







1 实验介绍
1.1 关于本实验
信息分类的评价指标一般有以下几个:混淆矩阵、准确率、精准率、召回率、F1 Score值、ROC曲线、AUC面积和分类评估报告。重点介绍了Sklearn的分类评价指标的函数和方法。讲解了中文分词的指标以及未登录词和登录词召回率。
1.2 实验目的
了解信息分类的常见指标;理解混淆矩阵、准确率、精确率、召回率、F1 Score、ROC曲线、AUC面积的作用;掌握混淆矩阵、准确率、精确率、召回率、F1 Score、ROC曲线、AUC面积的计算。
2 Sklearn中的评价指标
评价模型的合理性、有效性,不同的机器学习任务有不同的评价指标,同一任务有时也会因为侧重点的不同具有不同的评价指标。sklearn.metrics模型评价指标有混淆矩阵、准确率、召回率、F1 Score、ROC曲线和AUC面积等,如下表所示。
| 术语 | Sklearn函数 | 术语 | Sklearn函数 |
|---|---|---|---|
| 混淆矩阵 | confusion_matrix | ROC曲线 | roc_curve |
| 准确率 | accuracy_score | AUC面积 | roc_auc_score |
| 召回率 | recall_score | 分类评估报告 | classification_report |
| F1 Score | f1_score |
3 混淆矩阵
3.1 认识混淆矩阵
混淆矩阵又称为可能性表格,错误矩阵或分类矩阵,用于评估模型的预测精度,检查模型是否在预测时出现明显的错误,是衡量分类型模型准确度中最基本、最简单的方法。混淆矩阵由”行”列组成,列代表预测值,行代表真实值。每列总数表示预测为该类别的数据数目,每行总数表示该类别数据的真实数目。混淆矩阵如表13-2所示。
混淆矩阵的所有正确的预测结果都在对角线上,对角线之外的数据是预测错误结果,混淆矩阵具有如下特性。
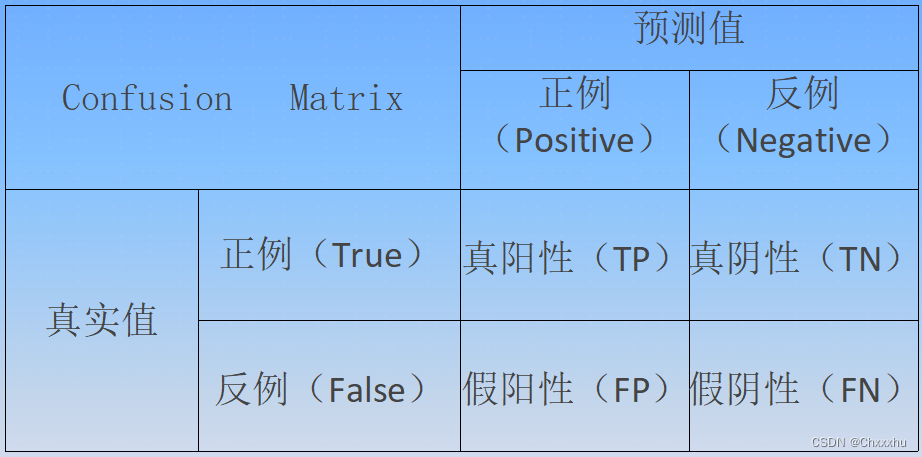
(1)样本全集=TPUFPUFNUTN。
(2)一个样本属于且只属于N*N集合中的一个。
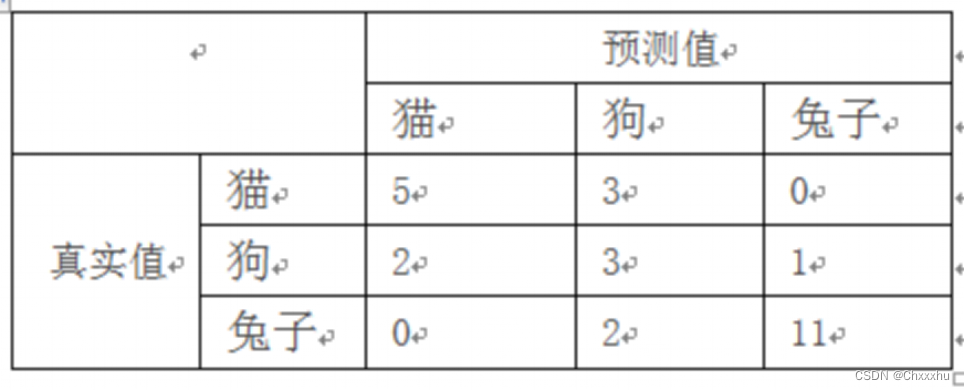
【例1】 混淆矩阵
现有 27只动物,其中8只猫、6条狗和13只兔子,对猫、狗、兔子进行分类的混淆矩阵中,将8只猫中3只预测成为狗;6条狗中 1条预测成兔子,还有2条预测成猫。13只兔子中2条预测成了狗;如下图所示。
3.2 Pandas计算混淆矩阵
混淆矩阵本质上就是列联表,Pandas提供crosstab()函数求得列联表,语法形式如下:
pd.crosstab(index,columns,values=None)
参数如下:
(1)index:指定了要分组的列,最终作为行。
(2)columns:指定了要分组的列,最终作为列。
(3)values:指定了要聚合的值(由行列共同影响)。
【任务1】Pandas的crosstab()函数
import pandas as pd
results =pd.DataFrame()
results['True']=[1,2,2,2,2]
results['Pred']=[2,2,1,2,1]
#pd.crosstab得到混淆矩阵
print (pd.crosstab(results['True'],results['Pred']))
程序运行结果如下:
Pred 1 2
True
1 0 1
2 2 2
True值有不重复的1和2,Pred值有1和2。交叉后组成了新的数据,具体的值为对应行列上的组合在原数据中的数量。
3.3 Sklearn计算混淆矩阵
sklearn.metrics模块提供confusion_matrix()函数用于混淆矩阵,语法形式如下:
sklearn.metrics.confusion_matrix(y_true,y_pred,labels)
参数如下:
(1)y_true:真实目标值。
(2)y_pred:估计器预测目标值。
(3)labels:指定类别对应的数字。
【任务2】Sklearn的confusion_matrix()函数
from sklearn.metrics import confusion_matrix
y_true=[2,0,2,2,0,1]
y_pred=[0,0,2,2,0,2]
print ("confusion_matrix\n",confusion_matrix(y_true,y_pred))
y_true =["cat","ant","cat","cat","ant","bird"]
y_pred =["ant","ant","cat","cat","ant","cat"]
print("confusion_matrix\n",confusion_matrix(y_true,y_pred,labels=["ant","bird","cat"]))
程序运行结果如下:
confusion_matrix
[[2 0 0]
[0 0 1]
[1 0 2]]
confusion_matrix
[[2 0 0]
[0 0 1]
[1 0 2]]
4 准确率
4.1 认识准确率
准确率(Accuracy,ACC)是最常用的分类性能指标。准确率=预测正确样本数/总样本数,公式如下:
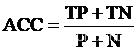
4.2 Sklearn计算准确率
sklearn.metrics模块提供accuracy_score()函数计算准确率,语法形式如下。
sklearn.metrics.accuracy_score(y_true,y_pred,normalize)
参数说明如下:
(1)y_true:真实目标值。
(2)y_pred:估计器预测目标值。
(3)normalize:默认值为True,返回正确分类的比例;False返回正确分类的样本数。
【任务3】accuracy_score()举例
import numpy as np
from sklearn.metrics import accuracy_score
y_pred=[0,2,1,3]
y_true=[0,1,2,3]
print(accuracy_score(y_true,y_pred))
print(accuracy_score(y_true,y_pred,normalize=False))
程序运行结果如下:
0.5
2
5 精确率
5.1认识精确率
精确率(Precision)又称为查准率,容易和准确率混淆。精确率只是针对预测正确的正样本而不是所有预测正确的样本,是正确预测的正例数/预测正例总数,公式如下。
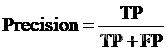
5.2 Sklearn计算精确率
sklearn.metrics模块提供precision_score()函数计算精确率,语法形式如下。
sklearn.metrics.precision_score(y_true,y_pred)
参数如下:
(1)y_true:真实目标值。
(2)y_pred:估计器预测目标值。
【任务4】Sklearn计算精确率。
from sklearn.metrics import precision_score
import numpy as np
y_true=np.array([1,0,1,1])
y_pred=np.array([0,1,1,0]) #预测正例1
p=precision_score(y_true,y_pred) #输出结果0.5
print (p)
程序运行结果如下:
0.5
6 召回率
6.1 认识召回率
召回率(Recall)是覆盖面的度量,是正确预测的正例数/实际正例总数,公式如下。

召回率又名查全率,与精确率是一对矛盾的度量。召回率和精确率计算公式的分子都是真阳的样本数。但是精确率的分母是预测阳性的数量;召回率的分母是真实阳性的数量。召回率体现模型对正样本的识别能力,而精确率体现了模型对负样本的区分能力。因此,当精确率高时,召回率往往偏低;而召回率高时,精确率往往偏低。
6.2 Sklearn计算召回率
sklearn,metrics模块提供recall_score()函数计算召回率,语法形式如下。
sklearn.metrics.recall_score(y_true,y_pred,average)
参数如下:
(1)y_true:真实目标值。
(2)y_pred:估计器预测目标值。
(3)average:可取值有micro、macro、weighted。
【任务5】Sklearn计算召回率
from sklearn.metrics import recall_score
y_true=[0,1,2,0,1,2]
y_pred=[0,2,1,0,0,1]
print(recall_score(y_true,y_pred,average='macro'))
print(recall_score(y_true,y_pred,average='micro'))
print(recall_score(y_true,y_pred,average='weighted'))
print(recall_score(y_true,y_pred,average=None))
程序运行结果如下:
0.3333333333333333
0.3333333333333333
0.3333333333333333
[1. 0. 0.]
7 F1 Score
7.1 认识F1 Score
当精确率和召回率都高时,F1的值也会高。在两者都要求高的情况下,可以用F1来衡量,F1 Score用于衡量二分类模型精确度,是精确率和召回率的调和值,变化范围为0~1。F1 Score计算公式如下。
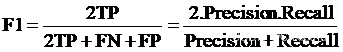
7.2 Sklearn计算F1 Score
sklearn.metrics模块提供f1_score()函数,形式如下所示。
sklearn.metrics.f1_acore(y_true,y_pred,average=“micro”)
参数说明如下:
(1)y_true:真实目标值。
(2)y_pred:估计器预测目标值。
【任务6】Sklearn计算F1值
from sklearn import metrics
y_true=[0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,2,2,2,2,2,2,2,2]
y_pred=[1,1,0,2,2,0,1,1,1,1,2,1,1,2,2,1,2,2,2,2,2,2,1,1]
F1=metrics.f1_score(y_true,y_pred,average="micro")
print("F1:",F1)
程序运行结果如下:
F1: 0.625
8 Python计算评价指标
load_digits数据集是sklearn.datasets中内置的手写数字图片数据集,用于图像分类算法,本例计算load_digits数据集的分类是混淆矩阵、准确度、召回率等指标。
【任务7】python计算评价指标举例
import numpy as np
import pandas as pd
from sklearn import datasets
d=datasets.load_digits()
x=d.data
y=d.target.copy() #防止原来数据改变
print(len(y))
y[d.target==9]=1
y[d.target!=9]=0
print(y)
#统计各个数据出现的个数
print(pd.value_counts(y))
#划分数据集为训练数据和测试数据
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=666)
#使用计算学习算法——逻辑回归算法进行数据分类
from sklearn.linear_model import LogisticRegression
log_reg=LogisticRegression(solver="newton-cg")
log_reg.fit(x_train,y_train)
print(log_reg.score(x_test,y_test))
y_pre=log_reg.predict(x_test)
#计算TN、FP、FN和TP
def TN(y_true,y_pre):
return np.sum((y_true==0) & (y_pre==0))
def FP(y_true,y_pre):
return np.sum((y_true==0) & (y_pre==1))
def FN(y_true,y_pre):
return np.sum((y_true==1) & (y_pre==0))
def TP(y_true,y_pre):
return np.sum((y_true==1) & (y_pre==1))
print(TN(y_test,y_pre))
print(FP(y_test,y_pre))
print(FN(y_test,y_pre))
print(TP(y_test,y_pre))
#混淆矩阵的定义
def confusion_matrix(y_true,y_pre):
return np.array([
[TN(y_true,y_pre),FP(y_true,y_pre)],
[FN(y_true,y_pre),TP(y_true,y_pre)]
])
print(confusion_matrix(y_test,y_pre))
#精准率
def precision(y_true,y_pre):
try:
return TP(y_true,y_pre)/(FP(y_true,y_pre)+TP(y_true,y_pre))
except:
return 0.0
print(precision(y_test,y_pre))
#召回率
def recall(y_true,y_pre):
try:
return TP(y_true,y_pre)/(FN(y_true,y_pre)+TP(y_true,y_pre))
except:
return 0.0
print(recall(y_test,y_pre))
程序运行结果如下:
1797
[0 0 0 … 0 1 0]
0 1617
1 180
dtype: int64
0.9844444444444445
404
1
6
39
[[404 1]
[ 6 39]]
0.975
0.8666666666666667
9 ROC曲线
9.1 认识ROC曲线
通过阈值进行类别区分,通常将大于阈值的样本认为是正类,小于阈值的样本认为是负类。如果减小阀值,正类的样本会增多,也会使得原先的负类被错误识别为正类。为了直观表示这一现象,引入ROC。ROC即Receiver Operating Characteristic,翻译为“受试者工作特征”曲线,在机器学习领域用来评判分类效果。
ROC曲线用于描述混淆矩阵中FPR-TPR两个量之间的相对变化情况,横轴是FPR(False Positive Rate,伪阳率),纵轴是TPR(True Positive Rate,真阳率),公式如下。
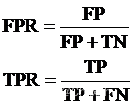
9.2 Sklearn 计算ROC曲线
sklearn.metrics模块提供roc_curve()函数计算ROC曲线,语法形式如下。
sklearn.metrics.roc_curve(y_true,y_score)
参数如下。
(1)y_true:每个样本的真实类别,0为反例,1为正例。
(2)y_score:预测得分,可以是正类的估计概率。
【任务8】roc_curve()举例
import numpy as np
import matplotlib.pyplot as plt
from sklearn import metrics
from sklearn.metrics import roc_auc_score
#y_true=np.array([0,0,1,1])
#ty_scores=np.array([0.1,0.4,0.35,0.8])
y_true=np.array([1,1,2,2])
y_scores=np.array([0.1,0.4,0.35,0.8])
#计算ADC
auc_test=roc_auc_score(y_true,y_scores)
#计算ROC
fpr,tpr,thresholds=metrics.roc_curve(y_true,y_scores,pos_label=2)
print("fpr:",fpr)
print ("tpr:",tpr)
print (thresholds)
plt.plot (fpr,tpr,color='red')
plt.plot([0,1],[0,1],color='yellow',linestyle='--')
plt.xlim([0.0,1.0])
plt.ylim([0.0,1.08])
plt.xlabel('FPR')
plt.ylabel('TPR')
#plt.annotate(xy=(.4,.2),xytext=(.5,.2),s='ROC curve(area=%0.2f)'%auc_test)
from sklearn.metrics import auc
print("auc",metrics.auc(fpr,tpr))
程序运行结果如下:
fpr: [0. 0. 0.5 0.5 1. ]
tpr: [0. 0.5 0.5 1. 1. ]
[1.8 0.8 0.4 0.35 0.1 ]
auc 0.75
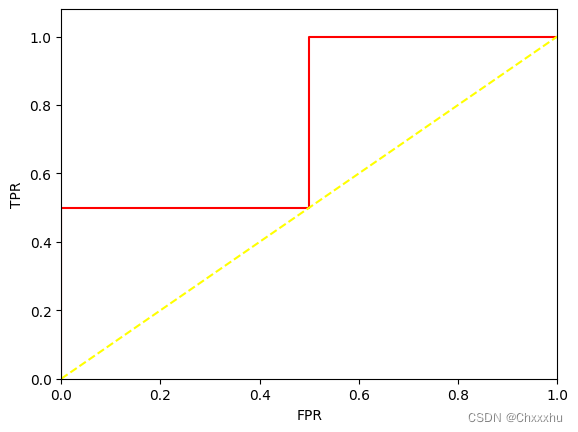
10 AUC面积
10.1 认识AUC面积
AUC(Area Under Curve)是指ROC曲线下的面积,由于ROC曲线一般都处于y=x直线上方,所以AUC的取值为0.5~1。AUC越接近1,检测方法真实性越高,当AUC等于0.5时,则真实性最低,无应用价值。
10.2 Sklearn计算AUC面积
sklearn.metrics模块提供roc_auc_score()函数,语法形式如下。
sklearn.metrics.roc_auc_score(y_true,y_score)
参数说明如下:
(1)y_true:每个样本的真实类别,必须为0(反例)或1(正例)标记。
(2)y_score:预测得分,可以是正类的估计概率。
【任务9】roc_auc_score()举例
import numpy as np
from sklearn.metrics import roc_auc_score
y_true=np.array([0,0,1,1])
y_scores=np.array([0.1,0.4,0.35,0.8])
print(roc_auc_score(y_true,y_scores))
程序运行结果如下:
0.75
11 分类评估报告
11.1 认识分类评估报告
分类评估报告显示每个类的精确度、召回率、F1 Score等信息。
11.2 Sklearn计算分类评估报告
Sklearn中的classification_report()函数形式如下。
sklearn.metrics.classification_report(y_true,y_pred,labels,target_names)
参数说明如下:
(1)y_true:真实目标值。
(2)y_pred:估计器预测目标值。
(3)labels:指定类别对应的数字。
(4)target_names:目标类别名称。
【任务10】classification_report()举例
from sklearn.metrics import classification_report
y_true=[0,1,2,2,2]
y_pred=[0,0,2,2,1]
target_names=['class 0','class 1','class 2']
print(classification_report(y_true,y_pred,target_names=target_names))
程序运行结果如下:
precision recall f1-score support
class 0 0.50 1.00 0.67 1
class 1 0.00 0.00 0.00 1
class 2 1.00 0.67 0.80 3
accuracy 0.60 5
macro avg 0.50 0.56 0.49 5
weighted avg 0.70 0.60 0.61 5
12 NLP评价指标
12.1 中文分词精确率和召回率
中文序列的每个词语可以按照文中的起止位置记作区间[i,j],将标准答案分词的所有区间构成集合为A、分词结果所有词语构成的区间集合为B。中文分词指标的精确率(Precision)和召回率(Recall)计算公式如下。
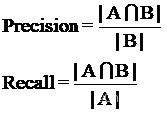
**【例1】**文本“武汉市长江大桥”进行中文分词的标准答案为[‘武汉市’,‘长江大桥’],现有两种分词结果,如表13-7所示。
| 分词结果 | 分词区间 | ||
|---|---|---|---|
| 标准答案 | [‘武汉市’,‘长江大桥’] | [1,2,3],[4,5,6,7] | A |
| 分词结果1 | [‘武汉‘,’市长‘,’江大桥’] | [1,2],[3,4],[5,6,7] | B’ |
| 重合部分 | 无 | 0 | A∩B |
| 分词结果2 | [‘武汉市’,‘长江大桥’] | [1,2,3],[4,5,6,7] | B’ |
| 重合部分 | [‘武汉市’,‘长江大桥’] | [1,2,3],[4,5,6,7] | A∩B’ |
分词结果与标准答案的交集为重合部分,对于分词结果1,由于没有重合部分,根据计算公式得到精确率和召回率均为0,分词结果1错误;对于分词结果2,重合部分为标准答案,精确率和召回率均为1,分词结果2正确。
**【例2】**中文文本“结婚的和尚未结婚的”进行中文分词的标准答案为[‘结婚’,‘的’,‘和’,‘尚未’,‘结婚’,‘的’],分词结果如表13-8所示。
| 分词结果 | 分词区间 | ||
|---|---|---|---|
| 标准答案 | [‘结婚’,‘的’,‘和’,‘尚未’,‘结婚’,‘的’] | [1,2],[3,3],[4,4],[5,6],[7,8],[9,9] | A |
| 分词结果 | [‘结婚’,‘的’,‘和尚’,‘未结婚’,‘的’] | [1,2],[3,3],[4,5],[6,7,8],[9,9] | B |
| 重合部分 | [‘结婚’,‘的’,‘的’] | [1,2],[3,3],[9,9] | A∩B |
根据精确率和召回率计算公式如下。
精确率为:3/5=0.6
召回率为:3/6=0.5
12.2 未登录词和登录词召回率
IV是”登录词”(In Vocabrulary),也就是已经存在于字典中的词。IV Recall是IV的召回率,计算公式如下。
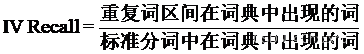
OOV是“未登录词”(Out Of Vocabulary),也就是新词,是在已知词典中不存在的词。OOV Recall是OOV的召回率,计算公式如下。
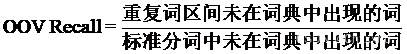
【任务11】未登录词和登录词召回率
已知字符串为“结婚的和尚未结婚的都应该好好考虑一下人生大事”,词典为[‘结婚’,‘尚未’,‘的’,‘和’,‘青年’,‘都’,‘应该’,‘好好考虑’,‘自己’,‘人生’,‘大事’]。
1.标准答案 A
分词结果:
[‘结婚’,‘的’,‘和’,‘尚未’,‘结婚’,‘的’,‘都’,‘应该’,‘好好’,‘考虑’,‘一下’,‘人生’,‘大事’]
分词区间:
[1,2],[3,3],[4,4],[5,6],[7,8],[9,9],[10,10],[11,12],[13,14],[15,16],[17,18],[19,20],[21,22]
2.分词结果 B
分词结果:
[‘结婚’,‘的’,‘和尚’,‘未结婚’,‘的’,‘都’,‘应该’,‘好好考虑’,‘一下’,‘人生大事’]
分词区间:
[1,2],[3,3],[4,5],[6,7,8],[9,9],[10,10],[11,12],[13,14,15,16],[17,18],[19,20,21,22]
3.重复词语A∩B
分词结果:[‘结婚’,‘的’,‘的’,‘都’,‘应该’,‘一下’]
分词区间:[1,2],[3,3],[9,9],[10,10],[11,12],[17,18]
根据如下公式:
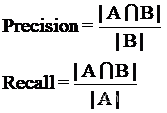
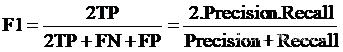
代人求得:
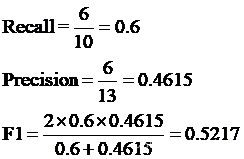
重复词区间在词典中出现的词=[‘结婚’,‘的’,‘的’,‘都’,‘应该’],个数为5;标准分词在词典中出现的词=[‘结婚’,‘的’,‘和’,‘尚未’,‘结婚’,‘的’,‘都’,‘应该’,‘人生’,‘大事’],个数为10。因此,V的召回率计算如下。

重复词区间未在词典中出现的词=[‘一下’],个数为1;标准分词未在词典中出现的词=[‘好好’,‘考虑’,‘一下’],个数为3。因此,OOV的召回率计算如下所示。
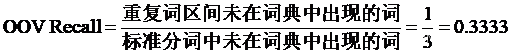
代码如下:
import re
def to_region(segmentation: str) -> list:
#将分词结果转换为区间
region = []
start = 0
for word in re.compile("\\s+").split(segmentation.strip()):
end = start + len(word)
region.append((start, end))
start = end
return region
def prf(gold: str, pred: str, dic) -> tuple:
#计算OOV_R, IV_R
A_size, B_size, A_cap_B_size, OOV, IV, OOV_R, IV_R = 0, 0, 0, 0, 0, 0, 0
A, B = set(to_region(gold)), set(to_region(pred))
A_size += len(A)
B_size += len(B)
A_cap_B_size += len(A & B)
text = re.sub("\\s+", "", gold)
for (start, end) in A:
word = text[start: end]
if word in dic:
IV += 1
else:
OOV += 1
for (start, end) in A & B:
word = text[start: end]
if word in dic:
IV_R += 1
else:
OOV_R += 1
p, r = A_cap_B_size / B_size * 100, A_cap_B_size / A_size * 100
return p, r, 2 * p * r / (p + r), OOV_R / OOV * 100, IV_R / IV * 100
if __name__ == '__main__':
# dic为词典
dic = ['结婚', '尚未', '的', '和', '青年', '都', '应该', '好好考虑', '自己', '人生', '大事']
# gold为标准答案
gold = '结婚 的 和 尚未 结婚 的 都 应该 好好 考虑 一下 人生 大事'
# pred为分词结果
pred = '结婚 的 和尚 未结婚 的 都 应该 好好考虑 一下 人生大事'
print("Precision:%.2f\n Recall:%.2f\n F1:%.2f\n OOV-R:%.2f\n IV-R:%.2f\n" % prf(gold, pred, dic))
程序运行结果如下:
Precision:60.00
Recall:46.15
F1:52.17
OOV-R:33.33
IV-R:50.00















 660
660











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









