







在视觉世界,计算机不仅需要识别出单个目标实例,同时还要识别出他们之间是如何交互的。人类往往是这种交互的核心,并且检测人物交互是一个重要的实践问题与科学问题,本文中,解决了具有挑战性的日常照片的<人,动作,物体>三元组的检测任务。提出了一个以人为中心的模型。假设一个人的外貌(姿势,着装,动作)是用于定位他们交互的对象的非常有效的线索,为了利用这种线索,模型学习根据被检测的人的外貌去预测目标物体位置的作用与密度。该模型可以联合学习来检测人类和物体,通过将这些预测融合起来,它能够在一个干净,联合训练的端到端系统中高效的推断出交互三元组。该模型称为InteractNet。
论文地址:https://arxiv.org/pdf/1704.07333.pdf
研究背景
单个实例的视觉识别(如目标检测,姿态估计)由于深度学习的发展取得了显著的进步。然而识别出单个的目标仅仅是理解视觉世界的第一步,为了理解图像中发生了什么,也必须要识别出这些单个实例之间的关系。人物交互的识别任务可能被表示为检测<人,动作,物体>三元组。该问题的研究对于实践和研究都非常有用,从实践的角度而言,包含人类的照片在互联网和社交网络中的日常上传中占据很大的比例,因此以人为中心理解在实践中具有很大的需求,人们能够产生很多的动作,绝大多数很少运用其他物体(如谈话,工作等)。与识别普通的对象类别相比,人类动作的精细度以及与大量物体的类型的交互带来了一个新的挑战。
相关工作
(1)目标检测
基于边界框的目标检测不断进步,R-CNN是一个两阶段的方法,第一阶段提出候选ROI,第二阶段进行目标分类,通过RoI池化能得到一个共享的特征图,能够快速提取区域特征。特征共享加速了实例级的检测同时能够识别更高阶的交互,本文中基于fast/faster R-CNN实现。
(2)人体动作和姿态识别
人的动作和姿势表示其与场景中的物体或其他人的交互,目前对图像中人体的动作和姿态理解已经取得很大进展,但这些方法只关注于人体实例,而不会对其于其他物体的交互进行预测,我们利用这些动作和姿势外观线索来对场景中于其他物体的交互进行预测。
(3)视觉关系
有研究利用来自开放世界词汇来识别视觉关系,这种视觉关系包含动词(穿),空间(靠近),动作(骑),或介词短语。本文与其相似,但是本文是为了理解以人为中心的交互,它以特别多样、有趣的方式发生,这种关系包含与物体直接交互(不需要空间,介词短语)。其目标是建立一个能够高精度识别图像中的交互的检测器,它来自于实际应用中的需求,但是对于开放世界识别设置中,对精度的评估并不可行,只能依靠基于召回的评估。
(4)人-物交互
人物交互于视觉关系相关,但是却有着不同的挑战,因为人的动作相比普通的目标更加精细(如走路,跑步,滑雪等),并且一个人可以同时进行多种动作(坐在椅子上一边喝茶一边看报)。这些问题需要对人的动作以及他周围的物体以更加丰富的方式进行深入的理解,而不仅仅是图像种人的周围有物体的存在,对人物交互的精确识别能够帮助计算机视觉很多任务的研究(图像检测,字幕生成,问答)。
研究内容
本文提出了一个以人为中心的人物交互识别模型,关注的核心是人体的外观(动作与姿势,衣着),这对于推断出交互的目标物体位于何处非常有用,通过这种估计的调节能够缩小目标物体的搜索空间,尽管通常会检测到很多物体,被推断出的目标位置能够帮助模型快速的找到与动作相关的物体。

使用faster R-CNN实现以人为中心的识别分支,特别是在与人有关的ROI中,这个分支对动作的目标物体位置进行动作分类与密度估计,对于每种动作,密度估计器会预测一个4维的高斯分布来模拟人与目标物体可能存在的相对位置,这种预测仅仅是基于人的外观,这种以人为中心的识别分支,以及一个标准的目标检测分支,一个简单的成对交互分支,形成了一个能联合优化的多任务学习系统。该方法在V-COCO上实现了 40.0AP,在HICO-DET上获得了27%的改进,这种改进主要基于人的外观中推断出目标物体的相对位置。

研究方法
本文目标是检测出<人,动作,物体>三元组,为了检测出该三元组,需要对人类的边界框和与他进行交互的物体的边界框进行精确的定位,我们分别表示为bh,bo,并且识别出他们的交互动作。我们的方法将这个复杂的多方面的问题分解为简单可管理的形式,我们使用fast R-CNN框架,并使用一个以人为中心的分支对动作进行分类并对估计每个动作在目标物体的位置的概率密度。该分支融合了通过目标检测的Fast R-CNN提取的特征,因此其边缘计算是轻量的。
当给出一组候选框,fast R-CNN 会输出一组目标框并且每个目标框都带有一个分类标签,我们的模型将三元组分数sh,oa分解为成对的人/物候选框bh,bo,以及一个行为a ,将其表示为如下所示:
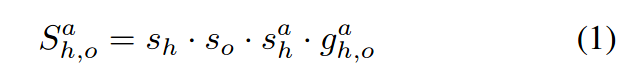
sh,so分别表示通过fast R-CNN 得到的bh,bo包含人与物体的分类分数。以人为中心分支输出为两项,第一个sha表示人在物体边界框bh处关于动作类别a得到的分数,uha是对于给出的人/动作对基于人的外观计算出的的交互物体的预测位置,其被用于计算gh,oa,描述边界框bo对应的物体成为实际交互物体的可能性。

1. 模型组件
(1)目标检测
目标检测分支与faster R-CNN是相同的,首先使用RPN网络产生目标建议框,然后使用RoilAlign提取每个建议框的特征,然后通过目标分类和边界框回归获得一组新的边界框,每一个边界框都有一个相关的分数so(对于与人相关的分数为sh),这些建议框仅在推理阶段使用用,在训练阶段,所有的分支都是使用的RPN的建议框进行训练。
(2)动作分类
- 以人为中心的分支的第一个作用是为每一个人类边界框bh和一个动作a分配一个分类分数sha。
与目标分类分支一样,我们从bh使用RoiAlign提取特征,并为每个动作类别a预测一个分数,因为一个人可以同时进行多种动作,输出层由用于多标签动作分类的二值sigmoid分类器组成,训练的目标是使真实的动作标签和模型预测的分数sha之间的二值交叉熵损失最小。 - 以人为中心的分支的第二个作用是基于一个人的外观(也可使用通过bh池化得到的特征)预测目标对象的位置。
然而仅仅依靠从bh获得的特征要实现对目标对象的位置的精确预测具有很大的挑战,因此需要对可能的位置预测一个密度,并将此输出与实际被检测对象一起用于对目标物体精准定位。我们将目标物体位置的密度建模为高斯函数,其均值是根据人体外观与动作进行预测的。最后以人为中心的分支预测uha(给出的人物框bh与动作a的目标对象的4维平均位置),然后其目标位置为:
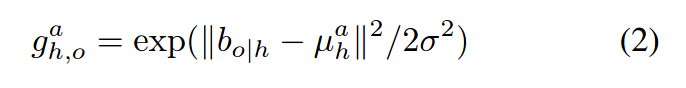
g可以检测物体框bo与预测的目标位置uha的兼容性,bo/h表示bo相对于坐标bh的的编码:
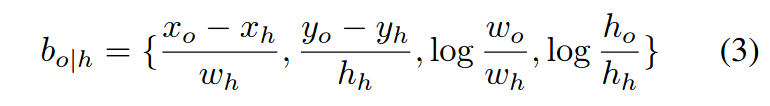
训练的目标就是使uha与bo/h之间的平滑L1损失最小化,bo表示真正交互的目标的位置,将σ设置为超参数,在验证集上,根据经验将其设置为0.3。如以下图表示对例中的人/动作交互的物体的位置分布图,一个携带的外观意味着物体在人的手中,一个扔的外观意味着物体在人的前面,一个坐的外观认为物体位于人的下面,图中的黄色虚线框(uha)仅仅是根据bh和a推断出来的,并不知道物体的真实信息。
直观的说,我们的公式是基于从bh计算出来的特征包含指向动作目标的强信号(甚至该目标对象在bh外面)这种假设预测出来的,我们认为这种“边界框之外”的回归是可能的,因为人体的外观对于物体的位置提供了很强的索引,并且这种预测是针对特定动作与特定实例的,尽管我们使用uni-model分布对目标位置建模但我们的公式仍然有效。

(3)交互识别
我们的以人为中心的模型基于人体的外观对动作进行评分,为了提高模型的辨别能力以及显示出框架的灵活性,将sha替换为基于人和物体的外观对一个动作进行评分的交互分支,使用sh,oa来表示。对于sh,oa的计算需要使用sha进行计算,同时与通过bo提取的特征并行执行相似的计算,通过这两个动作分类头得到的输出就是一个A-维的逻辑向量,将其进行求和(2个分类头)然后经过sigmoid函数产生A个分数(A 表示动作的总类数目),其训练目标是使真实的动作标签与预测的动作分数sh,oa之间的二值交叉熵损失最小。
2. 多任务训练
我们将人物交互看作一个多任务学习问题,该模型包含三个分支进行联合训练,最终的损失为模型中所有的损失之和,包含:
- 用于目标检测分支的分类和回归损失
- 以人为中心分支的动作分类和目标定位损失
- 交互分支的动作分类损失。
目标检测分支的输出就是以人为中心的分支输入。我们的训练是基于图像进行计算,其损失是通过RPN建议框和真实的目标框进行计算的,对于目标检测分支,最多从每个图像中采样64个框,正负比例为1:3,以人为中心的分支最多在16个与被检测的人有关的边界框bh上计算(即与真实的人类的边界框的IOU>=0.5),交互分支的损失只在正例三元组上计算,所有损失的权重都为1(除开在以人为中心分支上的动作分类项的权重为2)
3. 级联测试
- 目标检测分支:首先检测图像中所有的目标,然后使用非极大值抑制,使得分高于0.05的边界框的IOU阈值为0.3,这个步骤会产生一组新的具有n个分数为sh,so的边框集合,这些新的边框被用于剩下两个分支的输入。
- 以人为中心分支:接下来我们将以人为中心的分支应用于所有被检测的并分类为人的目标,对于每个动作a于被检测的人体边界框bh,我们会计算sha(分配给动作a 的分数)以及uha(预测的与bh相关的目标对象的位置的平均偏差),这一步的计算复杂度为O(n)。
- 交互分支:如果使用可选择的交互分支,必须计算每个动作a与人/物边界框对(bh,bo)的分数sh,oa,首先分别计算每个边界框bh,bo的动作分类头的逻辑值,其复杂度为O(n),然后将这两个逻辑值加起来并送入到sigmoid中得到sh,oa,这一步的计算复杂度为O(n2)。最后不是对所有的三元组计算得分,而是找到sh,oa最大的目标框进行计算:
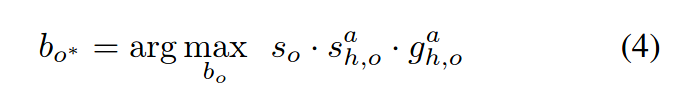
该公式是为了优先选择高分动作所预测的目标对象的位置周围的具有高置信度的物体,三元组为 <human, verb, object> =< bh, a,bo>,这些三元组以及分数sh,oa就是我们模型的最终输出,对于不与其他物体进行交互的动作,用sha而不使用sh,oa,且表示为<human, verb>分数为sh*sha。
数据集和评估方式
使用V-COCO 和HICO -DET 两个人物交互的基准数据集,来测试该方法的有效性与分析各个组件。V -COCO是COCO 的一个子集,在训练验证集上有5k张图片,在测试集上也约有5k张图片,包含8k个人物实例,平均每个人有2.9个动作,他的标注为26个动作类别。对于像(cut、hit、eat)会根据目标标注成两种类型,连接器具时与直接连接物体时(比如cut连接刀时,就表示用刀切,当cut连接蛋糕时,就表示切蛋糕),在评估时,对这两种类型分别评估,并且对这三种动作训练了6种目标估计。
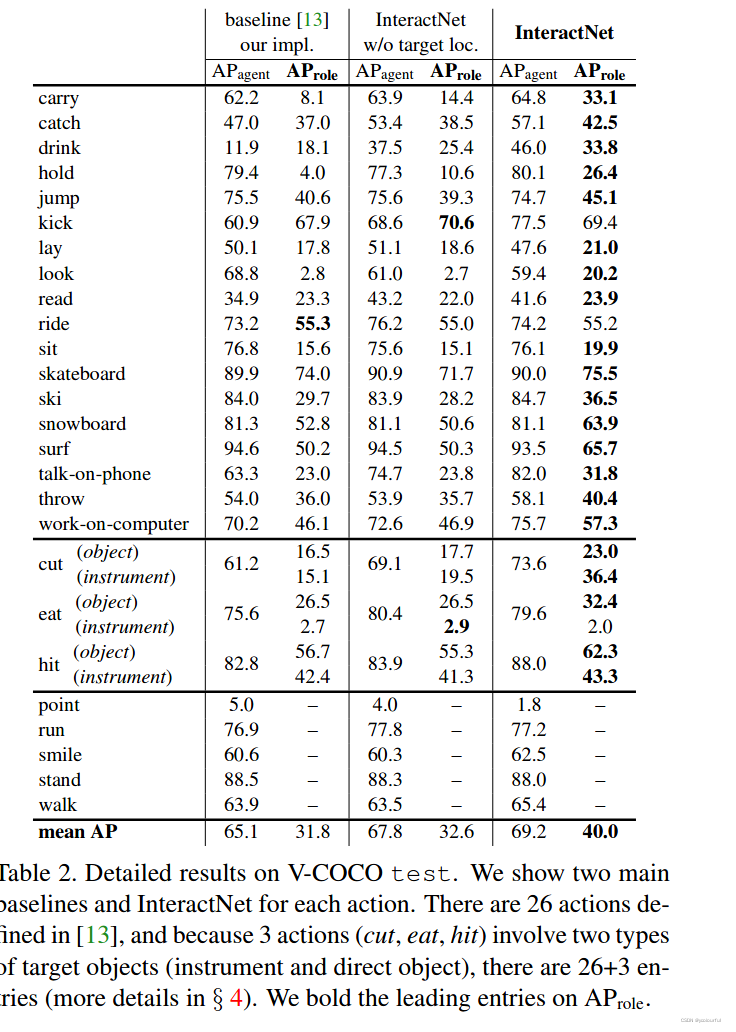 评估了两种精度指标,因为这是针对检测人物,所有都需要考虑召回率与精度。人物交互中的核心AP 就是三元组<human,verb,object>的AP,称为role AP(AP role)并且一个三元组如果是正阳性需要满足以下几个条件:
评估了两种精度指标,因为这是针对检测人物,所有都需要考虑召回率与精度。人物交互中的核心AP 就是三元组<human,verb,object>的AP,称为role AP(AP role)并且一个三元组如果是正阳性需要满足以下几个条件:
(1)预测的人物边界框bh与真实的人物边界框的IoU必须大于等于0.5
(2)预测的物体边界框bo与真实的物体边界框的IoU必须大于等于0.5
(3)预测的动作与真实的动作是一致的。
这种度量方式仅仅考虑到了目标对象的边界框的位置,并为考虑目标对象类别的正确性。
当交互没有对象时,对<human,verb>使用agent AP(APagent)来评估,假如为正阳性需要满足以下条件(不需要考虑对于物体的定位):
(1)预测的人物边界框bh与真实的人物边界框的IoU必须大于等于0.5
(2)预测的动作与真实的动作是一致的
实验
本实验基于带有FPN 的faster R-CNN实现的,主干使用的是ResNet-50,对faster R-CNN的RPN 进行训练,为了方便消融实验,将RPN 冻结住,与我们的网络不共享特征。使用RoiAlign从区域中提取7×7的特征,对于每个分支由两个1024维的全连接层(RELU )组成,后接每种输出类型的特定输出层。
给出一个在ImageNet上预训练的模型,首先在COCO的训练集(V-COCO的验证集)上训练目标检测分支,该模型在COCO的验证集上有33.8的目标检测精度。在V-COCO的验证集上建立人物交互模型,在V-COCO的验证集上进行超参数的选择,对超参数的调整之后,在V-COCO的训练验证集上训练,基于V-COCO的测试集报告结果。在V-COCO训练验证集上的10k次迭代的学习了为0.001,另外3k次迭代的学习率为0.001。权重衰减为0.001动量为0.9,在8个GPU 上使用SGD。当使用不同的主干网络进行实验,得到的结果,结果证明当使用ResNet-50-FPN时得到的效果最好。

能够检测交互三元组,并且还能检测交互物体位于人物边界框之外的交互行为,并将该物体与人物和动作联系起来。
 能够检测一个人与多个物体进行多种不同的交互,
能够检测一个人与多个物体进行多种不同的交互,
 检测一张图片中多个人物实例与不同的物体发生不同的交互
检测一张图片中多个人物实例与不同的物体发生不同的交互
 消融实验
消融实验
(1)有无目标定位

(2)是否使用FPN

(3)是否使用MPL

(4)在HICO-DET数据集上评估

结论
本文提出了InteractNet网络,该网络由3个分支组成,首先经过目标检测分支提取目标(包含人与物),再通过以人为中心的分支根据人的外观以及动作找到对应物体可能的位置,最后通过交互识别分使用从人的边界框和物体的边界框提取特征找到对应人物发生的交互动作。该方法在V-COCO 的精度AProle达到了40%。














 888
888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









