






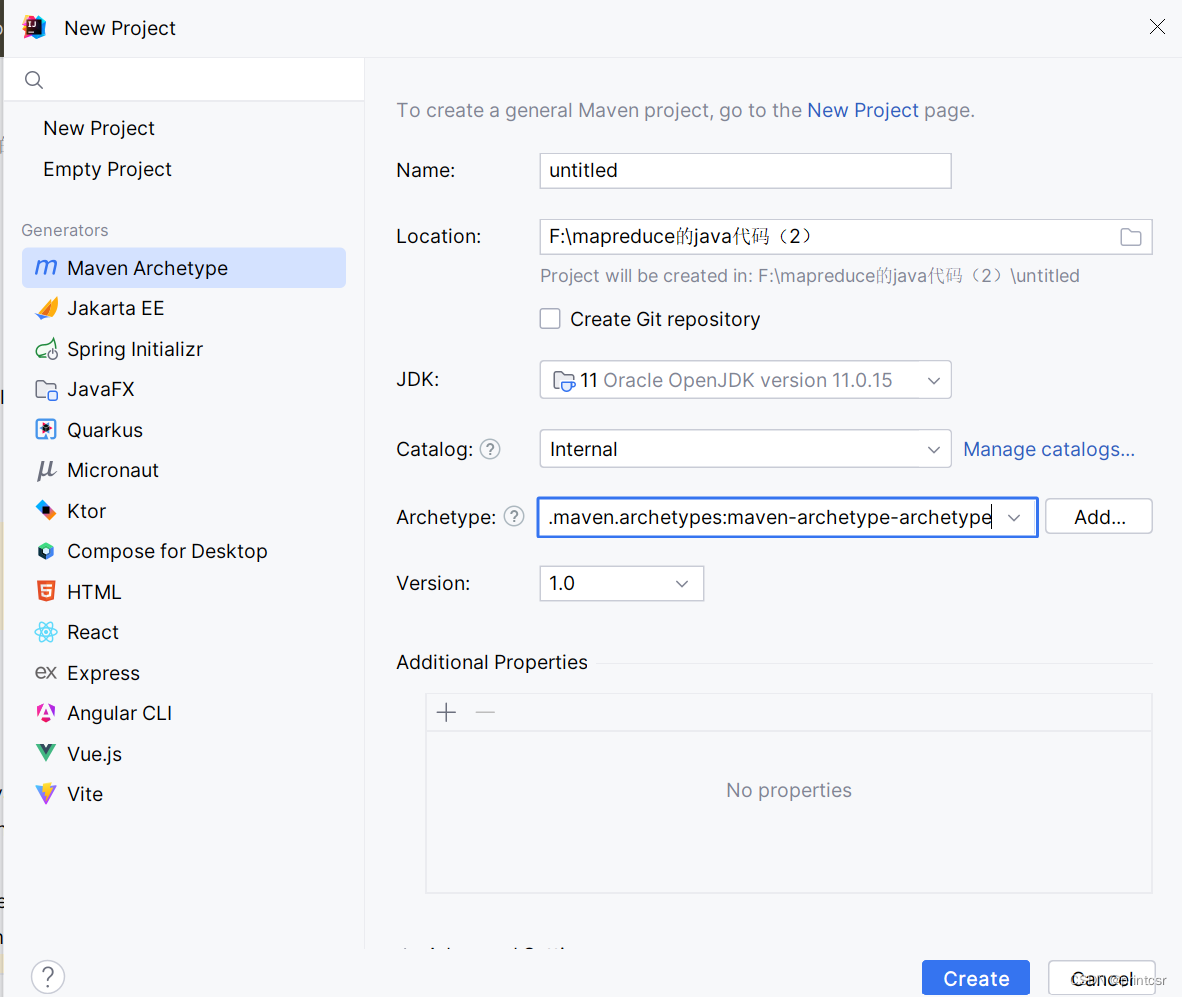
1.同hdfs 的java api,我们首先要在IDE中建立一个maven项目
pom.xml中配置如下:
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>3.3.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>3.3.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.4</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
</dependencies>---------------------------------------------------------------------------------------------------------------------------------
2. 编写java 代码,重写map与reduce类(我们以最经典的wordcount为例)
第一步,建立java目录,建立一个叫test的包(可写可不写,看自己喜好)
第二步,导入hadoop包,以及其他所需的包
package test;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;第三步,重写map,resuce方法
1.map方法,目的在于切割文章内容为一对对键值对,实现map-reduce中的map过程
class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
//前两个为输入类型,第一个数据类型表示首行偏移量;后两个为输出类型,输出为键值对类型
private final static IntWritable one = new IntWritable(1);
//IntWritable实例对象初始化为1
private Text word = new Text();
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
String line = value.toString();
//将待测信息转化为字符串
StringTokenizer tokenizer = new StringTokenizer(line);
//以空格区分
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}2.reduce方法,目的在于处理map方法切割过的数据,实现reduce过程
class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
//前两个为map输出结果类型,后两个为reduce输出结果
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
//开始计数,为每一个键统计对应的值
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}3.编写主函数,利用作业类引入map与reduce类
public class wordcount {
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(wordcount.class);
conf.setJobName("my_word_count");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}4.打包为jar文件
filr -> project structure -> artifacts -> + -> jar
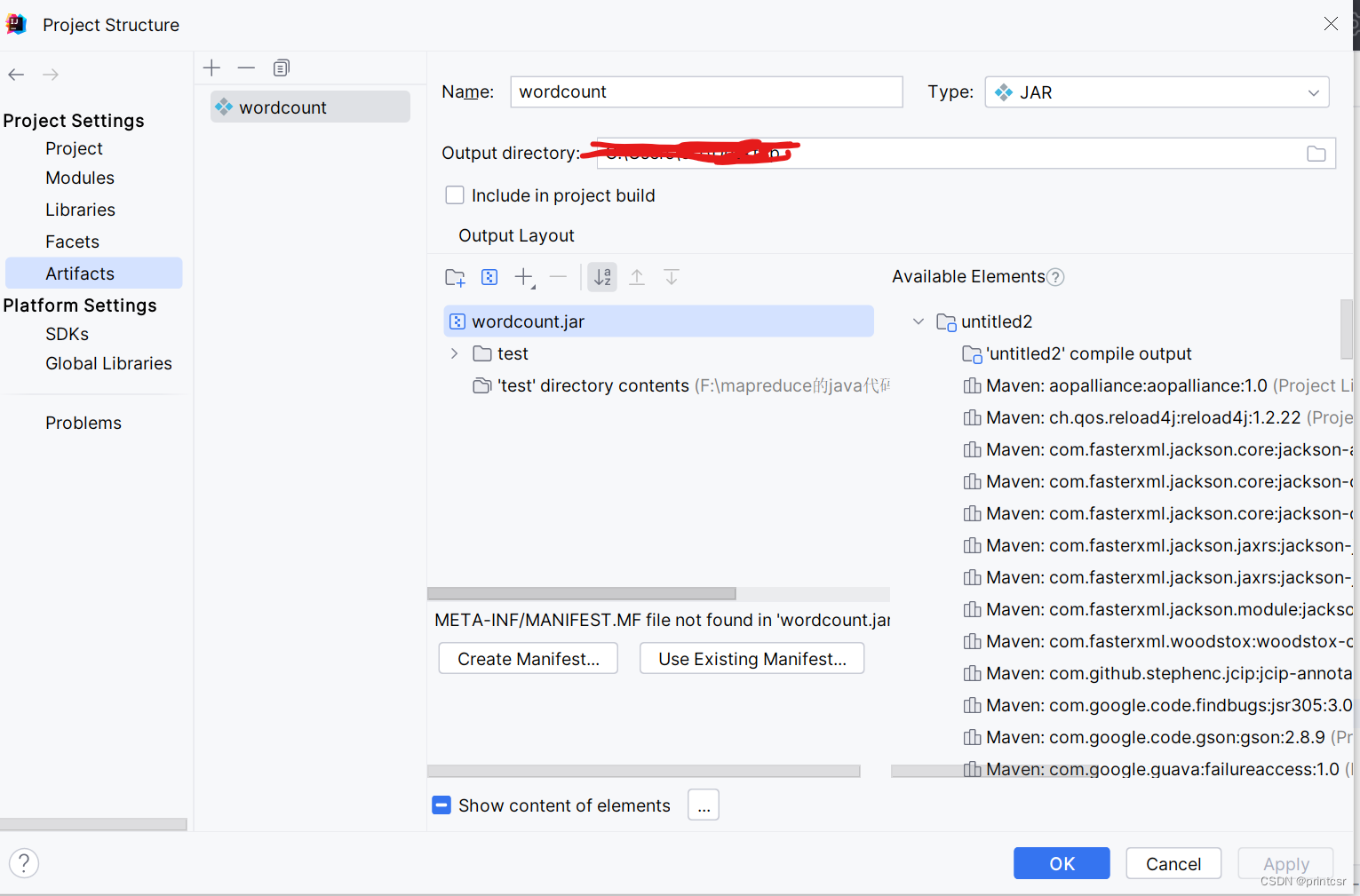
按java包的结构,新建dictionary,必须一模一样!然后在合适的包下面,导入这三个文件
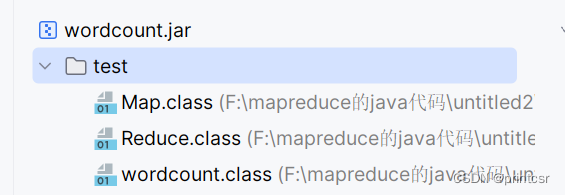
完成配置后,点击ok,再次点击Build Artifacts
完成后,在output dictionary中设置的地址中可以找到jar包,比如我设置的是桌面,那么就将在桌面找到jar包
---------------------------------------------------------------------------------------------------------------------------------
3.导入hadoop主虚拟机
使用xshell中rz指令,将jar包导入到虚拟机中,输入ls检查是否上传成功
确保hdfs目录中已经存在待检测的文件,在这里我的待测文件名叫做input,jar包所在的位置是/home/hadoop,所以对应的指令就是:
hadoop jar /home/hadoop/wordcount.jar test.wordcount /input /output因为我的jar包没有打包MANIFEST.MF文件,所以必须要使用test.wordcount即包名+主类名的方法来定位主类,如果你上一步已经打包了,那就无需这个指令。结果将输出hdfs中output文件夹下,所以执行这一步之前必须保证hdfs中不存在一个叫ouput的文件夹。可以采用50070端口监控文件

使用cat命令查看统计结果:
hadoop fs -cat /output/part-00000这里的part-00000是output文件夹中统计文件文件名,以自己ouput文件夹中文件名为准

那么,这就代表着我们的程序运行正确且成功了!















 3063
3063











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









