






Java并发工具包 上
回顾
回顾并发编程-理论篇,我们知道并发编程有最核心的三个工作,分工,协作,互斥,分工就是将大的任务,拆分成小任务,然后将这些小任务分配给线程,协作指的是,由于任务与任务存在依赖关系,比如任务B,需要用到任务A执行完后产生的结果,这个时候,就需要它们之间互相协作,保证整个任务的正确性。互斥指的是,为了保证程序的正确性,对于共享变量的读写,需要保证同一时刻只有一个线程操作。
Java提供的基本并发原语 Lock Condition Semaphore
本篇文章主要是对Java并发包提供的工具做一些简单的介绍和分类,Java并发包给我们提供了最基本的同步原语,锁,条件变量,信号量,在上篇文章我介绍过Java中解决并发问题的万能钥匙是管程,而锁和条件变量就是就是管程的组成部分。我也提到过 synchronized 代码块,提供的只是阉割版的管程,即条件变量只能有一个,如果你忘记了管程模型,可以看看下面这个图
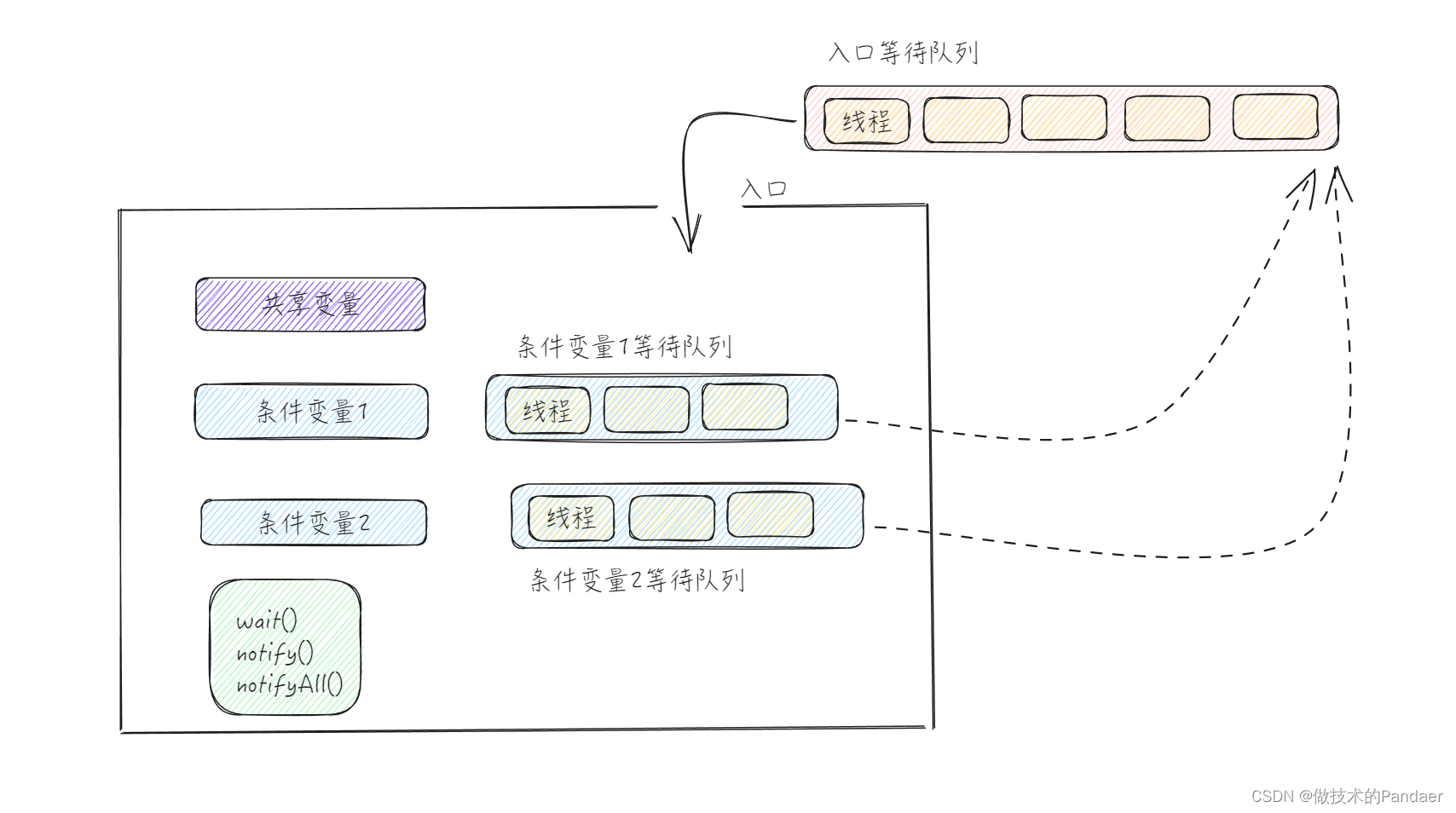
具体的流程,我就不详细说明了,接下来我们利用并发包中提供的Lock 以及 Condition实现一个阻塞队列,好好体会一下管程模型 代码链接
信号量也是能解决各种并发问题(互斥,同步),可以说管程就是在它的基础上发展而来,信号量其实可以看做是一个计数器,数字代表资源的数量,我们可以把它当做锁来使用,也可以把它用作同步(线程之间的协作)工具,我们通过信号量实现锁,以及利用信号量实现阻塞队列,来体会一下信号量 代码链接
class MyLock {
private final Semaphore semaphore = new Semaphore(1);
public void lock() {
try {
semaphore.acquire();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
public void unlock() {
semaphore.release();
}
}
锁的作用:保证临界区同一时刻只能有一个线程执行,也就是我们常说的互斥。
从另外一个角度来看,锁更像是一种权限的代表,就好似古时候的尚方宝剑,有了宝剑就可以行使皇帝的权力,锁也一样,一个线程获取了锁,就有了执行临界区的权限,锁只有一把,线程A获取了,其他线程只能等待着线程A把锁归还,才能去争夺执行临界区的权限。从这个角度,我们可以分析出,锁之所以可以保证互斥性,其实是因为对于这个临界区而言,只有一把锁,即一个资源。很自然的,我们就可以将信号量的初始值设置为1,表示资源只有一个。信号量可以完美的解决互斥问题,那同步问题呢?别急,我们看看如何利用信号量实现阻塞队列
public class MyBlockingQueueBySemaphore<T> {
private final LinkedList<T> queue = new LinkedList<>();
private int size;
//队列中不空的数量
private final Semaphore dataNum = new Semaphore(0);
//队列中空的数量
private final Semaphore nullNum;
private final Semaphore lock = new Semaphore(1);
public MyBlockingQueueBySemaphore(int limit) {
this.nullNum = new Semaphore(limit);
}
/**
* 入队操作,如果队列满了,就阻塞
* @param data
*/
public void enq(T data) {
try {
nullNum.acquire(); //申请一个空位
//由于LinkedList不是线程安全的,所以需要互斥添加数据
try {
lock.acquire();
queue.add(data);
size++;
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.release();
}
dataNum.release(); //增加不空位的数量
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
/**
* 出队操作 如果队列是空的,就阻塞
* @return
*/
public T deq() {
try {
dataNum.acquire(); //申请一个不空位
T res;
try {
//同样由于LinkedList不是线程安全的,对于queue的读写必须互斥
lock.acquire();
res = queue.removeFirst();
size--;
} catch (InterruptedException e) {
throw new RuntimeException(e);
}finally {
lock.release();
}
nullNum.release(); //增加一个空位
return res;
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
这段代码的核心:如何控制 dataNum ,nullNum 中资源的增减,来达到同步的效果,首先我们需要知道,阻塞队列队列什么时候阻塞呢?大致有两个地方,在入队操作时,如果队列满了,那么就会阻塞,以及在出队操作时,如果队列空了,也会阻塞。 那么现在的问题是,如何用信号量表示队列满了,同时在队列满了的时候,信号量恰好可以让线程阻塞,同样,如何利用信号量来表示队列为空,同时队列空了的时候,信号量恰好能让线程阻塞。
那么我们就需要明白,信号量的工作机制,信号量在什么时候,会让线程阻塞。在信号量的内部,维护了一个计数器,在执行acquire() 方法后,计数器的值-1,如果计数器的值 < 0, 那么当前线程就会阻塞,并加入到阻塞队列中。在执行release() 方法后,计数器的值+1,如果计数器的值<=0,那么计数器会从阻塞队列中唤醒一个线程。
简而言之,如果计数器的值=0的时候,执行 acquire() 这个方法,就会导致当前线程阻塞。也就是说,我们无法手动控制线程阻塞,那么就只能利用信号量的这个阻塞时机了,于是我们定义了两个信号量,一个是dataNum,表示队列中数据的个数,nullNum 表示队列中空的个数,初始化的时候,空的个数为队列的长度,数据的个数为0,在入队操作时,空的个数-1,数据的个数+1,在出队操作时,数据的个数-1,空的个数+1, 利用这两个信号量的增减,让阻塞队列正常运行起来,显然,利用信号量实现的阻塞队列,比用Lock + Condition实现的阻塞队列要困难许多,原因就在于对于Condition,我们可以手动控制线程的阻塞,而对于信号量,我们只能利用信号量的阻塞时机,这也是管程的优势所在。
互斥工具
按照,并发编程的三个核心步骤,分工,同步,互斥,我也将并发工具类划分为这三类,并发工具类中,用来保证互斥的是Lock,但是它只是一个接口,具体的实现类有 ReentrantLock,ReadWriteLock StampedLock ,为什么会出现这么多锁呢?其实啊,针对不同的并发场景,为了极致的优化性能,就会提供不同的锁,比如在强一致性的并发环境下,我们不得不使用互斥锁(ReentrantLock),然后在读多写少的并发环境下,我们可以使用ReadWriteLock ,为了更加的优化,多读写少的场景,出现了StampedLock锁。接下来我们来简单看一些这些锁的用法,具体更加深入的用法需要结合实践,来思考。
ReentrantLock 什么是可重入锁?
ReentrantLock 翻译过来叫做可重入锁?那什么叫可重入呢?
public class ReentrantLockTest {
private int count = 0;
private final Lock lock = new ReentrantLock();
public int read() {
try {
lock.lock(); //2
return count;
} finally {
lock.unlock();
}
}
public void write(int newVal) {
try {
lock.lock();
count = newVal + read(); // 1
System.out.println("设置成功");
} finally {
lock.unlock();
}
}
}
仔细观察,write() 方法,在重新赋值的时候,注释1处的代码,当前线程,已经获取了锁,然后在read()函数中,还要再次获取锁,如果是可重入锁,那么就不会阻塞到注释2处,如果是不可重入锁,就会阻塞到注释2处。简而言之,只要我有这个锁资源,其他利用这个锁保护临界区的地方,我都可以访问。大家都知道,synchronized 代码块,也是互斥锁,那为什么Java要重复造轮子呢?那是因为Lock可不只有一个lock()方法,它支持更多样式的lock()方法,看下图

至于这些方法有哪些作用,就需要你看看文档,了解一下了。
ReadWriteLock 读写锁的三条规则
在某些情景中,互斥锁有时候可能过于重了,就是让并行程序串行化过于严重了,这种场景就是读多写少,而且没有很强的一致性要求,而这种场景往往很场景,缓存就是这类场景,那么读写锁和互斥锁有什么区别了,主要就是读写锁将线程分为读线程和写线程,读线程与写线程约法三章
- 允许多个读线程读,由读写锁保证可见性和原子性问题
- 只允许一个写线程写
- 读线程和写线程互斥,由读线程就不能有写线程,同理,有写线程就不能有读线程
接下来看看简单用法
public class ReadWriteLockTest {
private String info = "xixi";
private final ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
private final Lock readLock = readWriteLock.readLock();
private final Lock writeLock = readWriteLock.writeLock();
public String readInfo() {
try {
System.out.println(Thread.currentThread().getName() + " 开始读info的值...(上锁之前)");
readLock.lock();
System.out.println(Thread.currentThread().getName() + " 读取info的值: " + info);
return info;
} finally {
readLock.unlock();
}
}
public void writeInfo(String newInfo) {
try {
System.out.println(Thread.currentThread().getName() + " 开始写info的值...(上锁之前)");
writeLock.lock();
info = newInfo;
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName() + " 成功写info的值");
} finally {
writeLock.unlock();
}
}
}
StampedLock 为什么它比读写锁更快呢?
StampedLock比读写锁快的原因在于它提供了乐观读的能力,那么问题来了,什么叫乐观读?乐观读是一种无锁算法,基本思想就是在读取数据的时候不加锁,在使用数据的时候,验证数据是否被修改了,如果被修改了,就需要重试或者回滚,我们来看看下面这段代码
class Point {
private int X;
private int Y;
private final StampedLock stampedLock = new StampedLock();
public int getDistanceFromOrigin() {
long stamp = stampedLock.tryOptimisticRead(); //1
int curX = X;
int curY = Y;
if (!stampedLock.validate(stamp)) {
stamp = stampedLock.readLock();
try {
curX = X;
curY = Y;
} finally {
stampedLock.unlockRead(stamp);
}
}
return (int)Math.sqrt(curX*curX + curY * curY);
}
}
通过阅读这段代码,不知道你有没有产生一个疑问?既然乐观读是一种无锁算法,那线程读的时候不使用Lock不就好了吗,为什么还要执行注释1的代码呢?这就需要回到乐观读的基本思想上了,乐观读在读取数据时不加锁,但是在使用数据时,却要验证数据是否被修改过?那么线程怎么知道数据被修改过呢?答案就是StampedLock。 我们可以将StampedLock看成一个守卫,守卫什么呢?当然是共享的数据,当线程A,需要对共享数据乐观读的时候,守卫并不会加锁,而是给线程A一个凭证,线程A读完之后,去干其他事情了,这个时候线程B来了,线程B要对共享数据执行写操作时,守卫不仅会给线程B一个凭证,还会在共享数据周围设置一个结界(上锁)只有线程B操作完之后,守卫才会释放结界,守卫每次只会保留给线程的最新的凭证,至于之前的凭证,守卫认为是失效的。所以你就看到了这段代码 stampedLock.validate(stamp) 这段代码就在验证,线程手上的凭证是否有效,如果失效就意味着,线程执行某种操作后,有其他线程做了其他事情,可能会导致共享数据发生了改变。
现在我们可以回答一个问题了,既然乐观读是无锁的算法,为什么还要使用锁呢?原因就在于StampedLock除了保证互斥外,还提供了对这片内存区域的监控。
那么StampedLock一般用在什么情况呢?当然还是读多写少的环境下,而且读的比例应该比写的比例大得多,有个问题你需要注意一下,StampedLock不支持可重入。
private final StampedLock stampedLock = new StampedLock();
private int count = 0;
public int read() {
System.out.println("乐观读...");
long stamp = stampedLock.tryOptimisticRead();
int res = count;
if (!stampedLock.validate(stamp)) {
try {
System.out.println("开始悲观读...");
stamp = stampedLock.readLock();
res = count;
System.out.println("悲观读完成...");
} finally {
stampedLock.unlockRead(stamp);
}
}
return res;
}
public void write(int val) {
long stamp = 0;
try {
stamp = stampedLock.writeLock();
System.out.println("锁定写,准备写数据");
count = read() + val;
System.out.println("数据写入完毕");
} finally {
if (stamp != 0) {
stampedLock.unlockWrite(stamp);
}
}
}
通过运行这段代码,你会发现它阻塞了,从而验证了它不可重入。
同步工具
并发程序中,互斥保证了最基本的程序正确性,而同步则是解决了线程与线程之间的依赖性,Java并发包肯定也考虑到了这点,于是提供了两个工具来解决线程与线程之间的依赖性。首先线程与线程之间存在两种关系,一种是父子关系,一种是兄弟关系。如果解决父子关系的同步问题可以使用CountDownLatch,如果解决兄弟关系之间的同步问题可以使用CyclicBarrier
父子关系的同步问题中最常见的一种就是父线程等待子线程运行结束。这种方法我们可以利用线程自带的join()解决,但是如果是线程池呢?该怎么实现父线程等待子线程运行结束这个目标呢?那当然就是CountDownLatch了,他的基本思路是 初始化一个计数器,在子线程中执行-1操作,父线程中检查计数器是否为0,不为零就阻塞,为零就唤醒并放行,这样就实现了等待子线程结束后,父线程才结束。
public static void main(String[] args) {
CountDownLatch countDownLatch = new CountDownLatch(2);
ExecutorService executorService = Executors.newFixedThreadPool(2);
executorService.execute(() -> {
System.out.println("我是线程A 我正在干活....");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("我是线程A,干完活啦");
countDownLatch.countDown();//3
});
executorService.execute(() -> {
System.out.println("我是线程B 我正在干活....");
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("我是线程B,干完活啦");
countDownLatch.countDown();//2
});
try {
countDownLatch.await();//1
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("测试结束");
executorService.shutdown();
}
通过阅读代码,可以简单的利用CountDownLatch解决父子之间的同步问题,我们可以稍微扩展一下,CountDownLatch不仅仅可以解决父子间的同步问题,其实兄弟之间的同步问题也可以解决。再抽象一下,CountDownLatch解决的是一个线程依赖一个或者多个线程的执行结果的同步问题。
那CyclicBarrier解决的是什么问题呢?其实也是,某项任务依赖多个任务的结果,那和CountDownLatch有什么区别呢?区别在于Cyclic这个上,CyclicBarrier可以循环计数,比如任务C依赖任务A,B,当任务A,B执行完后,任务C就可以执行,但是任务C不是一次性任务,而是一个持续性任务,为了运行任务C,就需要安排任务A,B。就这样循环往复。
public static void main(String[] args) {
ArrayBlockingQueue<String> stringQueue = new ArrayBlockingQueue<>(5);
ArrayBlockingQueue<Integer> intQueue = new ArrayBlockingQueue<>(5);
ExecutorService executorService = Executors.newSingleThreadExecutor();
CyclicBarrier cyclicBarrier = new CyclicBarrier(2, () -> {
executorService.execute(() -> {
//任务C
String name = stringQueue.poll();
Integer age = intQueue.poll();
System.out.println("name: " + name + " age: " + age);
});
});
Thread ta = new Thread(() -> {
//任务A
for (int i = 0; i < 5; i++) {
stringQueue.add("pandaer " + i);
try {
TimeUnit.SECONDS.sleep(1);
cyclicBarrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
throw new RuntimeException(e);
}
}
});
Thread tb = new Thread(() -> {
//任务B
for (int i = 0; i < 5; i++) {
intQueue.add(i);
try {
TimeUnit.SECONDS.sleep(2);
cyclicBarrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
throw new RuntimeException(e);
}
}
});
ta.start();
tb.start();
try {
ta.join();
tb.join();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("测试结束");
}
说明一下,为什么需要在executorService.execute()中执行任务C,这是由于回调函数的执行,是由最后一个将CyclicBarrier中计数器减到0的线程来执行的,如果任务C是一个耗时任务,那么就会拖慢整个循环任务。
int index = --count;
if (index == 0) { // tripped
Runnable command = barrierCommand;
if (command != null) {
try {
command.run();
} catch (Throwable ex) {
breakBarrier();
throw ex;
}
}
nextGeneration();
return 0;
}
这是cyclicBarrier.await()部分源码,可以发现只要index等于0后,那么就会执行创建CyclicBarrier对象时,执行的Runnable的run()方法,即我们的回调函数。
总结一下:CountDownLatch不仅仅可以用于父子之间的同步问题,只要符合一个线程需要其他线程的执行结果,都可以用,同样CyclicBarrier也不仅仅是兄弟之间的同步问题,更加本质的是循环任务,而这个任务又需要依赖其他任务的结果。
分工工具
并发程序中,首先要解决的问题就是分工,将大任务拆分成一个一个的小任务并分配给相应的线程。那么Java也提供了分工工具。分工工具用的最多的就是CompletableFuture,首先我们先来梳理一下任务的类型 任务可以分为
串行任务,并行任务,汇聚任务(一个任务依赖多个任务的执行结果),以及分治任务(大问题拆成小问题,解决算法一样,只是规模在变小)而CompletableFuture支持前三种,由Fork-Join来支持分治任务。我们举个例子,来看看CompletableFuture的基本用法 这个例子比较经典 —— 最优“烧水泡茶”
CompletableFuture Future
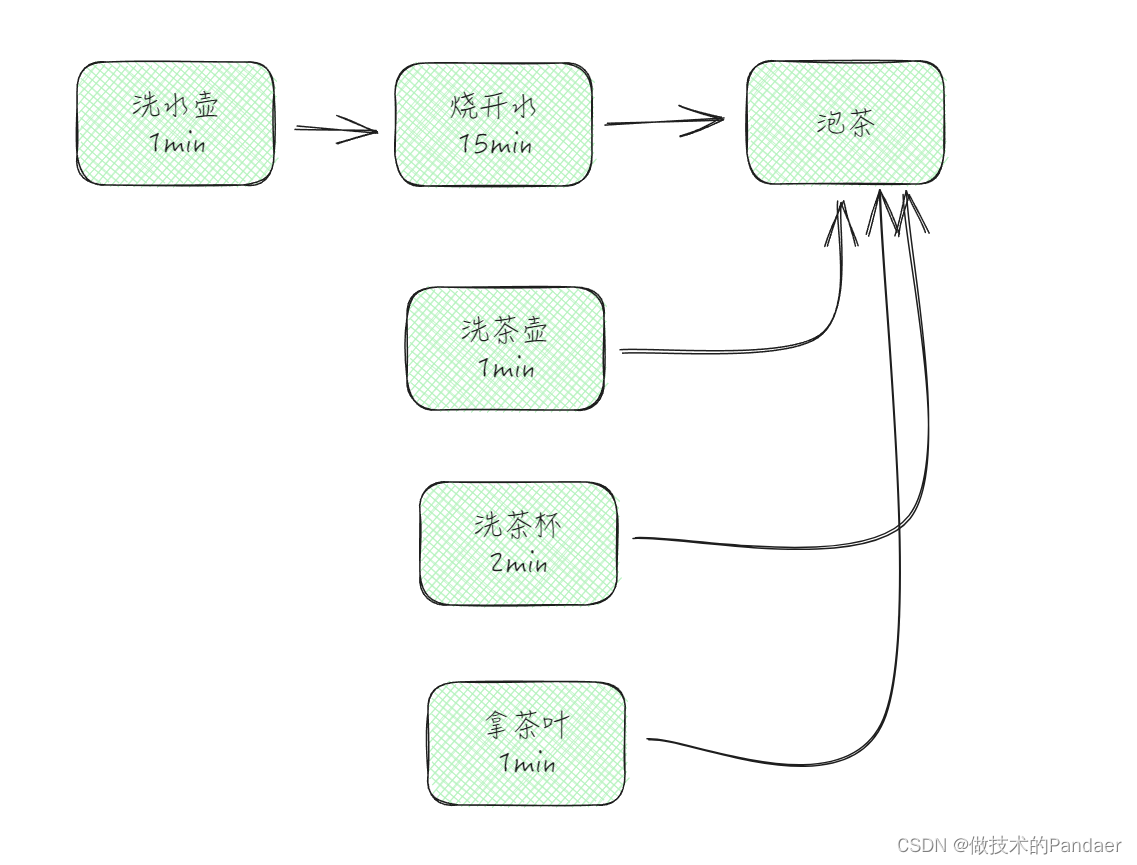
在讲解CompletableFuture之前,我们先看看他的基础版Future,如何实现“烧水泡茶”。
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(5);
long start = System.currentTimeMillis();
Future<String> task1 = executorService.submit(() -> {
//任务1 洗水壶 烧开水
try {
System.out.println("洗水壶...");
TimeUnit.SECONDS.sleep(1);
System.out.println("烧开水...");
TimeUnit.SECONDS.sleep(15);
return "开水";
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
Future<String> task2 = executorService.submit(() -> {
//任务2 洗茶壶
try {
System.out.println("洗茶壶...");
TimeUnit.SECONDS.sleep(1);
return "青铜茶壶";
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
Future<String> task3 = executorService.submit(() -> {
//任务3 洗茶杯
try {
System.out.println("洗茶杯...");
TimeUnit.SECONDS.sleep(2);
return "黄金茶杯 x 9";
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
Future<String> task4 = executorService.submit(() -> {
//任务4 洗茶杯
try {
System.out.println("拿茶叶...");
TimeUnit.SECONDS.sleep(1);
return "绝版龙井";
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
Future<String> task5 = executorService.submit(() -> {
//任务5 泡茶
try {
String water = task1.get();
String teapots = task2.get();
String teacups = task3.get();
String tea = task4.get();
return "pandaer 用 " + water + "在" + teapots + "泡" + tea + "并使用" + teacups + "装茶";
} catch (Exception e) {
throw new RuntimeException(e);
}
});
try {
String res = task5.get();
System.out.println(res + " 耗时:" + (System.currentTimeMillis() - start));
} catch (InterruptedException | ExecutionException e) {
throw new RuntimeException(e);
}
}
Future.get() 函数在结果没有返回时,会阻塞当前线程直到,结果返回。这是利用Future来实现的,接下来我们看看使用CompletableFuture来实现
public class CompletableFutureTest {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(5);
long start = System.currentTimeMillis();
CompletableFuture<String> task1 = CompletableFuture.supplyAsync(() -> {
try {
System.out.println("洗水壶...");
TimeUnit.SECONDS.sleep(1);
System.out.println("烧开水...");
TimeUnit.SECONDS.sleep(15);
return "开水";
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}, executorService);
CompletableFuture<String> task2 = CompletableFuture.supplyAsync(() -> {
try {
System.out.println("洗茶壶...");
TimeUnit.SECONDS.sleep(1);
return "青铜茶壶";
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}, executorService);
CompletableFuture<String> task3 = CompletableFuture.supplyAsync(() -> {
try {
System.out.println("洗茶杯...");
TimeUnit.SECONDS.sleep(2);
return "黄金茶杯 x 9";
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}, executorService);
CompletableFuture<String> task4 = CompletableFuture.supplyAsync(() -> {
try {
System.out.println("拿茶叶...");
TimeUnit.SECONDS.sleep(1);
return "绝版龙井";
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}, executorService);
CompletableFuture<String> task5 = CompletableFuture
.allOf(task1, task2, task3, task4) // 确保所有前置任务完成
.thenApplyAsync(v -> { // 使用thenApplyAsync来处理任务结果
try {
// 从任务中获取结果
String water = task1.get();
String teapots = task2.get();
String teacups = task3.get();
String tea = task4.get();
return "pandaer 用 " + water + "在" + teapots + "泡" + tea + "并使用" + teacups + "装茶";
} catch (Exception e) {
throw new RuntimeException(e);
}
}, executorService);
try {
// 等待最终任务完成并输出结果
String res = task5.get();
System.out.println(res + " 耗时:" + (System.currentTimeMillis() - start));
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
executorService.shutdown(); // 最后别忘了关闭ExecutorService
}
}
}
唯一的不同,就是在最后一步,整合前置任务的时候,用到了CompletableFuture给我们提供的操作符allOf
他能保证task1,task2,task3,task4执行完毕后,才会执行thenApplyAsync中的逻辑。CompletableFuture提供了很多这样的操作符,来简化异步任务的编排。
前面我介绍过,任务与任务之间的关系有两种一种是串行关系,一种是汇聚关系
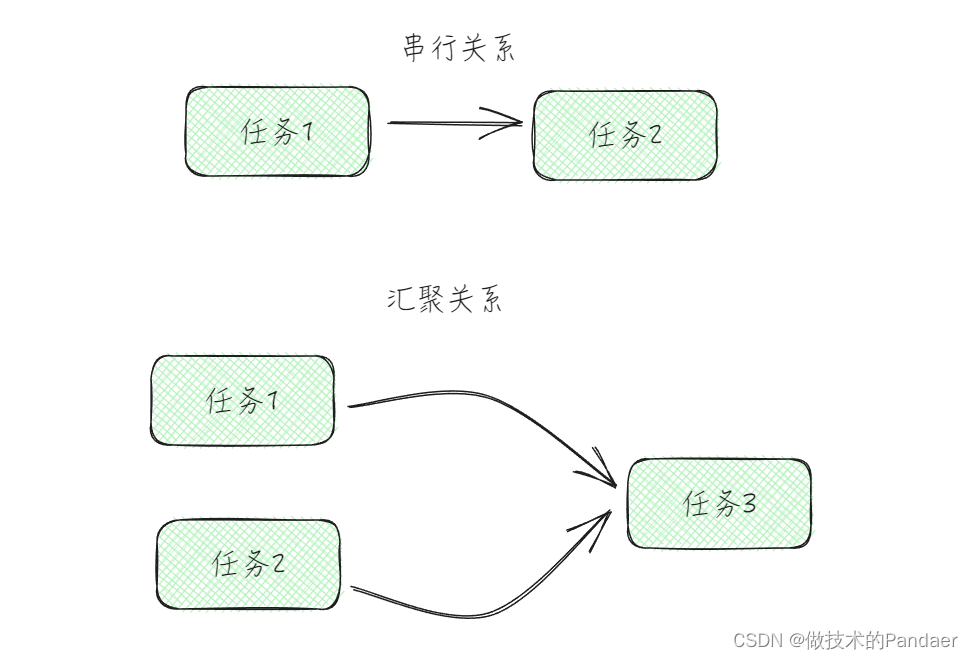
其中汇聚关系分为两种,一种是任务1和任务2同时执行完,才会执行任务3,这种叫做AND聚合任务,还有一种是只要任务1或者任务2完成一个,就执行任务3,这种叫做OR聚合任务,而CompletableFutrue的操作符就可以按照这个来分类
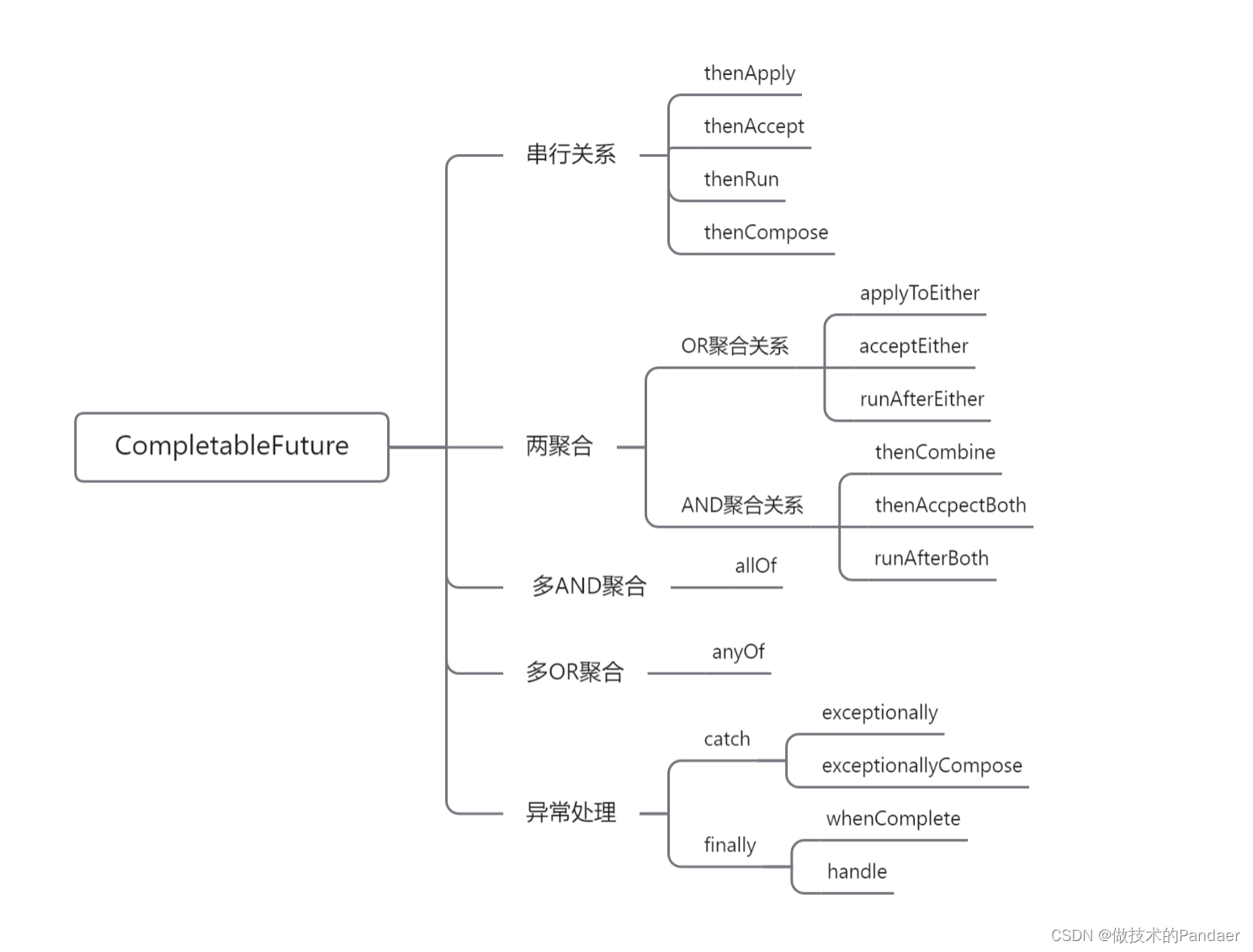
首先我们来思考一个问题,为什么每种关系对应的操作符都有很多,拿串行关系的举例,
public <U> CompletableFuture<U> thenApply(
Function<? super T,? extends U> fn) {
return uniApplyStage(null, fn);
}
public CompletableFuture<Void> thenAccept(Consumer<? super T> action) {
return uniAcceptStage(null, action);
}
public CompletableFuture<Void> thenRun(Runnable action) {
return uniRunStage(null, action);
}
唯一的不同就是方法参数不同,但是Java中支持方法的重载,似乎也没必要取多个方法名吧,其实Java这样设计是为了看到这个函数就清楚这个操作符的特点,比如方法名中存在apply,那么说明这个任务有输入还有输出,要是存在accpect,那么说明这个任务有输入,没有输出,要是存在run就说明这个任务没有输入,也没有输出,这样子看其他API是不是轻松了很多,至于thenCompose这个函数,主要有两个作用,一个作用是用来连接两个异步任务(这个异步任务可能是其他人的),一个作用根据上游的结果动态创建异步任务。
public static void main(String[] args) {
long start = System.currentTimeMillis();
AllCompletableFutureTest test = new AllCompletableFutureTest();
//连接两个异步任务
CompletableFuture<String> future = test.randomNum().thenCompose((num) -> {
return test.display(num);
});
System.out.println(future.join());
long end = System.currentTimeMillis();
System.out.println("测试结束: " + (end - start));
}
//异步任务1
public CompletableFuture<Integer> randomNum() {
return CompletableFuture.supplyAsync(() -> {
return ThreadLocalRandom.current().nextInt(10);
});
}
//异步任务2
public CompletableFuture<String> display(Integer num) {
return CompletableFuture.supplyAsync(() -> {
return num <= 5 ? "小于5的数": "大于5的数";
});
}
至于其他的API,就需要你去试一试效果啦,这里就不过多赘述了。
CompletionService
这个工具的作用时用来批量执行异步任务的,大致的设计思路:由于异步任务的返回结果的时间不确定,所以CompletionService整体的设计是一个生产者-消费者模型 异步任务是生产者,生产执行的结果,CompletionService中的是消费者,消费异步任务的执行的结果
public static void main(String[] args) throws InterruptedException, ExecutionException {
ExecutorService executorService = Executors.newFixedThreadPool(6);
ExecutorCompletionService<String> completionService = new ExecutorCompletionService<>(executorService);
completionService.submit(() -> {
System.out.println("你好呀");
TimeUnit.SECONDS.sleep(1);
return "hello";
});
completionService.submit(() -> {
System.out.println("hello,world");
TimeUnit.SECONDS.sleep(3);
return "world";
});
for (int i = 0; i < 2; i++) {
long start = System.currentTimeMillis();
System.out.println(completionService.take().get());
long end = System.currentTimeMillis();
System.out.println(end - start);
}
executorService.shutdown();
}
Fork-Join
Fork-Join是专门处理分治任务的,什么是分治任务?分治任务就是:一个大任务可以拆分成小任务,小任务还可以继续拆分,知道拆分的任务足够简单为止,而且这些任务之间用的算法都是同一套,唯一的区别就是任务的规模不一样。这类任务就被称为分治任务。为了让分治任务并行化,Fork-Join计算框架就诞生了,在Java中具体的实现是ForkJoinPool 以及 ForkJoinTask 其中ForkJoinTask有两个子类,RecursiveAction ,RecursiveTask。我们通过一个例子,来学习一下Fork-Join。这个例子我们都很熟悉,斐波拉契数
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
Fibonacci fibonacci = new Fibonacci(10);
Integer res = forkJoinPool.invoke(fibonacci);
System.out.println(res);
}
static class Fibonacci extends RecursiveTask<Integer> {
private int n;
public Fibonacci(int n) {
this.n = n;
}
@Override
protected Integer compute() {
if (n <= 1) {
return n;
}
Fibonacci f1 = new Fibonacci(n - 1);
f1.fork(); //1
Fibonacci f2 = new Fibonacci(n - 2);
return f2.compute() + f1.join(); //2
}
}
注释1,就会将任务f1,作为另外一个任务执行,提交到forkJoinPool的任务队列中,注释2,在本线程计算任务2,在另外一个线程计算f1, 有一个问题,为什么f2不fork,答案是提升节约资源,如果两个都fork的话,那么就会有这样一个任务,等待f2的结果,等待f1的结果,然后自己唯一的计算只是一个加法操作,大量的时间都在等待,极其不尊重CPU,如果只fork一个话,那么在等待的同时,自己也可以做计算。














 5233
5233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









