






开始可以借鉴阿里腾讯开发规范——实际中运用会大体相近
1、注释
#:单行注释
‘’‘ ’‘’ 或者“”“ ”“”:多行注释
2、标识符
合法:
ABC、ABC_123、姓名、_123
不合法:
123、1ABC、if(保留字)、init(预定义标识符)
(1)当标识符用作模块名时,应尽量短小,并且全部使用小写字母,可以使用下划线分割多个字母,例如game_main、game_register等。 (2)当标识符用作包的名称时,应尽量短小,并且全部使用小写字母,不推荐使用下划线,例如com.mr、com.mr.book等。 (3)当标识符用作类名时,应采用单词首字母大写的形式。例如,定义一个图书类,可以命名为Book。 (4)模块内部的类名,可以采用“下划线+首字母大写”的形式,如_Book。 函数名、类中的属性名和方法名,应全部使用小写字母,多个单词之间可以用下划线分割。 (5)常量命名应全部使用大写字母,单词之间可以用下划线分割。
-
字符集和格式:
-
标识符可以包含字母(大小写敏感)、数字和下划线 。
_ -
标识符的第一个字符必须是字母(大写或小写)或下划线 。
_
-
-
关键字和保留字:
-
不能使用Python中的关键字和保留字作为标识符。这些包括 , , , , , 等。
if``else``for``while``class``def
-
-
大小写敏感:
-
Python是大小写敏感的,因此标识符的大小写会被区分。
-
-
命名约定:
-
Python通常推荐以下划线命名法(Snake Case)来命名变量、函数、方法和模块名。这意味着多个单词用下划线连接,例如 , 。
my_variable``calculate_area()
-
-
类命名约定:
-
类名通常使用首字母大写的驼峰命名法(Pascal Case),例如 , 。
MyClass``MyClassWithMethods
-
-
变量和函数名:
-
变量名和函数名应该具有描述性,能够清晰地表达其用途或含义。
-
例如
max_value`,calculate_area(),`is_valid(), 等。
-
-
常量命名:
-
Python中没有真正意义上的常量,但是约定上,常量通常使用全大写字母,用下划线分隔单词。例如,
MAX_SIZE`,`PI`,`DEFAULT_VALUE.
-
input函数:
实现用户的输入
eval函数:
以python表达式的方式解析并执行字符串
print函数:
默认是换行的
print('123') 换行
print('123' ,end=" ") 不换行
3、数值类型
基本的数值类型:int、float、string、complex(复数类型:见的少 3+5j )
空值:None,常用于没有返回值的函数结果,
bool:值为true 和 flase
bytes:用bytes()函数进行数据转换;这种类型用于网络数据传输、二进制图片和文件的保存
-
Number(数字)
-
String(字符串)
-
bool(布尔类型)
-
List(列表)
-
Tuple(元组)
-
Set(集合)
-
Dictionary(字典)
Python3 的六个标准数据类型中:
-
不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
-
可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
此外还有一些高级的数据类型,如: 字节数组类型(bytes)。
(1)浮点类型详解
-
十进制形式 这种就是我们平时看到的小数形式,例如 34.6、346.0、0.346。
书写小数时必须包含一个小数点,否则会被 Python 当作整数处理。
2、指数形式 Python 小数的指数形式的写法为:
aEn 或 aen
a 为尾数部分,是一个十进制数;n 为指数部分,是一个十进制整数;E或e是固定的字符,用于分割尾数部分和指数部分。整个表达式等价于 a×10n。
指数形式的小数举例:
2.1E5 = 2.1×105,其中 2.1 是尾数,5 是指数。 3.7E-2 = 3.7×10-2,其中 3.7 是尾数,-2 是指数。 0.5E7 = 0.5×107,其中 0.5 是尾数,7 是指数。
注意,只要写成指数形式就是小数,即使它的最终值看起来像一个整数。例如 14E3 等价于 14000,但 14E3 是一个小数。

Python 只有一种小数类型,就是 float。C语言有两种小数类型,分别是 float 和 double:float 能容纳的小数范围比较小,double 能容纳的小数范围比较大。
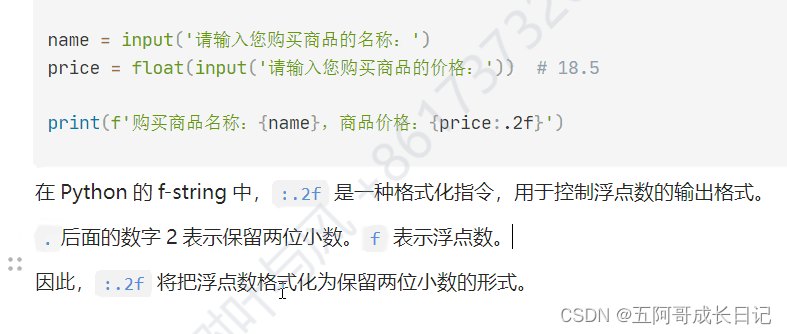
【实例】小数在 Python 中的使用:
f1 = 12.5
print("f1Value: ", f1)
print("f1Type: ", type(f1))
f2 = 0.34557808421257003
print("f2Value: ", f2)
print("f2Type: ", type(f2))
#当数值过小时Python会自动将其转换为科学计数法的形式,以更方便地显示和理解极小的数值。
f3 = 0.0000000000000000000000000847
print("f3Value: ", f3)
print("f3Type: ", type(f3))
f4 = 345679745132456787324523453.45006
print("f4Value: ", f4)
print("f4Type: ", type(f4))
f5 = 12e4
print("f5Value: ", f5)
print("f5Type: ", type(f5))
f6 = 12.3 * 0.1
print("f6Value: ", f6)
print("f6Type: ", type(f6))
4、字符串的索引和切片
这个不多说看菜鸟教程,一看就会
'+'在字符串中有连接作用;
len(s):返回s的长度或其他组合类型的元素个数
# 用法示例
my_list = [1, 2, 3, 4, 5]
print(len(my_list)) # 输出: 5
my_string = "Hello, World!"
print(len(my_string)) # 输出: 13
my_dict = {'a': 1, 'b': 2, 'c': 3}
print(len(my_dict)) # 输出: 3
str(s):把元素(s)转换为字符串
chr(‘65’):返回‘A’;
5、数据类型转换
1、type()
对变量进行类型的判断
自动类型的转换(不同类型混合运算生成的结果为最宽的类型)
type(10/4*4) flaot 123+4.0=127.0
2、isinstance()
跟提供的类型进行对比
isinstance(3,int) true isinstance(3.2,int) flase isinstance(3.2,(int,float,str)) true
6、正则表达式的常用函数
re.complie()使正则表达式变为正则表达式对象——一般使用网上工具
import re strpat = r'(\d+)'(\.\d*)?‘ txt=..... pats=re.complie(strpat)
re.match()扫描提供的对象,查找是否有匹配的
escape()
如果特殊字符太多,需要输入大量反斜杠,可以使用escape()

7、列表、元组、字典
列表(List)
-
有序集合:列表是有序的,可以通过索引访问元素,适合存储顺序相关的数据。
-
可变性:列表是可变的,可以动态增删元素,适合需要频繁修改数据的场景。
-
适用场景:
-
存储同类型或不同类型的数据集合,例如存储一组学生名单、待办事项列表等。
-
需要动态增删元素的情况,例如管理用户的收藏列表、网站的文章列表等。
-
元组(Tuple)
-
不可变性:元组一旦创建后,其内容不可修改,具有保护数据的特性。
-
性能优势:元组比列表更加轻量和高效,适合作为常量集合使用。
-
适用场景:
-
存储不会改变的数据集合,例如存储一组坐标、日期时间信息等。
-
作为函数返回值,可以确保数据不被修改。
-
在多线程环境下作为安全的数据结构使用。
-
字典(Dictionary)
-
键值对:字典存储的是键值对,可以通过键快速查找值,适合需要快速访问和查找数据的场景。
-
动态性:字典是可变的,可以方便地增删键值对,适合动态更新和管理数据。
-
适用场景:
-
存储具有映射关系的数据,例如用户信息、产品属性等。
-
需要快速查找和更新数据的情况,例如建立用户ID到详细信息的映射、存储配置信息等。
-
JSON 格式数据的解析和处理。
-
总结
-
列表适合存储有序的元素集合,需要频繁增删操作的场景。
-
元组适合不可变的、静态数据集合,用于保护数据或作为常量集合使用。
-
字典适合存储键值对,需要快速查找和更新数据的场景。
(1)列表
(1)索引和切片
#!/usr/bin/python3 list = ['red', 'green', 'blue', 'yellow', 'white', 'black'] print( list[0] ) print( list[1] ) print( list[2] ) #反向索引 #!/usr/bin/python3 list = ['red', 'green', 'blue', 'yellow', 'white', 'black'] print( list[-1] ) print( list[-2] ) print( list[-3] )
(2)切片
#!/usr/bin/python3
nums = [10, 20, 30, 40, 50, 60, 70, 80, 90]
print(nums[0:4])
#反向所以截止
#!/usr/bin/python3
list = ['Google', 'Runoob', "Zhihu", "Taobao", "Wiki"]
# 读取第二位
print ("list[1]: ", list[1])
# 从第二位开始(包含)截取到倒数第二位(不包含)
print ("list[1:-2]: ", list[1:-2])
(3)修改和更新
#!/usr/bin/python3
list = ['Google', 'Runoob', 1997, 2000]
print ("第三个元素为 : ", list[2])
list[2] = 2001
print ("更新后的第三个元素为 : ", list[2])
list1 = ['Google', 'Runoob', 'Taobao']
list1.append('Baidu')
print ("更新后的列表 : ", list1)
#输出
第三个元素为 : 1997
更新后的第三个元素为 : 2001
更新后的列表 : ['Google', 'Runoob', 'Taobao', 'Baidu']
(4)删除(del)
#!/usr/bin/python3
list = ['Google', 'Runoob', 1997, 2000]
print ("原始列表 : ", list)
del list[2]
print ("删除第三个元素 : ", list)
#输出
原始列表 : ['Google', 'Runoob', 1997, 2000]
删除第三个元素 : ['Google', 'Runoob', 2000]
(5)拼接和比较
>>> squares = [1, 4, 9, 16, 25]
>>> squares += [36, 49, 64, 81, 100]
>>> squares
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
>>>
#嵌套
>>> a = ['a', 'b', 'c']
>>> n = [1, 2, 3]
>>> x = [a, n]
>>> x
[['a', 'b', 'c'], [1, 2, 3]]
>>> x[0]
['a', 'b', 'c']
>>> x[0][1]
'b'
#比较
# 导入 operator 模块
import operator
a = [1, 2]
b = [2, 3]
c = [2, 3]
print("operator.eq(a,b): ", operator.eq(a,b))
print("operator.eq(c,b): ", operator.eq(c,b))
#输出
operator.eq(a,b): False
operator.eq(c,b): True
(6)列表的函数和方法
函数: len(list) 列表元素个数 max(list) 返回列表元素最大值 min(list) 返回列表元素最小值 list(seq) 将元组转换为列表 方法: list.append(obj) 在列表末尾添加新的对象 这个list就是所设的变量,随条件而变化,基本的写法就是只要写list.append(obj),但obj只添加一个值 list.count(obj) 统计某个元素在列表中出现的次数 list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) list.index(obj) 从列表中找出某个值第一个匹配项的索引位置 list.insert(index, obj) 将对象插入列表 list.pop([index=-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 list.remove(obj) 移除列表中某个值的第一个匹配项 这个时候想为什么不能删除重复的值,但为什么不用集合能,这个就没想到,要对数据类型更加熟悉 list.reverse() 反向列表中元素q list.sort( key=None, reverse=False) 对原列表进行排序 list.clear() 清空列表 list.copy() 复制列表
(2)元组
元组除了内容不可修改外性质跟列表差不多——以下写的是与列表略微不同的地方
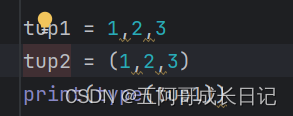
这个括号可有可无,当要写,规范格式
(1)修改
#!/usr/bin/python3
#元组中的元素值是不允许修改的,但我们可以对元组进行连接组合
tup1 = (12, 34.56)
tup2 = ('abc', 'xyz')
# 以下修改元组元素操作是非法的。
# tup1[0] = 100
# 创建一个新的元组
tup3 = tup1 + tup2
print (tup3)
(2)删除
#!/usr/bin/python3
#元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组
tup = ('Google', 'Runoob', 1997, 2000)
print (tup)
del tup
print ("删除后的元组 tup : ")
print (tup)
#输出
删除后的元组 tup :
Traceback (most recent call last):
File "test.py", line 8, in <module>
print (tup)
NameError: name 'tup' is not defined
(3)特性:元组不可变
>>> tup = ('r', 'u', 'n', 'o', 'o', 'b')
>>> tup[0] = 'g' # 不支持修改元素
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>> id(tup) # 查看内存地址
4440687904
>>> tup = (1,2,3)
>>> id(tup)
4441088800 # 内存地址不一样了
#从以上实例可以看出,重新赋值的元组 tup,绑定到新的对象了,不是修改了原来的对象。
(4)函数
函数: len(tuple) 列表元素个数 max(tuple) 返回列表元素最大值 min(tuple) 返回列表元素最小值 tuple(iterable) 将可迭代系列转换为元组
(3)字典
定义:
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值 key=>value 对用冒号 : 分割,每个对之间用逗号(,)分割,整个字典包括在花括号 {} 中
d = {key1 : value1, key2 : value2, key3 : value3 }
(1)创建空字典
# 使用大括号 {} 来创建空字典
emptyDict = {}
# 打印字典
print(emptyDict)
# 查看字典的数量
print("Length:", len(emptyDict))
# 查看类型
print(type(emptyDict))
#输出
{}
Length: 0
<class 'dict'>
(2)使用内建函数 dict() 创建字典
emptyDict = dict()
# 打印字典
print(emptyDict)
# 查看字典的数量
print("Length:",len(emptyDict))
# 查看类型
print(type(emptyDict))
#输出
{}
Length: 0
<class 'dict'>
(3)索引
#!/usr/bin/python3
tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
print ("tinydict['Name']: ", tinydict['Name'])
print ("tinydict['Age']: ", tinydict['Age'])
#输出
tinydict['Name']: Runoob
tinydict['Age']: 7
#如果用字典里没有的键访问数据,会输出错误如下
#!/usr/bin/python3
tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
print ("tinydict['Alice']: ", tinydict['Alice'])
#输出
Traceback (most recent call last):
File "test.py", line 5, in <module>
print ("tinydict['Alice']: ", tinydict['Alice'])
KeyError: 'Alice'
(4)修改字典
#!/usr/bin/python3
#向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对
tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
tinydict['Age'] = 8 # 更新 Age
tinydict['School'] = "菜鸟教程" # 添加信息
print ("tinydict['Age']: ", tinydict['Age'])
print ("tinydict['School']: ", tinydict['School'])
#输出
tinydict['Age']: 8
tinydict['School']: 菜鸟教程
(5)删除字典
能删单一的元素也能清空字典,清空只需一项操作。
显式删除一个字典用del命令,如下实例
#!/usr/bin/python3
tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
del tinydict['Name'] # 删除键 'Name'
tinydict.clear() # 清空字典
del tinydict # 删除字典
print ("tinydict['Age']: ", tinydict['Age'])
print ("tinydict['School']: ", tinydict['School'])
#输出
Traceback (most recent call last):
File "/runoob-test/test.py", line 9, in <module>
print ("tinydict['Age']: ", tinydict['Age'])
NameError: name 'tinydict' is not defined
(6)字典的特性
字典值可以是任何的 python 对象,既可以是标准的对象,也可以是用户定义的,但键不行。
两个重要的点需要记住:
1)不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住
#!/usr/bin/python3
tinydict = {'Name': 'Runoob', 'Age': 7, 'Name': '小菜鸟'}
print ("tinydict['Name']: ", tinydict['Name'])
#输出
tinydict['Name']: 小菜鸟
2)键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行,如下实例:
#!/usr/bin/python3
tinydict = {['Name']: 'Runoob', 'Age': 7}
print ("tinydict['Name']: ", tinydict['Name'])
#输出
Traceback (most recent call last):
File "test.py", line 3, in <module>
tinydict = {['Name']: 'Runoob', 'Age': 7}
TypeError: unhashable type: 'list'
(7)函数
len(dict) 计算字典元素个数,即键的总数。 str(dict) 输出字典,可以打印的字符串表示。 type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型。
(8)方法
1 dict.clear() 删除字典内所有元素 2 dict.copy() 返回一个字典的浅复制 3 dict.fromkeys() 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 4 dict.get(key, default=None) 返回指定键的值,如果键不在字典中返回 default 设置的默认值 5 key in dict 如果键在字典dict里返回true,否则返回false 6 dict.items() 以列表返回一个视图对象 7 dict.keys() 返回一个视图对象 8 dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default 9 dict.update(dict2) 把字典dict2的键/值对更新到dict里 10 dict.values() 返回一个视图对象 11 pop(key[,default]) 删除字典 key(键)所对应的值,返回被删除的值。 12 popitem() 返回并删除字典中的最后一对键和值。
8、集合
定义:集合是一个无序的不重复元素序列
可以使用{}创建集合当不能是空集合,也可以用set()函数创建(创建空集合必须用set()函数)
parame = {value01,value02,...}
或者
set(value)
set1 = {1, 2, 3, 4} # 直接使用大括号创建集合
set2 = set([4, 5, 6, 7]) # 使用 set() 函数从列表创建集合
(1)添加元素
>>> thisset = set(("Google", "Runoob", "Taobao"))
>>> thisset.add("Facebook")
>>> print(thisset)
{'Taobao', 'Facebook', 'Google', 'Runoob'}
#还有一个方法,也可以添加元素,且参数可以是列表,元组,字典等:update
>>> thisset = set(("Google", "Runoob", "Taobao"))
>>> thisset.update({1,3})
>>> print(thisset)
{1, 3, 'Google', 'Taobao', 'Runoob'}
>>> thisset.update([1,4],[5,6])
>>> print(thisset)
{1, 3, 4, 5, 6, 'Google', 'Taobao', 'Runoob'}
>>>
(2)删除
#有两种——s.remove()|s.discard()|pop()-随机删除
>>> thisset = set(("Google", "Runoob", "Taobao"))
>>> thisset.remove("Taobao")
>>> print(thisset)
{'Google', 'Runoob'}
>>> thisset.remove("Facebook") # 不存在会发生错误
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'Facebook'
>>>
>>> thisset = set(("Google", "Runoob", "Taobao"))
>>> thisset.discard("Facebook") # 不存在不会发生错误
>>> print(thisset)
{'Taobao', 'Google', 'Runoob'}
方法:
add() 为集合添加元素 clear() 移除集合中的所有元素 copy() 拷贝一个集合 difference() 返回多个集合的差集 difference_update() 移除集合中的元素,该元素在指定的集合也存在。 discard() 删除集合中指定的元素 intersection() 返回集合的交集 intersection_update() 返回集合的交集。 isdisjoint() 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。 issubset() 判断指定集合是否为该方法参数集合的子集。 issuperset() 判断该方法的参数集合是否为指定集合的子集 pop() 随机移除元素 remove() 移除指定元素 symmetric_difference() 返回两个集合中不重复的元素集合。 symmetric_difference_update() 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。 union() 返回两个集合的并集 update() 给集合添加元素 len() 计算集合元素个数
9、推导式
[表达式 for 变量 in 列表] [out_exp_res for out_exp in input_list] 或者 [表达式 for 变量 in 列表 if 条件] [out_exp_res for out_exp in input_list if condition]
>>> names = ['Bob','Tom','alice','Jerry','Wendy','Smith'] >>> new_names = [name.upper()for name in names if len(name)>3] >>> print(new_names) ['ALICE', 'JERRY', 'WENDY', 'SMITH'] >>> multiples = [i for i in range(30) if i % 3 == 0] >>> print(multiples) [0, 3, 6, 9, 12, 15, 18, 21, 24, 27]
(1)字典推导式
{ key_expr: value_expr for value in collection }
或
{ key_expr: value_expr for value in collection if condition }
listdemo = ['Google','Runoob', 'Taobao']
# 将列表中各字符串值为键,各字符串的长度为值,组成键值对
>>> newdict = {key:len(key) for key in listdemo}
>>> newdict
{'Google': 6, 'Runoob': 6, 'Taobao': 6}
>>> dic = {x: x**2 for x in (2, 4, 6)}
>>> dic
{2: 4, 4: 16, 6: 36}
>>> type(dic)
<class 'dict'>
(2)集合推导式
>>> setnew = {i**2 for i in (1,2,3)}
>>> setnew
{1, 4, 9}
>>> a = {x for x in 'abracadabra' if x not in 'abc'}
>>> a
{'d', 'r'}
>>> type(a)
<class 'set'>
(3)元组
>>> a = (x for x in range(1,10)) >>> a <generator object <genexpr> at 0x7faf6ee20a50> # 返回的是生成器对象 >>> tuple(a) # 使用 tuple() 函数,可以直接将生成器对象转换成元组 (1, 2, 3, 4, 5, 6, 7, 8, 9)
9、迭代器
定义:访问集合元素的一种方式。迭代器是一个可以记住遍历位置的对象。迭代器对象从第一个元素开始访问,直到所有元素被访问。
迭代器有两个基本的方法:iter()和next()
(1)使用iter()或者next() 函数可以将可迭代对象(如列表、字典、字符串等)转换为迭代器
>>> list=[1,2,3,4]
>>> it = iter(list) # 创建迭代器对象
>>> print (next(it)) # 输出迭代器的下一个元素
1
>>> print (next(it))
2
>>>
#!/usr/bin/python3
import sys # 引入 sys 模块
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
while True:
try:
print (next(it))
except StopIteration:
sys.exit()
也可以使用常规for语句进行遍历:
#!/usr/bin/python3
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
for x in it:
print (x, end=" ")
(2)面向对象时
把一个类作为一个迭代器使用需要在类中实现两个方法 iter() 与 next() 。
class MyNumbers:
def __iter__(self):
self.a = 1
return self
def __next__(self):
x = self.a
self.a += 1
return x
myclass = MyNumbers()
myiter = iter(myclass)
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))















 308
308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









