






No 01. 用两个栈实现队列
问题描述:
用两个栈实现一个队列。队列的声明如下,请实现它的两个函数 appendTail 和 deleteHead ,分别完成在队列尾部插入整数和在队列头部删除整数的功能。(若队列中没有元素,deleteHead 操作返回 -1 )
示例:
输入:
["CQueue","appendTail","deleteHead","deleteHead"]
[[],[3],[],[]]
输出:[null,null,3,-1]
核心思想:利用两个栈实现队列,在队列有输出请求时,若栈1非空栈2空,栈1所有元素弹入栈2,再从栈2顶部弹出一个元素,若栈2本身非空则直接从栈2顶部弹出元素
代码示例:
class CQueue {
public:
stack<int> stack1;
stack<int> stack2;
CQueue() {
}
void appendTail(int value) {
stack1.push(value);
}
int deleteHead() {
int res;
if(stack1.empty()&&stack2.empty()){
return -1;
}
else if(!stack1.empty()&&stack2.empty()){
while(!stack1.empty()){
int tmp=stack1.top();
stack1.pop();
stack2.push(tmp);
}
res=stack2.top();
stack2.pop();
}
else if(!stack2.empty()){
res=stack2.top();
stack2.pop();
}
return res;
}
};
/**
* Your CQueue object will be instantiated and called as such:
* CQueue* obj = new CQueue();
* obj->appendTail(value);
* int param_2 = obj->deleteHead();
*/No 02. 包含min函数的栈
问题描述:
定义栈的数据结构,请在该类型中实现一个能够得到栈的最小元素的 min 函数在该栈中,调用 min、push 及 pop 的时间复杂度都是 O(1)。
示例:
MinStack minStack = new MinStack();
minStack.push(-2);
minStack.push(0);
minStack.push(-3);
minStack.min(); --> 返回 -3.
minStack.pop();
minStack.top(); --> 返回 0.
minStack.min(); --> 返回 -2.来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/bao-han-minhan-shu-de-zhan-lcof
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
核心思想:利用辅助栈实现在0(1)的负载度内得到栈的最小元素
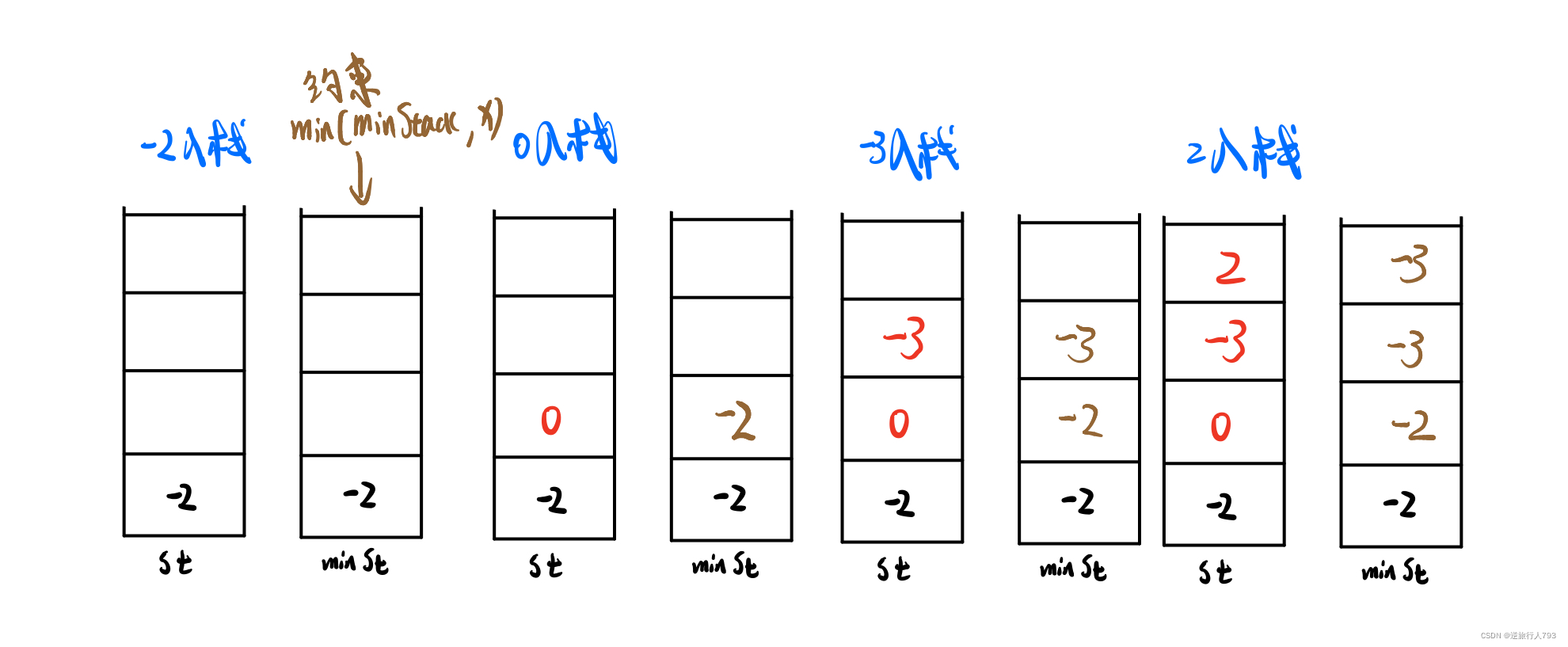
代码示例:
初始版本:
class MinStack {
public:
/* 定义两个栈容器 */
stack<int> st;
stack<int> minStack;
/** 构造函数清空栈容器 */
MinStack() {
while(!st.empty()) {
st.pop();
}
while(!minStack.empty()) {
minStack.pop();
}
/* 初始化最小栈的栈顶元素为最大值为了防止top访问空指针报错 */
minStack.push(INT_MAX);
}
void push(int x) {
st.push(x);
/* 比较最小栈的栈顶的值和当前值val的大小,将最小值押入最小栈也就是记录了当前st栈的最小值为栈顶元素 */
int minVal = std::min(minStack.top(), x);
/* 将最小值押入最小栈 */
minStack.push(minVal);
}
void pop() {
/* 弹出两个栈的栈顶元素 */
st.pop();
minStack.pop();
}
int top() {
return st.top();
}
int min() {
/* 取最小栈的栈顶元素就是此时st栈的最小值 */
return minStack.top();
}
};
更改版本:
class MinStack {
private:
stack<int> stkIn;
stack<int> stkMin;
public:
/** initialize your data structure here. */
MinStack() {}
void push(int x) {
stkIn.push(x);
if(stkMin.empty() or stkMin.top() >= x){
stkMin.push(x);
}
}
void pop() {
if(!stkMin.empty() and stkIn.top() == stkMin.top()){
stkMin.pop();
}
if (!stkIn.empty()) {
stkIn.pop();
}
}
int top() {
return stkIn.top();
}
int min() {
return stkMin.top();
}
};注意事项:一开始只是简单的pop两个栈,但是在编译阶段会报错,在每个pop前面给minStack的push前面加个判断是否空可以防止报错,亦可以通过在构造函数给栈塞个INT_MAX,以此防止top访问空指针报错
No 03. 从尾到头打印链表
问题描述:输入一个链表的头节点,从尾到头反过来返回每个节点的值(用数组返回)。
示例:
输入:head = [1,3,2] 输出:[2,3,1]
核心思想:可以构建辅助栈,利用栈的特性(先进后出),将表内元素逆置。
代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
vector<int> reversePrint(ListNode* head) {
stack<int>s;
vector<int>v;
ListNode* a=head;
while(a!=NULL){
s.push(a->val);
a=a->next;
}
while(!s.empty()){
v.push_back(s.top());
s.pop();
}
return v;
}
};注意:类内只能构建变量和函数
No 04. 反转链表
问题描述: 定义一个函数,输入一个链表的头节点,反转该链表并输出反转后链表的头节点。
示例:
输入: 1->2->3->4->5->NULL 输出: 5->4->3->2->1->NULL
原本构想: 本想延续上一道的思想将其存入栈内,再构建一个新链表,将其重新赋值,但是写到最后发现不会用指针指向容器。。。。若以后发现方法再补充
失败的代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
stack<int>s;
ListNode *a=head;
list<int>l;
while(a!=NULL){
s.push(a->val);
a=a->next;
}
while(!s.empty()){
l.push_back(s.top());
s.pop();
}
ListNode* b=&(l.begin());
return b;
}
};核心思想(双指针法):
声明两个指针,一个从头开始一个从空指针开始,每次用tmp储存cur原本指向的节点,之后让cur指向pre,之后更新pre和cur指针用tmp给cur指路,cur给pre指路,
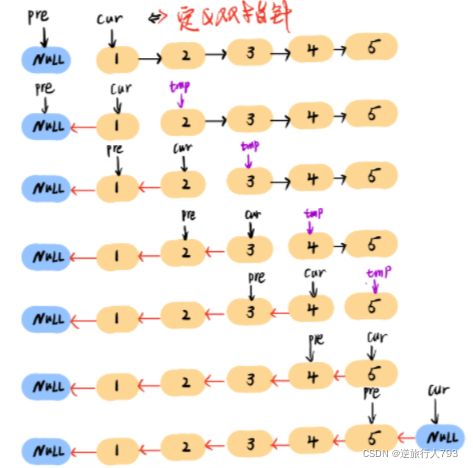
代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode* cur=head;
ListNode* pre=nullptr;
while(cur!=NULL){
ListNode* tmp=cur->next;
cur->next=pre;
pre=cur;
cur=tmp;
}
return pre;
}
};No 05. 复杂链表的复制
题目描述:
请实现 copyRandomList 函数,复制一个复杂链表。在复杂链表中,每个节点除了有一个 next 指针指向下一个节点,还有一个 random 指针指向链表中的任意节点或者 null。
示例:

输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
设计思路:
利用哈希表的查询特点,考虑构建 原链表节点 和 新链表对应节点 的键值对映射关系,再遍历构建新链表各节点的 next 和 random 引用指向即可
代码:
/*
// Definition for a Node.
class Node {
public:
int val;
Node* next;
Node* random;
Node(int _val) {
val = _val;
next = NULL;
random = NULL;
}
};
*/
class Solution {
public:
Node* copyRandomList(Node* head) {
unordered_map<Node* ,Node*> m;
Node* cur=head;
while(cur!=NULL){ //复制各节点,并建立 “原节点 -> 新节点” 的 Map 映射
m[cur]=new Node(cur->val);
cur=cur->next;
}
cur=head;
while(cur!=NULL){ //将新就链表的指针指向规则给新链表附上
m[cur]->next=m[cur->next];
m[cur]->random=m[cur->random];
cur=cur->next;
}
return m[head];
}
};
备注:1.哈希映射 m[cur]->next=m[cur->next]; 代表将原链cur指向节点的下一个节点连上新链next(即完成一组next关系的赋值)
2. map与unordered_map的区别
map
优点:
1.有序性,这是map结构最大的优点,其元素的有序性在很多应用中都会简化很多的操作;
2.红黑树,内部实现一个红黑树使得map的很多操作在O(lgn)的时间复杂度下就可以实现,因此效率非常的高。
缺点:空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点、孩子节点和红/黑性质,使得每一个节点都占用大量的空间
应用场景:对于那些有顺序要求的问题,用map会更高效一些
unordered_map
优点:因为内部实现了哈希表,因此其查找速度非常的快
缺点:哈希表的建立比较耗费时间
应用场景:对于查找问题,unordered_map会更加高效一些,因此遇到查找问题,常会考虑一下用unordered_map















 392
392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









