






1 KNN算法是什么?
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
------------来自360百科
2 KNN算法的伪代码:
对未知类别属性的数据集中的每个点依次执行以下操作:
(1)算出已知数据集中的点与目标点之间的距离S;
(2)按照距离递增排序;
(3)选取与目标点距离最小的k个点;(K取整数)
(4)确定前k个点所在属性的出现概率;
(5)得出前k个点出现概率最高的属性作为当前点的预测分类。3 举例子说明KNN算法:
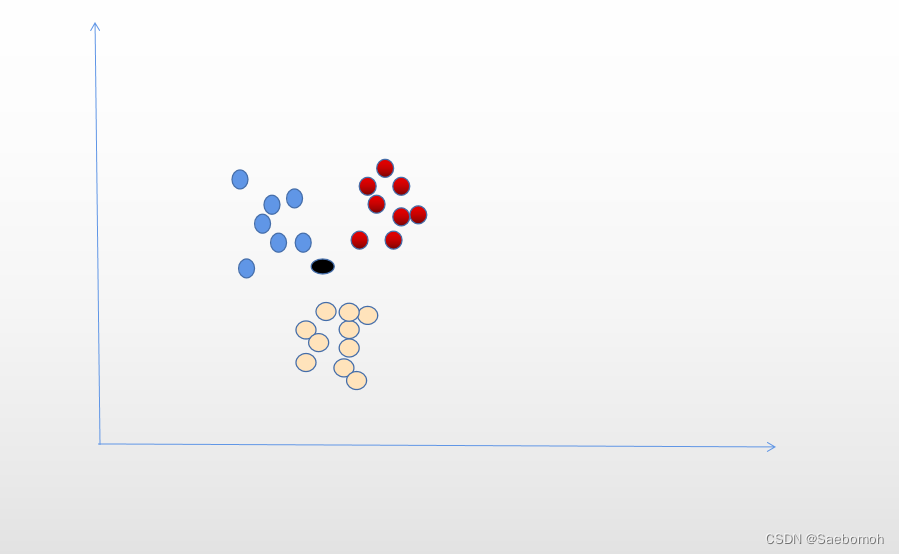
三个不同颜色的属性 现在存在着一个黑点让你判断黑点的属性是属于红蓝黄三种的哪一种
把每个点的坐标表示出来
以黑色点为目标点 邻近K个点作为比较点,找出与黑色点最近的距离
即判断黑色点从属于这个点颜色的属性
4 数据集准备:
在网上找了许多数据集,借用小数据,返回x,y
2 写一个KNN函数,进行分类:
计算欧氏距离
3 排序,返回位置索引
4 创建字典初始化数据分类
5 统计
6 降序,找出距离最近K个点训练数据
7 测试
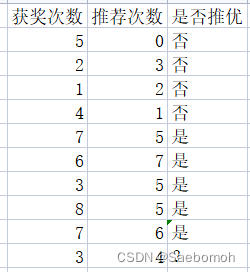
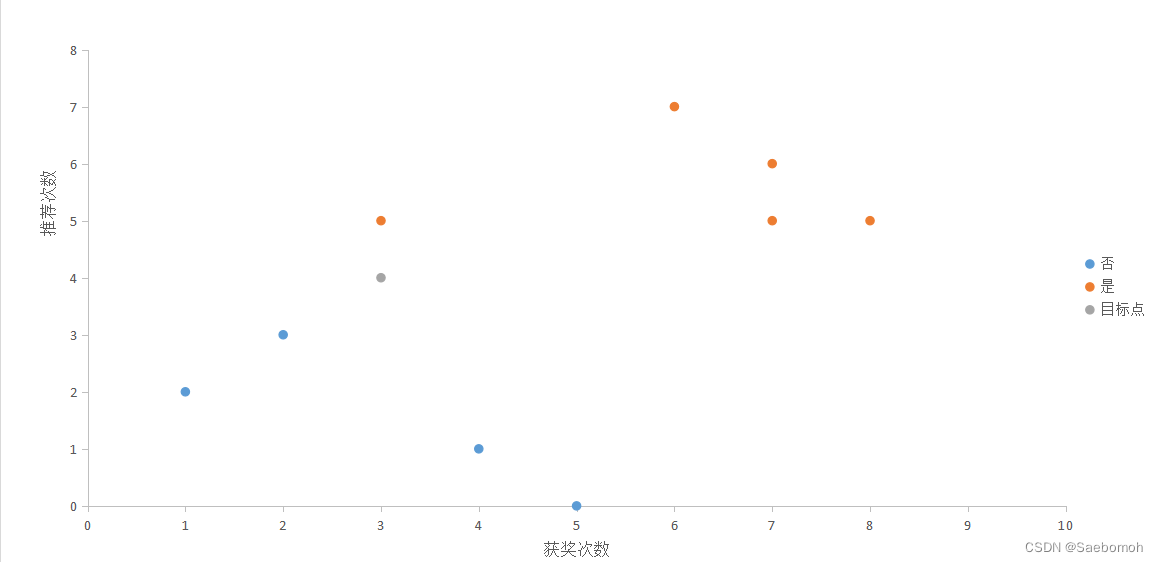
以下是题目数据:
5 代码实现
import numpy as np
import operator
def DataSet():
group = np.array([[5,0],[7,5],[2,3],[6,7],[1,2],[3,5],[8,5],[4,1],[7,6]])
labels = ['否','是','否','是','否','是','是','否','是']
return group, labels
def KNN(in_x, x_labels,y_labels,k):
x_labels_size = x_labels.shape[0]
distances = (np.tile(in_x,(x_labels_size,1))-x_labels)**2 ##欧氏距离
ad_distances = distances.sum(axis=1)
sq_distances = ad_distances ** 0.5
ed_distances = sq_distances.argsort() #欧氏距离进行排序,返回索引
classdict = {}
for i in range(k): ##前K个数统计计数
voteI_label = y_labels[ed_distances[i]]
classdict[voteI_label] = classdict.get(voteI_label,0) + 1
sort_classdict = sorted(classdict.items(),key = operator.itemgetter(1), reverse = True) ##排序
return sort_classdict[0][0]
if __name__ == '__main__':
group,labels = DataSet()
test_x = [3,4]
print ('输入的数据是否推免:{}'.format(KNN(test_x,group,labels,3)))
结果展示:

(参考up博主sequenceflow)
6 个人总结
KNN算法优点:
简单有效,重新训练的代价低(修改参数即可进行训练),适合类域交叉样本(有时候属性重叠比较多)重叠越多分类越好
缺点:
类别评分不是规格化,输出可解释性不强(根据距离,看不到空间决策,不比决策树),欧氏距离计算量较大(点越多越大),精度不够















 2078
2078











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









