






掘金文章链接食用效果更加:[Java]似乎很多人搞错了HashMap红黑树退化?(图文并茂)
先省流,说结论:
HashMap去树化有两种情况
在树拆分过程中,拆完的两棵树分别判定,如果总节点<=6的话就去树化
在去除树节点时,通过一系列条件判定,一般会在树节点2-6时进行去树化
前言
之前在准备面试背八股时,看了一堆HashMap树化的东西,但是似乎没啥人讲去树化,而有的文章可能会略提一下,但是似乎解答也不统一(非引战,只做讨论)


叠甲
- 本人才疏学浅,对HashMap源码只略懂一二。如果内容有问题,请指正orz,我会第一时间去研究和修改内容,非常感谢orz。
- 本文使用Java8源码,目前最新的Java22源码几乎没有对去树化进行修改,总流程一致。
- 本文着重讲去树化,一些顶层方法如resize、put、remove并不做展开,需要读者自己can can。
正文
1. 去树化的底层方法
HashMap去树化使用的是untreeify方法,流程很简单,就是从当前的node开始,逐个使用replacementNode把树节点改为普通节点
final HashMap.Node<K,V> untreeify(HashMap<K,V> map) {
// hd 链表头 tl 链表尾
HashMap.Node<K,V> hd = null, tl = null;
// 从当前Node开始,逐个调用replacementNode将书树节点换成链表节点
for (HashMap.Node<K,V> q = this; q != null; q = q.next) {
HashMap.Node<K,V> p = map.replacementNode(q, null);
if (tl == null)
hd = p;
else
tl.next = p;
tl = p;
}
return hd;
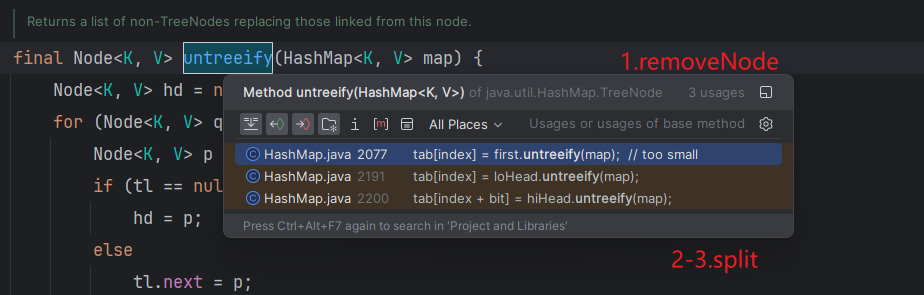
}2. 哪里会调用去树化
HashMap中有两个地方会调用去树化,这也是大部分文章中忽视的。具体的方法:removeNode和split,由于split方法是大家津津乐道的<=6去树化理论,我就先说说split方法
a. split中的去树化
split,顾名思义,就是把树撕成两棵树,至于是怎么撕为什么撕,各位八股好手应该记得resize方法中根据Node二进制头对链表和树进行拆分,这是老生常谈的玩意了,这里就不做展开。而这个过程中如果哪一棵树节点<=6,就进行去树化
具体流程
final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) {
// ...通过hash值的高位bit,分出hi,lo两条链表
// 分别判断它们长度是否<=UNTREEIFY_THRESHOLD(6)
if (loHead != null) {
if (lc <= UNTREEIFY_THRESHOLD)
tab[index] = loHead.untreeify(map);
else {
tab[index] = loHead;
if (hiHead != null) // (else is already treeified)
loHead.treeify(tab);
}
}
if (hiHead != null) {
if (hc <= UNTREEIFY_THRESHOLD)
tab[index + bit] = hiHead.untreeify(map);
else {
tab[index + bit] = hiHead;
if (loHead != null)
hiHead.treeify(tab);
}
}
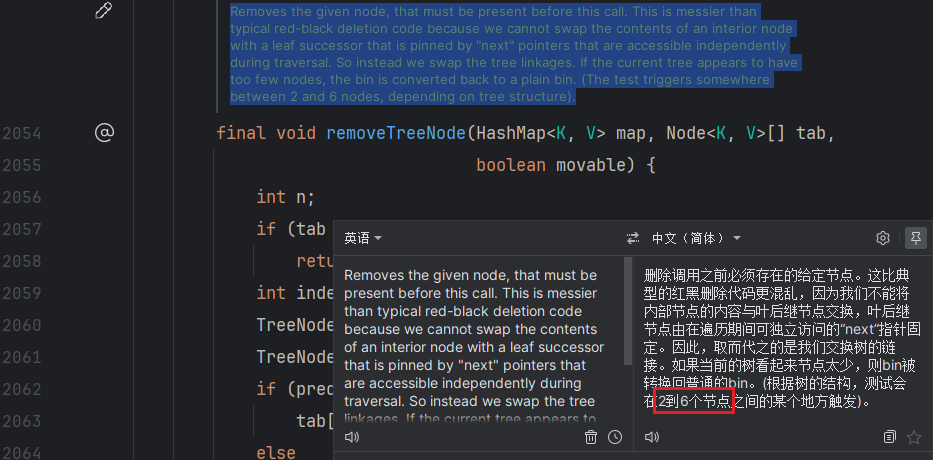
}b. removeNode中的去树化
这个方法大家其实很常用,就是remove的底层调用,而里面作者的原话:The test triggers somewhere between 2 and 6 nodes, depending on tree structure,说人话就是大概2-6个节点去树化
具体流程
final void removeTreeNode(HashMap<K,V> map, Node<K,V>[] tab,
boolean movable) {
// ... 定位出节点所在树的根节点
// 调用untreeify条件
if (root == null
|| (movable
&& (root.right == null
|| (rl = root.left) == null
|| rl.left == null))) { tab[index] = first.untreeify(map); // too small
return;
}
// ... 节点的删除/替换
}
代码中的条件root.right == null|| (rl = root.left) == null|| rl.left == null比较抽象,我画个图吧,假如图中A~C中有一个为null则条件成立(源代码这里注释了个tooSmall,后面我们就称这个条件为tooSmall情况吧)
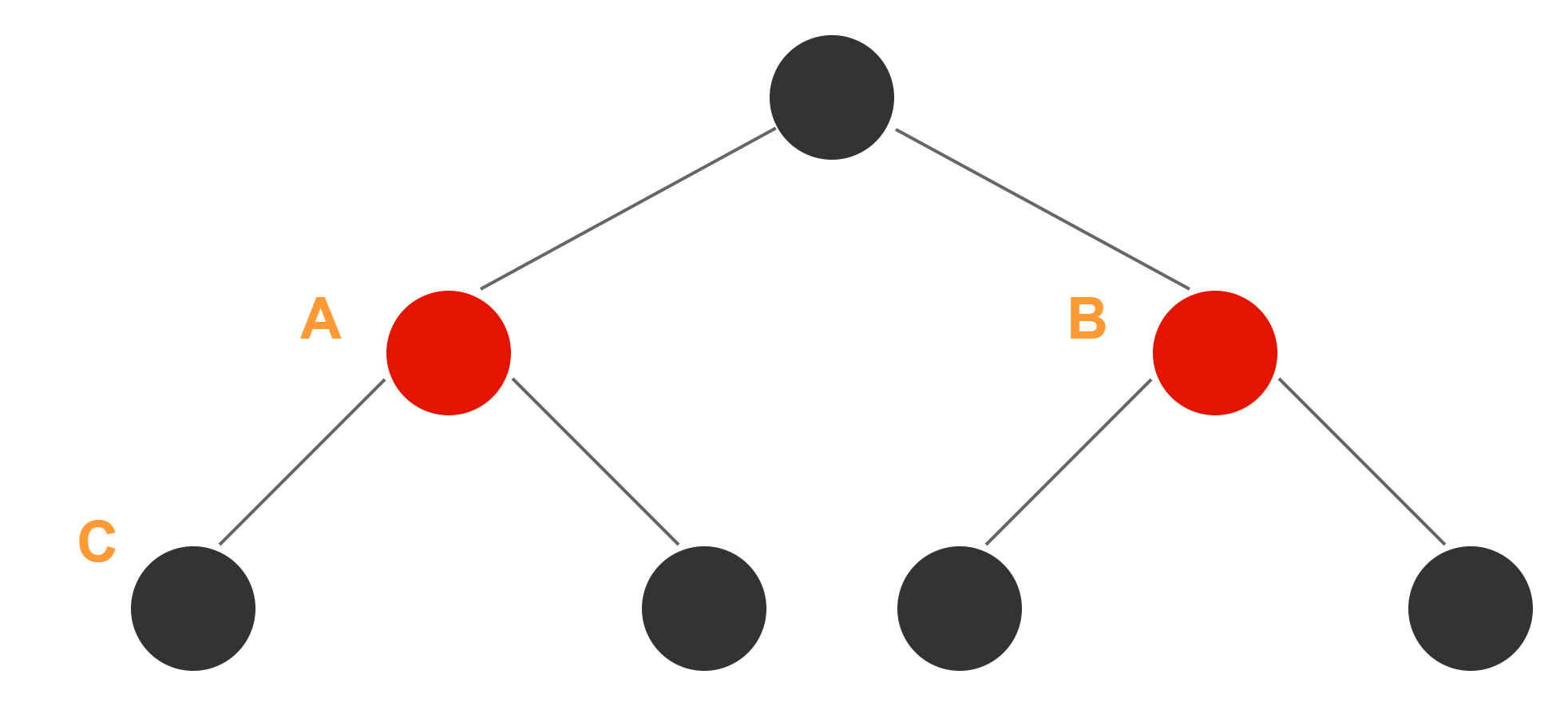
那在什么情况下条件成立呢,根据红黑树的规则
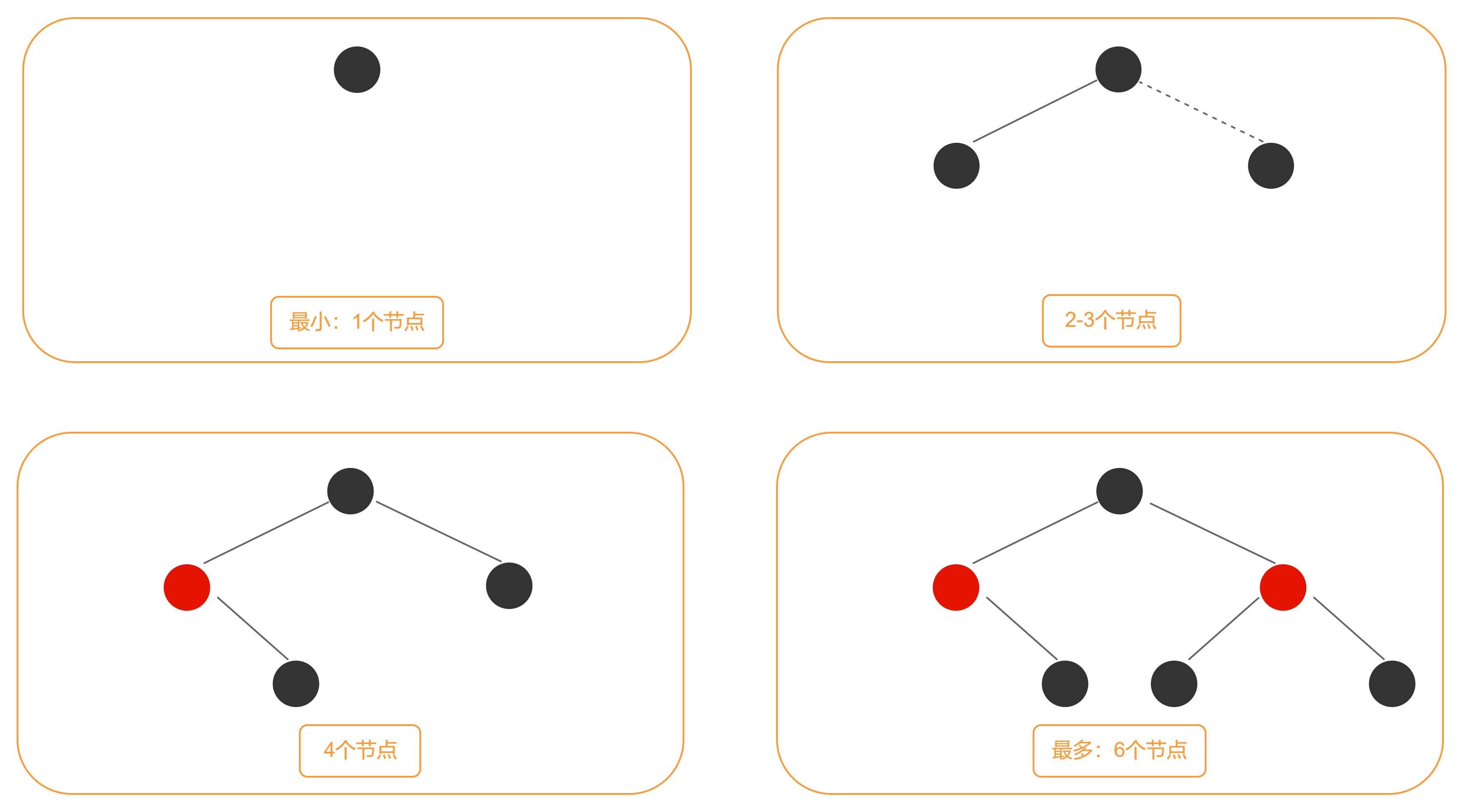
ok,到这里可以算是破案了,HashMap去树化有俩方法,而且条件不一致,难怪网上说的总是奇奇怪怪。但是,真的吗,我不信(鲁豫脸),本着实践出真知的原则,我想再实操一下
实践环节
实践内容仅为印证观点,嫌我啰嗦的小伙伴可以直接跳过
为了代码量小点,导入了lombok,小伙伴copy了代码的话可能要适配一下
感兴趣的小伙伴也可以copy代码(为了不影响观感,我把代码统一放在后面)
下面我会这两个条件分别复现split和tooSmall
1. split中出现单链<=6情况
这个场景实在是很难复现,因为我需要通过hash值相等才能让节点都落入同一个hash槽,但是在split时由于hash值一致,节点只会归到同一条链表而不是散列在两条链表中,最后的长度也不会<=6
不过没事,我还想到了个无赖方法:反射
- 重写
hashCode和equals方法,让所有node都进入到同一个hash槽,生成红黑树 - 通过反射修改节点hash值
- 插入大量无关节点,触发HashMap扩容
- 扩容中,split方法根据高位bit拆分出hiHead和loHead两条链表,而由于我把hash值改了,原本的节点会随机进入链表,最后大概率会出现<=6的情况
2. removeNode中树出现tooSmall情况
- 重写
hashCode和equals方法,让所有node都进入到同一个hash槽,并生成红黑树 - 一边删除树的节点,一边对树的情况进行打印和判断
由于这种情况可能的节点比较多,我就尝试给出最少节点和最多节点的部分操作吧
2个节点
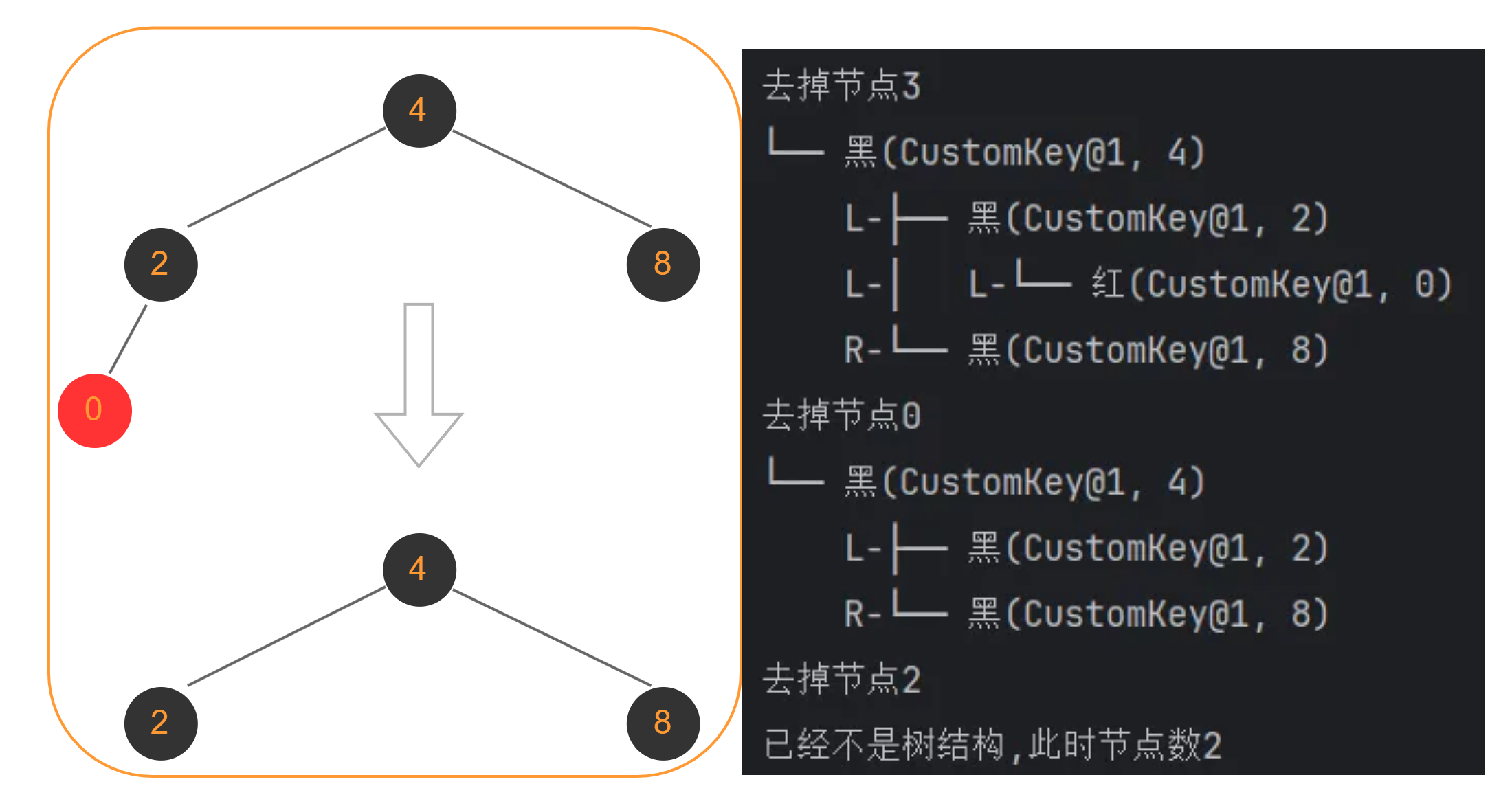
可能会有小伙伴问:画的节点不是三个吗,为什么算两个
因为是先判断条件再删除结点的,在删除节点0操作时仍然不会tooSmall,而在删除2、4、8任意一个节点时进行判断,才会触发去树化
5个节点
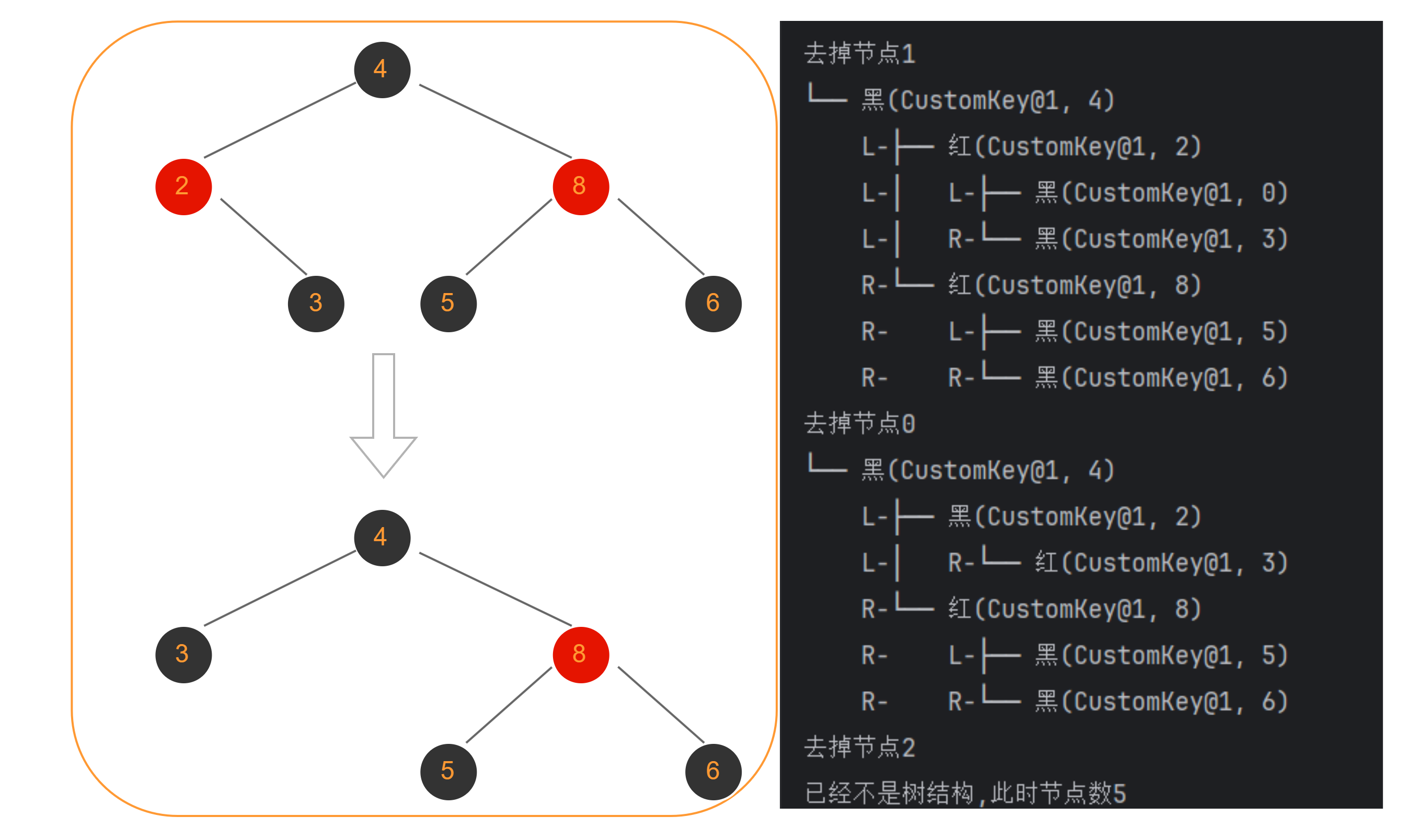
由于情景很多,我只复现了去树化时节点为2和节点为5,感兴趣的小伙伴可以copy下代码,通过debug一个一个删除节点来尝试不同的树结构
TIPS:很怪,我想不到作者提出的6个节点就去树化的情况,如果有小伙伴能够复现也可以告诉我一下嘿
总结
我个人认为网上大部分关于HashMap untreeify的观点是有待商榷的,我个人认为的话应该是这样的:
HashMap去树化有两种情况
1.在树拆分过程中,拆完的两棵树分别判定,如果总节点<=6的话就去树化
2.在去除树节点时,通过一系列条件判定,一般会在树节点2-6时进行去树化
后语
第一次写文章,没想到这么累orz,要考虑的东西太多了图片比例深浅色主题适配文案风格啥的都得想,单单写这一篇小文章就小半天过去了,实在太佩服那些写长文的大佬了。
btw有的小伙伴如果是背八股的时候看到这篇文章,可能会问这个考不考。我觉得没人会考这个的,但是我觉得不一定要面试官问你才说这个知识点,可以试着把面试官"勾引"到这个问题上来,我曾经就得手过一次:先借机点一下这个问题,接着面试官问,那刚刚这个问题你有了解过答案吗。嘿嘿,我的回合!这样感觉不仅能拿到一点面试主动权,而且个人感觉也是一个比较加分的点,能体现出你不只是八股好手,还有去深入研究过源码这样嘿嘿。
最后再叠一个甲,这是我的处女文,如果文章内容出现表达不清晰/逻辑不通/内容错误等地方,请谅解,如果你能指出问题,非常感谢orz。
















 1908
1908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









