, 255), random.randint(0, 255), 192)
mask_array = np.array(self.instance_image[i].get("pred_masks")[0].to("cpu"))
mask_image = Image.fromarray(mask_array * 255, mode='L') # 创建一个PIL灰度图像
# 创建一个与mask_image相同大小的透明图像
transparent_image = Image.new('RGBA', mask_image.size, (0, 0, 0, 0))
draw = ImageDraw.Draw(transparent_image)
for y, row in enumerate(mask_array):
for x, value in enumerate(row):
if value:
draw.point((x, y), fill=colour)
self.masks.append(transparent_image) # 半透明随机颜色掩膜
# self.look_masks.append( # 用于显示的掩膜
# ImageTk.PhotoImage(self.master.Zoom_Image(self.masks[i], proportion=self.scale_factor)))
self.look_masks.append(self.none_image) # 用于显示的掩膜,初始都没有,所以整个空图片
self.masks_imgid.append(
self.image_canvas.create_image(0, 0, anchor="nw", image=self.look_masks[i], tag="mask")) # 显示掩膜
def Goto_Modle(self): # 根据当前模式启用或者禁用按钮,并修改self.now_image(当前处理的图片)
if self.now_mode.get() == 0:
self.now_image = self.image # 当前处理的图片
self.Scale_Image()
elif self.now_mode.get() == 1:
# 给整张图片虚化,然后将当前实例部分保持不变
self.now_image = self.image.filter(ImageFilter.GaussianBlur(radius=self.ambiguity))
self.Show_Instances()
self.Scale_Image()
elif self.now_mode.get() == 2:
self.now_image = Image.new('RGB', self.image.size, color=self.background_color)
self.Show_Instances()
self.Scale_Image()
def Show_Instances(self): # 显示实例,就是在当前图片上将该实例拓印下来
array_img = np.array(self.image)
array_now_img = np.array(self.now_image)
for i in range(self.instances_num):
if self.hold_list[i]:
mask_array = self.instance_image[i].get("pred_masks")[0].to("cpu")
# 将原图中对应为True的像素赋值给当前处理图片的对应位置
array_now_img[mask_array] = array_img[mask_array]
# 将NumPy数组转回PIL图像
self.now_image = Image.fromarray(array_now_img)
screen_recognition_window.py
# 屏幕识别窗口,还有一个选择屏幕区域的窗口和截取屏幕转为流的类
import time
import tkinter as tk # gui用
from threading import Thread
from tkinter import messagebox
import tkinter.filedialog # 文件相关窗口
import cv2
import numpy as np
from PIL import Image, ImageTk, ImageDraw
from mss import mss
class ScreenRecognitionWindow(tk.Toplevel):
def __init__(self, master, ip=False):
super().__init__(master) # 父类调用,
self.master = master
self.grab_set() # 独占焦点
if ip:
self.ip = f"http://{self.master.down_frame_screen.ip_e[1].get()}:{self.master.down_frame_screen.ip_e[2].get()}@{self.master.down_frame_screen.ip_e[0].get()}/"
self.title("网络摄像头识别")
self.capture = cv2.VideoCapture(self.ip)
# 尝试读取一帧
ret, img = self.capture.read()
if not ret:
tk.messagebox.showwarning(title='警告!', message='无法从摄像头中读取图片')
self.destroy()
return
self.monitor = {"top": 0
, "left": 0
, "width": img.shape[1]
, "height": img.shape[0]}
else:
self.ip = None
self.title("屏幕识别")
# 截取部分大小
self.monitor = {"top": self.master.up_frame_screen.position[0].get()
, "left": self.master.up_frame_screen.position[1].get()
, "width": self.master.up_frame_screen.position[2].get()
, "height": self.master.up_frame_screen.position[3].get()}
self.processing_mode = self.master.up_frame_screen.processing_mode.get() # 处理方式
self.scale_factor = self.master.up_frame_screen.scale_factor # 缩放系数
self.new_width = int(self.monitor["width"] * self.scale_factor) # 缩放后的大小
self.new_height = int(self.monitor["height"] * self.scale_factor)
self.now_width = self.monitor["width"]
self.now_height = self.monitor["height"]
# 设置大小和位置(设置为截取部分的大小)
self.geometry("%dx%d+0+0" % (self.monitor["width"], self.monitor["height"]))
self.canvas = tkinter.Canvas(self, width=self.monitor["width"], height=self.monitor["height"], )
self.image_id = self.canvas.create_image(0, 0, anchor="nw",
image=ImageTk.PhotoImage(Image.new('RGB', (0, 0)))) # 先不放图片
self.canvas.pack(fill=tk.BOTH, expand=True)
self.bind("<Configure>", self.On_Resize) # 绑定窗口大小改变事件
self.bind('<Button-1>', self.Button_Click) # 绑定鼠标左键点击事件
self.start_up = False
def destroy(self):
super().destroy()
if not self.ip is None:
self.capture.release()
def Button_Click(self, event):
if self.start_up:
return
else:
self.start_up = True
self.Handle()
def On_Resize(self, event):
# 计算新的宽度和高度,保持屏幕截图的比例
new_width = event.width
new_height = event.height
# print(new_width,new_height,self.monitor["width"],self.monitor["height"])
if new_width == self.now_width and new_height == self.now_height:
return
proportion = min(new_width / self.monitor["width"], new_height / self.monitor["height"])
self.now_width = int(proportion * self.monitor["width"])
self.now_height = int(proportion * self.monitor["height"])
self.geometry(f"{self.now_width}x{self.now_height}+{self.winfo_x()}+{self.winfo_y()}")
def Handle(self):
if self.ip is None:
if self.processing_mode == 0:
sct = mss() # 创建一个屏幕捕获对象
while True:
screenshot = np.uint8(sct.grab(self.monitor)) # 捕获屏幕截图
screenshot = cv2.resize(screenshot, (self.new_width, self.new_height)) # 修改大小
screenshot = cv2.cvtColor(screenshot, cv2.COLOR_RGB2BGR) # 将截图转换为OpenCV格式(BGR)
_, visualized_output = self.master.visualization.run_model_image(screenshot)
self.canvas.now_image = ImageTk.PhotoImage(
Image.fromarray(cv2.resize(visualized_output.get_image(), (self.now_width, self.now_height))))
self.canvas.itemconfig(self.image_id, image=self.canvas.now_image)
self.canvas.update() # 更新canvas以显示新图片
if not self.winfo_exists():
self.start_up = False
break
# time.sleep(0.01)
elif self.processing_mode == 1:
screen = Screen(self.monitor, self.scale_factor)
for vis in self.master.visualization.run_model_video(screen, screen=True):
self.canvas.now_image = ImageTk.PhotoImage(Image.fromarray( # 调整为窗口大小
cv2.resize(vis, (self.now_width, self.now_height))))
self.canvas.itemconfig(self.image_id, image=self.canvas.now_image)
self.canvas.update() # 更新canvas以显示新图片
if not self.winfo_exists():
self.start_up = False
break
# time.sleep(0.01)
else:
screen = Screen(self.monitor, self.scale_factor, ip=self.capture)
if self.processing_mode == 0:
while True:
ret, img = screen.next()
if not ret: # 没读取成功图片
self.start_up = False
break
_, visualized_output = self.master.visualization.run_model_image(img)
self.canvas.now_image = ImageTk.PhotoImage(
Image.fromarray(cv2.resize(visualized_output.get_image(), (self.now_width, self.now_height))))
self.canvas.itemconfig(self.image_id, image=self.canvas.now_image)
self.canvas.update() # 更新canvas以显示新图片
if not self.winfo_exists():
self.start_up = False
break
# time.sleep(0.01)
elif self.processing_mode == 1:
for vis in self.master.visualization.run_model_video(screen, screen=True):
self.canvas.now_image = ImageTk.PhotoImage(Image.fromarray( # 调整为窗口大小
cv2.resize(vis, (self.now_width, self.now_height))))
self.canvas.itemconfig(self.image_id, image=self.canvas.now_image)
self.canvas.update() # 更新canvas以显示新图片
if not self.winfo_exists():
self.start_up = False
break
# time.sleep(0.01)
screen.Stop()
class Screen(object): # 一个获取屏幕的对象,流式
def __init__(self, monitor=None, scale_factor=1, ip=None): # 初始化
if monitor is None:
monitor = {"top": 0, "left": 0, "width": 1920, "height": 1080}
self.ip = ip
if ip is None:
self.sct = mss() # 创建一个屏幕捕获对象
self.monitor = monitor # 定义捕获的屏幕区域
else:
# 预分配缓冲区
self.buffer = []
self.buffer_size = 8
self.get_ip = Thread(target=self.Get_IP_Img)
self.get_ip.start()
self.scale_factor = scale_factor # 缩放系数
self.new_width = int(monitor["width"] * scale_factor)
self.new_height = int(monitor["width"] * scale_factor)
self.stop=False
def Get_IP_Img(self): # 一直维持一个大小为self.buffer_size的缓冲区,
while True:
try:
while len(self.buffer) < self.buffer_size:
ret, img = self.ip.read()
self.buffer.append(cv2.cvtColor(img, cv2.COLOR_RGB2BGR))
if self.buffer:
self.buffer.pop(0) # 删除最老的帧
if self.stop:
break
except:
break
def Stop(self):
self.stop=True
def next(self):
if self.ip is None:
try:
screenshot = np.uint8(self.sct.grab(self.monitor)) # 捕获屏幕截图
screenshot = cv2.resize(screenshot, (self.new_width, self.new_height)) # 修改大小
screenshot = cv2.cvtColor(screenshot, cv2.COLOR_RGB2BGR) # 将截图转换为OpenCV格式(BGR)
except:
return False, None
return True, screenshot
else:
try:
if self.buffer:
img = self.buffer.pop(0)
screenshot = cv2.resize(img, (self.new_width, self.new_height))
return True, screenshot
else:
time.sleep(0.1)
if self.buffer:
img = self.buffer.pop(0)
screenshot = cv2.resize(img, (self.new_width, self.new_height))
return True, screenshot
else:
self.Stop()
return False, None
except:
self.Stop()
return False, None
class SelectScreenArea(tk.Toplevel): # 创建一个透明窗口,然后再在这个透明窗口上进行选择操作
# 仿照类似qq截屏的样子,想法是截屏+遮罩,遮罩用四个半透明矩形处理,只用更改右边和下面矩形的大小就行
def __init__(self, master):
super().__init__(master) # 父类调用,
self.master = master
sct = mss() # 在窗口显示出来之前截屏
monitors = sct.monitors # # 获取所有显示器的信息
self.m_width = monitors[0]["width"]
self.m_height = monitors[0]["height"]
# print(monitors)
self.screenshot = ImageTk.PhotoImage(
Image.fromarray(cv2.cvtColor(np.uint8(sct.grab(monitors[0])), cv2.COLOR_BGR2RGB)))
self.grab_set() # 独占焦点
# self.attributes("-fullscreen", True) # 设置全屏,这只能截取第一个屏幕(我是双屏)
self.overrideredirect(True) # 隐藏边框
self.geometry("{0}x{1}+0+0".format(self.m_width, self.m_height))
self.attributes("-topmost", True) # 设置窗口在最上层
self.configure(bg="blue") # 蓝色背景,看一看
# 一个有颜色画布遮挡住全部屏幕
self.canvas = tkinter.Canvas(self, width=self.m_width, height=self.m_height, )
self.canvas.pack(fill=tk.BOTH)
self.canvas.create_image(0, 0, anchor="nw", image=self.screenshot) # 整个屏幕的截图并放在画布上
self.canvas.update() # 更新canvas以显示新图片
self.canvas.create_text(0, 0, text="左键框选窗口,右键确定,esc退出", anchor="nw", font=("Arial", 20), fill="black")
self.image_masking = [ImageTk.PhotoImage(Image.new('RGB', (0, 0)))] * 4 # 四个遮罩
self.bind('<Button-1>', self.Button_Click) # 绑定鼠标左键点击事件
self.bind('<B1-Motion>', self.Button_Loosen) # 绑定鼠标左键点击移动事件
self.bind('<ButtonRelease-1>', self.Button_Movex) # 绑定鼠标左键点击释放事件
self.bind('<Button-3>', self.Button_Click_3) # 绑定鼠标右键点击事件
self.bind('<Escape>', lambda event: self.destroy()) # 绑定Esc按键退出事件,不返回输出
self.start = [0, 0]
self.end = [0, 0]
def Button_Click(self, event): # 按下
# 本来的考虑是按下就能防止最左边和最上面框,并且不用改,没想到还有往左上角拖动这一操作
self.start[0], self.start[1] = [event.x, event.y] # 保存开始位置
self.Set_Masking(event.x, event.y) # 设置遮罩
def Button_Loosen(self, event): # 移动
self.Set_Masking(event.x, event.y) # 设置遮罩
def Button_Movex(self, event): # 松开
self.end[0], self.end[1] = [event.x, event.y] # 保存结束位置
def Set_Masking(self, x, y): # 修改掩膜(遮罩)
if self.start[0] > x:
max_x = self.start[0]
min_x = x
else:
min_x = self.start[0]
max_x = x
if self.start[1] > y:
max_y = self.start[1]
min_y = y
else:
min_y = self.start[1]
max_y = y
size_x = self.m_width
size_y = self.m_height
self.canvas.delete("masking") # 删除之前的遮罩(不加也会没有,但感觉不安全)
self.image_masking[0] = ImageTk.PhotoImage(Image.new('RGBA', (min_x, size_y), (0, 0, 0, 128))) # 左遮罩
self.canvas.create_image(0, 0, anchor="nw", image=self.image_masking[0], tag="masking")
self.image_masking[1] = ImageTk.PhotoImage(Image.new('RGBA', (max_x - min_x, min_y), (0, 0, 0, 128))) # 上遮罩
self.canvas.create_image(min_x, 0, anchor="nw", image=self.image_masking[1], tag="masking")
self.image_masking[2] = ImageTk.PhotoImage(Image.new('RGBA', (size_x - max_x, size_y), (0, 0, 0, 128))) # 右遮罩
self.canvas.create_image(max_x, 0, anchor="nw", image=self.image_masking[2], tag="masking")
self.image_masking[3] = ImageTk.PhotoImage(Image.new('RGBA', (max_x - min_x, size_y - max_y), (0, 0, 0, 128)))
self.canvas.create_image(min_x, max_y, anchor="nw", image=self.image_masking[3], tag="masking") # 下遮罩
self.canvas.update() # 更新canvas以显示新图片
def Button_Click_3(self, event): # 右键保存输入
if self.start[0] > self.end[0]:
max_x = self.start[0]
min_x = self.end[0]
else:
min_x = self.start[0]
max_x = self.end[0]
if self.start[1] > self.end[1]:
max_y = self.start[1]
min_y = self.end[1]
else:
min_y = self.start[1]
max_y = self.end[1]
self.master.up_frame_screen.position[0].set(min_y)
self.master.up_frame_screen.position[1].set(min_x)
self.master.up_frame_screen.position[2].set(max_x - min_x)
self.master.up_frame_screen.position[3].set(max_y - min_y)
self.destroy()
if __name__ == '__main__':
main_window = tk.Tk()
SelectScreenArea(main_window)
main_window.up_frame_screen = tk.LabelFrame(main_window, text="屏幕")
main_window.up_frame_screen.position = [tk.IntVar(), tk.IntVar(), tk.IntVar(), tk.IntVar()]
main_window.mainloop() # 开启主循环,让窗口处于显示状态
set_up_window.py
# 设置窗口类,打开一个设置窗口
import tkinter as tk # gui用
from tkinter import messagebox
import tkinter.filedialog # 文件相关窗口
class SetUpWindow(tk.Toplevel):
def __init__(self, master):
super().__init__(master) # 父类调用,
self.master = master
self.title("设置")
self.grab_set() # 独占焦点
# 设置大小和位置(相对于父窗口左上角)
self.geometry("%dx%d+%d+%d" % (640, 192, master.winfo_x() + 128, master.winfo_y() + 128))
self.resizable(False, False) # 禁止缩放
# 仅仅先设置三个:默认模型位置,默认配置文件位置,默认保存位置,其他的什么并行,先不管。
self.default_path = [tk.StringVar(), tk.StringVar(), tk.StringVar()] # 文本框关联默认位置变量
self.default_path[0].set(master.default_path[0])
self.default_path[1].set(master.default_path[1])
self.default_path[2].set(master.default_path[2])
# 上半部分===================================================
self.data_frame = tk.LabelFrame(self, text="默认路径", ) # 一个标签框架,装除了保存取消按钮以外所有的设置项
data_len = 3
# 三个位置,每个给三个控件:标签,输入框,选择按钮。
self.data_dick = {}
self.data_dick["save_model"] = [tk.Label(self.data_frame, text="默认模型位置"),
tk.Entry(self.data_frame, textvariable=self.default_path[0]),
tk.Button(self.data_frame, text="请选择文件", command=self.Select_File)] # 默认模型位置控件
self.data_dick["save_yaml"] = [tk.Label(self.data_frame, text="模型配置位置"),
tk.Entry(self.data_frame, textvariable=self.default_path[1]),
tk.Button(self.data_frame, text="请选择文件", command=self.Select_Yaml)] # 模型配置位置控件
self.data_dick["save_path"] = [tk.Label(self.data_frame, text="默认保存位置"),
tk.Entry(self.data_frame, textvariable=self.default_path[2]),
tk.Button(self.data_frame, text="选择文件夹", command=self.Select_Folder)] # 默认保存位置控件
def Implement_Grid(list, row): # 将控件放好位置
list[0].grid(row=row, column=0, )
list[1].grid(row=row, column=1, )
list[2].grid(row=row, column=2, )
for i, j in zip(self.data_dick, range(data_len)):
Implement_Grid(self.data_dick[i], j)
for i in range(3): # 调整缩放比
self.data_frame.columnconfigure(i, weight=1)
self.data_frame.rowconfigure(i, weight=1)
self.data_frame.grid(row=0, column=0, sticky="wesn")
# 下半部分===================================================
self.button_frame = tk.LabelFrame(self, text="完成", ) # 一个标签框架,装除了保存取消按钮以外所有的设置项
save_button = tk.Button(self.button_frame, text="保存", command=self.Save_Settings)
cancel_button = tk.Button(self.button_frame, text="取消", command=self.destroy) # 直接关了,不管那么多
save_button.grid(row=0, column=0, )
cancel_button.grid(row=0, column=1, )
self.button_frame.grid(row=1, column=0, sticky="wesn")
self.rowconfigure(0, weight=data_len)
self.rowconfigure(1, weight=1)
self.columnconfigure(0, weight=1)
def Save_Settings(self): # 保存设置
self.master.Change_Path_Data([i.get() for i in self.default_path])
self.master.Initialize_Model()
messagebox.showinfo("保存成功", "设置已保存")
self.destroy() # 关闭窗口
def Select_File(self): # 选择文件
file_path = tk.filedialog.askopenfilename(filetypes=[("实例分割的模型文件", '*.pth')]) # 文件选择对话框
if file_path.strip() != '': # 是空的时候,往往没有选择,直接关闭窗口
self.default_path[0].set(file_path.strip()) # 将文本框值改变为新路径
def Select_Yaml(self): # 选择文件
file_path = tk.filedialog.askopenfilename(filetypes=[("实例分割的配置文件", '*.yaml')]) # 文件选择对话框
if file_path.strip() != '': # 是空的时候,往往没有选择,直接关闭窗口
self.default_path[1].set(file_path.strip()) # 将文本框值改变为新路径
def Select_Folder(self): # 选择文件夹
file_path = tk.filedialog.askdirectory()
if file_path.strip() != '': # 是空的时候,往往没有选择,直接关闭窗口
self.default_path[2].set(file_path.strip()) # 将文本框值改变为新路径
因为我电脑没摄像头,所以没设置电脑摄像头功能。















 2289
2289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









