







RNN中比较有名的3个变体代表:GRU,LSTM,bidirectional RNNs
GRU门控循环单元
我们传统的RNN在计算hi的时候,会由当前xi以及之前那个hi-1进行计算而成的,在这里,我们需要将门控机制引入到RNN中
门控机制:就是对我们当前输入的信息进行筛选,类似于一个门一样,门打开就是会让你这些信息进来,门关闭的话,相当于你的信息停留在这,所以它决定了会由哪些信息进入到下一层。
这里会有两个门控,分别是更新门和重置门,它的作用就在于权衡我们过去的信息,即hi或者是hi-1之类的,和当前我们输入信息他们之间的一个比重问题
更新门和重置门,也是由上一个hi-1和输入的xi决定的,但是,这里的权重值wx和之前是不一样的,更新门有自己专属的一个权重,重置门也会有一个自己专属权重,
其中重置门的作用就是考虑到上一层隐藏的状态对当前那个激活,我们通过计算来获得一个当前一个比较新的一个临时的一个激活值hi~
而更新门则权衡我们当前目前新得到的新的激活hi~和我们之前的过去的状态hi-1之间的影响,我们最终计算我们可以得到传输到下一层的一个隐藏的状态hi
这里的*表示我们元素之间进行一个三层的计算

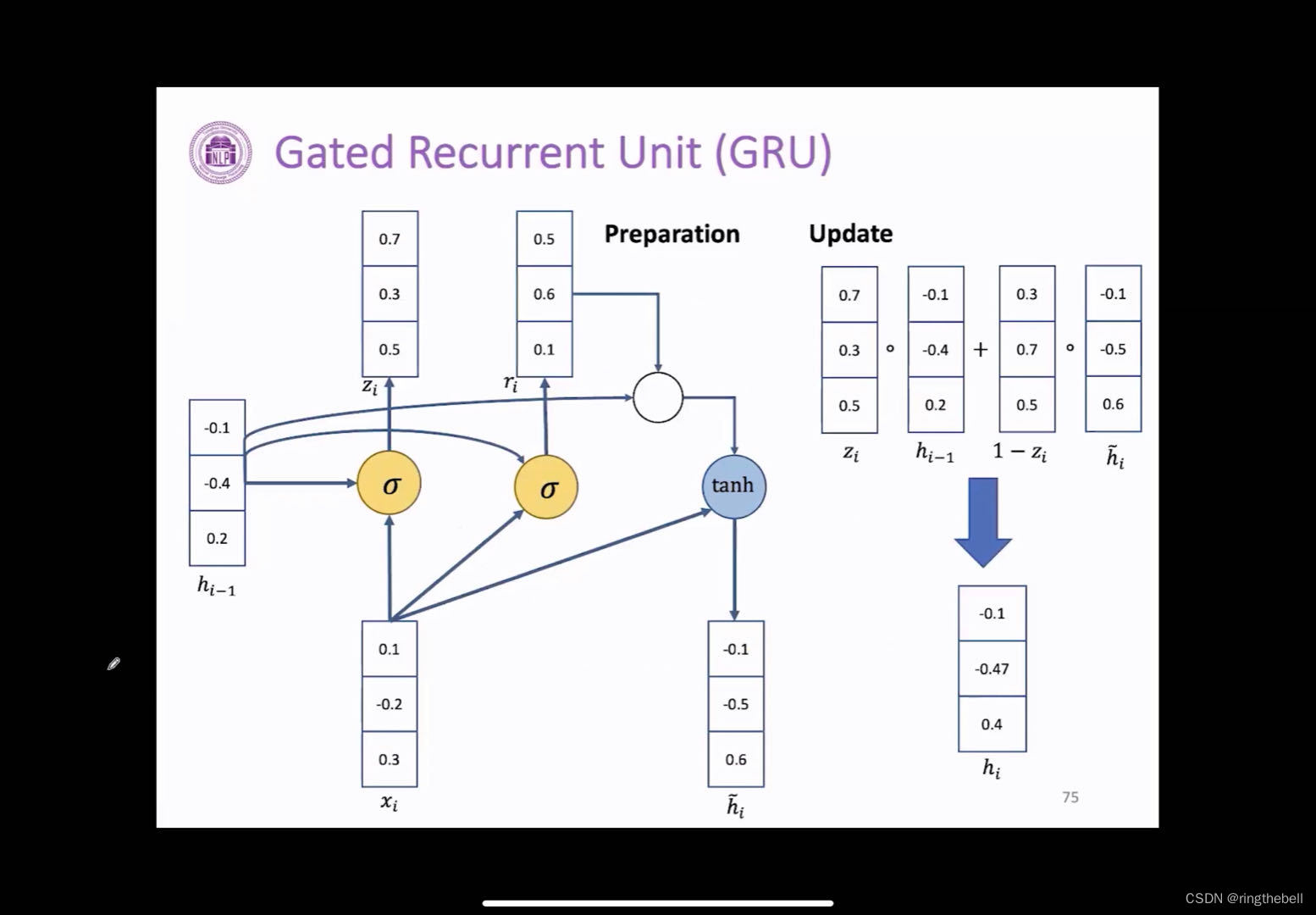
以下为演示GRU的一个计算
在我们拿到当前的一个输入xi和上一层的隐藏状态变量hi-1,我们首先通过这么一个计算得到更新门zi和重置门ri两个数值(在这里简化了,类似于权重以及Bears没有给出),它的有向边就是wx对应我们更新门对应的权重
得到重置门的几个参数之后,计算我们新的激活hi-1,相当于它也是有重置门参数以及上一层的hi-1,和当前的输入有关
在我们计算得到这三个参数之后,分别是重置门zi,更新门ri,以及新的激活hi~。我们就可以计算我们最终需要传输到下一层的隐藏变量hi
如果当我们的重置门的值无限接近于零的时候,我们可以看到相当于r无限接近于0,我们新的激活hi~,就和我们上一个隐藏状态是没有关系的,这时可以理解为hi~是由当前输入进行计算得到的,和之前上一层的隐藏状态就没有关系了
一个比较好的例子:一个新文章的开头,它过去的信息可能会对当前的结果是没有用的

而对于更新门来说,它是控制了过去的状态,与我们当前激活,他们相比之下可能会由一个多大的关系
例如,当我们zi无限接近于1的时候,我们最终计算就相当于我们直接由上一层,因为刚才已经得到了相当于直接hi会等于hi-1
而当我们这个zi无限接近于0的时候,最终计算也是hi会直接由我们当前的输入进行得到的,相当于是丢弃了过去的状态,直接采用我们当前之前新计算激活hi进行得到

LSTM长短期记忆网络
GRU有两个控制门,而LSTM(long short - term memory network)会更复杂一点
LSTM也是RNN的一个变体,能够像GRU一样来学习,长期的数据依赖关系,同样LSTM也是有一个结构单元的,如途中中间的部分
我们从结构上来看,会比之前的RNN或者是GRU更复杂一点,但它的逻辑也是比较清晰的,我们可以看下面的介绍
黄色方块开始:神经网络层、元素之间的一个操作、箭头表示向量的传递、箭头的合并表示我们向量之间需要进行一个合并的操作,分叉就表示我们向量之间的复制与拷贝

LSTM最关键的就是它加了一个新的值:cell state,即cell状态。用它来学习长期的依赖关系,而且我们可以看到水平的线是贯穿整个链条的,在我们计算的时候,可能会进行一些微小的线性之间的相互操作,而我们可以通过门控制系统来进行一个移除或者进行一个添加cell状态里面的信息,即线上一般会由这几个操作,这样就可以使得信息的传播可能会更加地容易
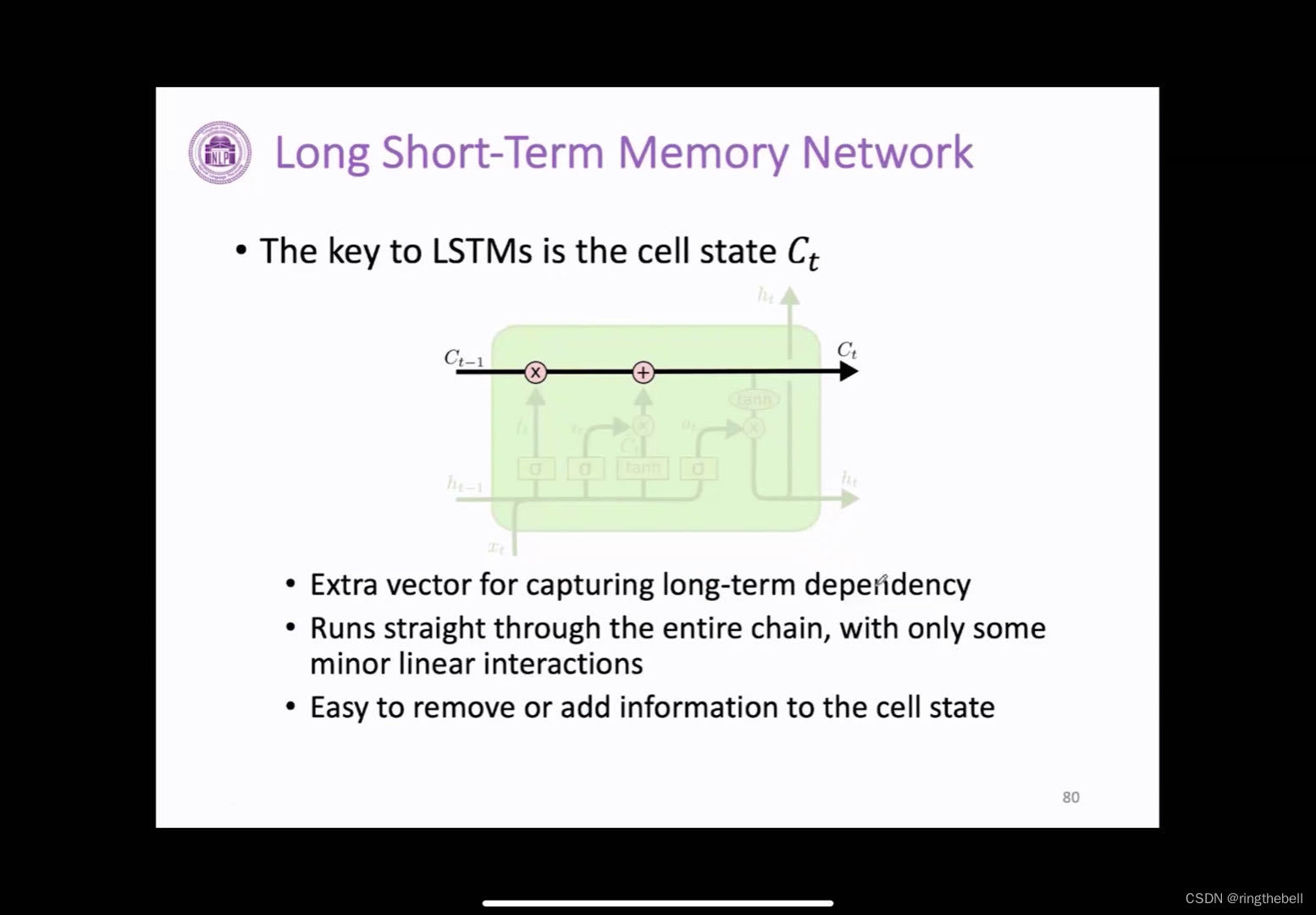
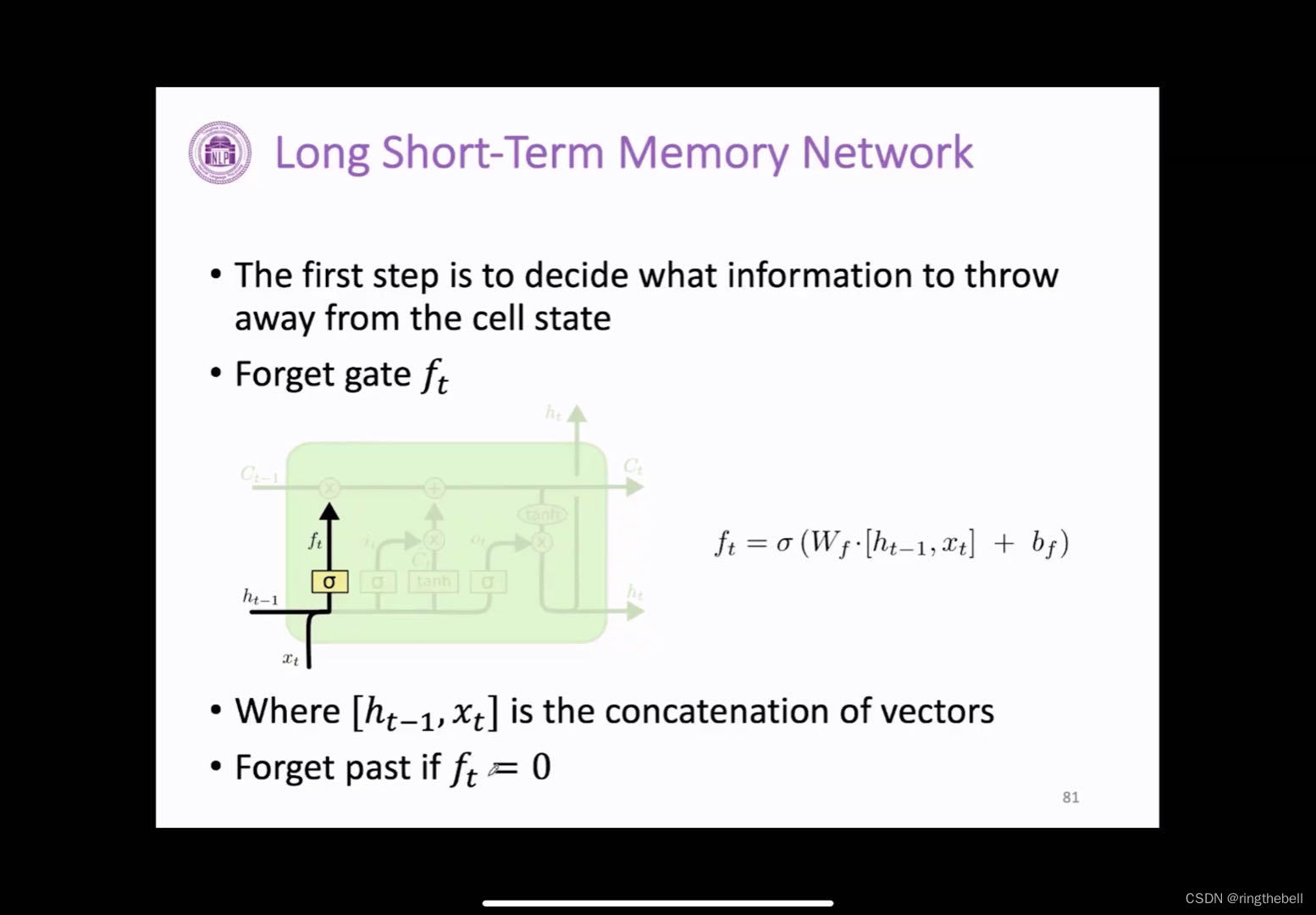
首先是第一个门,遗忘门,它的作用主要来决定我们当前上一个状态有哪些信息可以从cell状态中进行移除
遗忘门的计算也是以当前的输入和上一层这个隐藏状态进行得到的,但他这里和之前的计算方式不一样,首先它会把当前的输入和上一层隐藏的状态我们需要进行一个连接,然后乘上遗忘门这个专属矩阵和bias,我们通过一个激活函数,来输出一个0~1之间的一个值
如果这个ft是个0,那么遗忘门最终高的计算结果就是0,则,表示过去的某些信息我们就是直接进行丢弃,进行不要的
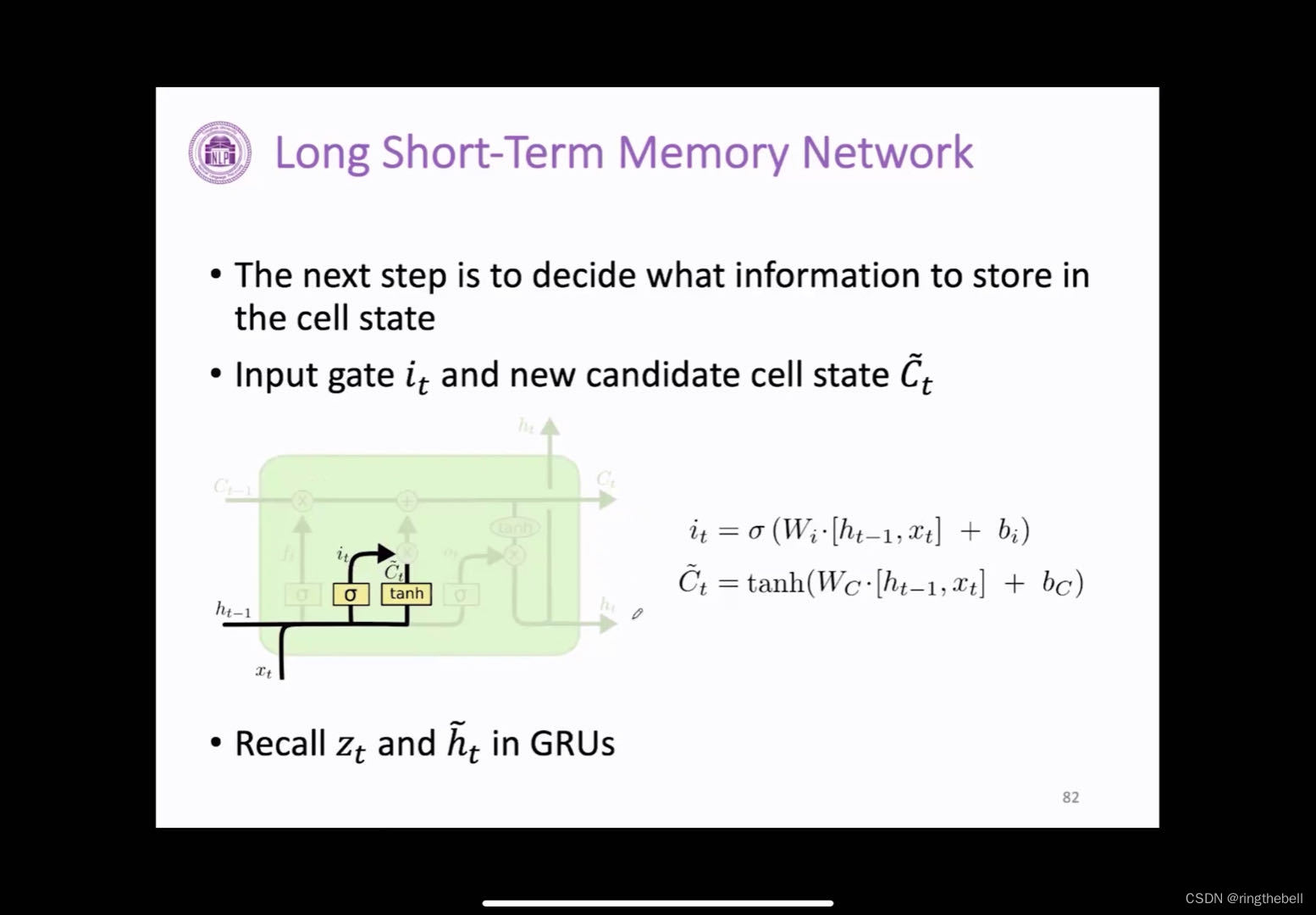
对于输入门,决定哪些是信息是可以存入到cell状态里面去的,它的计算方式和遗忘门比较类似,也是通过当前的输入,还有上一层的隐藏状态进行一个连接,然后乘上他们专属的wi,就是输入门矩阵以及bias,通过激活函数来得到我们的输入参数it,与此同时,我们也会通过当前的输入来计算一个我们待选的信息算量ct,但这两个参数计算完之后,我们就可以得到输入门,他就是来控制我们这个待选的信息变量ct,它中有哪些部分需要存入到我们cell状态中(类似GRU中更新门的操作)
接下来就可以更新cell状态,
首先需要对cell状态里的信息进行筛选,就相当于我们是拿遗忘门所算出来的这个参数值乘上上一层这个cell的状态,来决定哪些信息我们进行保留以及忘记,同时我们还需要加入新的信息状态及输入门会和我们这个待选的新向量ct进行一个相乘,来决定当前我们有哪些信息需要加入到我们的cell状态中
最终我们可以看到左边图数据流向,上一层ct-1经过我们的遗忘门操作,再加上我们新的当前信息数据,我们就可以得到传输到下一层这个cell状态
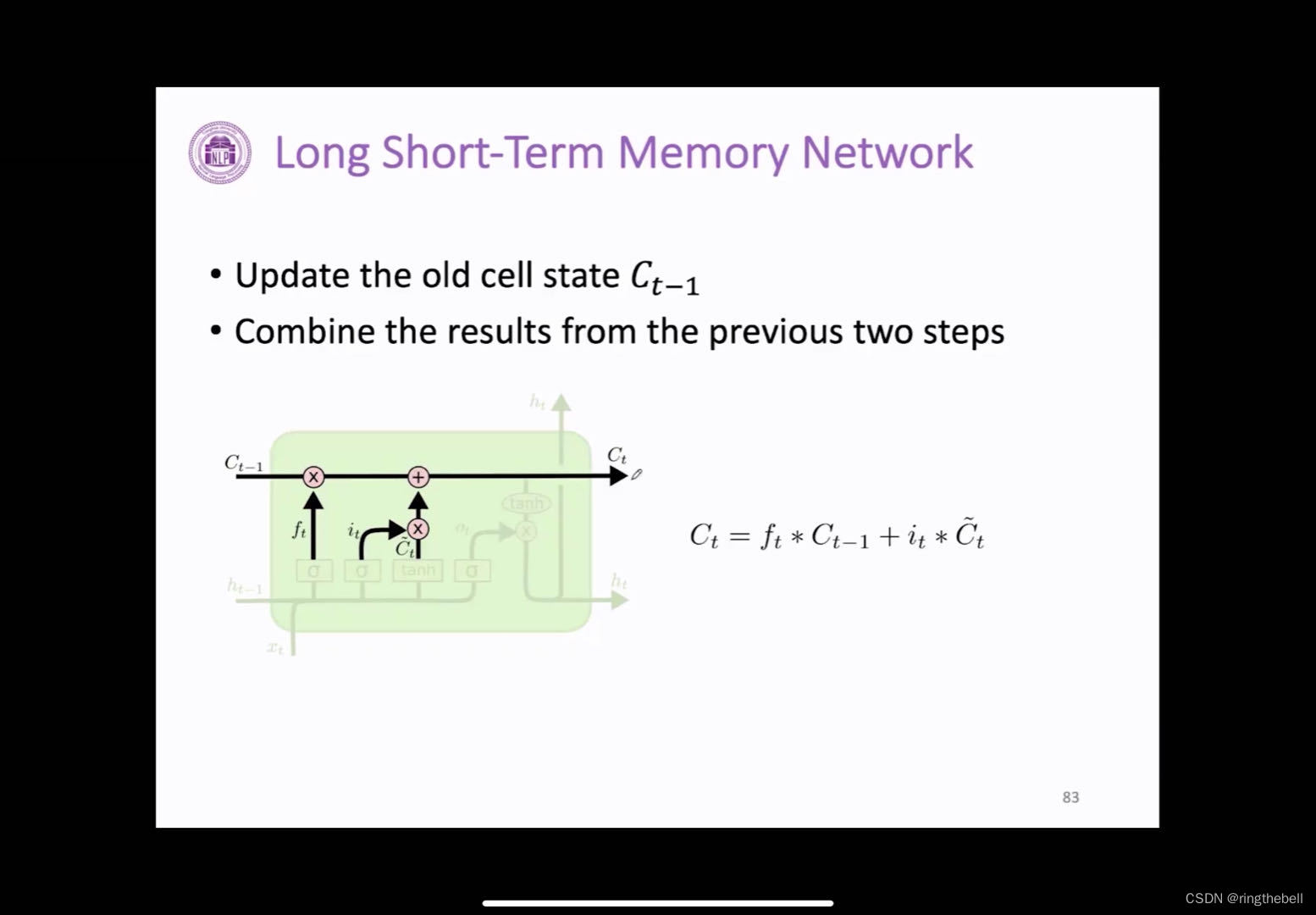
最后为输出门,它决定了我们有哪些信息可以进行输出,因为当我们计算完ct-1之后,它会进入到下一层,同时我们还需要计算我们新的ht。
这个门的计算也是当前输入和上一层这个ht-1进行计算,然后乘上输出门的专属矩阵以及B经过计划使得我们得到一个值,得到这个值之后,我们发现这个cell状态,首先我们也会经过一个激活函数,然后乘上我们输出门,来得到我们最终的新的一层状态传入到下一层,这里也可以理解为,我们可能会需要调整一些句子信息,来适应一些特定单词的一些表述。

综上,LSTM很强大,因为我们每个隐藏层都是已经有一个内部的神经元网络已经计算好了,所以尤其是在我们做堆叠或者做的我们往很深的时候,它会表现的性格很好,而且由于我们引入了门控制的机制,他对神经网络的输入和输出,会进行一个动态控制,会增强我们对信息的利用能力
而且LSTM可以有效地缓解梯度的问题,所以当你有大量的数据的时候,也很好用,当年比较火爆的时候,很多论文都采用了LSTM。
bidirectional RNNs双向RNN
(同理也可以衍生出双向LSTM)
前面提到,RNN都有一个特点,就是每一个时间步下的状态里面的隐藏状态变量,都是从我们过去这个序列,以及当前输入来捕获信息的,或者允许过去的值,来影响我们当前状态,但有的时候,我们可能有些应用我们在输入预测的时候或者我们在计算当前的时候不仅是依赖过去,我们可能会依赖于未来的输入,相当于是我们可能会依赖整个输入序列,而不仅仅是过去。
例如:当我们进行手写体识别的时候,我们对我们当前字的识别,可能不仅仅取决于过去,我们还会取决于未来的几个字,还有语音识别,当前我们的音符因素也或者取决于未来的几个值数据。
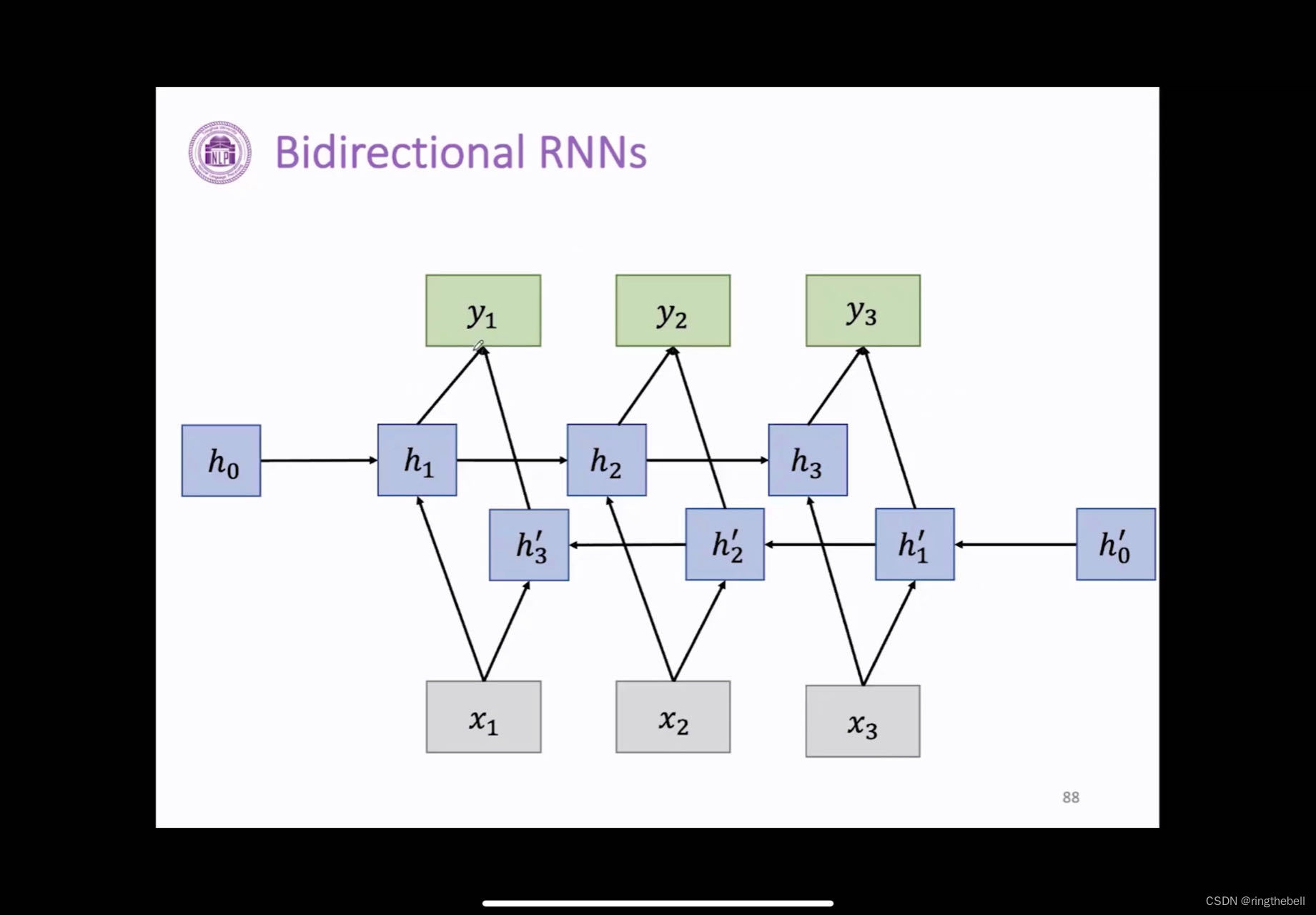
而双向RNN,如下所示:
h0到h3那个走向,为一个从前往后移的RNN那个状态
h‘0到h'3,相当于一个从后往前的RNN的状态
图中,就相当于我们每一个时刻对应输入,它同时都会拿到我们ht,即从过去的一个相关信息总结,我们也可以拿到未来的一个数据相关的总结,这样我们的到的信息就会很多,性能也会表现的更好一点
summary
循环神经网络(Recurrent Netural Network,Rnn)
RNN可以很好体现顺序记忆,但由于它自身的机制问题,也会存在一些梯度问题
RNN变体可以很好地解决这个问题,同时性能也会有很大的一个提升
















 2081
2081











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









