







1 实验介绍
1.1 关于本实验
本实验介绍了信息提取的相关概念,如信息、信息熵,互信息等。其次介绍了正则表达式的基本语法和re模块。最后讲解了命名实体的相关信息及方法。
1.2 实验目的
了解信息提取的步骤及其应用;理解信息、信息熵、互信息等概念并掌握其计算。掌握正则表达式的应用;掌握命名实体识别常用方法.
2 相关概念
2.1 信息
信息泛指人类社会传播的一切内容,如音讯、消息、通信系统传输和处理的对象。信息可以通过“信息熵”被量化。1942年,香农(Shannon)在《通信的数学原理》论文中指出:“信息是用来消除随机不确定性的东西”。
2.2 信息熵
信息熵是系统中信息含量的量化指标,越不确定的事物,其信息熵越大。信息篇公式如下。
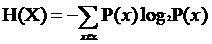
其中,P(x)表示事件x出现的概率。
当P=0或者1时,H(x)=0,即随机变量是完全确定的。
当P=0.5时,H(x)=1,即随机变量不确定性最大。
信息熵具有如下三条性质:
(1)单调性:发生概率越高的事件,信息嫡越低。例如,“太阳从东方升起”是确定事件,没有消除任何不确定性,所以不携带任何信息量。
(2)非负性:信息熵不能为负。
(3)累加性:多个事件发生总的信息熵等于各个事件的信息熵之和。
【任务1】计算信息熵
import numpy as np
# 熵定义函数
def entropy_func(data):
len_data =len(data)
entropy =0
for ix in set(data):
p_value=data.count(ix)/len_data
entropy -= p_value *np.log2(p_value)
return entropy
#各自产生20个数据,一个具有10个分类;另一个具有2个分类
n_count=20
b10_list=[]
a2_list=[]
for ix in range(n_count):
b10_list.append(np.random.randint(10))
a2_list.append(np.random.randint(2))
#b10_list代表10个类别
print("10个类别:",b10_list)
#a2_list代表2个类别
print("2个类别:",a2_list)
#输出两组数据的信息熵
print("10类数据的信息熵 ",entropy_func(b10_list))
print("2类数据的信息熵 ",entropy_func(a2_list))
程序运行结果如下:
10个类别: [4, 6, 9, 3, 0, 2, 2, 8, 4, 0, 6, 0, 3, 1, 1, 5, 9, 2, 8, 9]
2个类别: [0, 1, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0]
10类数据的信息熵 3.1086949695628423
2类数据的信息熵 0.9709505944546686
2.3 信息熵与霍夫曼编码
【例1】赌马比赛
已知4匹马分别是{a,b,c,d},其获胜概率分别为{1/2,1/4,1/8,1/8}。通过如下3个二元问题确定哪一匹马(x)赢得比赛。
问题1:a获胜了吗?
问题2:b获胜了吗?
问题3:c获胜了吗?
问答流程如下:
(1)如果x=a,需要提问1次(问题1)。
(2)如果x=b,需要提问2次(问题1,问题2)。
(3)如果x=c,需要提问3次(问题1,问题2,问题3)。
(4)如果x=d,需要提问3次(问题1,问题2,问题3)。
因此,确定x取值的二元问题数量为:

根据信息熵公式:

采用霍夫曼编码给{a,b,c,d}编码为{0,10,110,111},把最短的码0分配给发生概率最高的事件a,以此类推。
2.4 互信息
互信息是对两个离散型随机变量X和Y相关程度的度量;互信息越大,意味着两个随机变量的关联就越密切。
3 正则表达式
正则表达式,又称规则表达式、常规表示法(Regular Expression,RE),在代码中常简写为regex、regexp。正则表达式是指通过事先定义好的特定字符(“元字符")组成的“规则字符串”,对字符串进行过滤逻辑,凡是符合规则的字符串,认为“匹配”,否则认为不“匹配”。例如,要判断一个字符串是否包含合法的E-mail,就创建一个匹配E-mail的正则表达式,然后通过该正则表达式去判断过滤。
3.1 基本语法
正则表达式中的元字符如下表。
| 元字符 | 含义 | 输入 | 输出 |
|---|---|---|---|
| . | 匹配任意字符 | a.c | Abc |
| ^ | 匹配开始位置 | ^abc | Abc |
| $ | 匹配结束位置 | abc$ | Abc |
| * | 匹配前一个元字符0到多次 | abc* | ab;abccc |
| + | 匹配前一个元字符1到多次 | abc+ | abc;abccc |
| ? | 匹配前一个元字符0到1次 | abc? | ab;abc |
| {} | {m,n}匹配前一个字符m~n次,若省略n,则匹配m至无限次 | ab{1,2}c | abc或abbc |
| [] | 字符集中任意字符,可以逐个列出,也可以给出范围 | a[bcd]e | abe或ace或ade |
| | | 逻辑表达式"或” | abc|def | abc或def |
| () | 匹配括号中任意表达式 | a(123|456)c | a456c |
| \A | 匹配字符串开始位置 | \Aabc | Abc |
| \Z | 只在字符串结尾进行匹配 | abc\Z | Abc |
| \b | 匹配位于单词开始或结束位置的空字符串 | \babc\b | 空格abc空格 |
| \B | 匹配不位于单词开始或结束位置的空字符串 | a\Bbc | Abc |
| \d | 匹配一个数字,相当于[0一9] | a\dc | a1c |
| \D | 匹配非数字,相当于【^0一9】 | a\Dc | Abc |
| \w | 匹配数字、字母、下画线中任意一个字符,相当于[a一z A一z 0-9] | a\wc | Abc |
| \W | 匹配非数字、字母、下画线中的任意字符,相当于【^a一z A一z 0-9】 | a\Wc | a c |
3.2 re模块
re模块提供compile()、findall()、search()、match()、split()、replace()、sub()等函数用于实现正则表达式相关功能,如下表所示。
| 函数 | 描述 |
|---|---|
| compile() | 根据包含正则表达式的字符串创建模式对象 |
| findall() | 搜索字符串,以列表类型返回全部能匹配的子串 |
| search() | 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象 |
| match() | 从一个字符串的开始位置起匹配正则表达式,返回match对象 |
| split() | 将一个字符串按照正则表达式匹配结果进行分隔,返回列表类型 |
| replace() | 用于执行查找并替换的操作,将正则表达式匹配到的子串,用字符串替换 |
| sub() | 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串 |
3.2.1 compile()函数
功能:编译一个正则表达式语句,并返回编译后的正则表达式对象。compile()函数格式如下。
re.compile(string[,flags])
参数如下:
(1)string:要匹配的字符串。
(2)flags:标志位,用于控制正则表达式的匹配方式,如是否区分大小写等。
【任务2】compile()举例
import re
s="this is a python test"
p=re.compile('\w+') #青编译正则表达式,获得其对象
res=p.findall(s) #用正则表达式对象去匹配内容
print(res)
程序运行结果如下:
[‘this’,‘is’,‘a’,‘python’,‘test’]
3.2.2 findall()函数
功能:用于匹配所有符合规律的内容,返回包含结果的列表。
findall()函数格式如下。
re.findall(pattern,string[,flags])
参数如下:
pattern:匹配的正则表达式。
【任务3】findall()举例
import re
p=re.compile(r'\d+')
print (p.findall('o1n2m3k4'))
程序运行结果如下:
[‘1’, ‘2’, ‘3’, ‘4’]
3.2.3 search()函数
功能:用于匹配并提取第一个符合规则的内容,返回一个正则表达式对象。search()函数格式如下。
re.search(pattern,string[,flags])
【任务4】search()举例
import re
a="123abc456"
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0))
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1))
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2))
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3))
程序运行结果如下:
123abc456
123
abc
456
group()函数返回整体匹配的字符串,多个组号对应组号匹配的字符串。group(1)列出第一个括号匹配部分group(2)列出第二个括号匹配部分,group(3)列出第三个括号匹配部分。
3.2.4 match()函数
功能:从字符串的开头开始匹配一个模式,如果成功,返回成功的对象,否则返回None。
match()函数格式如下:
re.match(pattern,string[,flags])
【任务5】match()举例
import re
print (re.match('www','www.runoob.com').span()) #在起始位置匹配
print (re.match('com','www.runoob.com')) #不在起始位置匹配
程序运行结果如下:
(0, 3)
None
3.2.5 replace()函数
功能:用于执行查找并替换的操作,将正则表达式匹配到的子串,用字符串替换。replace()函数格式如下。
str.replace(regexp,replacement)
【任务6】replace()举例
str ="javascript";
str.replace('javascript','JavaScript') #将字符串javascript替我为JavaScript
程序运行结果如下:
‘JavaScript’
str.replace('a','b') #将所有的字母a替换为学母b,返回jbvbscript
程序运行结果如下:
‘jbvbscript’
3.2.6 split()函数
功能:用于分隔字符串,用给定的正则表达式进行分隔,分隔后返回结果列表。split()函数格式如下。
re.split (pattern,string[,maxaplit,fiags])
【任务7】split()举例
(1)只传一个参数,默认分隔整个字符申。
str="a,b,c,d,e"
str.split(',')
程序运行结果如下:
[‘a’, ‘b’, ‘c’, ‘d’, ‘e’]
str="a,b,c,d,e"
str.split(',',3)
程序运行结果如下:
[‘a’, ‘b’, ‘c’, ‘d,e’]
str="aa44bb55cc66dd";
print(re.split('\d+',str))
程序运行结果如下:
[‘aa’, ‘bb’, ‘cc’, ‘dd’]
3.2.7 sub()函数
功能:使用re替换字符串中每一个匹配的子串后返回替换后的字符串。sub()函数格式如下。
re.sub(regexp,string)
【任务8】sub()举例
import re
s='123abcssfasdfas123'
a=re.sub('123(.*?)123','1239123',s)
print(a)
程序运行结果如下:
1239123
3.3 提取电影信息
【任务9】爬取豆瓣电影的网址,提取“电影名”信息
豆瓣电影上海热映的电影网址如下:url=https:/movie.douban.com/cinema/nowplaying/shanghai/。
代码如下:
#用于获取豆瓣热映的电影信息:
import requests # 爬虫库
import re # 正则表达式
def getHTMLText(url):
try:
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36 chrome-extension'}
r = requests.get(url,headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("Erro_get")
#用于提取所需要的电影信息:
def parsePage(ilt,html):
tlt = re.findall(r'data-title\=\".*?\"',html)
for i in range(len(tlt)):
plt = eval(tlt[i].split('=')[1])
if plt in ilt:
pass
else:
ilt.append(plt)
#用于输出电影列表:
def printInfo(ilt):
print("上 海 热 映")
for i in ilt:
print(i)
#主函数
def main():
url = 'https://movie.douban.com/cinema/nowplaying/shanghai/'
list = []
html = getHTMLText(url)
parsePage(list,html)
printInfo(list)
main()
程序运行结果如下:
上 海 热 映
旺卡
瞒天过海
涉过愤怒的海
爆裂点
照明商店
再见,李可乐
拿破仑
河边的错误
热搜
我本是高山
蜡笔小新:新次元!超能力大决战
飞鸭向前冲
饥饿游戏:鸣鸟与蛇之歌
刀尖
星愿
沉默笔录
傍晚向日葵
惊奇队长2
红猪
无价之宝
志愿军:雄兵出击
开国将帅授衔1955
拯救嫌疑人
不要走散好不好
疾速营救
仲肯
诡摇铃
吾爱敦煌
开山人
坚如磐石
一个和四个
最后一夜
大话西游之大圣娶亲
珍·古道尔的传奇一生
千里送鹤
萨瓦流淌的方向
红高粱
汪汪队立大功大电影2:超能大冒险
看不见的顶峰
蚂蚁传奇之终极一战
站直啰,别趴下
盗马贼
盲流
错位
碧玉簪
党的女儿
洛神
苏武牧羊
狗神
三大队
月光武士
陀螺女孩
狭路“箱”逢
逆境追凶
名侦探柯南:黑铁的鱼影
怒潮
海王2:失落的王国
爱乐之城
4 命名实体识别
4.1认识命名实体
命名实体识别(Named Entity Recognition,NER),又称作“专名识别",是指在文档集合中识别出特定类型的事物名称或符号的过程,进行三大类(实体类、时间类和数字类)和七小类(人名、机构名、地名、时间、日期、货币和百分比)的实体识别,具体如下。
(1)实体名(Entity Name),包括人名、地名、机构名。
(2)时间表达式(Temporal Expressions),包括日期、时间和持续时间。
(3)数字表达式(Number Expressions),包括钱、度量、百分比以及基数。
4.2 常见方法
早期的命名实体识别方法大都是基于规则,由于每个新领域的文本需要更新规则,代价往往非常大。自20世纪0年代后期以来,基于大规模语料库的统计方法逐新成为自然语言处理的主流,命名实体识别常见方法分为以下几类。
(1)有监督的学习方法
目前常用的模型成方法包括隐马尔可大模型、语言模型、最大熵模型、支特向量机、决策树和条件随机场等,其中,条件随机场(Conditional Random Field,CRP)是由McCallum等人在2003年发明,与基于字的汉语分词方法的原理一样,就是把命名实体识别过程看作个序列标注问题,将给定文本首先进行分词处理,然后对人名、简单地名和简单的组织机构名进行识别,最后识别复合地名和复合组织机构名。简单地名是指地名中不嵌套包含其他地名,如“西安市”等,而“西安市长安区西长安街618号“则为复合地名。同样,简单的组织机构名中也不嵌套包括其他组织机构名,如“西安邮电大学”等,而“中华人民共和国国家卫生健康委员会”为复合组织机构名。基于CRF的命名实体识别方法属于有监督的学习方法,需要利用已标注的大规模语料对CRF模型的参数进行训练。
(2)半监督的学习方法
利用标注的小数据集(种子数据)自举学习。
(3)无监督的学习方法
利用词汇资源(如WordNet)等进行上下文聚类。
(4)混合方法
几种模型相结合或利用统计方法和人工总结的知识库。
【任务10】中文命名实体识别
#语料初始化的实现
import joblib
import sklearn_crfsuite
class CorpusProcess(object):
# 由词性提取标签
def pos_to_tag(self, p):
t = self._maps.get(p, None)
return t if t else 'O'
# 标签使用BIO模式
def tag_perform(self, tag, index):
if index == 0 and tag != 'O':
return 'B_{}'.format(tag)
elif tag != 'O':
return 'I_{}'.format(tag)
else:
return tag
#全角转半角
def q_to_b(self, q_str):
b_str = ""
for uchar in q_str:
inside_code = ord(uchar)
if inside_code == 12288: # 全角空格直接转换
inside_code = 32
elif 65374 >= inside_code >= 65281: # 全角字符(除空格)根据关系转化
inside_code -= 65248
b_str += chr(inside_code)
return b_str
# 语料初始化
def initialize(self):
lines = self.read_corpus_from_file(self.process_corpus_path)
words_list = [line.strip().split(' ') for line in lines if line.strip()]
del lines
self.init_sequence(words_list)
# 初始化字序列、词性序列
def init_sequence(self, words_list):
words_seq = [[word.split('/')[0] for word in words] for words in words_list]
pos_seq = [[word.split('/')[1] for word in words] for words in words_list]
tag_seq = [[self.pos_to_tag(p) for p in pos] for pos in pos_seq]
self.tag_seq = [[[self.tag_perform(tag_seq[index][i], w)
for w in range(len(words_seq[index][i]))]
for i in range(len(tag_seq[index]))]
for index in range(len(tag_seq))]
self.tag_seq = [[t for tag in tag_seq for t in tag] for tag_seq in self.tag_seq]
self.word_seq = [['<BOS>'] + [w for word in word_seq for w in word]
+ ['<EOS>'] for word_seq in words_seq]
#训练数据的实验过程
# 窗口切分
def segment_by_window(self, words_list=None, window=3):
words = []
begin, end = 0, window
for _ in range(1, len(words_list)):
if end > len(words_list):
break
words.append(words_list[begin: end])
begin = begin + 1
end = end + 1
return words
# 特征提取
def extract_feature(self, word_grams):
features, feature_list = [], []
for index in range(len(word_grams)):
for i in range(len(word_grams[index])):
word_gram = word_grams[index][i]
feature = {'w-1': word_gram[0],
'w': word_gram[1], 'w+1': word_gram[2],
'w-1:w': word_gram[0] + word_gram[1],
'w:w+1': word_gram[1] + word_gram[2],
'bias': 1.0}
feature_list.append(feature)
features.append(feature_list)
feature_list = []
return features
# 训练数据
def generator(self):
word_grams = [self.segment_by_window(word_list) for word_list in self.word_seq]
features = self.extract_feature(word_grams)
return features, self.tag_seq
#模型训练的实现过程
class CRF_NER(object):
# 初始化CRF模型参数
def __init__(self):
self.algorithm = 'lbfgs'
self.c1 = '0.1'
self.c2 = '0.1'
self.max_iterations = 100 # 迭代次数
self.model_path = './data/model.pkl'
self.corpus = CorpusProcess() # 加载语料预处理模块
self.model = None
# 定义模型
def initialize_model(self):
self.corpus.pre_process() # 语料预处理
self.corpus.initialize() # 初始化语料
algorithm = self.algorithm
c1 = float(self.c1)
c2 = float(self.c2)
max_iterations = int(self.max_iterations)
self.model = sklearn_crfsuite.CRF(algorithm=algorithm, c1=c1, c2=c2,
max_iterations=max_iterations,
all_possible_transitions=True)
# 模型训练
def train(self):
self.initialize_model()
x, y = self.corpus.generator()
x_train, y_train = x[500: ], y[500: ]
x_test, y_test = x[: 500], y[: 500]
self.model.fit(x_train, y_train)
labels = list(self.model.classes_)
labels.remove('O')
y_predict = self.model.predict(x_test)
metrics.flat_f1_score(y_test, y_predict, average='weighted', labels=labels)
sorted_labels = sorted(labels, key=lambda name: (name[1: ], name[0]))
print(metrics.flat_classification_report(
y_test, y_predict, labels=sorted_labels, digits=3))
# 保存模型
joblib.dump(self.model, self.model_path)
#模型预测的实现过程
def predict(self, sentence):
# 加载模型
self.model = joblib.load(self.model_path)
u_sent = self.corpus.q_to_b(sentence)
word_lists = [['<BOS>'] + [c for c in u_sent] + ['<EOS>']]
word_grams = [
self.corpus.segment_by_window(word_list) for word_list in word_lists]
features = self.corpus.extract_feature(word_grams)
y_predict = self.model.predict(features)
entity = ''
for index in range(len(y_predict[0])):
if y_predict[0][index] != 'O':
if index > 0 and(
y_predict[0][index][-1] != y_predict[0][index - 1][-1]):
entity += ' '
entity += u_sent[index]
elif entity[-1] != ' ':
entity += ' '
return entity
#使用训练完成的模型进行预测
ner=CRF_NER()
sentence1 = '2019年10月1日是新中国成立70周年的大日子,6时10分11万余名群众'\
'在天安门,观看了隆重的升旗仪式。8时香港特区政府也在湾仔金紫荆广场'\
'举行了隆重的升旗仪式。10时开始举行阅兵和群众游行,央视新闻媒体进行'\
'不间断的直播。'
output1 = ner.predict(sentence1)
print(output1)
sentence2 = '香港回归23周年升旗仪式今天(7月1日)8时在金紫荆广场举行。行政长官'\
'林郑月娥、一众特区政府官员、中央机构驻港代表及外国驻港使节等约100人出席。'
output2 = ner.predict(sentence2)
print(output2)
程序运行结果如下:
2019年10月1日 中国 6时10分 天安门 8时 香港特区政府 湾仔金紫荆广场 10时
香港 今天 7月1日 8时 金紫荆广场 官林郑月娥
4.3 NLTK命名实体识别
NLTK和Stanford NLP中对命名实体识别的分类,如下表所示。其中,LOCATION和GPE有重合。GPE通常表示地理-政治条目,如城市、州、国家等,LOCATION除了上述内容外,还能表示名山大川等。FACILITY通常表示知名的纪念碑等。
| 命名实体识别类别 | 举例 | 命名实体识别类别 | 举例 |
|---|---|---|---|
| PERSON | President Obama | MONEY | Twenty dollars |
| ORGANIZATION | WHO | PERCENT | 25% |
| LOCATION | Germany | FACILITY | Washington |
| DATE | May,2020-05-03 | GPE | Asia |
| TIME | 10:15:00 AM |
基于NLTK进行命名实体识别分为如下步骤。
步骤1:使用句子分隔器将文档分隔成句,采用nltk.sent_tokenize(text)实现。
步骤2:使用分词器将句子分隔成词,采用nltk.word_tokenize(sent)实现。
步骤3:标记词性,采用nltk.pos_tag(sent)实现。
步骤4:实体识别,得到一个树的列表。
步骤5:关系识别,寻找实体之间的关系,得到一个元组列表。
【任务11】NLTK进行命名实体识别举例(Pycharm中可运行)
import re
import pandas as pd
import nltk
def parse_document(document):
document = re.sub('\n', ' ', document)
if isinstance(document, str):
document = document
else:
raise ValueError('Document is not string!')
document = document.strip()
sentences = nltk.sent_tokenize(document)
sentences = [sentence.strip() for sentence in sentences]
return sentences
# 示例文档
text = """
FIFA was founded in 1904 to oversee international competition among the national associations of Belgium, Denmark, France, Germany, the Netherlands, Spain, Sweden, and Switzerland. Headquartered in Zürich, its membership now comprises 211 national associations. Member countries must each also be members of one of the six regional confederations into which the world is divided: Africa, Asia, Europe, North & Central America and the Caribbean, Oceania, and South America.
"""
# 分词句子
sentences = parse_document(text)
tokenized_sentences = [nltk.word_tokenize(sentence) for sentence in sentences]
# 标记句子并使用nltk的命名实体块
tagged_sentences = [nltk.pos_tag(sentence) for sentence in tokenized_sentences]
ne_chunked_sents = [nltk.ne_chunk(tagged) for tagged in tagged_sentences]
# 提取所有命名实体
named_entities = []
for ne_tagged_sentence in ne_chunked_sents:
for tagged_tree in ne_tagged_sentence:
# 仅提取具有NE标签的块
if hasattr(tagged_tree, 'label'):
entity_name = ' '.join(c[0] for c in tagged_tree.leaves()) # 获取NE名称
entity_type = tagged_tree.label() # 获取NE类别
named_entities.append((entity_name, entity_type))
# 获取唯一的命名实体
named_entities = list(set(named_entities))
# 将命名实体存储在数据框中
entity_frame = pd.DataFrame(named_entities, columns=['实体名称', '实体类型'])
# 显示结果
print(entity_frame)
程序运行结果如下:
Entity Name Entity Type
0 Africa PERSON
1 Europe GPE
2 Caribbean LOCATION
3 France GPE
4 FIFA ORGANIZATION
5 South America GPE
6 Asia GPE
7 Germany GPE
8 Switzerland GPE
9 Spain GPE
10 Zürich GPE
11 Netherlands GPE
12 Central America ORGANIZATION
13 Oceania GPE
14 Denmark GPE
15 North GPE
16 Belgium GPE
17 Sweden GPE
NLTK中的命名实体识别效果大致可以,能够识别FIFA为组织(ORGANIZATION),Belgium、Asia为GPE。但也有一些错误,如将Central America识别为ORGANIZATION,本来应该是GPE;将Africa识别为PERSON,实际上应该为GPE。
4.4 Stanford NLP命名实体识别
Stanford NLP基于Java。其英语命名实体识别的文件包的下载地址为https:/nlp.stanford.edu/software/CRF-NER.shtml,本机下载stanford-ner-4.2.0.zip。
本机安装Java路径为C:\Program Files\Java\jdk1.8.0_151\bin\java.exe,下载Stanford NER的zip文件解压后路径为D:\stanford-ner-4.2.0\stanford-ner-2020-11-17。
在classifer文件夹中的文件。
文件含义如下:
3 class:Location,Person,Organization
4 class:Location,Person,Organization,Misc
7 class:Location,Person,Organization,Money,Percent,Date,Time
【任务12】Stanford NLP进行命名实体识别举例
import re
from nltk.tag import StanfordNERTagger
import os
import pandas as pd
import nltk
def parse_document(document):
document = re.sub('\n', ' ', document)
if isinstance(document, str):
document = document
else:
raise ValueError('Document is not string!')
document = document.strip()
sentences = nltk.sent_tokenize(document)
sentences = [sentence.strip() for sentence in sentences]
return sentences
# sample document
text = """
FIFA was founded in 1904 to oversee international competition among the national associations of Belgium, Denmark, France, Germany, the Netherlands, Spain, Sweden, and Switzerland. Headquartered in Zürich, its membership now comprises 211 national associations. Member countries must each also be members of one of the six regional confederations into which the world is divided: Africa, Asia, Europe, North & Central America and the Caribbean, Oceania, and South America."""
sentences = parse_document(text)
tokenized_sentences = [nltk.word_tokenize(sentence) for sentence in sentences]
# set java path in environment variables
java_path = r'C:\Program Files\Java\jdk1.8.0_161\bin\java.exe'
os.environ['JAVAHOME'] = java_path
# load stanford NER
sn = StanfordNERTagger('./english.muc.7class.distsim.crf.ser.gz',path_to_jar='./stanford-ner.jar')
# tag sentences
ne_annotated_sentences = [sn.tag(sent) for sent in tokenized_sentences]
# extract named entities
named_entities = []
for sentence in ne_annotated_sentences:
temp_entity_name = ''
temp_named_entity = None
for term, tag in sentence:
# get terms with NE tags
if tag != 'O':
temp_entity_name = ' '.join([temp_entity_name, term]).strip() #get NE name
temp_named_entity = (temp_entity_name, tag) # get NE and its category
else:
if temp_named_entity:
named_entities.append(temp_named_entity)
temp_entity_name = ''
temp_named_entity = None
# get unique named entities
named_entities = list(set(named_entities))
# store named entities in a data frame
entity_frame = pd.DataFrame(named_entities, columns=['Entity Name', 'Entity Type'])
# display results
print(entity_frame)
程序运行结果如下:
Entity Name Entity Type
0 FIFA ORGANIZATION
1 Switzerland LOCATION
2 Sweden LOCATION
3 1904 DATE
4 Africa LOCATION
5 Belgium LOCATION
6 Denmark LOCATION
7 the Netherlands LOCATION
8 Asia LOCATION
9 Europe LOCATION
10 Zürich LOCATION
11 North & Central America ORGANIZATION
12 Caribbean LOCATION
13 Oceania LOCATION
14 Germany LOCATION
15 South America LOCATION
16 Spain LOCATION
17 France LOCATION















 522
522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









