






Spark反压机制----令牌桶机制
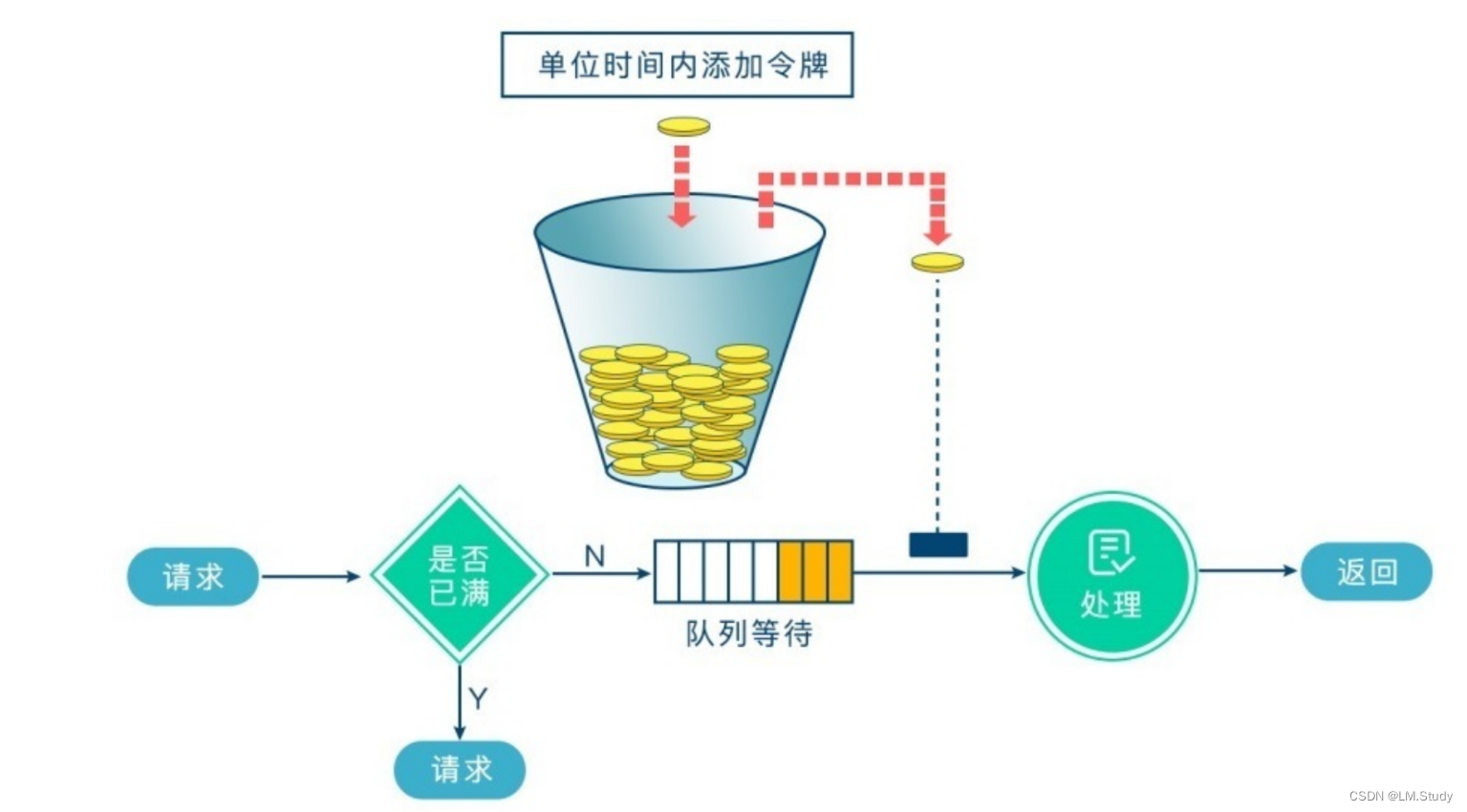
机制: 大小固定的令牌桶可自行以恒定的速率源源不断地产生令牌。如果令牌不被消耗,或者被消耗的速度小于产生的速度, 令牌就会不断地增多,直到把桶填满。后面再产生的令牌就会从桶中溢出。最后桶中可以保存的最大令牌数永远不会超过 桶的大小。当进行某操作时需要令牌时会从令牌桶中取出相应的令牌数,如果获取到则继续操作,否则阻塞。用完之后不 用放回。
个人解释:其实就是生产者和消费者模型;请求进行来之后要去桶里面取一个token,然后才能进行处理,这时就能解决用来解决 处理速度比摄入速度慢的情况;
Spark比MR快的原因是什么?
1:内存计算:Spark采用内存计算模型,将数据尽可能地存储在内存中进行处理,而MapReduce则依赖于磁盘读写。内存计算速 度快于磁盘读写,因此Spark能够更快地访问和处理数据。
2:运行模式:Spark支持多种运行模式,包括本地模式、独立部署模式和集群模式。而MapReduce主要运行在分布式集群上。 Spark在本地模式下可以充分利用单机多核资源进行并行计算,从而提高计算效率;
3:数据共享:在Spark中,可以通过共享变量(如广播变量和累加器)来减少数据的传输和复制。共享变量可以在集群中的不同 任务之间共享数据,减少数据的序列化和网络传输开销,提高计算效率。
4:DAG执行引擎:Spark使用基于DAG(有向无环图)的执行引擎,将作业划分为一系列阶段,每个阶段由一组任务组成; 简单说,有向无环图切分了任务的执行先后顺序;
5:封装的三大数据结构----RDD,广播变量,累加器
RDD:弹性分布式数据集,RDD可以在内存中缓存数据,并支持数据的转换和持久化操作。RDD的特性使得Spark能够在数 据处理过程中快速访问和转换数据,从而提高计算性能
广播变量:分布式共享只读变量 ,Driver会给每个节点的 Executor 一份副本,这个副本里可以存储RDD的运算结果,达到数 据共享的目的,减少数据之间的网络传输;
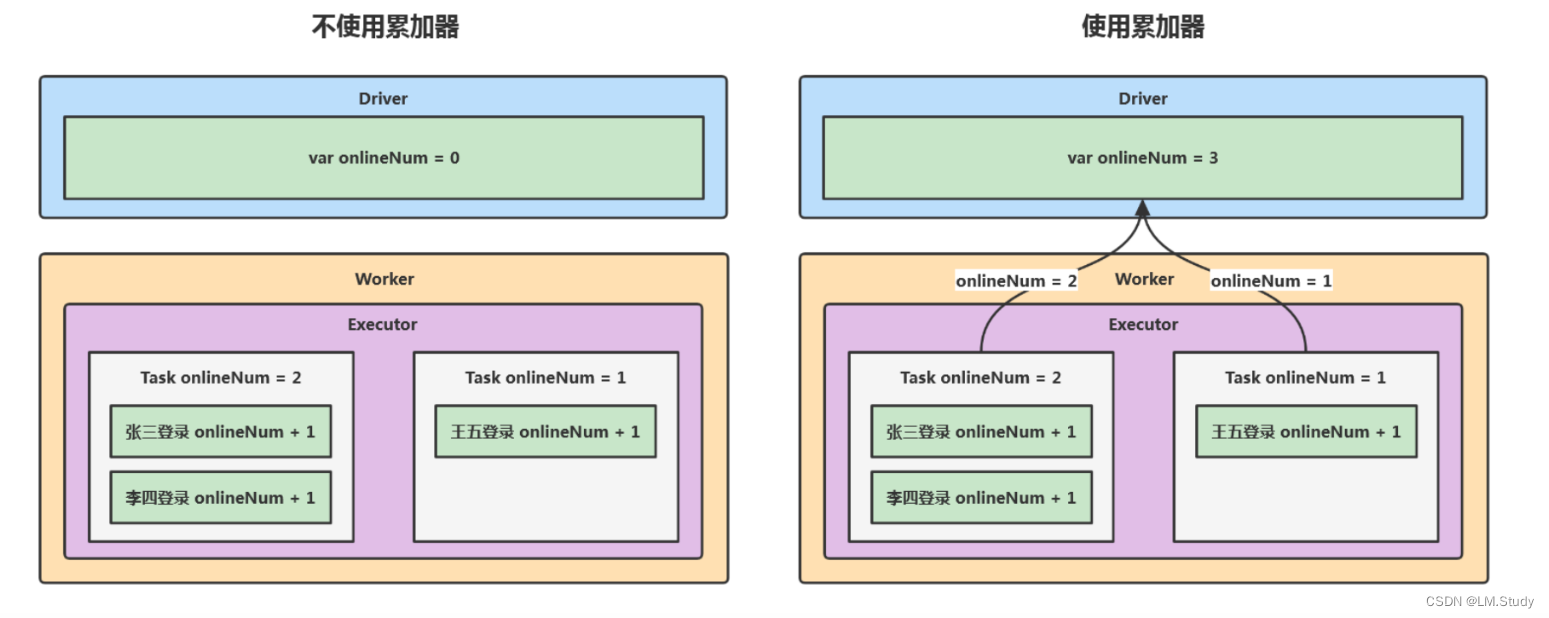
累加器:分布式共享只写变量;每个任务可以独立地更新累加器的值,Spark会自动将各个任务的更新结果进行聚合,并最 终得到累加器的最终值。
Spark中DAG的引入解决了什么问题
1:每个 MapReduce 操作都是相互独立的,HADOOP不知道接下来会有哪些Map Reduce。
2:每一步的输出结果,都会持久化到硬盘或者 HDFS 上。 3:当以上两个特点结合之后,我们就可以想象,如果在某些迭代的场景下,MapReduce 框架会对硬盘和 HDFS 的读写造成大量 浪费。
4:而每一步都是堵塞在上一步中,所以当我们处理复杂计算时,会需要很长时间,但是数据量却不大。
所以 Spark 中引入了 DAG,它可以优化计算计划,比如减少 shuffle 数据。
Spark中使用DAG体现在哪?
任务依赖
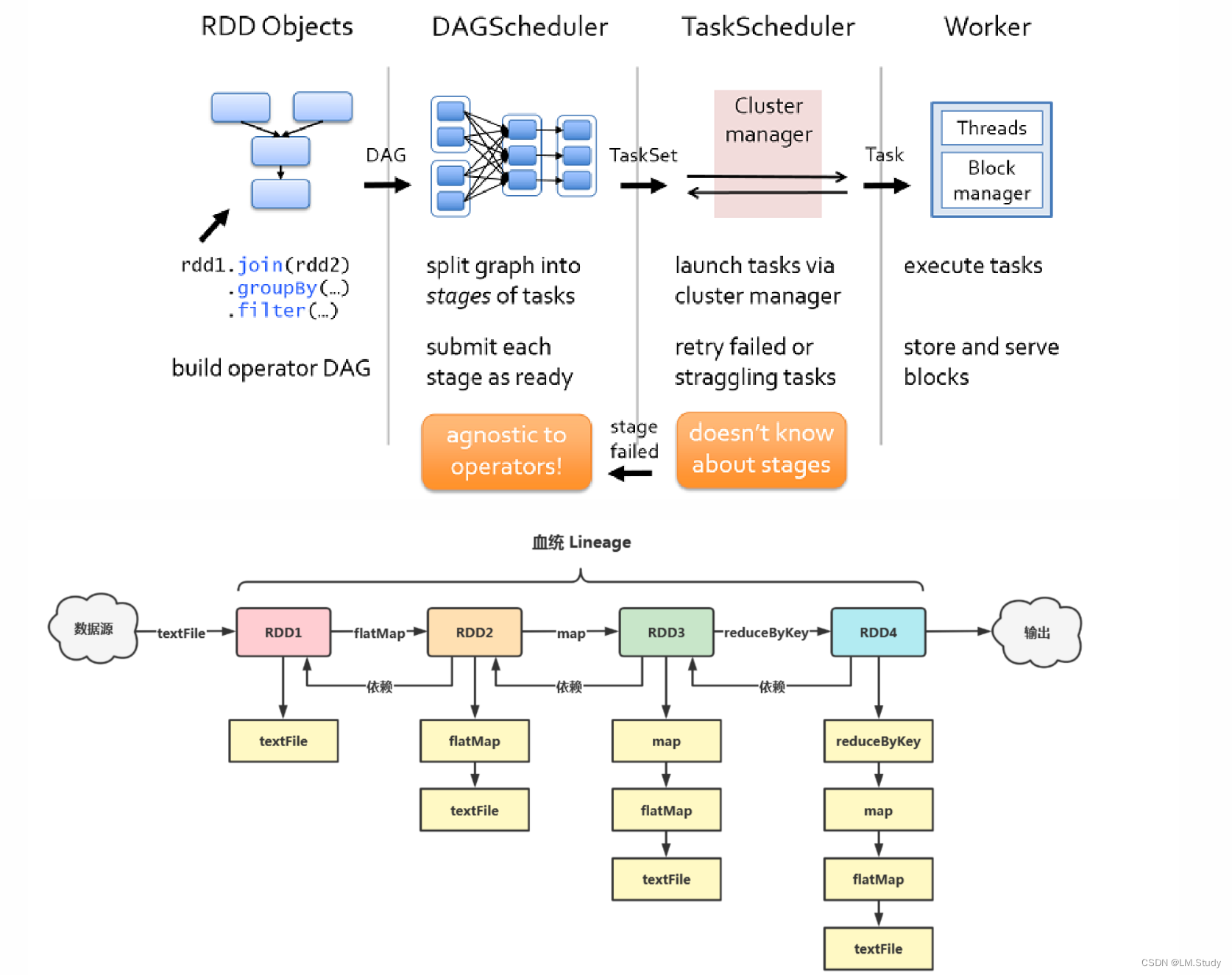
通过将用户定义的一系列的 RDD 转化成 DAG 图,然后 DAG Scheduler 把这个 DAG 转化成一个 TaskSet,而这个 TaskSet 就可以向集群申请计算资源,集群把这个 TaskSet 部署到 Worker 中去运算了。当然了,对于开发者来说,他的任务是定义一些 RDD,在 RDD 上做相应的转化动作,最后系统会将这一系列的 RDD 投放到 Spark的集群中去运行;然后运行结果进行driver收集;
在这个阶段中,RDD之间的依赖关系是靠DAG进行维护的,通过这些依赖关系可以进行数据恢复,这也是一种Spark的容错机制,同时这也是RDD之间的依赖关系的底层,就是DAG;
转换操作---RDD算子
RDD之间进行算子转换时,不会在原有的基础上进行修改,而是产生一个新的RDD;因此保留了两者之间的数据关系;同时,在使用控制算子时,cache(),persist()这两种算子会保留他们和RDD之间的关系,即数据和运算之间的关系;这些都是DAG的应用;
Shuffle操作
Shuffle是指将数据重新分区和重新排序的操作,例如groupByKey或join等操作。Shuffle操作会涉及数据的洗牌和网络传输,因此会引入较大的开销。Shuffle操作会创建新的阶段,并在DAG中表示数据的流动和依赖关系
RDD或DataFrame之间的依赖关系
在Spark中,RDD或DataFrame之间存在着父子关系或依赖关系。每个RDD或DataFrame都保存了对其父RDD或DataFrame的依赖信息,以及自身的转换操作。这种依赖关系构成了DAG的一部分,用于确定数据的来源和计算流程。
SQL下的存储引擎InnoDB和MyISAM行式存储引擎的区别
-
InnoDB(支持事务、行级锁、外键关联):
-
InnoDB是MySQL的默认存储引擎(从MySQL 5.5版本开始)。
-
它支持事务处理,可以使用ACID(原子性、一致性、隔离性、持久性)特性来确保数据的一致性和完整性。
-
InnoDB采用行级锁定,允许多个并发事务对不同行的数据进行读写操作,提供更好的并发性能。
-
它支持外键关联,可以维护表之间的引用完整性,确保数据的一致性。
-
InnoDB还提供了崩溃恢复能力,能够在系统崩溃后自动恢复数据的完整性。
-
-
MyISAM(不支持事务、表级锁、全文索引):
-
MyISAM是早期版本的MySQL默认存储引擎,目前仍然广泛使用。
-
它不支持事务处理,这意味着不能使用回滚和提交等操作来确保数据的完整性和一致性。
-
MyISAM采用表级锁定,这意味着在执行写操作时会锁定整个表,可能导致并发性能较差。
-
它不支持外键关联,无法自动维护引用完整性。
-
MyISAM的一个主要优势是对于读密集型应用,它的查询性能通常较好。
-
此外,MyISAM还提供全文索引功能,可以进行高效的全文搜索。
-
选择使用哪种存储引擎取决于具体的应用需求。如果需要事务支持、并发性能和数据完整性,以及对外键关联和崩溃恢复的需求,应选择InnoDB。而如果对于读密集型应用,不需要事务支持,并且需要全文索引功能,MyISAM可能是一个更好的选择。















 1008
1008











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









