







一、KNN
1、KNN
KNN属于有监督学习算法,既可以对有离散型标签的数据做分类,又可以对有连续型标签的数据做回归。
本文主要讨论KNN分类(下文称为KNN)。
2、KNN的核心思想
KNN不建立模型,直接存储所有可用的数据,并根据相似性对新数据进行分类,是一种基于实例学习(Instance-based learning)、非泛化性学习(non-generalizing learning)的算法。
二、KNN要素
1、相似性函数
- 欧氏距离(Euclidean Distance)
其中,x、y分别为数据,、
为数据的第 i 个属性,EuD(x,y)为欧氏距离。
- 曼哈顿距离(Manhattan Distance)
其中,ManD(x,y)为曼哈顿距离。
- 闵氏距离(Minkowski Distance)
其中,MinD(x,y)为闵氏距离,p为超参数,当p=1时,闵氏距离即为曼哈顿距离;当p=2时,闵氏距离即为欧氏距离。
- 余弦相似性(Cosine Similarity)
其中, 、
分别为x、y的模长,cos(x,y)为余弦相似性。
2、数据归一化(Normalization)
数据归一化可以标准化(Standardize)数据范围,消除数据量纲的影响。
- Z-score
其中,u为数据均值,为数据标准差,
为x归一化后的结果。
- Min-Max
其中,为数据的最小值,
为数据的最大值,
为x归一化后的结果。
3、K值的选取
超参数K值的选取,很大程度上影响KNN的准确率,例如下图。
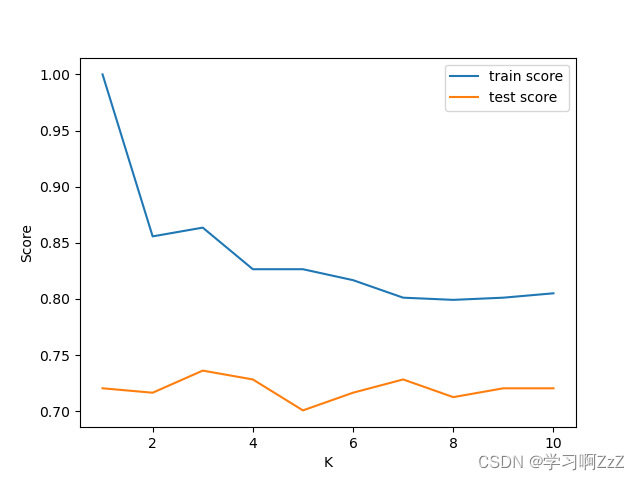
K值选取的效果可以通过维诺图(Voronoi Tessellation)来表示,如下所示:
当K=1时,

当K=5时,

可以得到结论:
- 当K太小时,KNN对噪声十分敏感
- 当K太大时,KNN可能导致过度平滑
4、分类算法过程
- 选择超参数K;
- 计算待分类数据与所有数据的相似性(欧氏距离等);
- 将相似性排序,选择最接近的K个(K-Nearest)数据;
- 根据这最接近的K个数据的多数结果(Majority Vote)作为最终结果。
三、KNN实践(sklearn)
以kaggle中数据集"Fake Bills"为例
1、数据准备
直接下载并使用"Fake Bills"数据集,读取数据
import pandas as pd
dataset = pd.read_csv('./fake_bills.csv') # 读取数据集由于数据集中存在缺失值,因此删除包含缺失值的行
dataset.dropna(axis=0, how='any', inplace=True) # 删除数据集中的缺失值数据预处理,将数据进行归一化处理,使用Min-Max归一化
from sklearn.preprocessing import MinMaxScaler
X = dataset.drop('is_genuine', axis=1) # 提取特征 X
y = dataset['is_genuine'] # 提取标签 y
MMScaler = MinMaxScaler().fit(X)
X_normalized = MMScaler.transform(X) # 将 X 归一化到 [0, 1] 区间2、训练模型
Hold-out,划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_normalized, y, test_size=0.33,
random_state=22) # 划分训练集和测试集,测试集占比为 0.33,随机种子为 22
选取K值,分别训练K=1,2,...,10的KNN模型,选取最好效果最好的K值
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
k_selected = 10 # 设置 K 的最大值为 10
train_score = np.zeros(k_selected) # 用于存储训练集的准确率
test_score = np.zeros(k_selected) # 用于存储测试集的准确率
# 遍历 K 的取值范围 [1, 10]
for i in range(k_selected):
KNN = KNeighborsClassifier(n_neighbors=i + 1)
KNN.fit(X_train, y_train) # 用训练集训练分类器
train_score[i] = KNN.score(X_train, y_train) # 计算并保存训练集的准确率
test_score[i] = KNN.score(X_test, y_test) # 计算并保存测试集的准确率
import matplotlib.pyplot as plt
plt.plot(np.arange(1, k_selected + 1), train_score, label="train score") # 绘制 K 的取值与训练集准确率的折线图
plt.plot(np.arange(1, k_selected + 1), test_score, label="test score") # 绘制 K 的取值与测试集准确率的折线图
plt.xlabel('K')
plt.ylabel('Score')
plt.legend()
plt.show()结果如下:
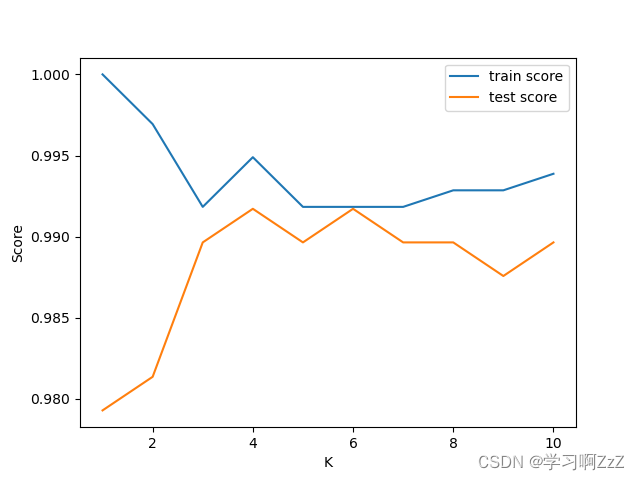
因此选取超参数K=4训练模型
KNN = KNeighborsClassifier(n_neighbors=4) # 根据图形选择最佳的 K 值为 4
KNN.fit(X_train, y_train) # 用训练集训练分类器3、评估模型
分别评估KNN模型在训练集和测试集上的准确率
print('Score of train-set : {:.4f}'.format(KNN.score(X_train, y_train))) # 打印训练集的准确率
print('Score of test-set : {:.4f}'.format(KNN.score(X_test, y_test))) # 打印测试集的准确率
结果如下:
Score of train-set : 0.9949
Score of test-set : 0.9917
使用混淆矩阵(confusion-matrix)评估KNN模型的TP、TN、FP、FN。
y_predict = KNN.predict(X_test) # 对测试集进行预测
print(pd.crosstab(y_test, y_predict, rownames=["true_value"], colnames=["predict_value"])) # 打印预测结果和真实标签的交叉表
结果如下:
| predict_value | False | True |
| true_value | ||
| False | 161 | 3 |
| True | 1 | 318 |
















 3270
3270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











