






本章概述
- 日志收集准备工作-部署ELK
- 日志收集方式
前言
日志收集的目的:
分布式日志数据统一收集,实现集中式查询和管理
故障排查
安全信息和事件管理
报表功能
日志收集的价值:
日志查询,问题排查,故障恢复,故障自愈
应用日志分析,错误报警
性能分析,用户行为分析
日志收集流程图:
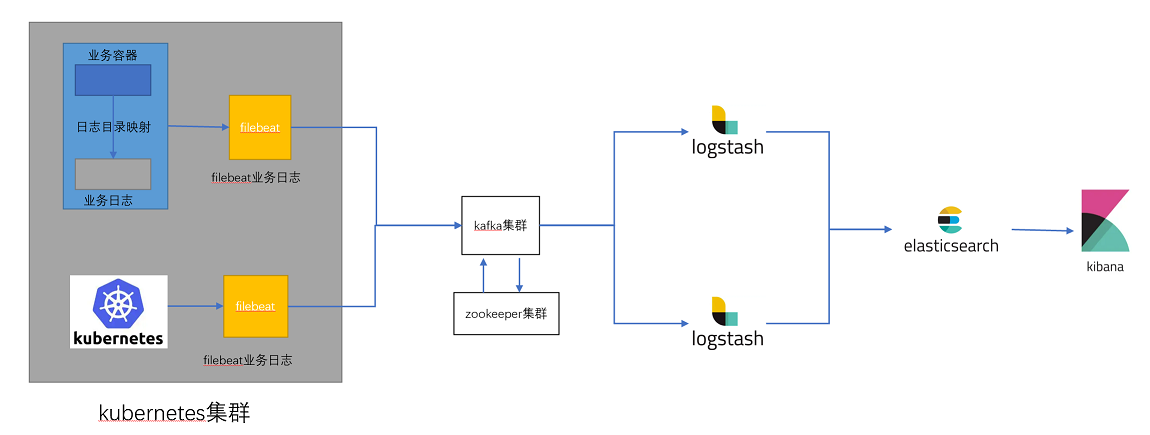
日志收集流程
1、在k8s集群内部(node、pod、容器)内置filebeat客户端收集日志(日志主要为业务access日志和kubernetes集群的系统日志)
2、日志发送给kafka集群,kafka集群进行缓存(削峰填谷)
注意:在业务高峰期,k8s集群会产生大量日志,如果日志直接发送给logstash,会占用logstash大量磁盘IO,负载很高,如果logstash无法及时处理,就会产生阻塞造成数据丢失。为了防止此类问题,在中间加上kafka缓存,消息先缓存在kafka中,由kafka投递给logstash进行处理。
3、logstash从kafka消费日志,并对日志进行过滤
4、然后将日志发送给elasticsearch,elasticsearch对日志进行分析
5、kibana用来展示elasticsearch的分析结果
15.1 日志收集准备工作-部署ELK
由于日志收集是基于ELK架构进行的,要先部署ELK,部署完成后,便于演示通过不同的日志收集方式实现kubernetes日志收集
机器准备:
kafka1 172.31.7.161
kafka2 172.31.7.162
kafka3 172.31.7.163
zookeeper1 172.31.7.171
zookeeper2 172.31.7.172
zookeeper3 172.31.7.173
elasticsearch01 172.31.7.181
elasticsearch02 172.31.7.182
elasticsearch03 172.31.7.183
kibana 172.31.7.181 (和elasticsearch01共用一台机器)
logstash 172.31.7.18515.1.1 部署zookeeper
1、zookeeper三个节点执行:yum安装jdk
yum -y install java-1.8.0-openjdk
验证java是否可用
java -version

2、三个zookeeper节点执行:创建目录/apps,并将zookeeper安装存放在该目录下
mkdir -p /apps
将zookeeper安装放在该目录下
cd /apps
wget https://downloads.apache.org/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
3、三个zookeeper节点执行:解压安装包并做软链接
tar xvf apache-zookeeper-3.6.3-bin.tar.gz
ln -sv /apps/apache-zookeeper-3.6.3-bin /apps/zookeeper
4、修改zookeeper配置
在三zookeeper个节点分别执行:
cd /apps/zookeeper/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper
clientPort=2181
server.1=172.31.7.171:2888:3888
server.2=172.31.7.172:2888:3888
server.3=172.31.7.173:2888:3888创建数据目录
mkdir -p /data/zookeeper
5、配置zookeeper节点id(注意,zookeeper集群每个节点的id都不一样)
在zookeeper1节点172.31.7.171上执行:
echo 1 > /data/zookeeper/myid
在zookeeper2节点172.31.7.172上执行:
echo 2 > /data/zookeeper/myid
在zookeeper3节点172.31.7.173上执行:
echo 3 > /data/zookeeper/myid6、运行zookeeper集群
三个节点分别执行
/apps/zookeeper/bin/zkServer.sh start
注意:zookeeper配置的初始化时间为10*2000ms,即20s,因此三个节点服务拉起时间不能超过20s,超过20s将会集群初始化失败
查看集群各节点角色
/apps/zookeeper/bin/zkServer.sh status #当前集群zookeeper3为leader角色。7、使用插件在windows主机上进行验证
(1)首先在windows主机安装java环境
java下载链接:https://download.oracle.com/java/18/latest/jdk-18_windows-x64_bin.exe
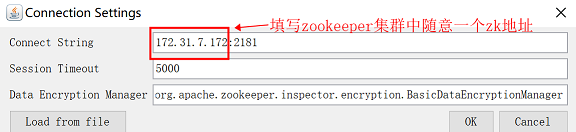
(2)安装完成后使用ZooInspector工具连接zookeeper
ZooInspector百度网盘下载链接:
链接:https://pan.baidu.com/s/1m8v0Ni9Fql1n_Y19vVKXsg
提取码:lh7t 下载完成后进行解压,然后进入build文件夹,双击打开zookeeper-dev-ZooInspector.jar(注意使用java打开该工具)
点击工具栏第一个按钮(如果第一次打开不显示工具栏,需要关闭,然后重新打开)
连接zookeeper
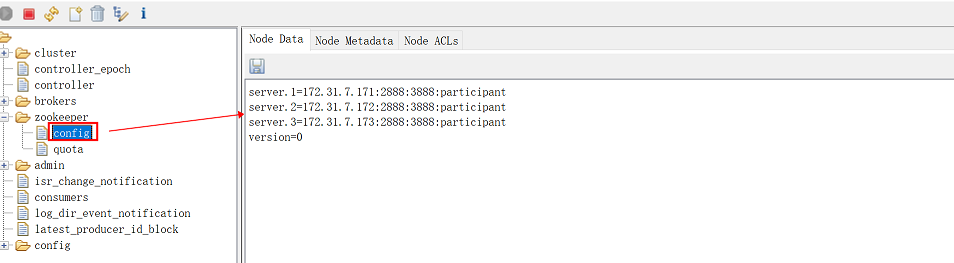
如果左侧能显示zookeeper,并且在其子列表中点击config,右侧可以显示zookeeper集群各节点地址,说明zookeeper正常
15.1.2 部署kafka
1、kafka三个节点分别执行:安装java并下载kafka安装包
yum -y install java-1.8.0-openjdk
创建目录
mkdir -p /apps
wget https://archive.apache.org/dist/kafka/2.4.1/kafka_2.13-2.4.1.tgz
2、kafka三个节点分别执行:解压安装包并做软连接
tar xvf kafka_2.13-2.4.1.tgz
ln -sv /apps/kafka_2.13-2.4.1 /apps/kafka3、修改kafka配置文件(注意三个kafka节点配置不同,要分别进行配置)
(1)kafka1节点172.31.7.161配置:
cd /apps/kafka/config
vim server.properties
broker.id=161 #指定borkerid,每个节点都不一样,这里以节点ip最后一位作为brokerid
listeners=PLAINTEXT://172.31.7.161:9092 #指定监听地址和端口,指定监听本地地址
log.dirs=/data/kafka-logs #指定日志目录
log.retention.hours=168 #指定日志保存时长
zookeeper.connect=172.31.7.171:2181,172.31.7.172:2181,172.31.7.173:2181 #指定zk地址和端口
创建日志目录
mkdir -p /data/kafka-logs
(2)kafka2节点172.31.7.162配置:
cd /apps/kafka/config
vim server.properties
broker.id=162 #指定borkerid,每个节点都不一样,这里以节点ip最后一位作为brokerid
listeners=PLAINTEXT://172.31.7.162:9092 #指定监听地址和端口,指定监听本地地址
log.dirs=/data/kafka-logs #指定日志目录
log.retention.hours=168 #指定日志保存时长
zookeeper.connect=172.31.7.171:2181,172.31.7.172:2181,172.31.7.173:2181 #指定zk地址和端口
创建日志目录
mkdir -p /data/kafka-logs
(3)kafka3节点172.31.7.163配置:
cd /apps/kafka/config
vim server.properties
broker.id=163 #指定borkerid,每个节点都不一样,这里以节点ip最后一位作为brokerid
listeners=PLAINTEXT://172.31.7.163:9092 #指定监听地址和端口,指定监听本地地址
log.dirs=/data/kafka-logs #指定kafka存储数据的目录
log.retention.hours=168 #指定日志保存时长
zookeeper.connect=172.31.7.171:2181,172.31.7.172:2181,172.31.7.173:2181 #指定zk地址和端口创建日志目录
mkdir -p /data/kafka-logs
4、启动kafka
(1)三个节点分别执行:
/apps/kafka/bin/kafka-server-start.sh -daemon /apps/kafka/config/server.properties
注意:如果多台机器是通过克隆同一个快照创建的,注意要更改主机名称,否则会报以下错误(日志为/app/zookeerper/logs/kafkaServer.out)
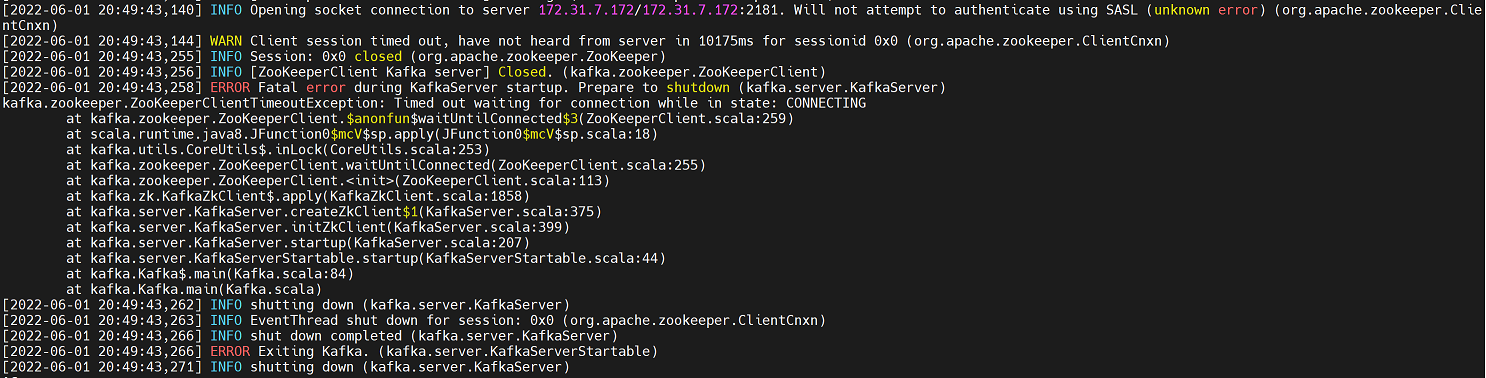
解决方法:修改主机名
hostnamectl set-hostname XXX #通过命令更改,临时生效
vim /etc/hosts #修改hosts文件,永久生效
(2)查看各主机9092端口是否起来
ss -ntl
(3)通过ZooInspector工具连接zookeeper,查看kafka是否已经注册到zookeeper集群中
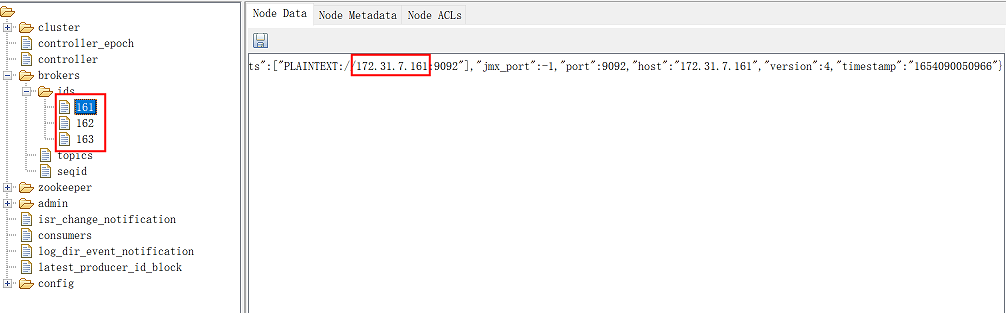
查看左侧brokers--ids,然后看到三个以kafka节点ip最后一位命名的三个文件,分别点击可以看到kafka的地址,说明kafka已经注册到zookeeper集群
(4)在windows主机使用kafka tool工具连接kafka查看kafka内是否有数据
kafka tool下载页面:Offset Explorer
windows版本下载链接:https://www.kafkatool.com/download2/offsetexplorer_64bit.exe
安装完成后打开kafka tool,进行配置
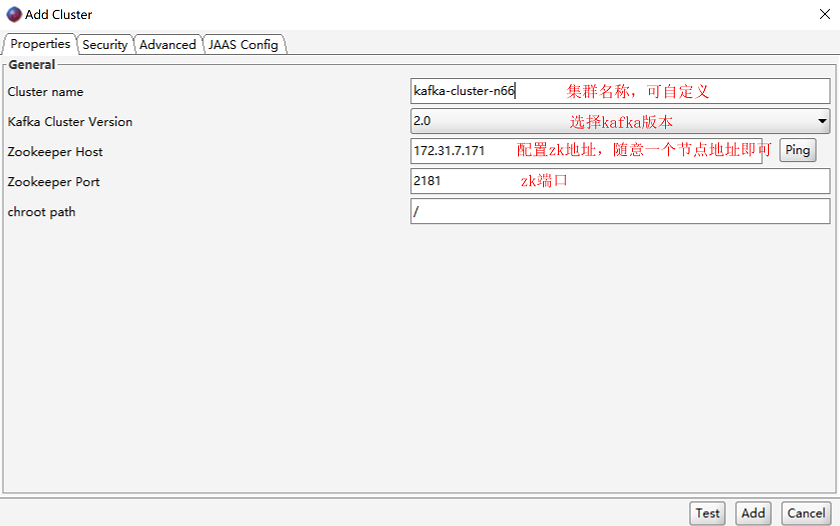
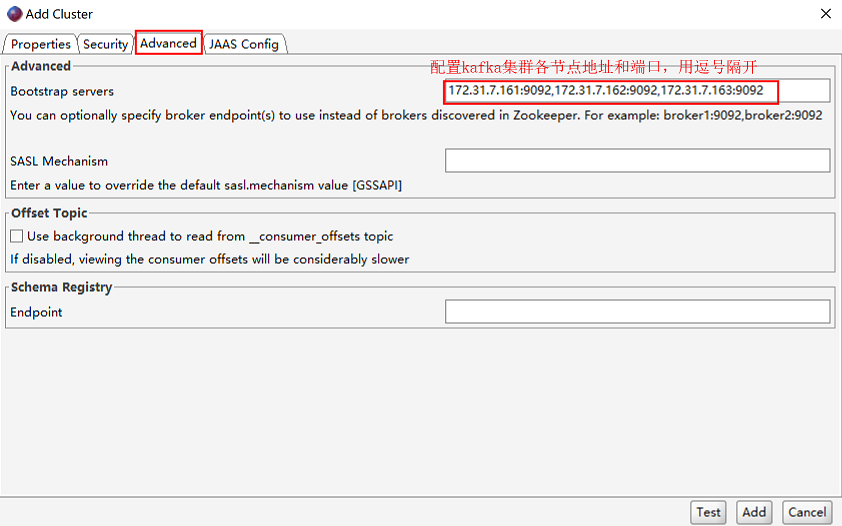
高级配置:
链接测试,如果返回connection successful,表示连接成功。点击“是”按钮查看集群情况
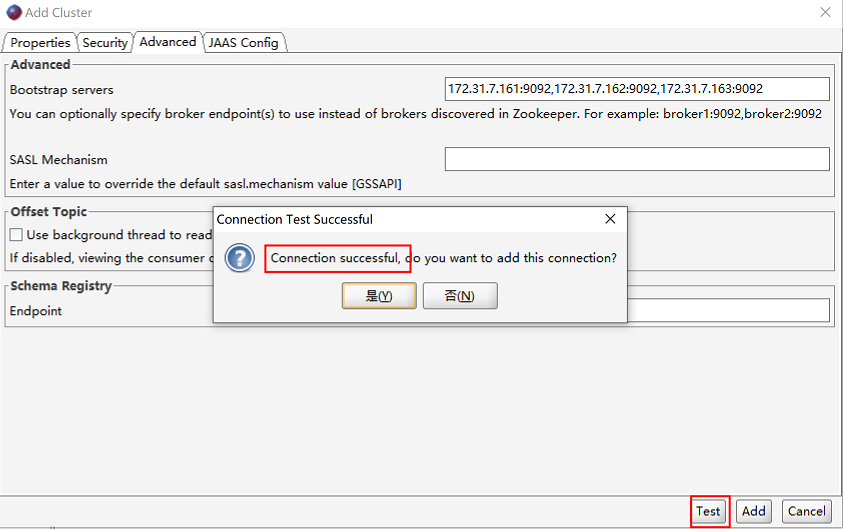
查看集群各节点
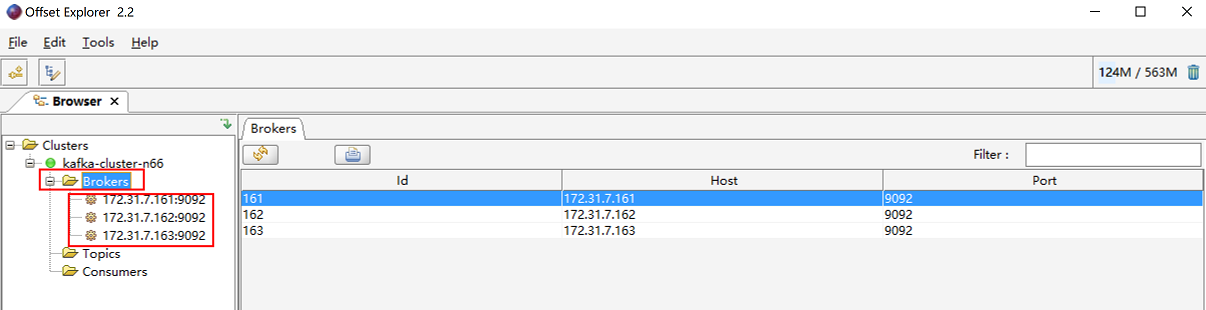
15.1.3 部署elasticsearch
elasticsearch依赖java环境,需要提前安装jdk,但elasticsearch有自带java环境的安装包,可以不用安装jdk,此时使用自带java环境的安装包。
elasticsearch对主机内存配置有要求,最少需要2G内存。
另外,elasticsearch,logstash,kibana三个组件都有相同的版本,下载时可以下载同一个版本。
官网下载页面:https://www.elastic.co/cn/downloads/past-releases#enterprise-search
1、下载elasticsearch并安装
三个节点分别执行:
下载elasticsearch rpm包,放到/usr/local/src/目录下
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.12.1-x86_64.rpm
安装elasticsearch
rpm -ivh /usr/local/src/elasticsearch-7.12.1-x86_64.rpm
2、修改配置文件并启动服务
(1)elasticsearch01节点172.31.7.181上执行:
vim /etc/elasticsearch/elasticsearch.yml
cluster.name: es-cluster-n66 #指定集群名称,三个节点集群名称配置一样
node.name: es01 #指定node名称,每个节点配置不能一样,这里将主机名配置文件node name
path.data: /var/lib/elasticsearch #指定数据目录,如果要保存数据,可以挂载存储到该目录
path.logs: /var/log/elasticsearch #指定日志目录,如果要保存数据,可以挂载存储到该目录
#bootstrap.memory_lock: true #是否开启内存锁定,即当elasticsearch启动时为其分配多大内存,通过修改vim /etc/elasticsearch/jvm.options文件来配置,这里暂不开启。
network.host: 172.31.7.181 #指定监听地址,这里写本机地址
http.port: 9200 #客户端监听端口,9200是给客户端使用的端口
discovery.seed_hosts: ["172.31.7.181", "172.31.7.182","172.31.7.183"] #发现配置,发现消息后通告给目标主机,这里填写集群内各节点ip地址或主机名
cluster.initial_master_nodes: ["172.31.7.181", "172.31.7.182","172.31.7.183"] #集群内哪些节点可以被选举为master,一般会将集群内各节点都加上
action.destructive_requires_name: true #通过严格匹配删除索引,防止误删除索引
http.cors.enabled: true #支持跨域访问
http.cors.allow-origin: "*" #云允许所有域名访问
配置完成后启动elasticsearch服务
systemctl start elasticsearch.service
(2)elasticsearch01节点172.31.7.182上执行:
vim /etc/elasticsearch/elasticsearch.yml
cluster.name: es-cluster-n66 #指定集群名称,三个节点集群名称配置一样
node.name: es02 #指定node名称,每个节点配置不能一样,这里将主机名配置文件node name
path.data: /var/lib/elasticsearch #指定数据目录,如果要保存数据,可以挂载存储到该目录
path.logs: /var/log/elasticsearch #指定日志目录,如果要保存数据,可以挂载存储到该目录
#bootstrap.memory_lock: true #是否开启内存锁定,即当elasticsearch启动时为其分配多大内存,通过修改vim /etc/elasticsearch/jvm.options文件来配置,这里暂不开启。
network.host: 172.31.7.182 #指定监听地址,这里写本机地址
http.port: 9200 #客户端监听端口,9200是给客户端使用的端口
discovery.seed_hosts: ["172.31.7.181", "172.31.7.182","172.31.7.183"] #发现配置,发现消息后通告给目标主机,这里填写集群内各节点ip地址或主机名
cluster.initial_master_nodes: ["172.31.7.181", "172.31.7.182","172.31.7.183"] #集群内哪些节点可以被选举为master,一般会将集群内各节点都加上
action.destructive_requires_name: true #通过严格匹配删除索引,防止误删除索引
http.cors.enabled: true #支持跨域访问
http.cors.allow-origin: "*" #云允许所有域名访问
配置完成后启动elasticsearch服务
systemctl start elasticsearch.service
(3)elasticsearch01节点172.31.7.183上执行:
vim /etc/elasticsearch/elasticsearch.yml
cluster.name: es-cluster-n66 #指定集群名称,三个节点集群名称配置一样
node.name: es03 #指定node名称,每个节点配置不能一样,这里将主机名配置文件node name
path.data: /var/lib/elasticsearch #指定数据目录,如果要保存数据,可以挂载存储到该目录
path.logs: /var/log/elasticsearch #指定日志目录,如果要保存数据,可以挂载存储到该目录
#bootstrap.memory_lock: true #是否开启内存锁定,即当elasticsearch启动时为其分配多大内存,通过修改vim /etc/elasticsearch/jvm.options文件来配置,这里暂不开启。
network.host: 172.31.7.183 #指定监听地址,这里写本机地址
http.port: 9200 #客户端监听端口,9200是给客户端使用的端口
discovery.seed_hosts: ["172.31.7.181", "172.31.7.182","172.31.7.183"] #发现配置,发现消息后通告给目标主机,这里填写集群内各节点ip地址或主机名
cluster.initial_master_nodes: ["172.31.7.181", "172.31.7.182","172.31.7.183"] #集群内哪些节点可以被选举为master,一般会将集群内各节点都加上
action.destructive_requires_name: true #通过严格匹配删除索引,防止误删除索引
http.cors.enabled: true #支持跨域访问
http.cors.allow-origin: "*" #云允许所有域名访问
配置完成后启动elasticsearch服务
systemctl start elasticsearch.service3、验证,查看9200端口是否被监听
4、通过谷歌浏览器插件elasticsearch-head连接elasticsearch进行验证。由于该插件需要访问谷歌商店才可以下载,因此无法加载,可以通过以下链接进行下载
(1)下载插件
插件下载地址:https://files.cnblogs.com/files/sanduzxcvbnm/elasticsearch-head.7z
(2)下载完成后进行解压elasticsearch-head.7z
(3)在浏览器加载elasticsearch-head插件步骤:
打开谷歌浏览器,点击右上角选项—更多工具—扩展程序
如果没有开启开发者模式,要开启开发者模式

选择加载已解压的扩展程序

加载完成
选择浏览器右上角插件图标,在下拉列表中选择elasticsearch head插件点击打开
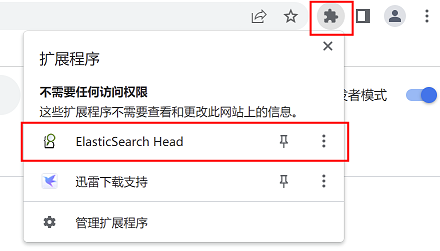
在框内输入elasticsearch集群内随意一个节点ip地址,点击连接,即可显示集群内节点信息。节点前带有*号(星号)的为master节点,不带星号的是从节点

15.1.4 部署kibana
这里将kibana和elasticsearch01部署在同一台机器,因此kibana地址为172.31.7.181
1、下载kibana安装包并安装
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.12.1-x86_64.rpm
cd /usr/local/src
rpm -ivh kibana-7.12.1-x86_64.rpm2、修改kibana配置文件并启动服务
vim /etc/kibana/kibana.yml
server.port: 5601 #kibana监听端口
server.host: "172.31.7.181" #kibana地址
elasticsearch.hosts: ["http://172.31.7.181:9200"] #elasticsearch的地址和端口
i18n.locale: "zh-CN" #修改kibana页面显示语言为中文启动kibana服务
systemctl start kibana
3、验证
查看5601端口是否被监听

浏览器访问:172.31.7.181:5601
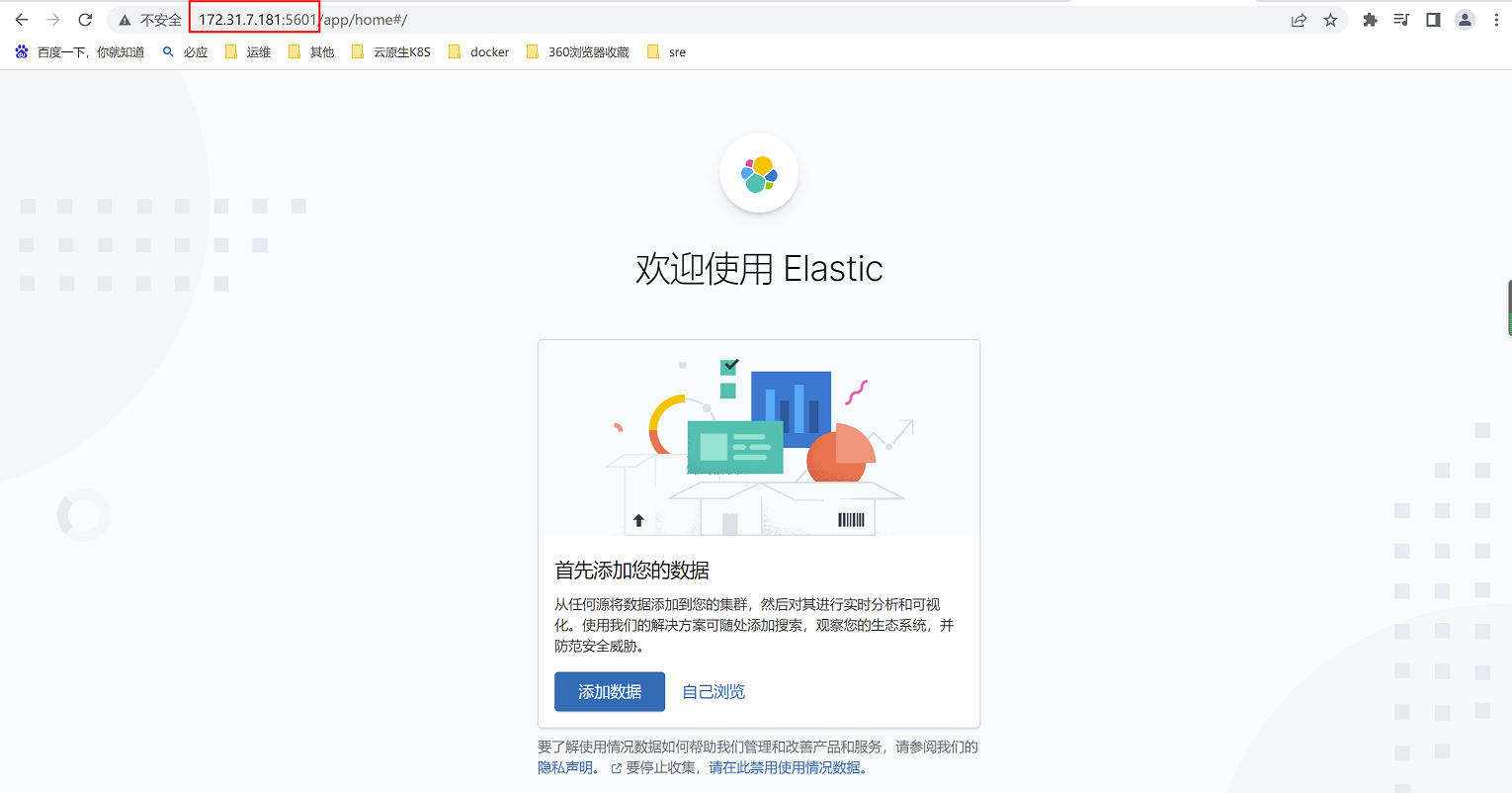
这里需要添加数据,由于k8s集群中尚未部署完成,没有收集到数据,因此需要等到收集到数据后再进行配置















 132
132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









