







 本文详细介绍了Hadoop的起源、特点、现状及组件,以及HBase作为Hadoop生态系统中的分布式列式数据库,其特性、与关系数据库的比较以及实现原理和系统架构。Hadoop和HBase在大数据处理中发挥关键作用,适用于大规模数据存储和分析需求。
本文详细介绍了Hadoop的起源、特点、现状及组件,以及HBase作为Hadoop生态系统中的分布式列式数据库,其特性、与关系数据库的比较以及实现原理和系统架构。Hadoop和HBase在大数据处理中发挥关键作用,适用于大规模数据存储和分析需求。
文章目录
主要内容
- Hadoop
- HBASE
一.Hadoop
Hadoop是一个开源的分布式计算框架,最初由Apache软件基金会开发和维护。它允许用户在集群中分布式存储和处理大规模数据集,提供了高可靠性、高可扩展性和高性能的数据处理能力。
Hadoop的发展史可以追溯到2004年,当时Google发表了一篇名为“Google File System”和“MapReduce”的论文,这两个技术成为了Hadoop的基础。Doug Cutting和Mike Cafarella在2005年创建了Hadoop项目,最初是为了实现Nutch搜索引擎的分布式处理。随后,Yahoo成为了Hadoop项目的主要支持者,并将其用于大规模数据处理和分析。
1.Hadoop的特点包括:
- 分布式存储:Hadoop使用Hadoop Distributed File System(HDFS)来分布式存储数据,数据被划分成多个块并存储在不同的节点上,提高了数据的可靠性和可用性。
- 分布式计算:Hadoop使用MapReduce编程模型来实现分布式计算,将数据划分成小块并在集群中并行处理,加快了数据处理速度。
- 可扩展性:Hadoop可以轻松地扩展到成百上千个节点,处理PB级别的数据,满足了大规模数据处理的需求。
- 高容错性:Hadoop具有高容错性,即使在节点故障的情况下,数据仍然可以被可靠地处理和恢复。
2.Hadoop现状
目前,Hadoop已经成为了大数据领域最流行的分布式计算框架之一,被广泛应用于各行各业的大规模数据处理和分析中。除了HDFS和MapReduce,Hadoop生态系统还包括了许多其他组件,如Hive、Pig、Spark等,为用户提供了更丰富的数据处理和分析工具。随着大数据技术的不断发展,Hadoop也在不断更新和完善,为用户提供更强大的数据处理能力。
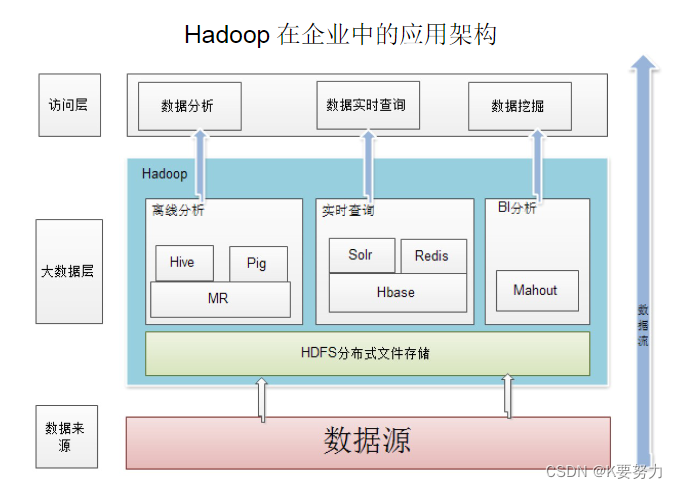
3.Hadoop项目结构
| 组件 | 功能 |
|---|---|
| HDFS | 分布式文件系统 |
| MapReduce | 分布式并行编程模型 |
| YARN | 资源管理和调度器 |
| Tez | 运行在YARN之上的下一代Hadoop查询处理框架 |
| Hive | Hadoop上的数据仓库 |
| HBase | Hadoop上的非关系型的分布式数据库 |
| Pig | 一个基于Hadoop的大规模数据分析平台,提供类似SQL的查询语言Pig Latin |
| Sqoop | 用于在Hadoop与传统数据库之间进行数据传递 |
| Oozie | Hadoop上的工作流管理系统 |
| Zookeeper | 提供分布式协调一致性服务 |
| Storm | 流计算框架 |
| Flume | 一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统 |
| Ambari | Hadoop快速部署工具,支持Apache Hadoop集群的供应、管理和监控 |
| Kafka | 一种高吞吐量的分布式订阅消息系统,可以处理消费者规模的网站中的所有动作数据流 |
| Spark | 类似于Hadoop MapReduce的通用并行框架 |

4.HBase特点
HBase是一个开源的分布式数据库,它是基于Google的Bigtable设计而来的,用于存储非结构化和半结构化数据。HBase是一个面向列的数据库,它将数据存储在表中的行和列族中,并且支持水平扩展。
HBase的特点包括:
- 高可靠性:HBase采用了分布式存储和复制机制,可以提供高可靠性和容错性。
- 高性能:HBase支持快速读写操作,并且可以水平扩展以提高性能。
- 灵活性:HBase支持动态模式和灵活的数据模型,可以存储各种类型的数据。
- 高可扩展性:HBase可以在集群中添加新的节点来扩展存储容量和处理能力。
5.与传统关系数据库相比,HBase具有以下优势:
- 存储能力:HBase可以存储PB级别的数据,而传统关系数据库通常只能存储TB级别的数据。
- 处理能力:HBase可以处理大规模数据并支持高并发访问,而传统关系数据库在处理大数据量和高并发情况下性能会下降。
- 数据模型:HBase的数据模型更灵活,可以存储各种类型的数据,而传统关系数据库需要预先定义表结构。
- 可扩展性:HBase可以通过添加新节点来扩展存储容量和处理能力,而传统关系数据库需要升级硬件或软件来扩展。
总的来说,HBase适用于需要存储大规模非结构化数据和需要高性能、高可扩展性的场景,而传统关系数据库适用于结构化数据和需要事务支持的场景。在选择数据库时,需要根据具体的业务需求和数据特点来进行权衡和选择。
6.HBase实现原理与功能组件
HBase是一个基于Hadoop的分布式、面向列的数据库,它的实现原理和功能组件如下:
实现原理:
- 数据存储:HBase将数据存储在HDFS上,数据按列族存储,每个列族包含多个列限定符,每个列族可以包含多个列簇。
- 数据模型:HBase采用稀疏矩阵的数据模型,数据以行键和列族索引的形式存储,可以支持高效的随机读写操作。
- 分布式存储:HBase采用分布式存储架构,数据被分散存储在多台服务器上,可以实现水平扩展。
- 数据一致性:HBase通过ZooKeeper实现数据一致性,保证数据的一致性和可靠性。
功能组件:
- HMaster:负责管理HBase集群的元数据信息,包括表的创建、删除、分片等操作。
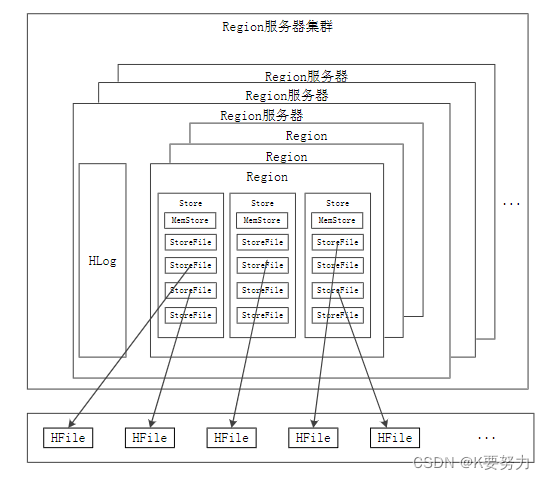
- RegionServer:负责实际的数据存储和读写操作,每个RegionServer管理多个Region,每个Region对应一个表的一个分片。
- HRegion:HBase数据的最小单元,包含一个表的一个分片的数据。
- HTable:HBase表的客户端接口,用于进行数据的读写操作。
- HBase Shell:提供命令行接口,方便用户进行数据的管理和查询操作。
- HBase API:提供Java、Python等语言的API接口,方便开发人员进行数据的读写操作。
- HBase Coprocessor:允许用户在RegionServer上运行自定义的代码,可以实现数据的过滤、计算等操作。
- HBase Bulk Load:提供高效的数据批量导入功能,可以快速将大量数据导入HBase中。
7.HBase三层结构
HBase是一个分布式、面向列的NoSQL数据库,其数据存储结构可以分为三层:
1. 表(Table):HBase中的最顶层结构是表,表由多行(Row)组成,每行又包含多个列族(Column Family)。
2. 行(Row):表中的每一行都有一个唯一的行键(Row Key),行键用来唯一标识一行数据。行中的数据以列族为单位进行存储。
3. 列族(Column Family):列族是表中的一个逻辑组织单位,每个列族可以包含多个列(Column)。列族在表的创建时就需要定义,并且在表的生命周期中不能被修改。
总的来说,HBase的数据存储结构可以看作是一个由表、行和列族组成的多维数据结构。通过这种结构,HBase能够实现高效的数据存储和检索,同时支持水平扩展和高可用性。
8.HBase系统架构
HBase系统架构主要包括以下几个组件:
-
HMaster:HMaster是HBase的主节点,负责管理和协调整个集群的工作。它负责负载均衡、元数据管理、region的分配和监控等工作。
-
RegionServer:RegionServer是HBase的工作节点,负责存储和管理数据。每个RegionServer可以管理多个Region,每个Region对应一个表的一部分数据。
-
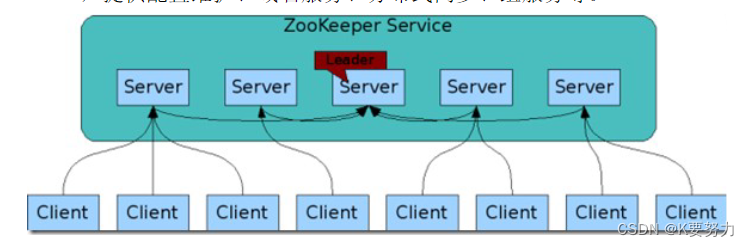
ZooKeeper:ZooKeeper是HBase的协调服务,负责集群的协调和管理。HBase依赖ZooKeeper来实现分布式锁、选举、配置管理等功能。
-
HDFS:HBase使用Hadoop分布式文件系统(HDFS)来存储数据。HBase将数据存储在HDFS上,并通过HDFS提供的高可靠性和扩展性来保证数据的安全和可靠性。
-
Client:Client是与HBase交互的应用程序,通过HBase客户端API来访问和操作HBase中的数据。客户端可以直接连接HBase集群,也可以通过Thrift、REST等接口来访问HBase。

整个HBase系统架构是一个分布式的、高可用的系统,可以通过添加新的RegionServer节点来实现水平扩展,从而提高系统的吞吐量和容量。同时,HBase还提供了数据复制、自动故障转移、数据压缩等功能,以保证数据的可靠性和性能。
总结
以上是今天要讲的内容,学到了Hadoop和HBase基础。
















 3187
3187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











