






目录
05.加载数据、创建并训练卷积神经网络模型,绘制训练过程中的准确率和损失值曲线,并将训练好的模型保存为HDF5格式文件。
一、介绍:
MNIST手写数字识别数据集是由Yann LeCun、Corinna Cortes和Christopher Burges等人创建的。该数据集最初于1998年发布,是一个用于机器学习算法评估和比较的标准基准。MNIST代表了Modified National Institute of Standards and Technology(修改后的国家标准与技术研究所)。
这个数据集由来自不同人手写的数字图像组成,涵盖了从0到9的数字。每张图像都是单通道(灰度)的,分辨率为28x28像素。这些图像是由美国国家标准与技术研究所(NIST)的员工和美国高中生共同构建的。
MNIST数据集最初的目的是为了提供一个用于训练机器学习算法的标准数据集,并且是一个简单的问题,使得不同的算法可以进行直接的比较和评估。由于其简单和普遍性,MNIST数据集成为了计算机视觉和机器学习领域中最为流行的基准数据集之一。
虽然MNIST数据集在最初发布时并没有引起太多关注,但随着深度学习的兴起,尤其是卷积神经网络(CNN)的出现,MNIST数据集成为了评估深度学习算法性能的主要数据集之一。通过在MNIST上训练和测试模型,研究人员能够快速地验证新的算法、架构和技术,并且探索不同的训练方法和超参数设置。
因此,MNIST手写数字识别数据集在推动机器学习和深度学习领域的发展方面发挥了重要作用,成为了许多研究和算法发展的起点。
二、MNIST数据集获取方法:
请查看点击这链接,观看获取方法。
三、训练结果及预测效果:
01.训练结果:
训练十个批次。
478 秒/60=7.97 分钟
所以整个批次的耗时大约是 7.97 分钟。
验证集的准确率(val_accuracy)是 0.9949,即 99.49%。

02. 预测效果 :
2.1待预测图像:0-9共十张图像。
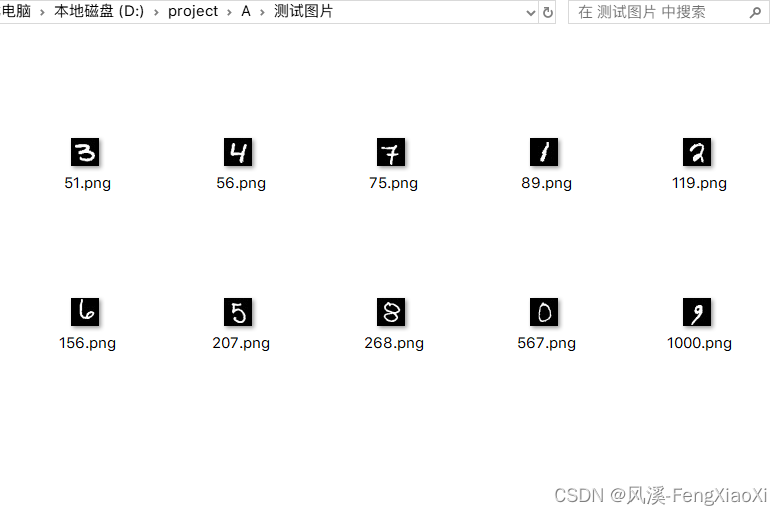
2.2预测结果:
可以看上面展示的待预测图像,进行对比。
这个准确率显示模型的预测非常可靠,接近100%。
四、模型训练:
01.导入所需库:
import tensorflow as tf
import matplotlib.pyplot as plt
02.加载数据集:
-
使用
tf.keras.preprocessing.image_dataset_from_directory函数从指定目录加载图像数据集。这个函数用于从目录中读取图像文件,并将它们转换为TensorFlow数据集对象。函数的参数包括:directory: 数据集所在的目录路径。color_mode: 图像的颜色模式,这里设置为灰度模式('grayscale')。image_size: 图像的大小,这里设置为(28, 28)。batch_size: 批处理大小,即每个训练批次包含的图像数量。label_mode: 标签模式,这里设置为'categorical'表示使用分类标签。validation_split: 用于验证集划分的比例,这里设置为0.2表示20%的数据用于验证集。subset: 指定数据集的子集,这里设置为'training'表示加载训练集。seed: 随机种子,用于数据集分割的随机性。
def load_data():
# 从指定目录加载训练集,使用灰度模式,图像大小为28x28像素,批处理大小为28,使用分类标签,
# 验证集占训练集的20%,加载训练集,设置随机种子为123
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
directory='mnist_dataset/train',
color_mode='grayscale',
image_size=(28, 28),
batch_size=28,
label_mode='categorical',
validation_split=0.2,
subset='training',
seed=123
)
# 从指定目录加载测试集,使用灰度模式,图像大小为28x28像素,批处理大小为28,使用分类标签,
# 验证集占测试集的20%,加载训练集,设置随机种子为123
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
directory='mnist_dataset/test',
color_mode='grayscale',
image_size=(28, 28),
batch_size=28,
label_mode='categorical',
validation_split=0.2,
subset='training',
seed=123,
)
# 获取训练集的类别名称
class_names = train_ds.class_names
# 打印类别名称
print('class_names')
# 返回加载的训练集、验证集和类别名称
return train_ds, val_ds, class_names
03.构建卷积神经网络(CNN):
def model_dast():
model = tf.keras.Sequential()
# 第一个卷积层块
model.add(tf.keras.layers.Conv2D(filters=64, kernel_size=(5, 5), padding='Same', input_shape=(28, 28, 1)))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.Conv2D(filters=64, kernel_size=(5, 5), padding='Same', activation='relu'))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.MaxPool2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
# 第二个卷积层块
model.add(tf.keras.layers.Conv2D(filters=64, kernel_size=(3, 3), padding='Same'))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.Conv2D(filters=64, kernel_size=(3, 3), padding='Same', activation='relu'))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.MaxPool2D(pool_size=(2, 2), strides=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
# 第三个卷积层块
model.add(tf.keras.layers.Conv2D(filters=64, kernel_size=(3, 3), padding='Same', activation='relu'))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.Dropout(0.25))
# 全连接层
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(256, activation='relu'))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
model.summary()
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
return model
04.绘制模型训练过程中的准确率和损失值的变化曲线:
def plt_train(history):
# 提取训练过程中的准确率和损失值
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
# 创建一个大小为(10, 8)的图像
plt.figure(figsize=(10, 8))
# 绘制准确率曲线
plt.subplot(2, 1, 1) # 创建第一个子图,2行1列,位于第1行
plt.plot(acc, label='Training Accuracy') # 绘制训练准确率曲线
plt.plot(val_acc, label='Validation Accuracy') # 绘制验证准确率曲线
plt.legend(loc='lower right') # 添加图例,位置为右下角
plt.ylim([min(min(acc), min(val_acc)), 1]) # 设置y轴范围,使其适应数据范围
plt.ylabel('Accuracy') # 设置y轴标签
plt.title('Training and Validation Accuracy') # 设置标题
# 绘制损失值曲线
plt.subplot(2, 1, 2) # 创建第二个子图,2行1列,位于第2行
plt.plot(loss, label='Training Loss') # 绘制训练损失值曲线
plt.plot(val_loss, label='Validation Loss') # 绘制验证损失值曲线
plt.legend(loc='upper right') # 添加图例,位置为右上角
plt.ylabel('Cross Entropy') # 设置y轴标签
plt.title('Training and Validation Loss') # 设置标题
# 调整子图布局,以确保子图之间的间距合适
plt.tight_layout()
# 将绘制的结果保存为图片,文件名为'training_results.png',dpi为100
plt.savefig('training_results.png', dpi=100)
# 显示绘制的图像
plt.show()
05.加载数据、创建并训练卷积神经网络模型,绘制训练过程中的准确率和损失值曲线,并将训练好的模型保存为HDF5格式文件。
# 如果当前文件作为独立运行的脚本
if __name__ == "__main__":
# 加载数据集,包括训练集、验证集和类别名称
train_ds, val_ds, class_name = load_data()
# 创建并初始化卷积神经网络模型
model = model_dast()
# 使用训练集训练模型,指定训练轮数为10,同时使用验证集验证模型
history = model.fit(train_ds, epochs=10, validation_data=val_ds)
# 绘制模型训练过程中的准确率和损失值曲线
plt_train(history)
# 将训练好的模型保存为HDF5格式文件,文件名为'cnn.h5'
model.save('cnn.h5')















 1054
1054











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









