






Hystrix是springcloud中的重要组件,是奈菲公司推出的一个隔离措施,可以设置在某种超时或者失败情形下断开依赖调用或者返回指定逻辑,从而提高分布式系统的稳定性。
先介绍一下服务雪崩、服务降级和服务熔断:
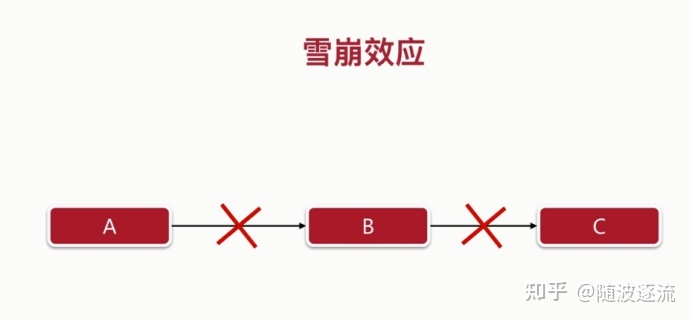
服务雪崩:其实和redis缓存雪崩类似,顾名思义,雪花堆积过多而导致整片雪崩。当多个微服务之间调用的时候,假设服务A调用微服务B 和微服务C,微服务B 和微服务C 又调用其他的微服务,这就是所谓的“扇出”,如果扇出的链路上某个微服务的调用响应时间过长或者不可用,对微服务A 的调用就会占用越来越多的系统资源,进而引起系统崩溃,所谓的“雪崩效应”。也就是当多个服务同时调用时,没有及时响应,会形成一个堆积,会一直在等待,连接有没有释放,这样导致接口无法访问,比如双十一抢购时,几百万用户同时访问,这时服务肯定都没办法响应了。
服务降级:当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略地降级,以此释放资源以保证核心任务的正常运行。也就是说,当整个微服务整体的负载超出了预设的上限阈值或即将到来的流量预计将会超过预设的阈值时,为了保证重要或基本的服务能正常运行,我们可以将一些不重要或不紧急的服务或任务进行服务的延迟使用或暂停使用。
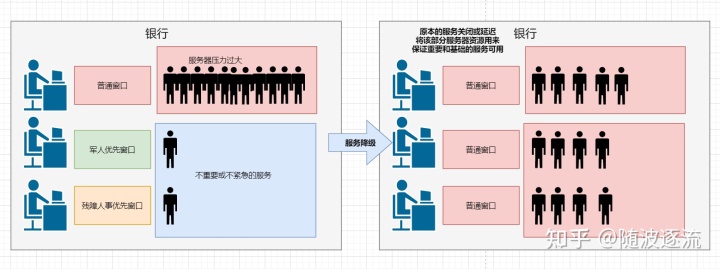
举个例子,在银行中,有很多个服务窗口可以办理业务,其中也有特殊窗口(比如军人优先,残障人士优先的窗口),当银行来了很多人进行办理业务(服务器压力剧增,服务器负载超过了上限阈值),普通窗口已经排了很多人了。这时候,银行会暂时地关闭或延迟特殊窗口的服务,将特殊窗口变成普通窗口来办理所有人的业务,待到银行中办理业务的人不那么多时(下降到上限阈值以下)(将一些不重要或不紧急的服务或任务进行延迟使用或暂停使用),这就是服务降级。
上代码
1.先导入依赖
<!-- Hystrix -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
2.在入口处加上注解
@SpringBootApplication
@EnableEurekaClient
@EnableCircuitBreaker3.编写接口
值得一提的是,在打上@HystrixCommand注解后还会默认提供超时服务,默认时间为1秒钟,当请求超过一秒时会自动做降级处理
@GetMapping("hystrixTest")
// @HystrixCommand(fallbackMethod = "defaultFallBack") // 默认降级处理
@HystrixCommand(fallbackMethod = "testFallBack") // 自定义降级处理
public String hystrixTest() throws Exception {
// 主动制造异常 模仿微服务整体的负载超出了预设的上限阈值
throw new Exception();
}
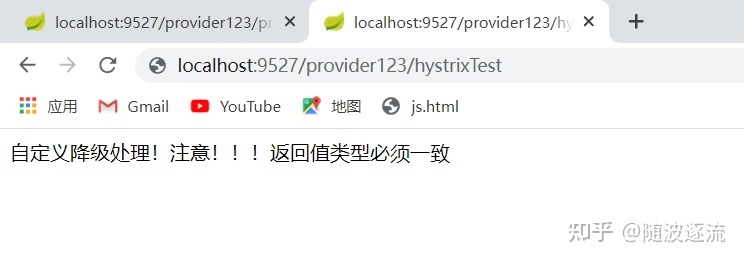
public String testFallBack() {
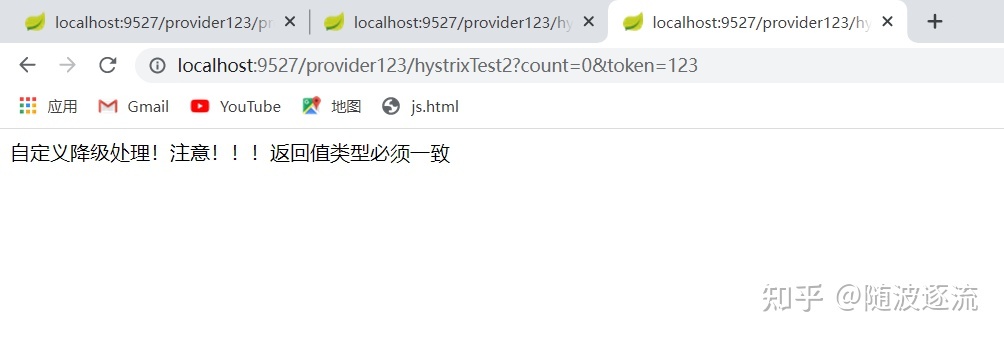
return "自定义降级处理!注意!!!返回值类型必须一致";
}此时访问该接口
不止是返回值类型不一样时,降级处理会失效,方法参数不同也会失效
服务熔断
熔断机制是对应雪崩效应的一种微服务链路保护机制。当扇出链路的某个微服务不可用或者响应时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回错误的响应信息。当检测到该节点微服务调用响应正常后恢复调用链路。有点儿像股市的熔断机制,当指数触及熔断阈值时暂时停止所有的交易。而我们这里是暂时停止所有的接口访问。在 SpringCloud框架里熔断机制通过 Hystrix 实现。Hystrix 会监控微服务间调用的状况,当失败的调用到一定阈值,缺省是5秒内20此调用失败就会启动熔断机制。
上代码
@GetMapping("hystrixTest2")
@HystrixCommand(commandProperties = {
@HystrixProperty(name="circuitBreaker.enabled",value = "true"), // 是否开启熔断机制
@HystrixProperty(name="circuitBreaker.requestVolumeThreshold",value = "10"), //短路期的最小请求数
@HystrixProperty(name="circuitBreaker.sleepWindowInMilliseconds",value = "5000"), // 时间
@HystrixProperty(name="circuitBreaker.errorThresholdPercentage",value = "60") // 百分比
}) // 自定义降级处理
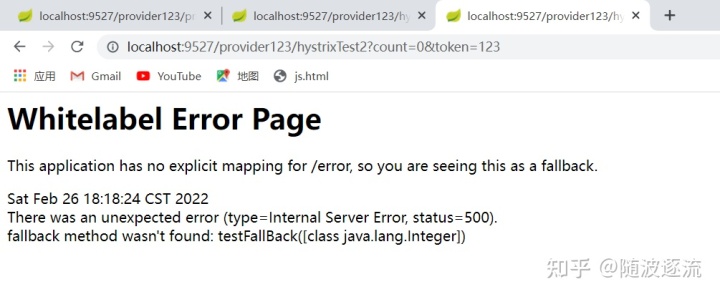
public String hystrixTest2(Integer count) throws Exception {
if(count == 0){
// 主动制造异常
throw new Exception();
}
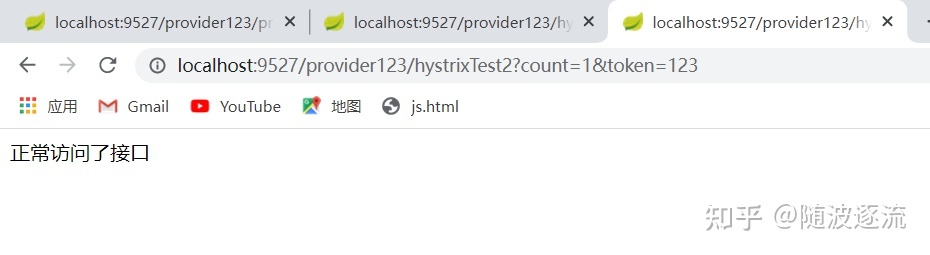
return "正常访问了接口";
}
此时接口可以正常访问,即使出错也不影响后续线程访问。但是当请求错误的数量达到熔断机制的阈值时,会自动开启熔断机制,在指定的时间内,停止该接口的访问
正常访问接口
异常访问接口(触发了服务降级)
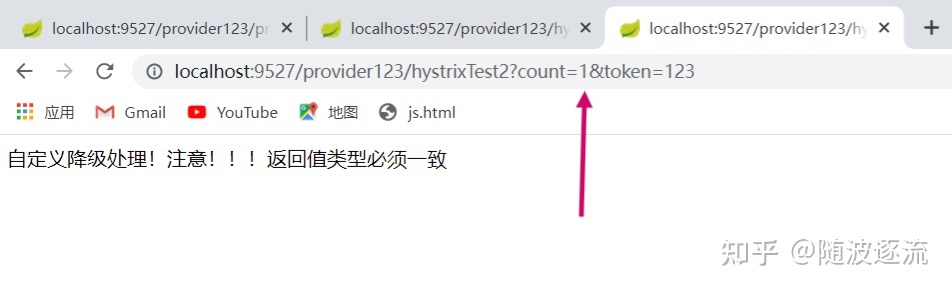
此时该接口仍可正常访问,但是当访问异常次数达到熔断机制的阈值时,在指定时间内该接口无法访问
测试:此时count为0触发异常,访问过多触发熔断机制,在此发送count为1的正常无错的请求也不行
此时有没有觉得服务熔断与服务降级不好区分,其实他们之间的区别还是比较大的,降级是处理后台的错误,对错误信息进行处理,然后返回给前端,是处理错误的一个机制;而熔断是一种预防措施,防止错误的请求过多而占用资源带来的影响,它们之间并不冲突。
回过头来在了解一下Hystrix设计原则
- 防止单个服务的故障,耗尽整个系统服务的容器(比如tomcat)的线程资源,避免分布式环境里大量级联失败。通过第三方客户端访问(通常是通过网络)依赖服务出现失败、拒绝、超时或短路时执行回退逻辑
- 用快速失败代替排队(每个依赖服务维护一个小的线程池或信号量,当线程池满或信号量满,会立即拒绝服务而不会排队等待)和优雅的服务降级;当依赖服务失效后又恢复正常,快速恢复
- 提供接近实时的监控和警报,从而能够快速发现故障和修复。监控信息包括请求成功,失败(客户端抛出的异常),超时和线程拒绝。如果访问依赖服务的错误百分比超过阈值,断路器会跳闸,此时服务会在一段时间内停止对特定服务的所有请求
- 将所有请求外部系统(或请求依赖服务)封装到HystrixCommand或HystrixObservableCommand对象中,然后这些请求在一个独立的线程中执行。使用隔离技术来限制任何一个依赖的失败对系统的影响。每个依赖服务维护一个小的线程池(或信号量),当线程池满或信号量满,会立即拒绝服务而不会排队等待















 71
71











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









