







目录
DDL
DDL(Data Definition Language), 数据定义语言 该语言部分包括以下内容
- 对数据库的常用操作
- 对表结构的常用操作
- 修改表结构
一.对数据库的常用操作
查看数据库
show databases;创建数据库
create databases [if not exists] mydb1;切换数据库
use mydb1;删除数据库
drop database [if exists] mydb1;修改数据库编码
alter database mydb1 character set utf8;二.对表结构的常用操作
-- 创建表的格式
create table [if not exists] 表名(
字段名1 类型[(宽度)] [约束条件] [comment '字段说明'],
................................................
)[表的一些设置];
--注意最后一个字段名后面不需要加逗号,一段话的结尾处记得加分号(也可不加)创建表是构建一张空表,指定这个表的名字,这个表有几列,每一列叫什么名字,以及每一列存储的数据类型。
处理现有的表 在创建新表时,指定的表名必须不存在,否则将会出错,如果要防止意外覆盖已有的表,SQL要求首先手工删除该表,然后再重建它,而不是简单地用创建表语句覆盖它
如果你仅想在一个表不存在时创建它,应该在表名好给出 if not exists。这样做不检查已有表的模式是否与你打算创建表的模式相匹配。它只是查看表名是否存在,并且仅在表名不存在时创建它
use mydb1;
create table student(
sid int,
name varchar(20),
gender varchar(20),
age int,
birth date,
address varchar(20),
score double
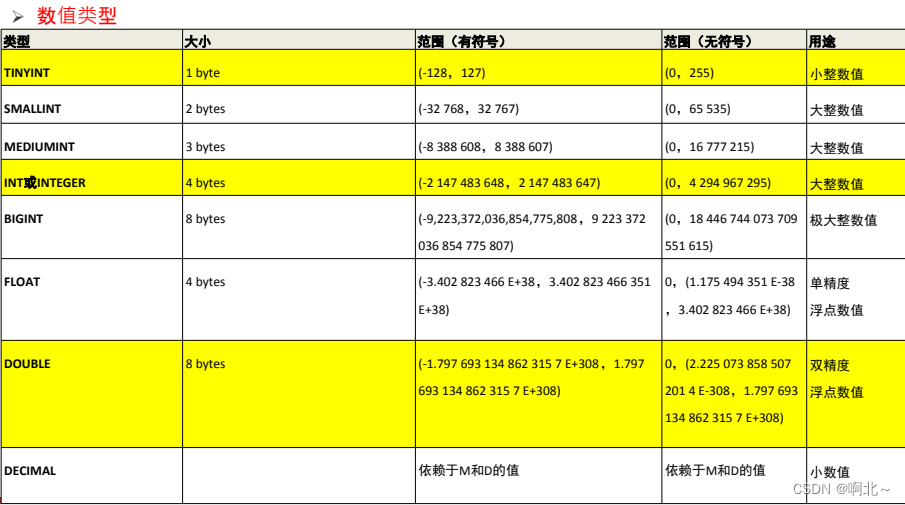
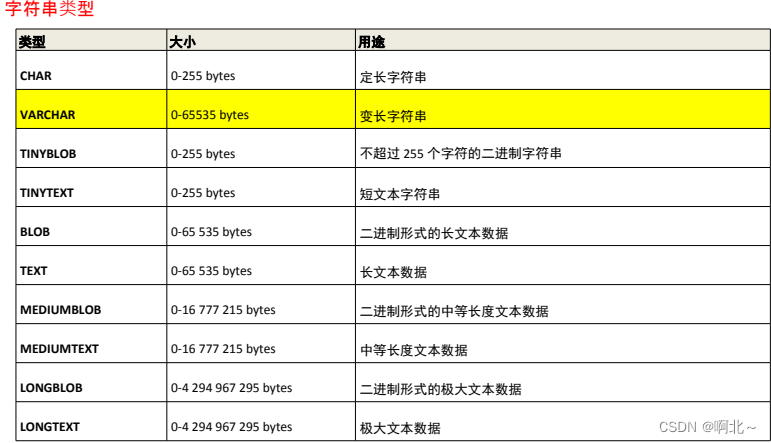
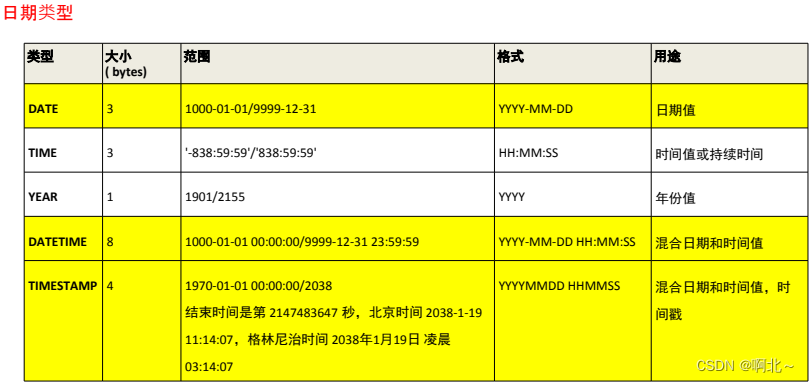
);我们还需要创建表的时候为表中字段指定数据类型,只有数据符合类型要求才能存储起来,使用数据类型的原则是:够用就行,尽量使用取值范围小的,而不用大的,这样可以更多的节省存储空间。
三.对表结构的常用操作
查看当前数据库的所有表名称
show tables;查看指定某个表的创建语句
show create table 表名;查看表结构
desc 表名;删除表
drop table 表名;alter table 表名 add 列名 类型(长度) [约束];修改列名和类型
alter table 表名 change 旧列名 新列名 类型(长度) 约束;删除列
alter table 表名 drop 列名;修改表名
rename table 表名 to 新表名;DML
DML是指数据操作语言,英文全称是Data Mainpulation Language,用来对数据库中表的数据记录进行更新。包括以下内容
- 插入insert
- 删除delete
- 更新update
一.数据插入
-- 第一种格式
insert into 表(列1,列2,列3...) values(值1,值2,值3...);
-- 第二种格式
insert into 表 values(值1,值2,值3...);二.数据修改
-- 格式1
update 表名 set 字段名=值,字段名=值...;
-- 格式2
update 表名 set 字段名=值,字段名=值...where 条件;三.数据删除
delete from 表名[where 条件];
truncate table 表名 或者 truncate 表名;注意:delete和truncate原理不同,delete只删除内容,而truncate类似于drop table,可以理解为将整个表删除,然后再创建该表
DQL
概念:数据库管理系统一个重要功能就是数据查询,数据查询不应只是简单返回数据库中存储的数据,还应该根据需要对数据进行筛选以及确定数据以什么样的格式显示,Mysql数据库使用select语句来查询数据。
一.简单查询
语法
select 列名1,列名2 from 表 where 条件举例-- 查询所有商品
select *form product;别名查询
select pname as pn from product;去重查询
select distinct price from product;二.条件查询
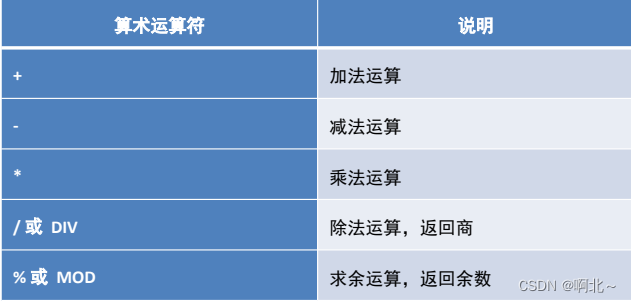
条件查询一般配合着运算符进行查询的。
运算符如下:
算数运算符
比较运算符
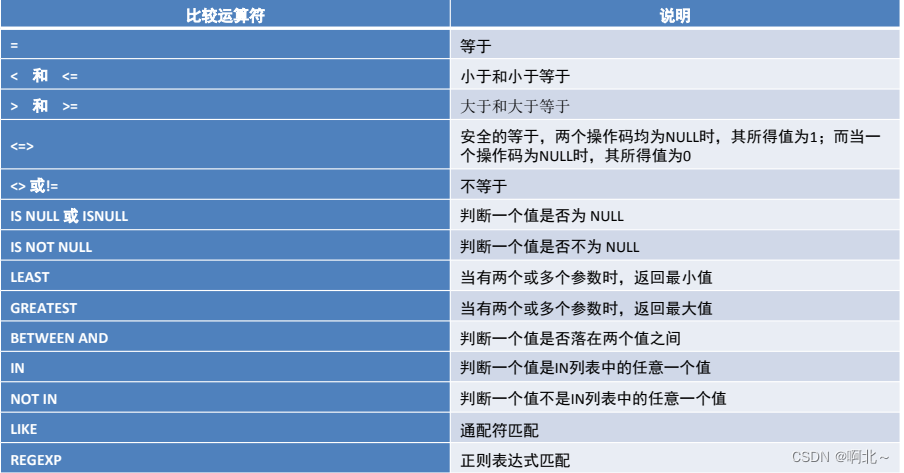
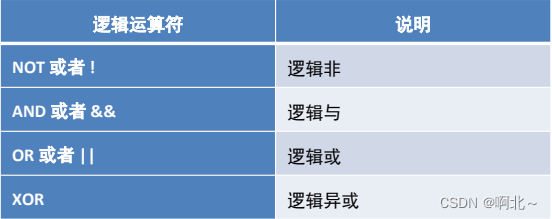
逻辑运算符
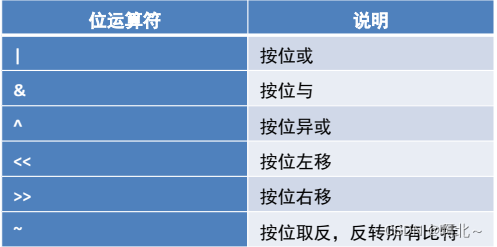
位运算符
例如:
查询商品名称为'耐克'的商品所有信息
select *from product where pname='耐克';三.排序查询
如果我们需要对读取的数据进行排序,我们就可以使用MySQL的order by 子句来设定你想按那个字段那种方式来进行排序,再返回搜索结果
语法:
select
字段1,
字段2,...
from 表名
order by 字段1 [asc|desc],字段2[asc|desc]...
特点:
- asc代表升序,desc代表降序,如果不写默认升序
- order by 用于子句中可以支持单个字段,多个字段,表达式,函数,别名
- order by子句,放在查询语句的最后面。limit子句除外
举例:
使用价格排序(降序)
select *from product order by price desc;四.聚合查询
之前的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵向查询,它是对一列的值进行计算,然后返回一个单一的值;另外聚合函数会忽略空值
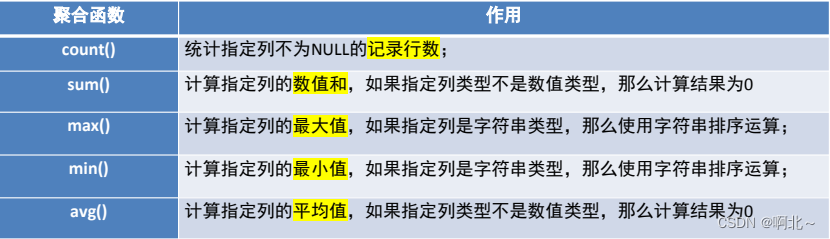
例如
查询商品的总条数
select count(*) from product;注意: NULL值的处理
- count函数对null值的处理,如果count函数的参数为星号(*),则统计所有记录的个数。而如果参数为某字段,不统计含null值的记录个数
- sum和avg函数对null值的处理 ,俩个函数都忽略null值的存在
- max和min函数对null值同样是忽略
五.分组查询
分组查询是指使用group by子句对查询信息进行分组,形象的说就是把一张表,按某个字段进行分组,分成多张表。
格式:
select
字段1,
字段2...
from 表名
group by
分组字段
having 分组条件;注意:如果要进行分组的话,则select子句之后,只能出现分组的字段和统计函数,其他的字段不能出现。
分组之后的条件筛选-having;
- 分组之后对统计结果进行筛选的话必须使用having,不能使用where
- where子句用来筛选from子句中指定的操作所产生的行
- group by 子句用来分组 where子句的输出
- having子句用来从分组的结果中筛选行
操作
统计各个分类商品的个数,且只显示个数大于4的信息
select category_id,count(*) from product
group by category_id
having count(*)>4;六.分页查询
由于数据量很大,显示屏长度有限,因此对数据需要采取分页显示方式。例如数据共有30条,每页显示5条
格式:
-- 方式1 显示前n条
select 字段1,字段2....
from 表明 limit n;
--方式2 分页显示
select 字段1,字段2...
from 表明 limit m,n;
m:整数,表示从第几条索引开始,计算方式 (当前页-1)*每页显示条数
n:整数,表示查询多少条数据
insert into select语句
将一张表的数据导入到另一张表中。(前提是目标表必须存在)
insert into table2(字段1,字段2...)
select value1,value2,...from table1;
select into from 语句
将一张表的数据导入到另一张表中,(前提要求目标table2不存在,因为插入时会自动创建表table2,并将table1指定字段数据复制到table2中),有俩种选择 select into和insert into select
格式:
select value1,value2
into table2
from table1;七.正则表达式
正则表达式描述一种字符串匹配的规则,正则表达式本身就是一个字符串,使用这个字符串来描述、用来定义匹配规则,匹配一系列符合某个句法规则的字符串。正则表达式通常被用来检索、替换那么符合某个规则的文本
mysql通过regexp关键字支持正则表达式进行字符串匹配
格式:
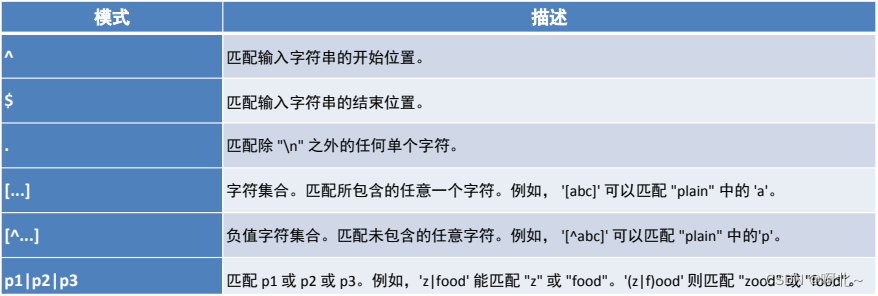

-- ^在字符串开始处进行匹配
select 'abc' regexp '^a';
-- $ 在字符串末尾开始匹配
select 'abc' regexp 'a$';
select 'abc' regexp 'c%$';
-- . 匹配任意字符
select 'abc' regexp '.b';
select 'abc' regexp '.c';
select 'abc' regexp 'a.';
-- [...]匹配括号内的任意单个字符
select 'abc' regexp '[xyz]';
select 'abc' regexp '[xaz]';
-- [^...]注意^符合只有在[]内才是取反的意思,在别的地方都是表示开始处匹配
select 'a' regexp '[^abc]';
-- a* 匹配0个或多个a,包括空字符串。可以作为占位符使用.有没有指定字符都可以匹配到数据
select 'stab' regexp '.ta*b';
-- a+ 匹配1个或者多个a,但是不包括空字符
select 'stab' regexp '.ta+b';
-- a? 匹配0个或者1个a
select 'stb' regexp '.ta?b';
-- a1|a2 匹配a1或者a2
select 'a' regexp 'a|b';
-- a{m} 匹配m个a
select 'auuuuc' regexp 'au{4}c';
-- a{m,n} 匹配m到n个a,包含m和n
select 'auuuuc' regexp 'au{3,5}c';
-- (abc) abc作为一个序列匹配,不用括号括起来都是用单个字符去匹配,如果要把多个字符作为一个整体去匹配就需要用到括号,所以括号适合上面的所有情况.
select 'xababy' regex[ 'x(abab)y';














 1606
1606











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









