






仅作练习,侵权联系删除
代码
7页视频信息.py
获取前7页的视频信息
import json
import os
import re
import time
import requests
from DrissionPage import ChromiumPage
# 打开浏览器,手动登录账号,取cookie
def get_ck():
page = ChromiumPage()
page.get("https://www.xinpianchang.com/discover/article-27-180-all-all-0-0-score-pp4")
time.sleep(10)
cookies = page.cookies()
cookies = ', '.join([f"\'{cookie['name']}\':\'{cookie['value']}\'" for cookie in cookies])
cookies = json.dumps(cookies)
# 使用正则表达式提取键值对
pattern = re.compile(r"'([^']+)':'([^']+)'")
matches = pattern.findall(cookies)
# 转换为字典
cookies = {key: value for key, value in matches}
print('cookies', cookies)
return cookies
cookies = get_ck()
for i in range(1, 8):
headers = {
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9',
# Requests sorts cookies= alphabetically
# 'cookie': 'Device_ID=8ot5e2cg6lzl4q2m6; Authorization=B1B9682CB8F69EB9FB8F694F80B8F69AEB6B8F69D97762B2E237; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2214882668%22%2C%22first_id%22%3A%221913182f98f36b-041ddc99b17b4a-26001e51-2359296-1913182f990612%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%7D%2C%22%24device_id%22%3A%221913182f98f36b-041ddc99b17b4a-26001e51-2359296-1913182f990612%22%7D; sl-session=yKGIM3WUwGY5O8voLLclMQ==; Hm_lvt_446567e1546b322b726d54ed9b5ad346=1723115438,1723115460,1723120731,1723810557; HMACCOUNT=3C402195F4DFF3E8; Hm_lpvt_446567e1546b322b726d54ed9b5ad346=1723810955',
'if-none-match': 'W/"7iqcws87zm3vnu"',
'priority': 'u=1, i',
'referer': 'https://www.xinpianchang.com/discover/article-27-180-all-all-0-0-score-pp4',
'sec-ch-ua': '"Not)A;Brand";v="99", "Google Chrome";v="127", "Chromium";v="127"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36',
'x-nextjs-data': '1',
'x-user-hash': '14882668:4074873819',
}
params = {
'param': f'27-180-all-all-0-0-score-pp{i}',
}
if i == 1:
response = requests.get(
f'https://www.xinpianchang.com/_next/data/gJx7P4y6Bi_PvEysygeJE/discover/article/27-180.json',
params=params, cookies=cookies, headers=headers)
# print(response.json())
else:
response = requests.get(
# data/xxxxxxxxxxxxxxxx/discover,中间的xxxxxx从网页上抓包,找链接,会变,仅修改中间位置就行
f'https://www.xinpianchang.com/_next/data/gJx7P4y6Bi_PvEysygeJE/discover/article/27-180-all-all-0-0-score-pp{i}.json',
params=params, cookies=cookies, headers=headers)
print(response)
print(response.json())
lists = response.json()['pageProps']['discoverArticleData']['list']
for list in lists:
title = list['title']
print(title)
cate = []
categories = list['categories']
for category in categories:
category_name1 = category['category_name']
cate.append(category_name1)
category_name2 = category['sub']['category_name']
cate.append(category_name2)
print(cate)
url = list['web_url']
print(url)
# 创建一个字典来存储所有信息
movie_info = {
# 标题
'title': title,
# 分类
'cate': cate,
# 链接
'url': url,
}
# 读取已有的 JSON 文件内容
file_path = 'movie_info1.json'
if os.path.exists(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
existing_data = json.load(f)
else:
existing_data = []
# 添加新的电影信息到现有数据中
existing_data.append(movie_info)
# 将更新后的数据写回到 JSON 文件
with open(file_path, 'w', encoding='utf-8') as f:
json.dump(existing_data, f, ensure_ascii=False, indent=4)
print(f"{title}已追加到 movie_info1.json 文件中。")
成果展示
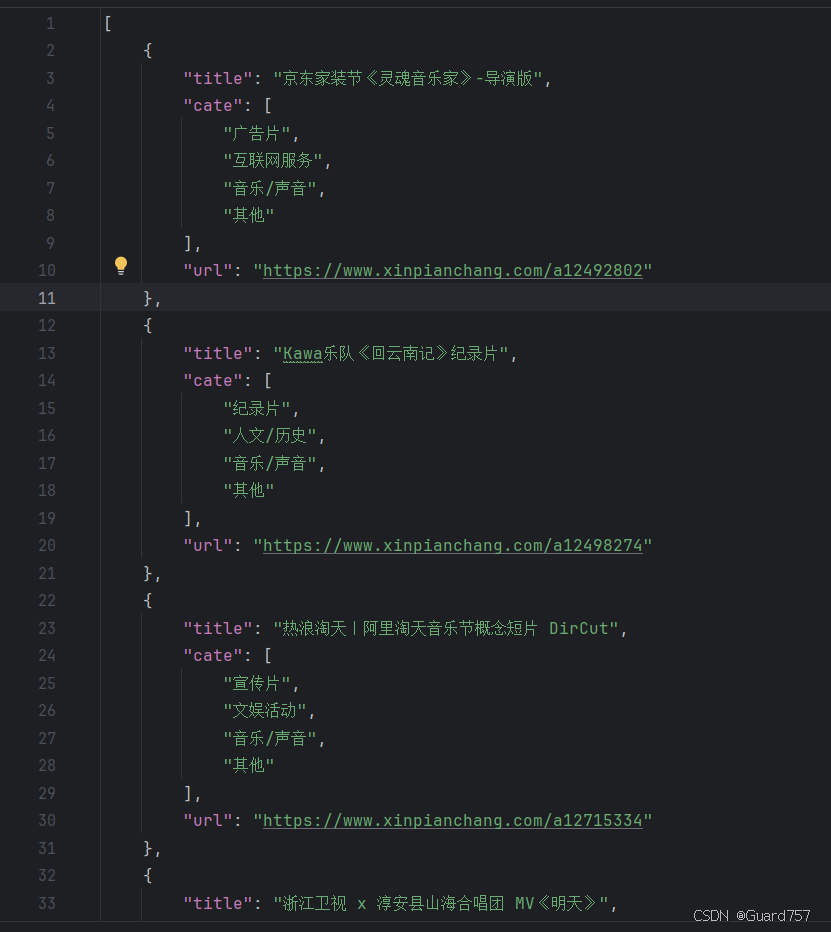
视频链接.py
视频链接在html中,使用request请求没加载出来,没数据,这里使用自动化工具
import json
import re
import time
from DrissionPage import ChromiumPage
def get_ck(url):
# 使用ChromiumPage获取网页内容
page = ChromiumPage()
page.get(url)
time.sleep(10) # 等待页面加载
html = page.html
clean_url = None
# 正则表达式匹配视频链接
match = re.search(r'src="([^"]+\.mp4\?[^"]+)"', html)
if match:
video_url = match.group(1)
# 使用正则表达式提取基本 URL
match = re.match(r'([^?]+)', video_url)
if match:
clean_url = match.group(1)
print('================', clean_url)
else:
print("URL 不匹配")
else:
print("视频链接未找到")
return clean_url
def get_urls_from_json(json_file, count=60):
# 从本地JSON文件中读取URL列表
url_list = []
with open(json_file, 'r', encoding='utf-8') as file:
datas = json.load(file)
for data in datas:
url = data['url']
url_list.append(url)
# 取出前count个URL
urls = url_list[:count]
print(urls)
return urls
def save_urls_to_json(urls, output_file):
# 将URL列表保存到JSON文件中
with open(output_file, 'w', encoding='utf-8') as file:
json.dump(urls, file, ensure_ascii=False, indent=4)
print(f"Clean URLs 已保存到 {output_file}")
# 从JSON文件中读取URL
json_file_path = 'movie_info1.json' # 替换为你的文件路径
urls = get_urls_from_json(json_file_path, 60)
# 用于存储 clean_url 的列表
clean_urls = []
# 对每个URL执行 get_ck 函数,并将得到的 clean_url 添加到列表中
for url in urls:
clean_url = get_ck(url)
if clean_url:
clean_urls.append({'clean_url': clean_url})
# 将得到的 clean_url 列表保存到一个新的 JSON 文件中
output_file_path = 'clean_urls.json' # 设置输出文件路径
save_urls_to_json(clean_urls, output_file_path)
成果展示
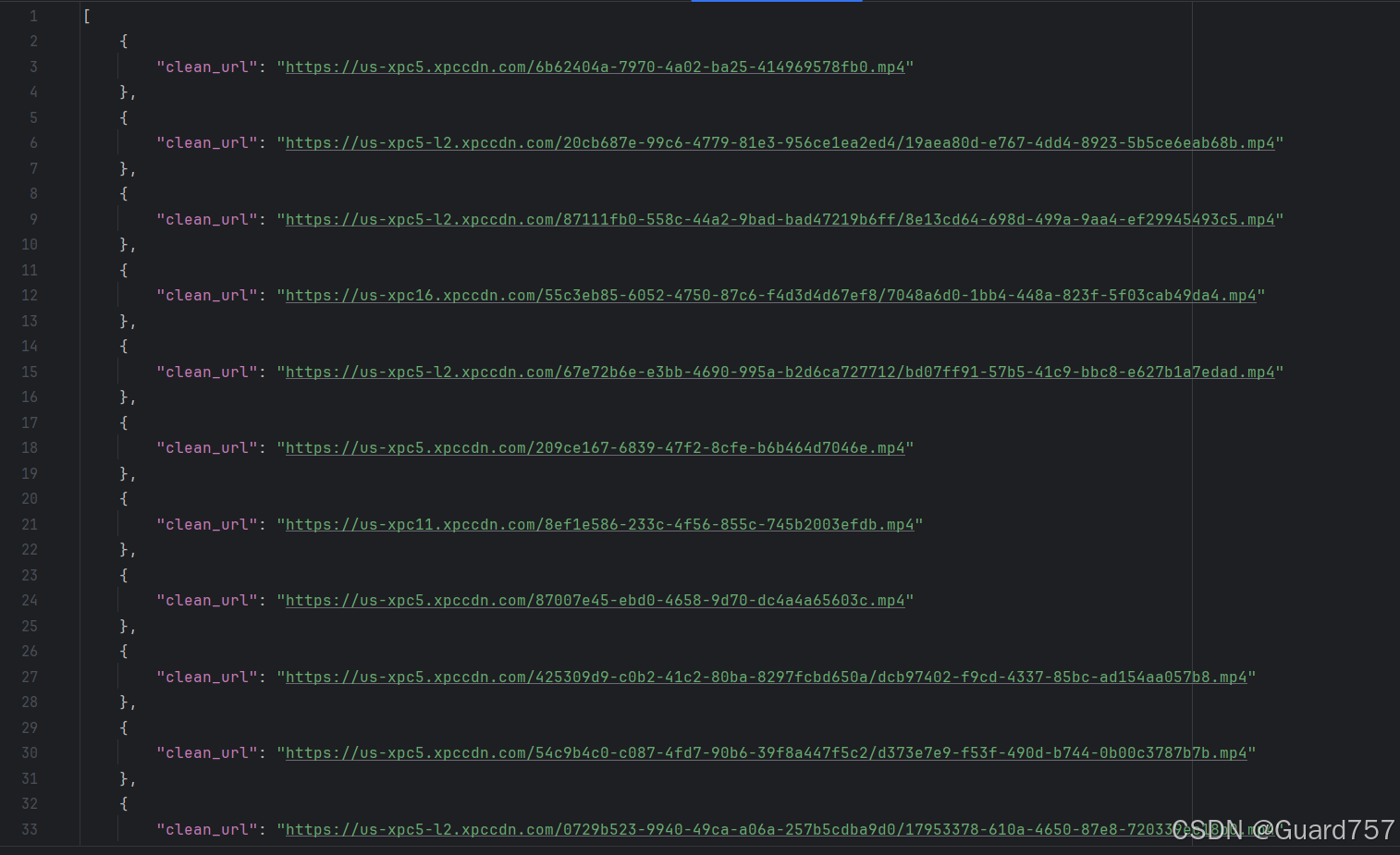
视频下载.py
使用多线程,快速下载视频
import json
import requests
import os
import re
import time
from concurrent.futures import ThreadPoolExecutor
def video(video_url, thread_name):
headers = {
'sec-ch-ua': '"Not)A;Brand";v="99", "Google Chrome";v="127", "Chromium";v="127"',
'Referer': 'https://www.xinpianchang.com/',
'sec-ch-ua-mobile': '?0',
'Range': 'bytes=0-',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36',
'sec-ch-ua-platform': '"Windows"',
}
params = {
'j': '{"userId":14882668,"deviceId":"66b4975aaf0658528","ip":"42.235.14.44,61.163.51.58"}',
}
try:
response = requests.get(video_url, params=params, headers=headers, stream=True)
print(f"{thread_name}: {response}")
if response.status_code == 206:
with open(f'{thread_name}.mp4', 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
print(f"{thread_name}: 视频下载完成")
else:
print(f"{thread_name}: 下载失败,状态码:{response.status_code}")
except Exception as e:
print(f"{thread_name}: 下载出错: {e}")
# 读取已有的 JSON 文件内容
with open('clean_urls.json', 'r', encoding='utf-8') as f:
datas = json.load(f)
# 多线程下载视频
def download_videos_multithreaded(urls):
with ThreadPoolExecutor(max_workers=10) as executor: # 设置最大线程数
for i, data in enumerate(urls):
video_url = data.get('clean_url')
if video_url:
thread_name = f'视频{i+1}'
executor.submit(video, video_url, thread_name)
download_videos_multithreaded(datas)
成果展示
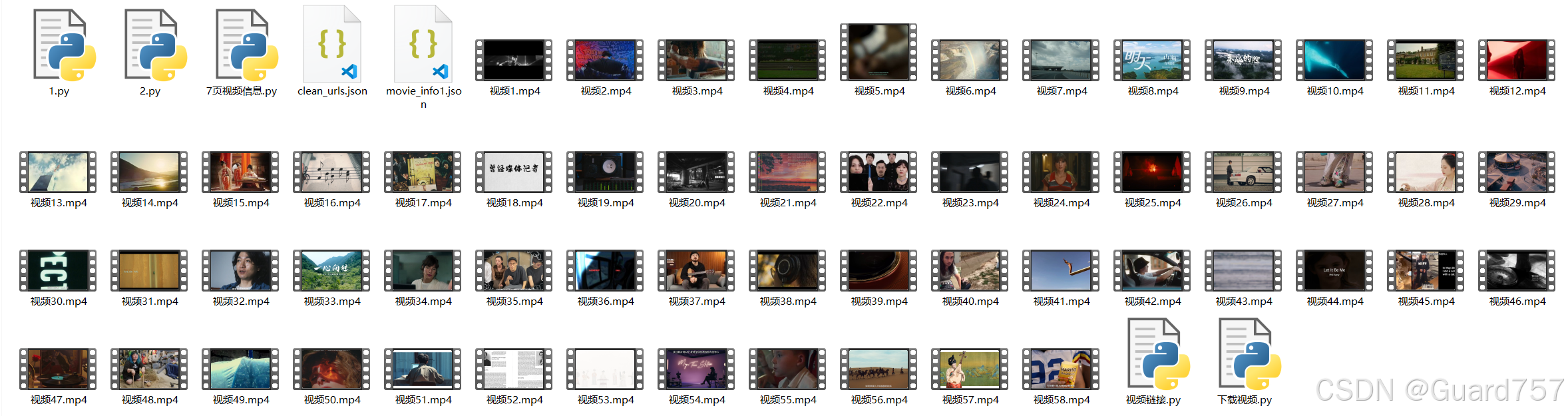

















 2650
2650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









