






基本假设:
页面都从缓冲池获取
不考虑重复key(面试中可能问:重复的key怎么实现)
节点布局为kv键值对
锁的粒度为页级,且是缓冲池的页,不是B+树的页
b_plus_index
b_plus_leaf_page
b_plus_internal_page
b_plus_index 依赖于b_plus_leaf_page b_plus_internal_page 实现
m阶的B+树,根节点及中间结点和叶子结点均最多只有m-1个元素,最多有m个子树。最少有 ceil(m/2) - 1个元素(ceil向上取整-)。
叶子与非叶子的区别:
1.叶子多一个next_page_id
2.第一个kv:非叶子的第一个key为invalid,而叶子正常存
3.半满和非半满:为了保证B+树的分裂次数比较少,把B+树维护在一个半满的状态,这样不管做插入或删除,在半满的状态都比较有利。半满状态:叶子为n/2向下取整,非叶子为n/2 向上取整。
叶子查找:(二分查找)
1.从下标0开始
2.只有相等或不存在
非叶子查找:
1.从下标为1开始
2.有相等,大于,小于三种情况。
查找并发:
全加读锁,先拿锁后解锁(从根节点出发,先给根节点加读锁,往子节点走,拿到子节点页面的锁再把上一页面的锁释放)
释放页面时记得unpin
查找伪码:
B+树的插入
参考:https://www.javatpoint.com/b-plus-tree
按照国外的B+树的规定:
step1:找到元素属于的叶结点,插入新元素。(注意:是从根结点一层一层往下查找,直到其所属的叶子结点再插入新元素)
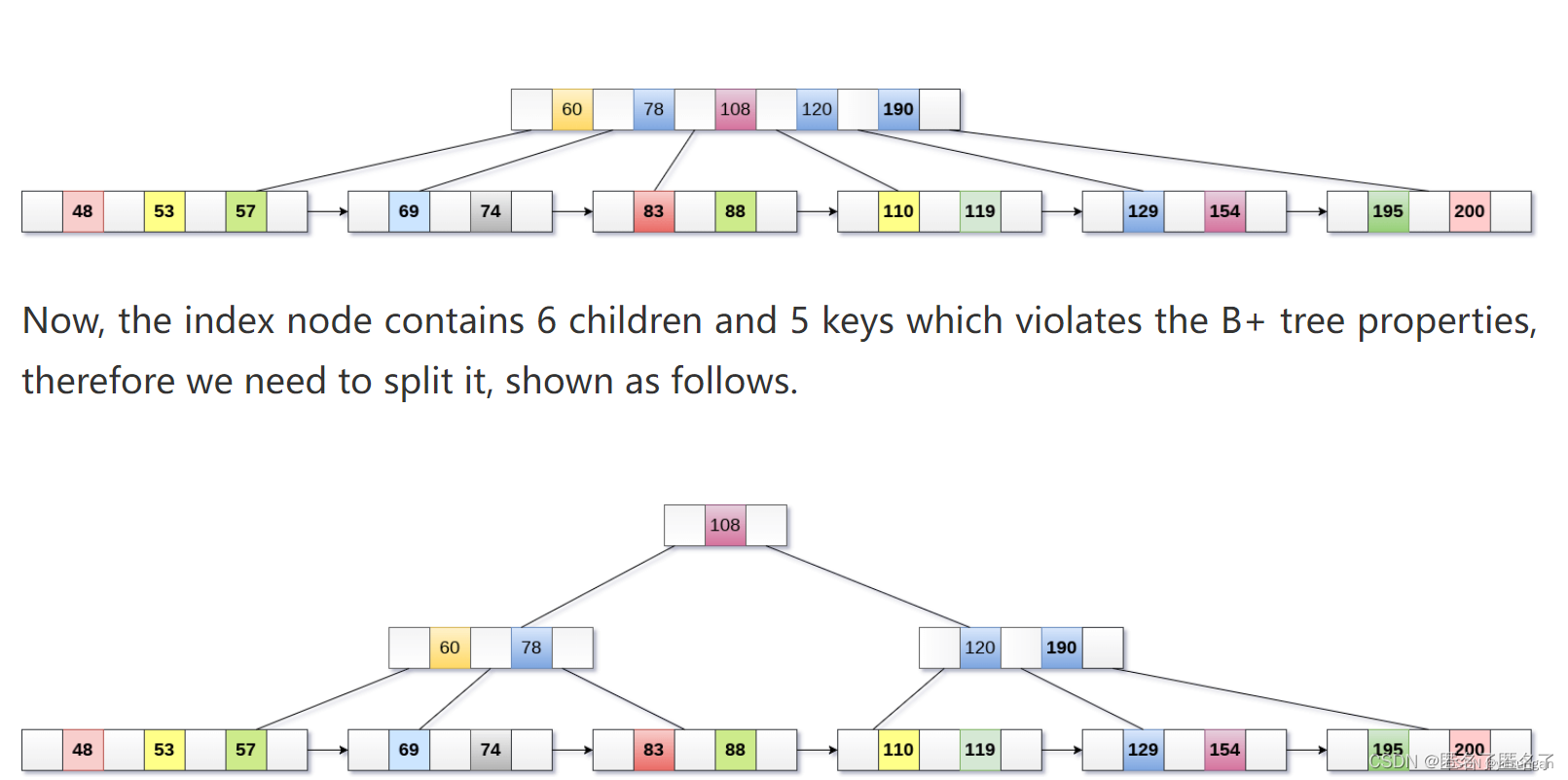
step2:如果叶子结点空间不满足了,如5阶的B+树中的叶子结点有5个元素,那么将分裂叶子结点,将叶子结点的中间元素向上提到父结点。
step3:如果一个中间结点空间不满足了,分裂结点,将里面的中间元素向上提到父结点。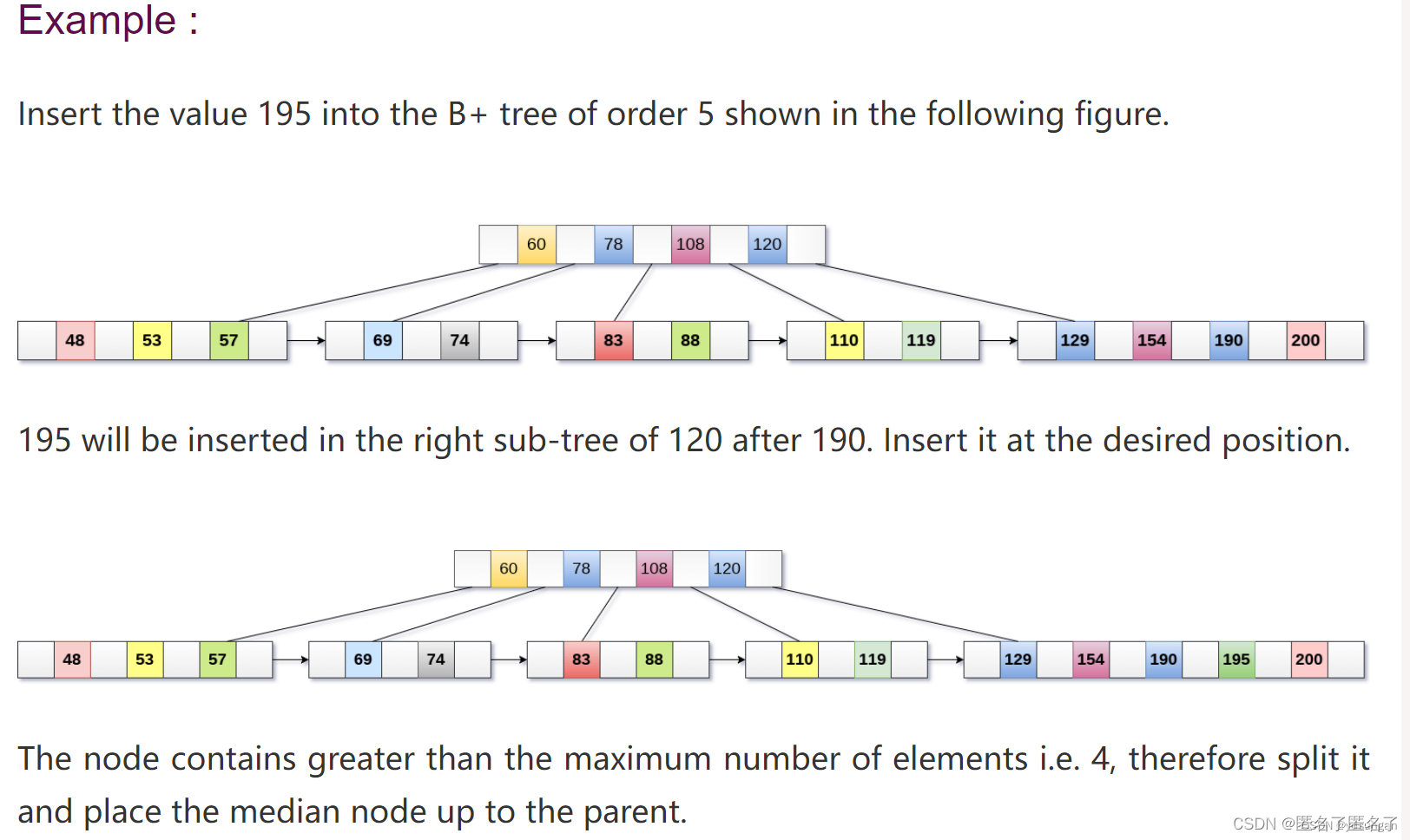
插入伪码:

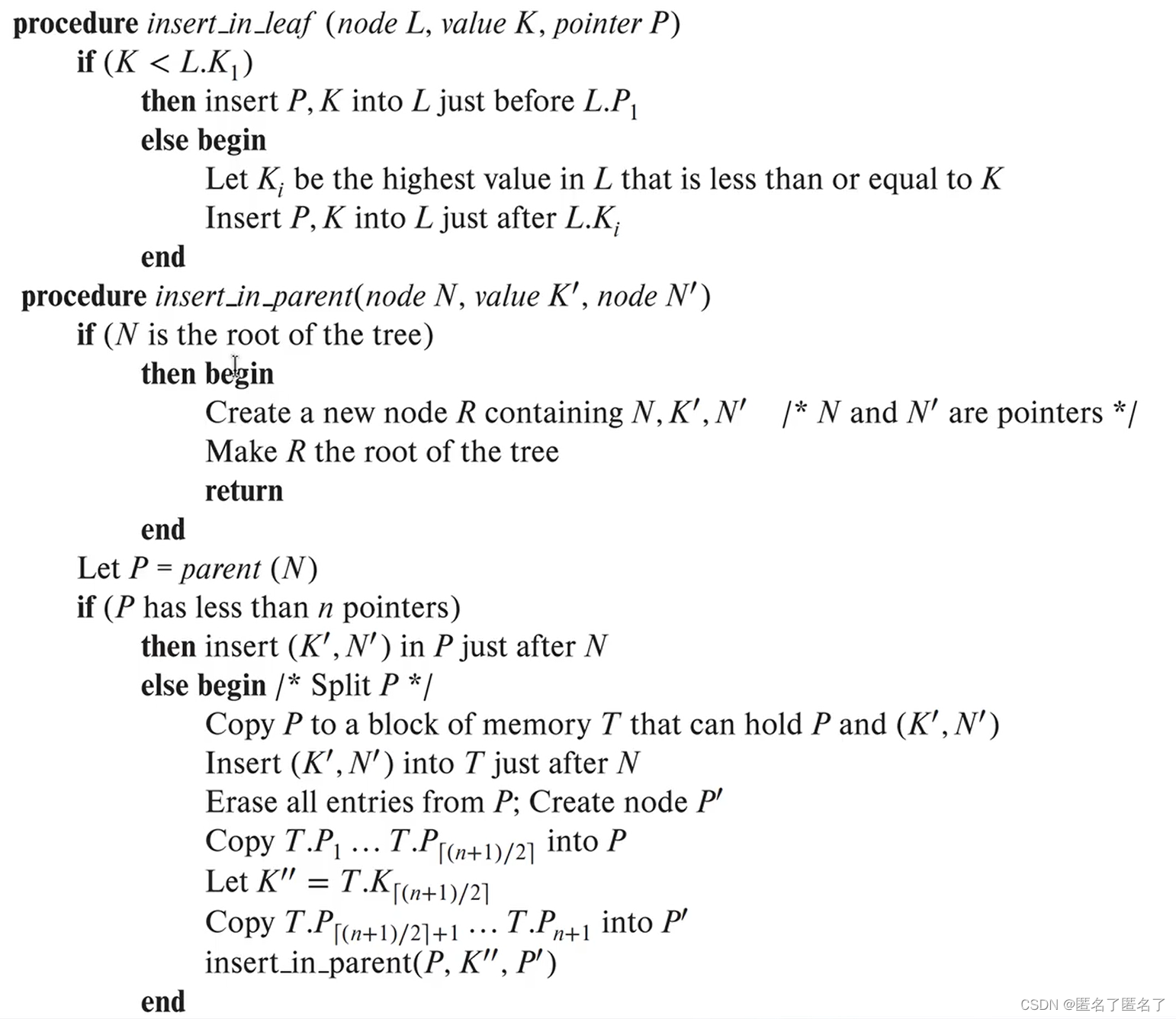
B+树的并发控制机制
基础的并发机制:它采用了两种粒度的锁:
(1)index粒度的S/X锁;
(2)page粒度的S/X锁(本文等同于树节点粒度)。
前者被用来控制对树结构访问及修改操作的冲突,后者被用来控制对数据页访问及修改操作的冲突。
iindex粒度的S/X锁
读操作在访问树结构的过程中对B+树加的是S锁,所以其它读操作可以并行访问树结构,减少了读-读操作之间的并发冲突。因为写操作可能会修改整个树结构,所以需要避免两个写操作同时访问B+树。悲观写操作通过索引粒度的互斥锁避免这个问题。但悲观写操作在访问树结构的过程中对B+树加的是X锁,所以它会堵塞其它的读/写操作,这在高并发场景下会导致糟糕的多线程扩展性。
因为每一个树节点页可以容纳大量的键值对信息,所以B+树的写操作在多数情况下并不会触发split/merge等修改树结构的操作。乐观思想假设大部分写操作并不会修改树结构。在访问树结构过程中持有树结构的S锁,从而支持其它读/乐观写操作同时访问树结构,而写操作对叶节点持有X锁。
B+树往往优先执行乐观写操作,只有乐观写操作失败才会执行悲观写操作,从而减少了操作之间的冲突和堵塞。不管是悲观写操作还是乐观写操作,它都通过索引粒度或者页粒度的锁避免相互之间修改相同的数据。
即使其它读写操作访问的是树结构的不同分支,在实际执行过程中不会产生相互间的影响,但是悲观写操作依然会堵塞其它所有读/写操作,直到树结构修改完成,这导致了过高的堵塞开销。
考虑只锁住B+树中被修改的分支,而不是锁住整个树结构?
page粒度的S/X锁
树节点粒度的S/X锁:只对修改的分支加锁。读操作在持有子节点的锁后才释放父节点的锁。
读操作先获得子节点的S锁,再释放父节点的S锁,这个过程反复执行直到找到某个叶节点。因为读操作在持有子节点的锁后才释放父节点的锁,所以不会读到一个正在修改的树节点,不会在定位到某个子节点后子节点的键值对被移动到其它节点。
往往采用自顶向下的加锁策略,在安全地获取到子节点的锁后释放父节点的锁。然而我们很容易发现,这种加锁方式依然是十分悲观的:大部分获取到的锁其实是无意义的,尤其在树的上层,因为离根节点越近的树节点被更新的概率越低。因此,如果存在一种自底向上加锁的策略,只有在树节点分裂或者合并或者删除的情况下向上加锁,只对被修改的树节点加锁,就可以在很大程度上减少加锁的范围和频率,从而提高B+树的多线程扩展性。















 1729
1729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









