









 本文介绍了单层感知机的基本概念,与逻辑回归的异同,包括激活函数的区别、损失函数的选择,以及其实现过程。通过实例演示了如何用Python构建并训练单层感知机,以及其在二分类问题中的应用。
本文介绍了单层感知机的基本概念,与逻辑回归的异同,包括激活函数的区别、损失函数的选择,以及其实现过程。通过实例演示了如何用Python构建并训练单层感知机,以及其在二分类问题中的应用。
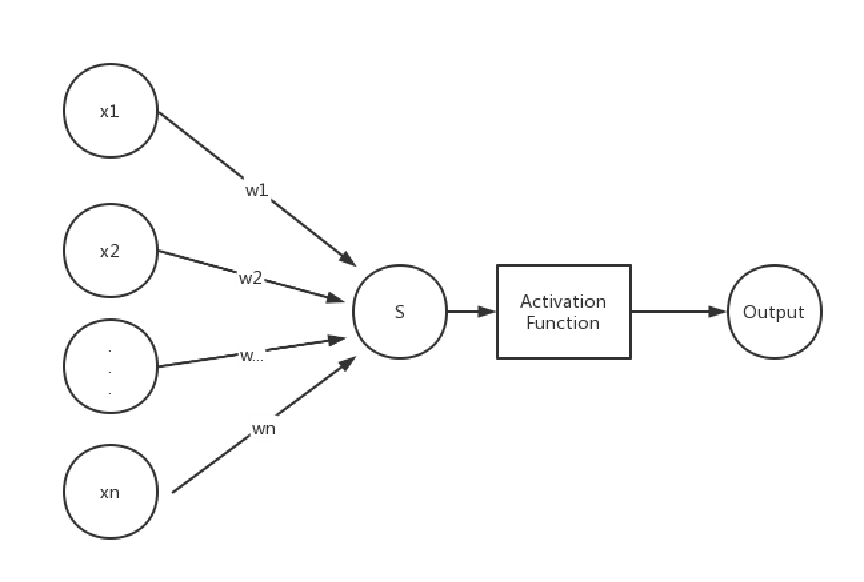
单层感知机是机器学习中最为基础的方法之一,也可以认为是一种最为简单的神经网络,其模型结构与逻辑回归是一致的,都是多个输入,乘以权值求和再加上偏置,再经过激活函数得到输出,如下图所示。
单层感知机与逻辑回归的主要不同在于激活函数与损失函数。在逻辑回归中,我们通常用sigmoid函数作为激活函数,而在单层感知机中激活函数为sign函数。由于单层感知机使用sign函数,结构较为简单,不像sigmoid 函数那样以一定概率对结果进行输出,所以单层感知机效果与逻辑回归相比较差,泛化能力很差。逻辑回归的损失函数通常选用交叉熵损失函数,也可以选用均方差损失函数,而单层感知机则是基于误分类点到超平面的距离总和来构造损失函数。
逻辑回归与单层感知机用途相同,都可以用来解决二分类问题。
算法原理
(1)前向传递过程(类别预测)
对于一组含有n个数据,p个指标的数据集X,每一组数据都对应着一个类别,这个样本一共含有两大类:A类和B类。与逻辑回归相同,我们通过这些数据训练模型,最终能够利用这个模型来对未知类别的一组数据进行类别预测。
我们以样本中的其中一组数据为例。该组数据为, 则该模型的权值向量为
。则
最终该组样本的输出为:
输出结果为+1或-1。所以我们训练过程中可以让+1代表A类,-1代表B类。这样在预测过程中,如果输出结果为+1,则输入A类,否则属于B类。
(2)训练方法
与一般的神经网络相同,我们都是通过构造损失函数,并由损失函数推导出模型中损失函数对参数w和b的梯度,利用梯度下降法从而进行参数更新。
类比三维空间点到平面距离公式,我们推广到p维空间中点x到超平面wx+b=0的距离为:
训练样本X中含有n组数据,每组数据对应p维空间中一个点。我们的目的是寻找一个超平面,能够把两类数据尽可能分割开。其中一种构造损失函数的方法是统计误分类点的个数,让误分类点的个数减少,然而该函数不是关于w,b的连续可导函数,难以训练。另一种是统计所有误分类点到超平面距离和,作为损失函数,并最小化该损失函数。设初始时超平面为w.x+b=0,n个点中误分类点个数为m。则所有误分类点到超平面的距离之和为:
对于误分类点,类y的数值与的数值符号相反,y为+1或-1,所以可以用
来替代
,达到去绝对值的目的;并且单层感知机解决线性可分问题,损失函数最终收敛到0,所以
这一项对收敛结果没有影响,可以不考虑该项。最终的损失函数简化为:
关于误分类点的选取,可以依据 与
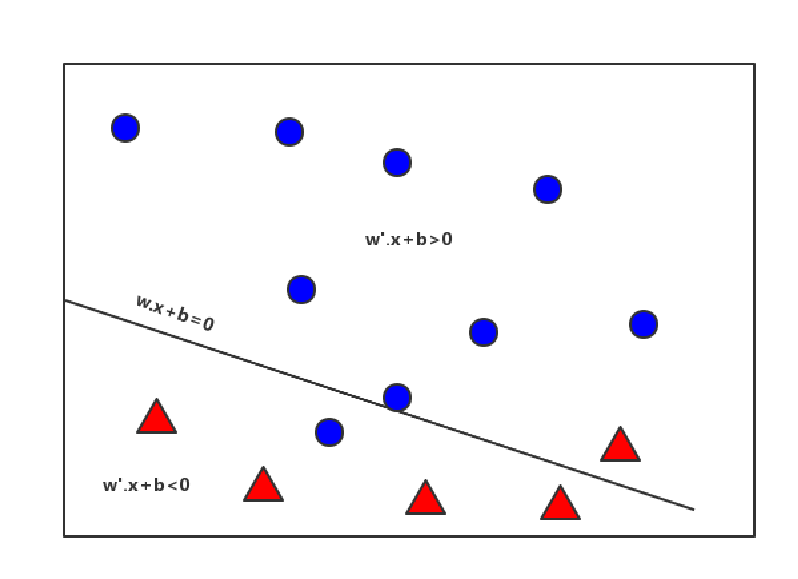
的符号来判断,如果符号相同,则不是误分类点,否则是误分类点。对于下图,右上部分其中的三角形便是一个误分类点(该三角形wx+b>0,但实际类别为-1)。
根据该损失函数Loss求其对参数w与b的导数,利用梯度下降法更新参数。推导过程需要利用矩阵求导的知识,兔兔把推导过程写在下面了。(由于b和yi都是一个数而不是向量,可以按照一元函数求导直接计算)。
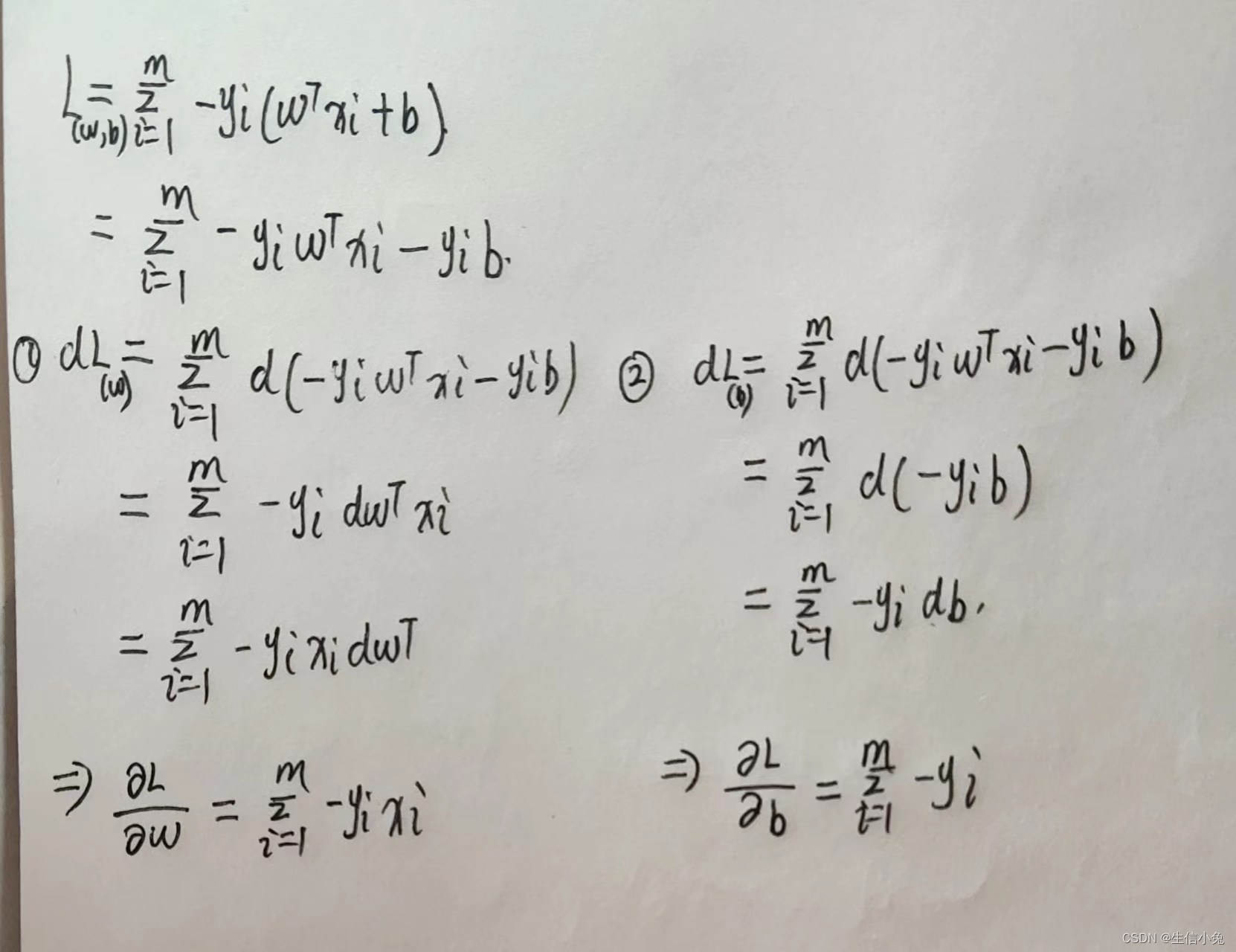
最终我们得到的结果为:
算法实现
在这里兔兔以数据集dry_bean_dataset数据集为例。为了直观体现该模型的效果,我们仅选取MajorAxisLength和MinorAxisLength两个指标,数据选取前3320组数据,此时数据集仅含有SEKER和BARBUNYA两类。数据点的分布如图所示。
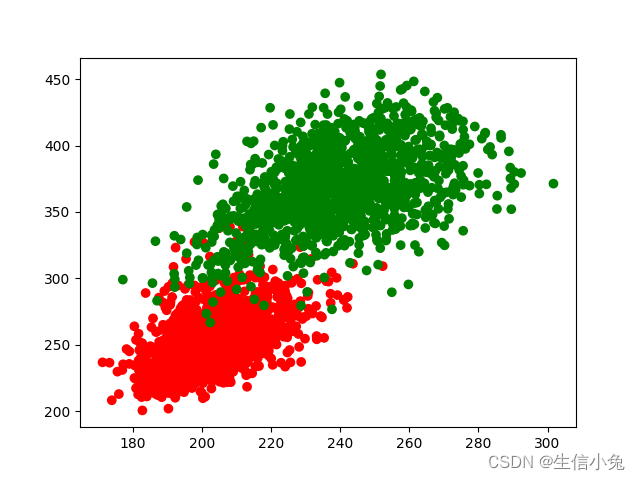
我们可以令SEKER类为+1,另一类为-1,然后才能输入到模型中进行训练。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
class perceptron:
def __init__(self,x,y,alpha=0.2,circle=100):
self.x=x #训练样本
self.y=y #训练样本中各组数据对应的类别
self.alpha=alpha #学习率
self.circle=circle #学习次数
self.n=x.shape[0] #样本个数
self.p=x.shape[1] #样本指标个数
self.w=np.random.normal(size=(self.p,1))
self.b=np.random.normal(size=1)
def sign(self,x):
'''sign激活函数'''
if x>0:
return 1
elif x<0:
return -1
else:
return 0
def train(self):
for i in range(self.circle):
print('the {} circle'.format(i))
dw=0;db=0
num=0 #误分类点的个数
for j in range(self.n):
if self.y[j]*(np.dot(self.w.T,self.x[j].T)+self.b)>=0:
continue
else:
dw+=-self.y[j]*self.x[j].T
db+=-self.y[j]
num+=1
self.w-=self.alpha*dw/num
self.b-=self.alpha*db/num
def prediction(self,x):
'''根据数据x判断该数据属于哪一类'''
s=np.dot(self.w.T,x)+self.b
output=self.sign(s)
return output
if __name__=='__main__':
df=pd.DataFrame(pd.read_csv('Dry_Bean_Dataset.csv'))
x=df.loc[0:3320,'MajorAxisLength':'MinorAxisLength']
y=df.loc[0:3320,'Class']
X=np.mat(x)
Y=[]
color=[]
for c in y:
if c=='SEKER':
color.append('red')
Y.append(1)
else:
color.append('green')
Y.append(-1)
plt.scatter(x['MajorAxisLength'],x['MinorAxisLength'],color=color)
p=perceptron(x=X,y=Y)
p.train()在该方法中,为了防止梯度下降过程中梯度爆炸的出现,在梯度下降过程中先把各个梯度求和后再除以误分类点的个数,达到减少步长的目的。但是若无误分类点,除以0会出现报错的情况,此时也可以在算法中加入判断误分类点个数是否为0的情况,如果为0,就不进行参数更新。
在数据较少(如几十组数据)时,可以使用所有数据进行训练;对于数据较多的情况(几千甚至几万以上),用所有数据进行训练速度会很慢,效果也很差,所以可以采用随机梯度下降法,每次从中选取部分数据进行训练。代码改进如下:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
class perceptron:
def __init__(self,x,y,alpha=0.001,circle=500,batchlength=20):
self.x=x #训练样本
self.y=y #训练样本中各组数据对应的类别
self.alpha=alpha #学习率
self.circle=circle #学习次数
self.n=x.shape[0] #样本个数
self.p=x.shape[1] #样本指标个数
self.w=np.random.normal(size=(self.p,1))
self.b=np.random.normal(size=1)
self.batchlength=batchlength #每次训练样本中使用的数据个数
def batches(self):
data=list(zip(self.x,self.y))
np.random.shuffle(data)
batches=[data[i:i+self.batchlength] for i in range(0,self.n,self.batchlength)]
return batches
def sign(self,x):
'''sign激活函数'''
if x>0:
return 1
elif x<0:
return -1
else:
return 0
def train(self):
for i in range(self.circle):
print('the {} circle'.format(i))
for batch in self.batches():
dw = 0;db = 0
num = 1
for x,y in batch:
if y*(np.dot(self.w.T,x.T)+self.b)>=0:
continue
else:
dw+=-y*x.T
db+=-y
num+=1
if num !=0:
self.w-=self.alpha*dw/num
self.b-=self.alpha*db/num
else:
continue
color=[]
for c in self.y:
if c==1:
color.append('green')
else:
color.append('red')
x=np.arange(180,470,1)
y=-self.w[0]*x/self.w[1]-self.b/self.w[1] #分割线
plt.plot(x,y)
plt.scatter(np.array(self.x[:,0]),np.array(self.x[:,1]),color=color)
plt.xlim([180,470])
plt.ylim([160,320])
plt.pause(0.1)
plt.clf()
def prediction(self,x):
'''根据数据x判断该数据属于哪一类'''
s=np.dot(self.w.T,x)+self.b
output=self.sign(s)
return output
if __name__=='__main__':
df=pd.DataFrame(pd.read_csv('Dry_Bean_Dataset.csv'))
x=df.loc[0:3320,'MajorAxisLength':'MinorAxisLength']
y=df.loc[0:3320,'Class']
X=np.mat(x)
Y=[]
for c in y:
if c=='SEKER':
Y.append(1)
else:
Y.append(-1)
p=perceptron(x=X,y=Y)
p.train()由于分割的超平面方程为,在这里指标个数为2,所以对式子进行化简,得到对应平面内的直线方程为:
(其中w=(wo,w1),x=(x,y))。最终的运行结果如下。
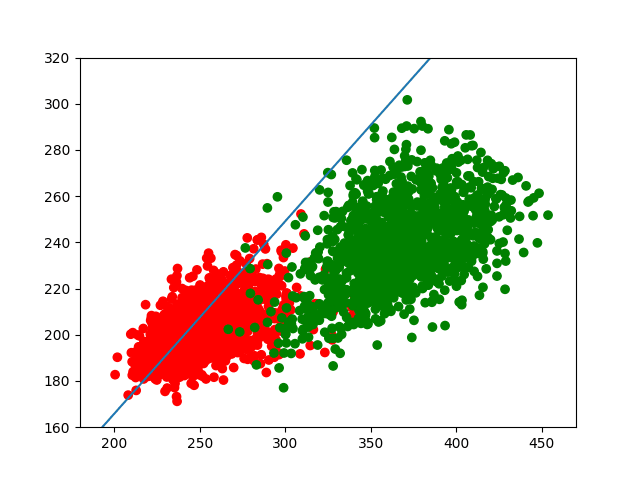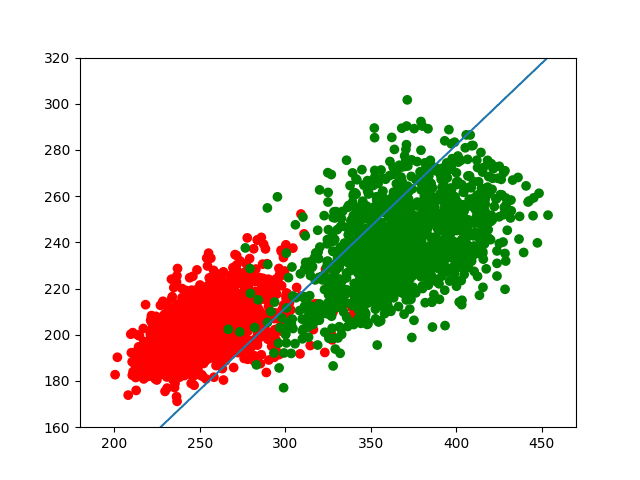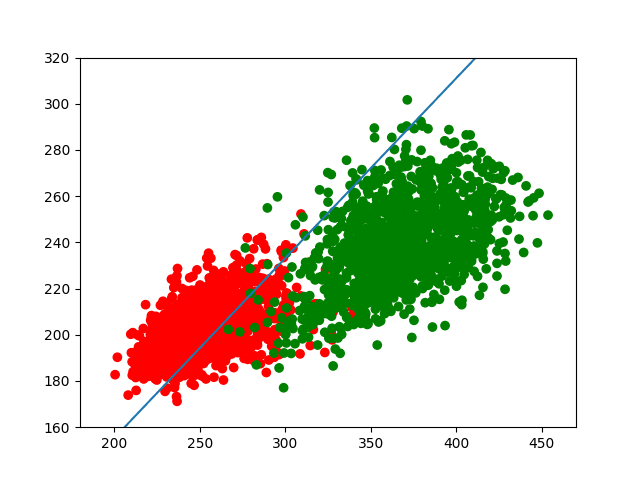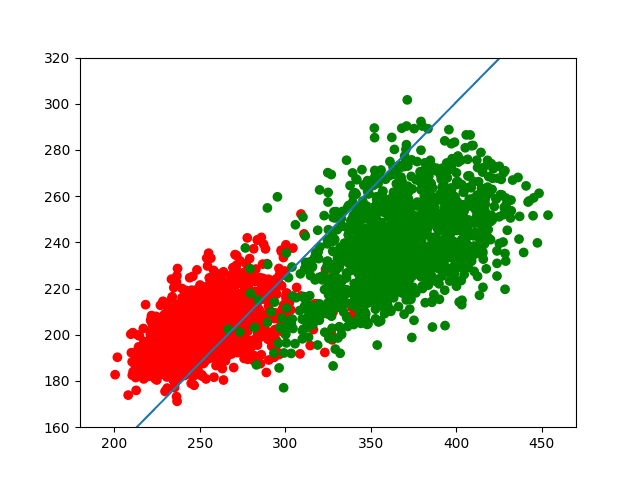
我们发现,该直线能够较好地把两部分分开,但由于两类数据有较大的重叠部分,所以也很难完全分开。
总结
关于单层感知机,其结构与逻辑回归(LR)是一致的,但是效果与逻辑回归相比较差。由多个这样的单层感知机结构组合在一起可以组成多层感知机,或者是深度神经网络结构。单层感知机或是逻辑回归等这些神经网络虽然结构十分简单,却是其它更为复杂的神经网络的基础,在学习时需要掌握数据在模型中的计算过程、损失函数构造方法、利用损失函数求梯度并利用梯度下降等优化方法更新参数方法。
补充:
在本篇文章中,需要掌握矩阵求导、常见激活函数、梯度下降系列算法等知识,这些知识点若不清楚可以参考兔兔以往的几篇文章或其它相关文章。关于单层感知机的模型,可以参考逻辑回归,在学习过程中体会二者的相同与不同之处。
1:激活函数(activation function)的种类与应用
如果感兴趣的话,也可以尝试使用动量梯度下降等优化方法,甚至牛顿法也可以(但是牛顿法计算量较大,训练时间长)。对于其中的激活函数,也可以采用其它种类的激活函数,并尝试构造不同的损失函数并求梯度进行训练(不过此时该模型应该就不能称作是单层感知机了)。


















 372
372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











