






什么事框架
框架就是将公共的部分(公共的功能的程序)进行抽取;他们也就是父类和接口,从而形成的代码体
如何使用框架:通过引入jar包/class/方法使用里面的功能;
使用框架的目的(意义):简化了代码,增加了功能的拓展性
mybatis的框架时持久层的框架所以主要功能时操作数据库,它支持sql语句,存储,高级映射,
几乎免除了jdbc的所有的工作,通过xml文件映射文件 进行使用
spring框架:的主要作用是将其他的框架进行统一的管理,不至于说使用一个框架用一种程序语法
而是统一的语法进行使用;
管理bean的生命周期 bean:就是被spring管理的对象
如何整合框架
在内存中 开辟一块海量的空间 , 然后在内存中实例化这些框架的对象 , 依次对对象进行了管理 ;
在spring的内部的框架(也就是spring 的对象)之间可以用一种通用的一种方式进行调用(在内部可以对 对象进行任何的操作); 所以spring也就是一个容器 ;
在使用spring框架的时候安装lombook的作用 : 就是帮我们解决了实例化bean的时候自动生成了 tostring , get ,set 的方法(也就是在我们写代码的时候会提醒我们的这些方法);也就是通过注解的 方式进行的

@ToString : 自动生成toString方法
@EqualsAndHashcode : 从对象的字段中生成hashCode和equals的实现
@NoArgsConstructor/@RequiredArgsConstructor/@AllArgsConstructor
自动生成构造方法
@Data : 自动生成set/get方法,toString方法,equals方法,hashCode方法,不带参数的构造方法
@Value : 用于注解final类
如何使用spring框架里的对象
Spring的内存非常小有的jar包只有几兆所以成为轻量级
依赖注入只需在程序中提供要使用的 对象的名称就可以;具体对象在容器中如何赋值和封装;这就是容器的功能 ; 我们无需知道;
通过依赖注入使用spring的对象
依赖:就是classA 包含classB ClassA通过依赖的方式调用依赖的方式使用ClassB的功能
Spring 使用” 依赖注入”的方式来管理 Bean 之间的依赖关系,使用 IoC 实现对象之间的解耦和

mvc的模型(mvc是一种设计思想。三层结构是实现了三层模型的代码的实现两者是不相等)mvc的设计的目的主要是解藕
如果将所有的代码都写入到一个类里那么就会出现代码混乱 ;不便于后期的维护所以出现了 分层的模型,其实mvc是一个思想通过mvc的分层的思想进行代码的编写
一般分为三级:
M(model)持久层就是盖层的代码与数据库进行交互的目的;是将数据存到数据库中;mybatis就是持久层的框架;面向接口来使用mybatis框架;model使用接口来进行操作数据库
C(controller) 控制层:就是完成业务的具体的操作的过程;就是想要完成什么业务的代码写入到该层里;(controller--service)controller层就是接受view前端传过来的参数;在controller层接受前端的参数里面有前端的参数 service会进行加工处理controller接受view层传过来参数进行加工
V(view)(视图层):就是页面用户能够看到的页面;里面包含了html css等前端的代码
三层代码的书写
先在业务层写一个借口(目的:就是对业务进行公共的调用抽取就;比如想要调用某个业务的方法就讲该业务的方法写入到该接口里)在写一个实现类(目的;就是实现该接口里的方法)
传统的方式想要调用另一个类的方法 ;就要首先创建这个类的对象就是new 类;
然后再 类名 .方法();即可成功调用该方法
Spring的核心 (IOC. AOP)
IOC(控制反转)容器创建对象 自己创建类
由于传统代码是直接new 一个对象 这样的话就会直接new 死了 导致代码 的耦合新太高;所以引入ioc来解决该问题;
将创建对象的任务交给Spring来完成,同时对象的生命周期(创建/初始化(给对象赋值)/该对象的使用 / 对象资源的释放(销毁对象))也由Spring来完成;
通过依赖(就是引入)注入(DI)
也就是通过调控系统对象传递给Spring进行管理
项目
pom文件是配置maven的工程
maven管理jar包文件的
maven的主要作用就是进行管理jar包的,管理所有的开源的jar(maven的jar包都在中央仓库(私服镜像)里面存着);通过坐标的方式进行用来检索jar包,在maven配置什么jar包就会下载什么jar包;
在maven里有自己的项目的jar包的路径;起作用是:被自己的项目进行依赖(如果在写其他业务的时候如果有相同的代码块那么此时就直接引入jar包即可)
如何让spring创建对象
自己创建的类如何让spring进行管理,并让spring创建该对象
就是在该项目中创建application.xml文件,也就是spring的配置文件;在该文件里面是被spring容器里是被spring管理的对象
在里面加一个bean标签 bean标签里面有id(值是类名且类名的首字母小写)spring容器中的对象的标识且不能重复; Class(值是类的全路径 :包名.类名)类的全路径
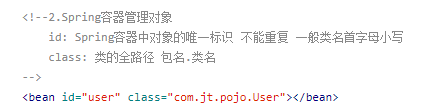
在使用spring框架的时候test类里的方法的返回值必须为空
在测试类中如何创建对象
在 测试类的方法中 创建容器 ;创建容器的代码如下:

然后在从容器中获取对象 ;获取对象的代码如下

调用对象的方法

spring容器通过反射机制实例化对象里面的对象
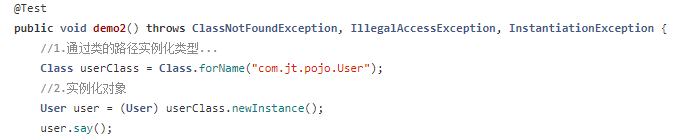
spring在application.xml中的解析过程

spring容器中如何存储对象(只有存储好对象才能通过getbean进行直接获取实例化好的对象)
就是在spring容器中通过map集合进行存储; 把application.xml文件中的bean标签的id当做k ;而实例化好的对象当做v进行存储;
工厂模式进行实例化抽象类 接口
框架如何实现松耦合
就是三层架构当做一方 测试类当做一方spring框架当做中间方 ; 所以测试类与mvc实现了松耦合
mvc将类交给spring框架, spring进行创建对象; 测试类通过getbean从容器中获取对象;从而实现了松耦合;















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









