







超级鹰 url : https://www.chaojiying.com/
超级鹰使用步骤:
点击左上角登录/注册
3 .注册完成后:进入到用户中心
4.在用户中心这一栏中找到 “开发文档”并且进行点击
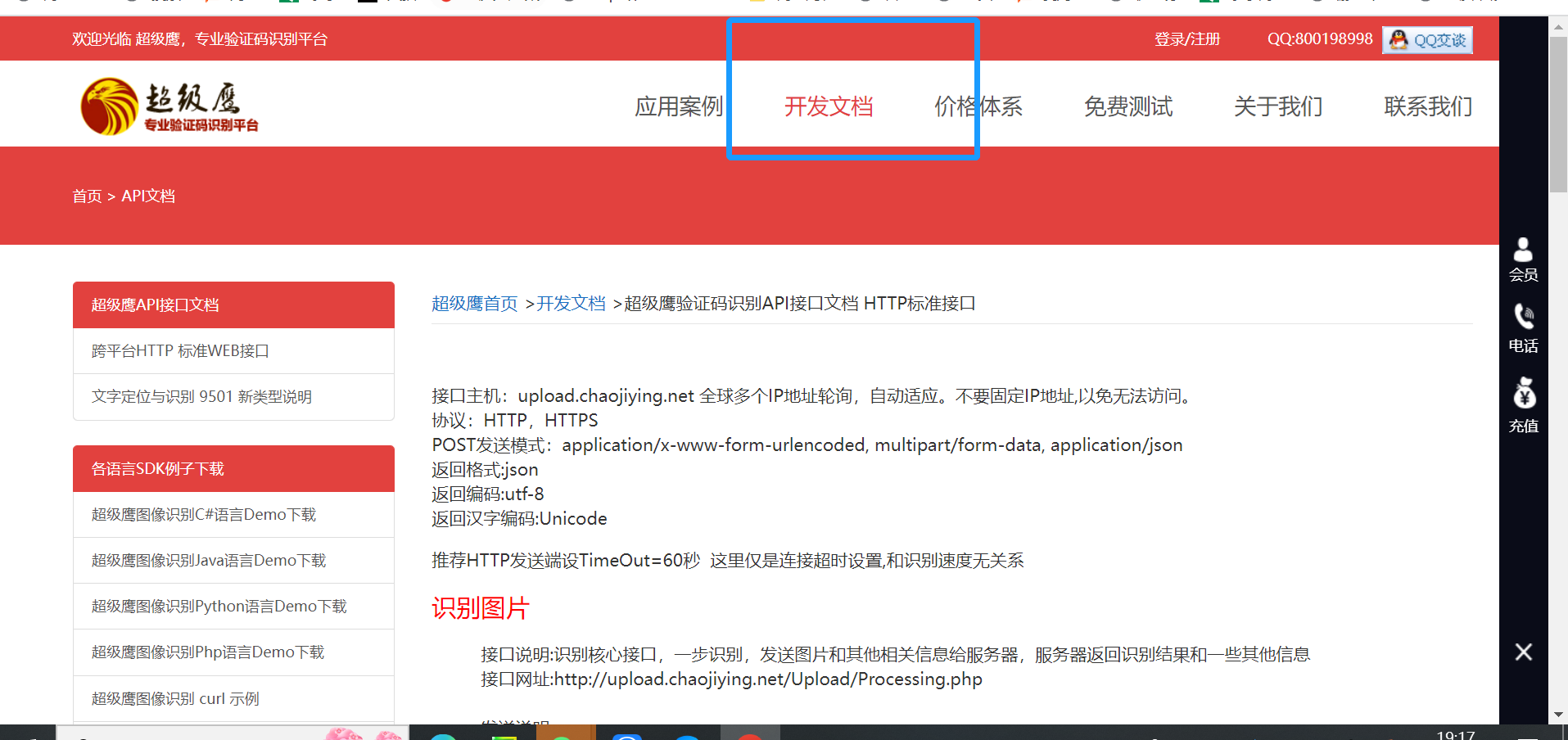
在开发文档这一页面中的左边找到“超级鹰图像识别Python语言Demo”下载,点击
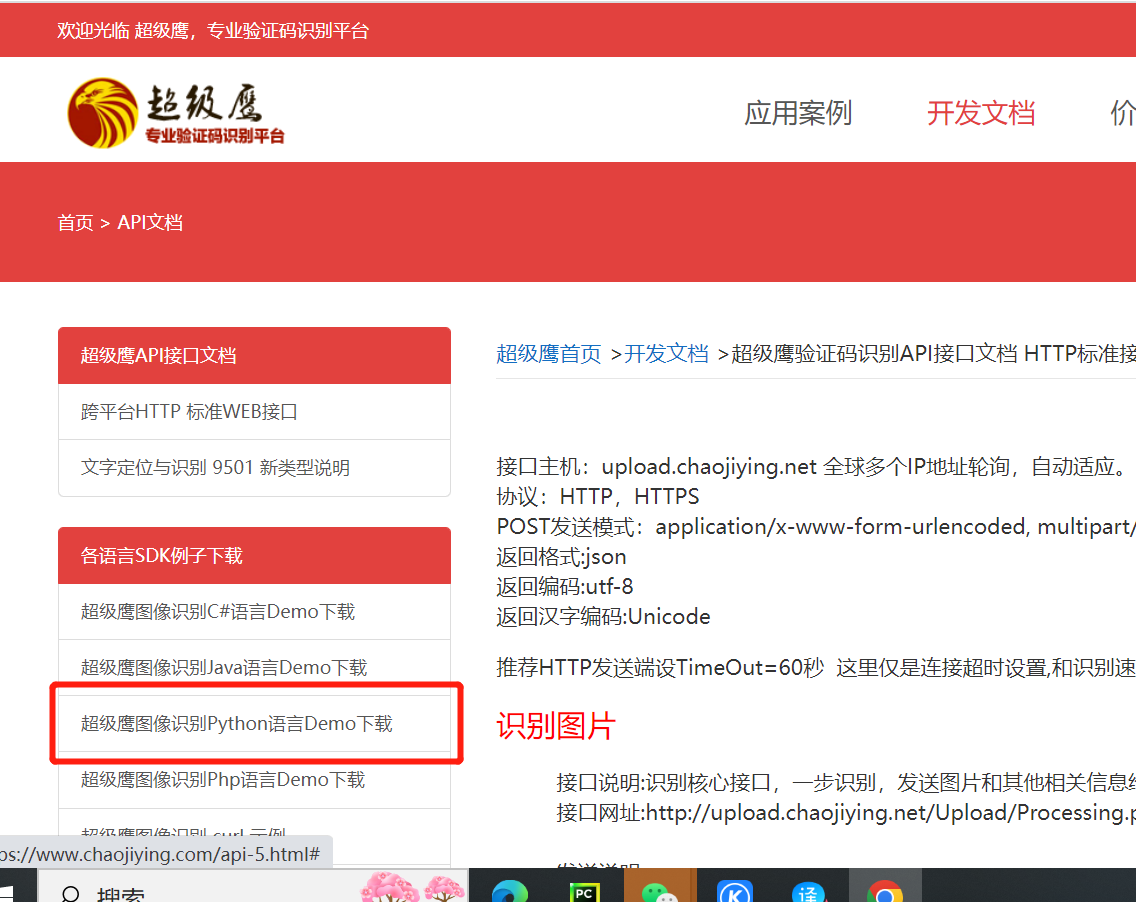
点击后出现如下页面找到“点击这里下载”点击下载
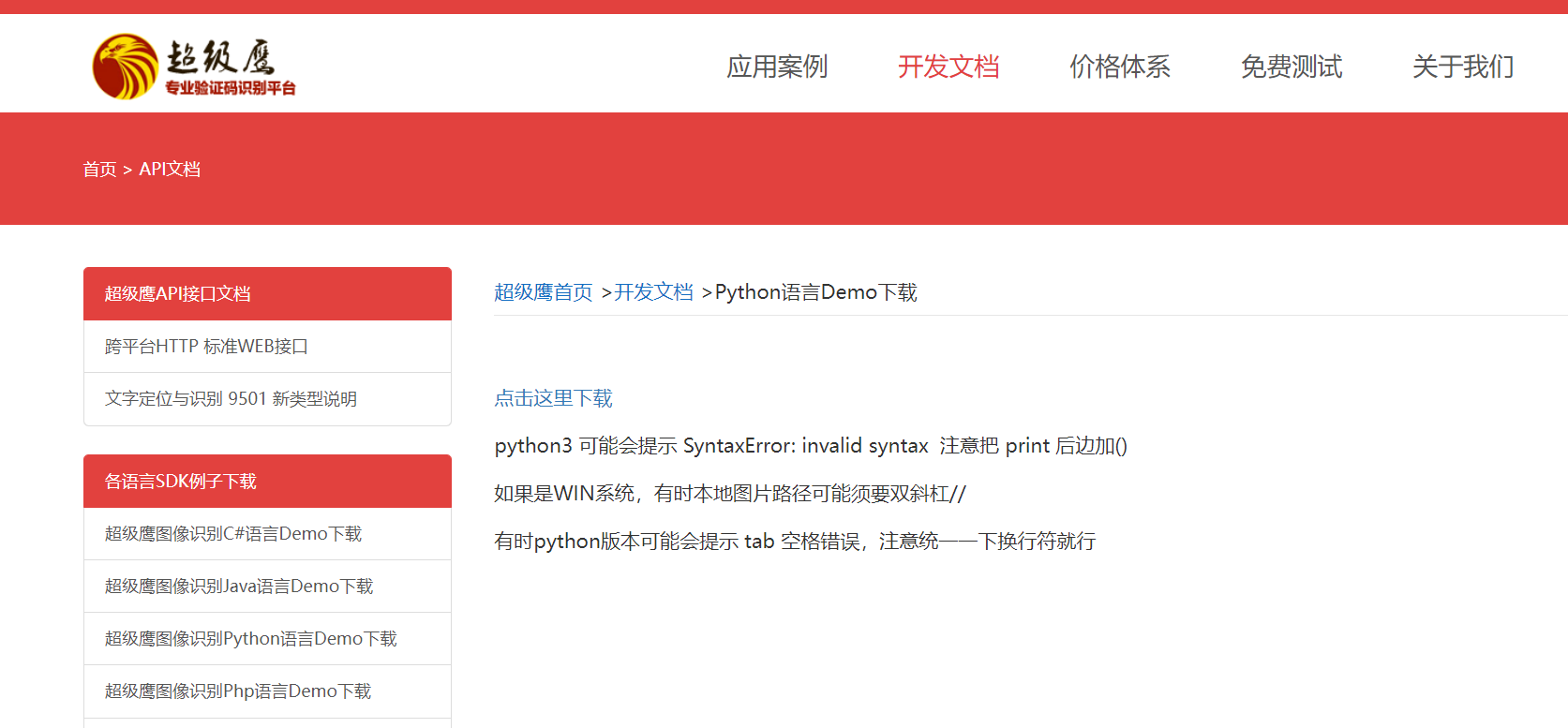
下载完成会出现如下页面
将其显示在文件夹中
因为Chaojiying_Python.rar 是一个压缩文件,所以将其解压在当前文件中
解压完成后,会多出Chaojiying_Python这样一个文件,点击进入
进入Chaojiying_Python文件夹后会出现,这样一个页面,注意chaojiying.py这个python文件
将chaojiying.py 这个文件复制下来,并随后打开pycharm
打开pycharm后找到你需要运行实现自动化登录python文件夹,我需要实现登录页面的验证识别,我的这个文件在python爬虫这个文件中
将刚才复制的“ chaojiying.py“,python文件复制在当前需要使用的.py文件中(python爬虫文件中)
最好在pycharm看一下刚才复制的这个chaojiying.py , python文件,这个文件中详细注释了,这个文件的详细功能。
随后就可以肆意的玩了超级鹰所具备的功能了。
实战:识别古诗文网登录页面中的验证码
使用超级鹰平台识别验证码的编码流程:
将验证码图片进行本地下载
调用平台提供的示例代码进行图片数据识别
实例代码:
import requests
from lxml import etree
from chaojiying import Chaojiying_Client
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Mobile Safari/537.36'}
page_text =requests.get(url=url,headers=headers)
page_text.encoding = 'utf-8'
html = page_text.text
page_html = etree.HTML(html)
# print(page_html)
code_img_src = page_html.xpath('/html/body/form[1]/div[4]/div[4]/img/@src')
# print(code_img_src) 获得到的src图片地址为:/RandCode.ashx
# 正确图片地址为: ’https://so.gushiwen.cn/RandCode.ashx‘
#我们要实现图片地址的拼接
code_wanzheng_src = 'https://so.gushiwen.cn' + page_html.xpath('/html/body/form[1]/div[4]/div[4]/img/@src')[0]
# 如果因为通过xpath方法提取出来的数据是一个存储在列表中的数据,而字符串拼接用的是字符串,如果不通过 [0] 列表索引 ,将数据拿出来会报出如下错误
# ypeError: can only concatenate str (not "list") to str
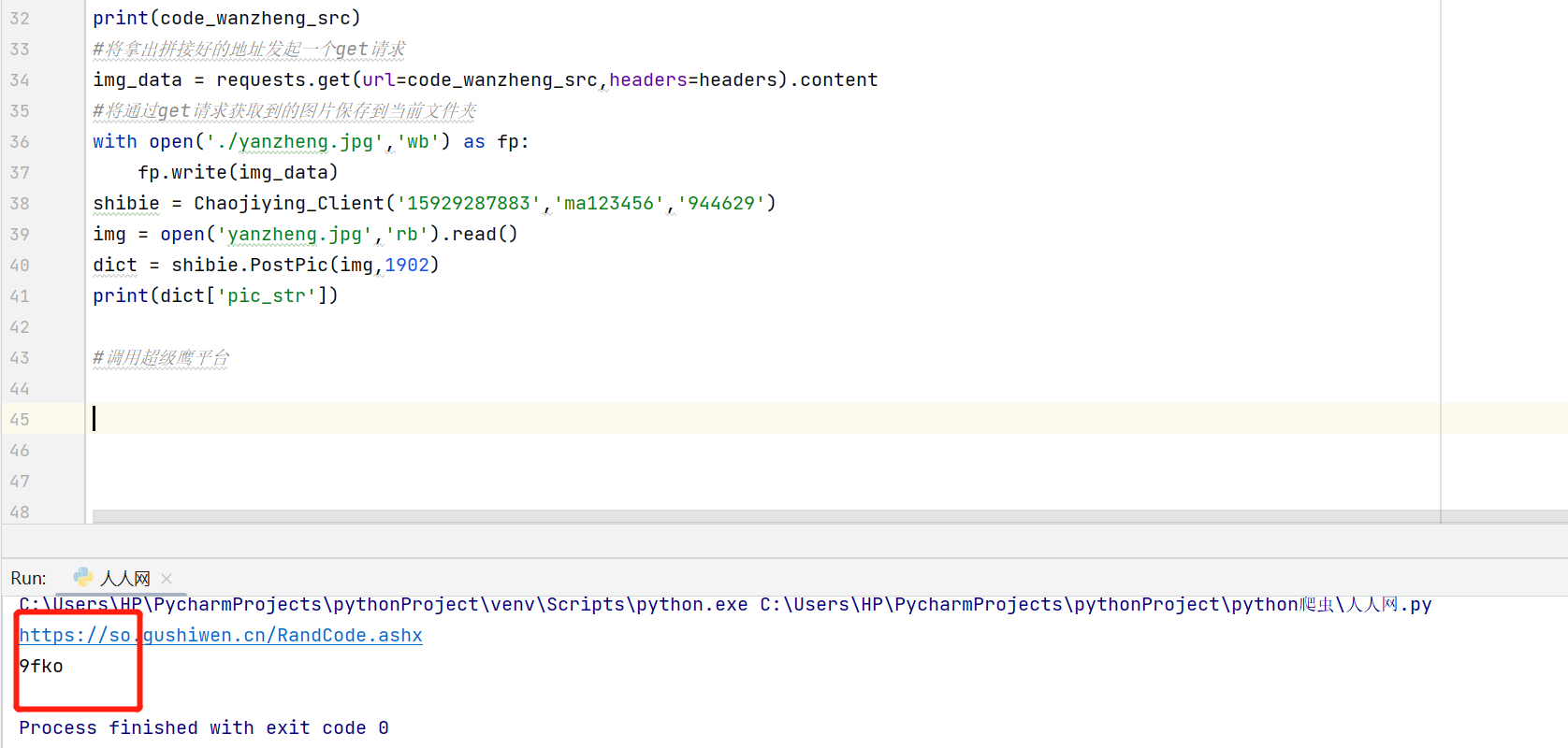
print(code_wanzheng_src)
#将拿出拼接好的地址发起一个get请求
img_data = requests.get(url=code_wanzheng_src,headers=headers).content
#将通过get请求获取到的图片保存到当前文件夹
with open('./yanzheng.jpg','wb') as fp:
fp.write(img_data)
shibie = Chaojiying_Client('15929287883','ma123456','944629')
img = open('yanzheng.jpg','rb').read()
dict = shibie.PostPic(img,1902)
print(dict['pic_str'])代码不理解的我可以详细说一下
给所登录网站发送请求的老一套流程
import requests
from lxml import etree
from chaojiying import Chaojiying_Client
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Mobile Safari/537.36'}
page_text =requests.get(url=url,headers=headers)
page_text.encoding = 'utf-8'
html = page_text.text
xpath页面解析
page_html = etree.HTML(html)
# print(page_html)
code_img_src = page_html.xpath('/html/body/form[1]/div[4]/div[4]/img/@src')
# print(code_img_src) 获得到的src图片地址为:/RandCode.ashx
# 正确图片地址为: ’https://so.gushiwen.cn/RandCode.ashx‘
#我们要实现图片地址的拼接
code_wanzheng_src = 'https://so.gushiwen.cn' + page_html.xpath('/html/body/form[1]/div[4]/div[4]/img/@src')[0]
# 如果因为通过xpath方法提取出来的数据是一个存储在列表中的数据,而字符串拼接用的是字符串,如果不通过 [0] 列表索引 ,将数据拿出来会报出如下错误
# ypeError: can only concatenate str (not "list") to str
print(code_wanzheng_src)通过打印可以拿到这个验证码的完整地址因为用xpath获取src 图片地址不够完整
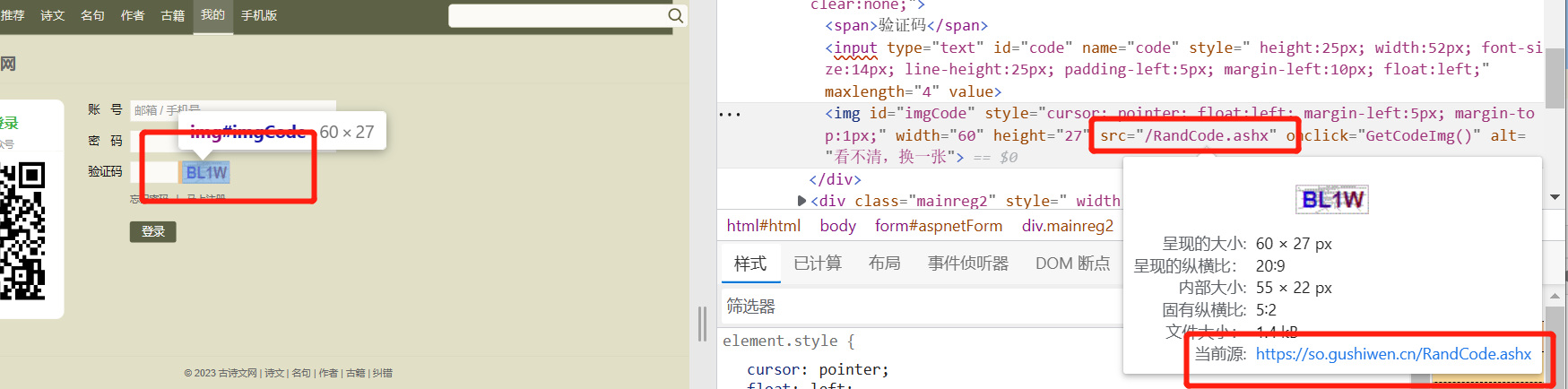
如何获取一段内容在html页面的详细位置,因为这样方便通过,bf4,获取正则,或者 xpath解析,
将鼠标移动到你需要获取内容页面显示的位置(我需要获取验证码在html页面的位置),鼠标右击,抓包工具就会自动定位到你需要内容的位置,(图片显示的是验证码在html页面的位置)。
通过get请求获取到的图片保存到当前文件夹(你对图片发起一个get请求,其实就是对它发起一个下载请求)
with open('./yanzheng.jpg','wb') as fp:
fp.write(img_data)超级鹰验证码识别需要输入的信息
想要使用超级鹰就需要输入上面这些信息
shibie = Chaojiying_Client('15929287883','ma123456','944629')
打开刚才下载验证码图片的保存位置
img = open('yanzheng.jpg','rb').read()
给超级鹰传输图片信息(img就是下载的验证码)和这个平台使用 验证码类型 代号码
dict = shibie.PostPic(img,1902)
#打印验证码内容
print(dict['pic_str'])验证码类型:1902 代表:平台所使用验证码类型是:常见4~6位英文数字
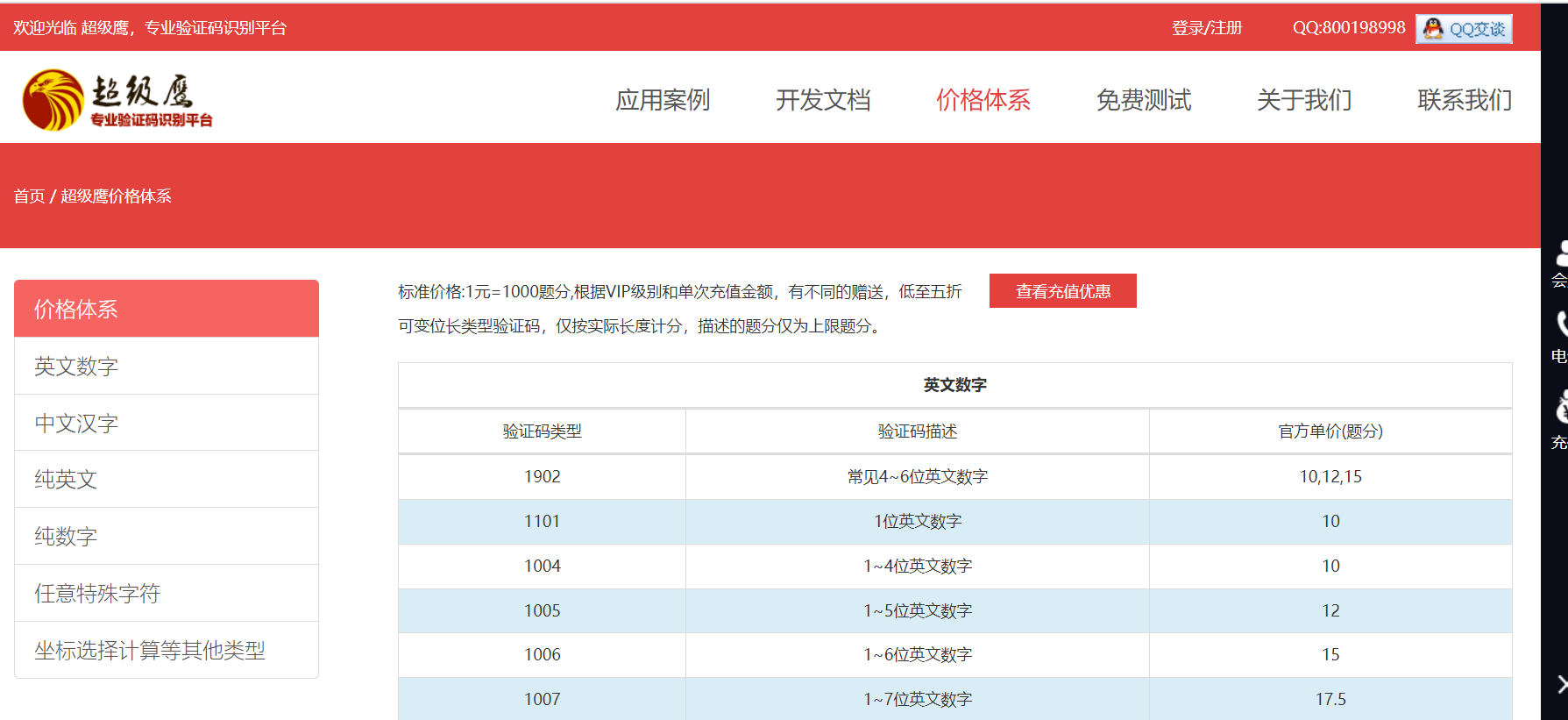
古诗文网登录页面:(注意观察验证码类型在超级鹰“价格体系中找到对应的代码号将其正确填入”)
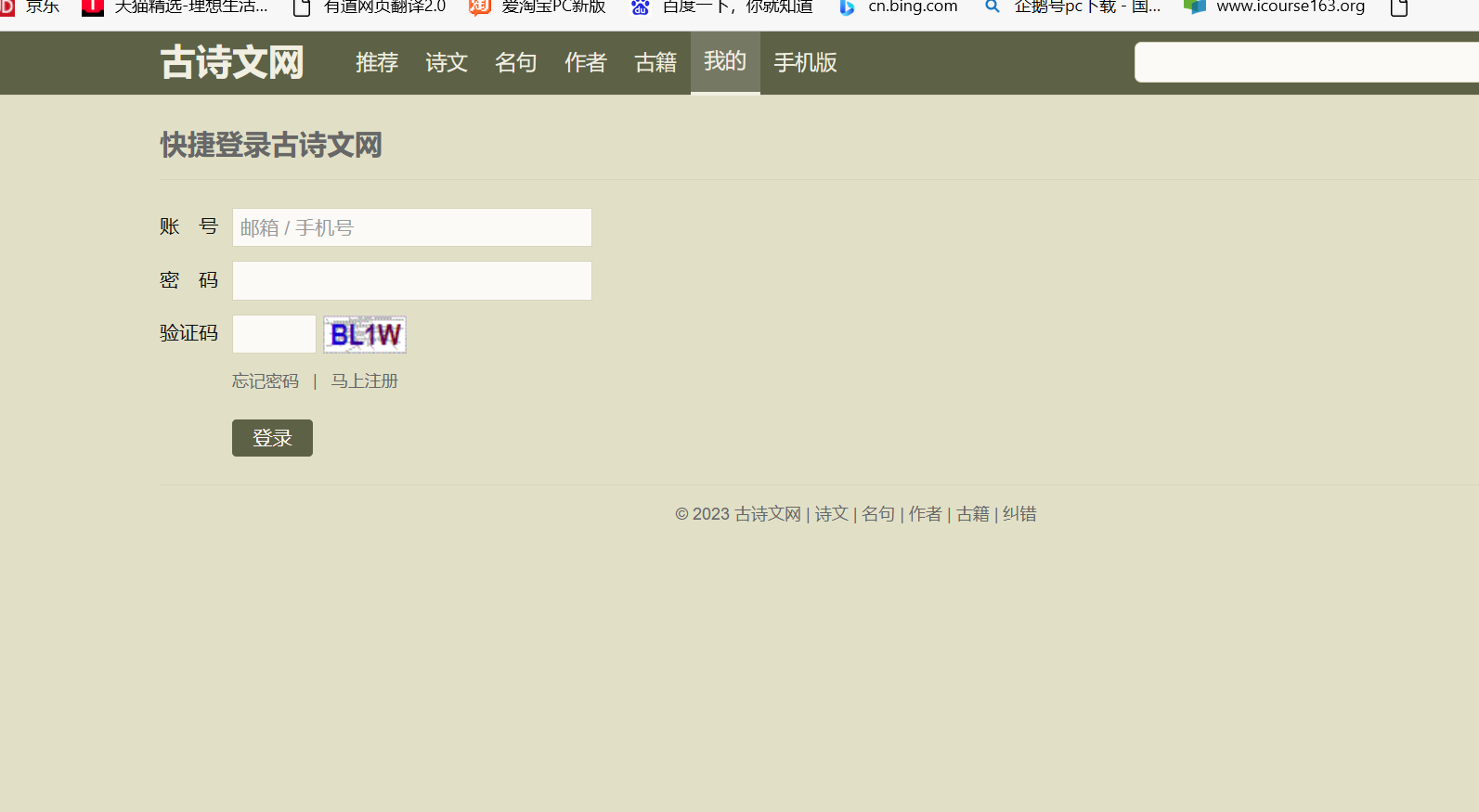
测试:(花了1分大洋呜呜呜)
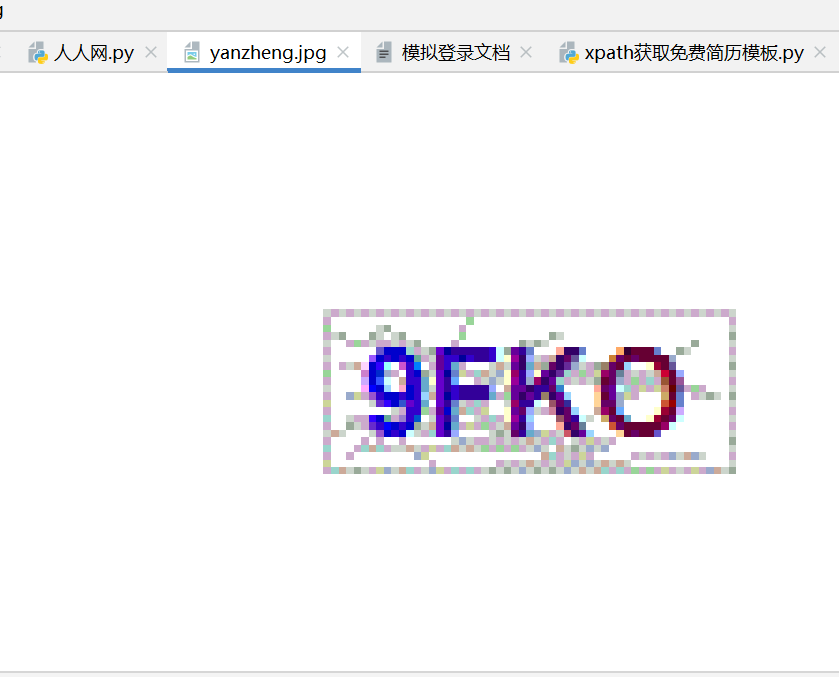
验证码是: 9fko
我们在下载的验证图片看看是不是:
总结:
论语二则:
“里仁为美,择不处仁,焉得知?”-《里仁篇》
意思是说:“居住在有仁德的地方才是好的。选择住处,不住在有仁德的地方,那怎么能说是聪明智慧呢?”
“我未见好仁者,恶不仁者。好仁者,无以尚之;恶不仁者,其为仁矣,不使不仁者加乎其身,有能一日用其力于仁矣乎?我未见力不足者。盖有之矣,我未之见也。”-《里仁篇》
孔子说:“我没有见过爱好仁德的人,也没有见过厌恶不仁的人。 爱好仁德的人,是不能再好的了;厌恶不仁的人,在实行仁德的时候,不让不仁德的人影响自己。 有能一天把自己的力量用在实行仁德上吗? 我还没有看见因为力量不够的。 这种人可能还是存在,但我没见过。 ”

















 748
748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









