






损失函数
Softmax函数
如果模型能输出10个标签的概率,对应真实标签的概率输出尽可能接近100%,而其他标签的概率输出尽可能接近0%,且所有输出概率之和为1。这是一种更合理的假设!与此对应,真实的标签值可以转变成一个10维度的one-hot向量,在对应数字的位置上为1,其余位置为0,比如标签“6”可以转变成[0,0,0,0,0,0,1,0,0,0]。
为了实现上述思路,需要引入Softmax函数,它可以将原始输出转变成对应标签的概率。
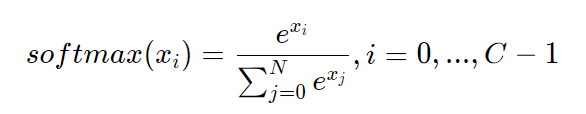
从公式的形式可见,每个输出的范围均在0~1之间,且所有输出之和等于1,这是这种变换后可被解释成概率的基本前提。对应到代码上,需要在前向计算中,对全连接网络的输出层增加一个Softmax运算,outputs = F.softmax(outputs)。
下图是一个三个标签的分类模型(三分类)使用的Softmax输出层,从中可见原始输出的三个数字3、1、-3,经过Softmax层后转变成加和为1的三个概率值0.88、0.12、0。
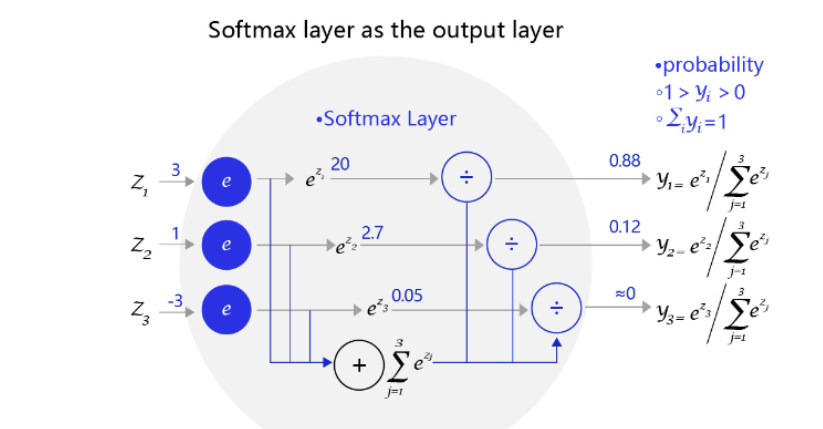
在二分类问题中,Sigmoid函数等价于Softmax函数
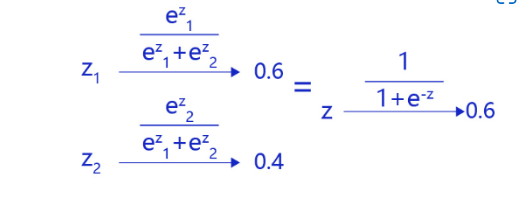
交叉熵
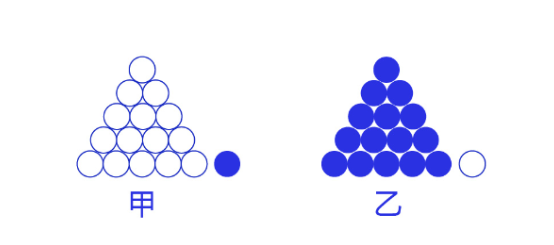
交叉熵损失函数的设计是基于最大似然思想:最大概率得到观察结果的假设是真的。如何理解呢?举个例子来说,如 图7 所示。有两个外形相同的盒子,甲盒中有99个白球,1个蓝球;乙盒中有99个蓝球,1个白球。一次试验取出了一个蓝球,请问这个球应该是从哪个盒子中取出的?
贝叶斯公式解决:
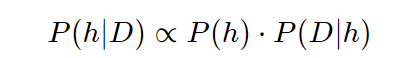
从乙盒中取出一个蓝球的概率更高(P(D∣h))(P(D|h))(P(D∣h)),所以观察到一个蓝球更可能是从乙盒中取出的(P(h∣D))(P(h|D))(P(h∣D))。
依据贝叶斯公式,某二分类模型“生成”n个训练样本的概率:
P
(
x
1
)
⋅
S
(
w
T
x
1
)
⋅
P
(
x
2
)
⋅
(
1
−
S
(
w
T
x
2
)
)
⋅
.
.
.
⋅
P
(
x
n
)
⋅
S
(
w
T
x
n
)
P(x_1)·S(w^Tx_1)·P(x_2)·(1-S(w^Tx_2))·...·P(x_n)·S(w^Tx_n)
P(x1)⋅S(wTx1)⋅P(x2)⋅(1−S(wTx2))⋅...⋅P(xn)⋅S(wTxn)
经过公式推导,使得上述概率最大等价于最小化交叉熵,得到交叉熵的损失函数。交叉熵的公式如下:
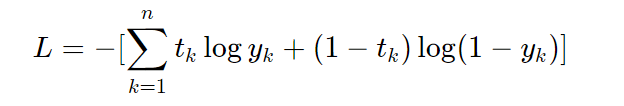
其中,log表示以e为底数的自然对数。yk代表模型输出,tk代表各个标签。tk中只有正确解的标签为1,其余均为0(one-hot表示)。
因此,交叉熵只计算对应着“正确解”标签的输出的自然对数。比如,假设正确标签的索引是“2”,与之对应的神经网络的输出是0.6,则交叉熵误差是−log0.6=0.51;若“2”对应的输出是0.1,则交叉熵误差为−log0.1=2.30。由此可见,交叉熵误差的值是由正确标签所对应的输出结果决定的。
交叉熵代码实现
在手写数字识别任务中,仅改动三行代码,就可以将在现有模型的损失函数替换成交叉熵(Cross_entropy)。
- 在读取数据部分,将标签的类型设置成int,体现它是一个标签而不是实数值(飞桨框架默认将标签处理成int64)。
- 在网络定义部分,将输出层改成“输出十个标签的概率”的模式。
- 在训练过程部分,将损失函数从均方误差换成交叉熵。
在数据处理部分,需要修改标签变量Label的格式,代码如下所示。
# 改前
label = np.reshape(labels[i], [1]).astype('float32')
# 改后
label = np.reshape(labels[i], [1]).astype('int64')
在网络定义部分,需要修改输出层结构,代码如下所示。
# 改前
self.fc = Linear(in_features=980, out_features=1)
# 改后
self.fc = Linear(in_features=980, out_features=10)
修改计算损失的函数,从均方误差(常用于回归问题)到交叉熵误差(常用于分类问题),代码如下所示。
# 改前
loss = paddle.nn.functional.square_error_cost(predict, label)
# 改后
loss = paddle.nn.functional.cross_entropy(predict, label)
由于量纲不同,无法从loss的值判断两个算法的好坏,所以要统一量纲,引入准确率,以下是准确率的计算。
def evaluation(model, datasets):
model.eval()
acc_set = list()
for batch_id, data in enumerate(datasets()):
images, labels = data
images = paddle.to_tensor(images)
labels = paddle.to_tensor(labels)
pred = model(images) # 获取预测值
acc = paddle.metric.accuracy(input=pred, label=labels)
acc_set.extend(acc.numpy())
# #计算多个batch的准确率
acc_val_mean = np.array(acc_set).mean()
return acc_val_mean
训练了10个epoc的准确率
















 1214
1214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











