







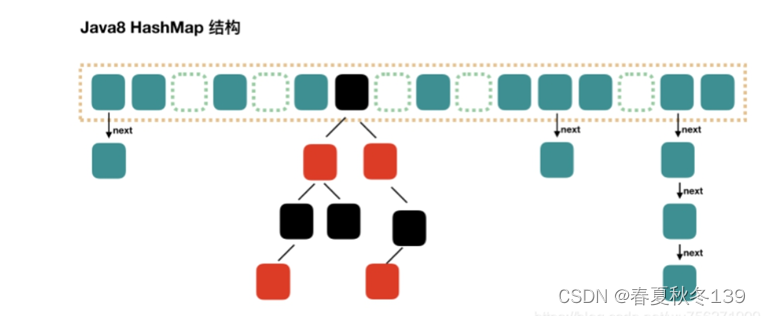
1. Jdk8数组+链表或者数组+红黑树实现,当链表中的元素超过了 8 个 数组大小超过64以后, 会 将链表转换为红黑树,当红黑树节点 小于 等于6 时又会退化为链表。
2. 当newHashMap():底层没有创建数组,首次调用put()方法示时,底层创建长度 为16的数组,jdk8底层的数组是:Node[],用数组容量大小乘以加载因子得 到一个值,一旦数组中存储的元素个数超过该值就会调用rehash方法将数组容量增加到原来的2^x倍,专业术语叫做扩容,在做扩容的时候会生成一个新的数组,原来的所有数据需要 重新计算哈希码值重新分配到新的数组,所以扩容的操作非常消耗性能。
补充 :默认的负载因子大小为0.75,数组大小为16。也就是说,默认情况下,那么当HashMap 中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍
3. 在我们Java中任何对象都有hashcode,hash算法就是通过hashcode与自己进 行向右位移16的异或运算。这样做是为了计算出来的hash值足够随机,足够分散,还有 产生的数组下标足够随机。
map.put(k,v)实现原理
(1)首先将k,v封装到Node对象当中(节点)。
(2)先调用k的hashCode()方法得出哈希值,并通过哈希算法转换成数组的下标。
(3)下标位置上如果没有任何元素,就把Node添加到这个位置上。如果说下标对应的位 置上有链表。此时,就会拿着k和链表上每个节点的k进行equal。如果所有的equals方 法返回都是false,那么这个新的节点将被添加到链表的末尾。如其中有一个equals返回了 true,那么这个节点的value将会被覆盖。
map.get(k)实现原理
(1)、先调用k的hashCode()方法得出哈希值,并通过哈希算法转换成数组的下标。
(2)、通过数组的下标快速定位到某个位置上。如果这个位置上什么都没有则返回null,
如果这个位置上有单向链表,则会拿着参数K和单向链表上的每一个节点的K进行equals比较内容,所有的equals 都返回false 则返回空,如果参数k和单向表上的节点的k进行equals返回true 那么该value 就是get(k)寻找的value。
Hash冲突
不同对象算出来的数组下表相同就会产生hash冲突,当单线链表达到一定长度之后查询效率会变得非常低。
当链表长度大于8的时候,链表会变成红黑树,来提高查询效率。















 3932
3932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









