






2.2.2 内核调用
内核调用会生成大量的block和thread来在GPU上并行地处理数据,语法如下:
FFT << <blockNum, threadPerBlock >> >应确保内核使用__global__关键字定义。可包含三个用逗号分隔的参数。
para1:希望执行的block数
para2:每个块将具有的线程数
para3:可选,指定内核使用的共享内存的大小
2.2.3 配置内核参数
一个块中的线程可以通过共享内存彼此通信
GPU支持三位网格块和三位线程块,语法如下:
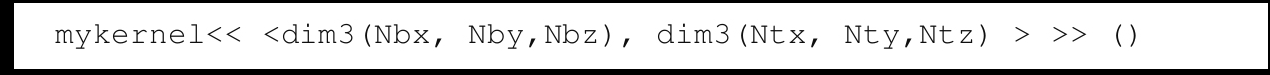
在这里,Nbx、Nby和Nbz分别表示网格中沿x,y和z轴方向的块数。同样,Ntx、Nty和Ntz分别表示一个块中沿x,y和z轴方向的线程数。如果没有指定y和z的维数,默认情况下它们被取为1
启动一个16×16的块网格,所有的块都包含16×16个线程

2.2.4 cuda API函数
__global__,__device__,__host__限定符关键字 ,表明函数被声明为一个设备函数
如果要在设备上执行并从设备函数调用函数,则必须使用__device__关键字
__host__关键字用于从其他主机函数调用普通函数。默认情况下,程序中所有函数都是主机函数















 1192
1192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









