






一、如何进行元素定位
1.1.元素定位作用
让程序操作指定元素,就必须先找到此元素
1.2.html页面组成格式

1.3.元素定位的概念
元素定位就是通过元素的信息或元素层级结构来定位元素的。
二、浏览器开发者工具
2.1.作用
快速定位元素,查看元素信息
2.2.谷歌浏览器的开发者工具
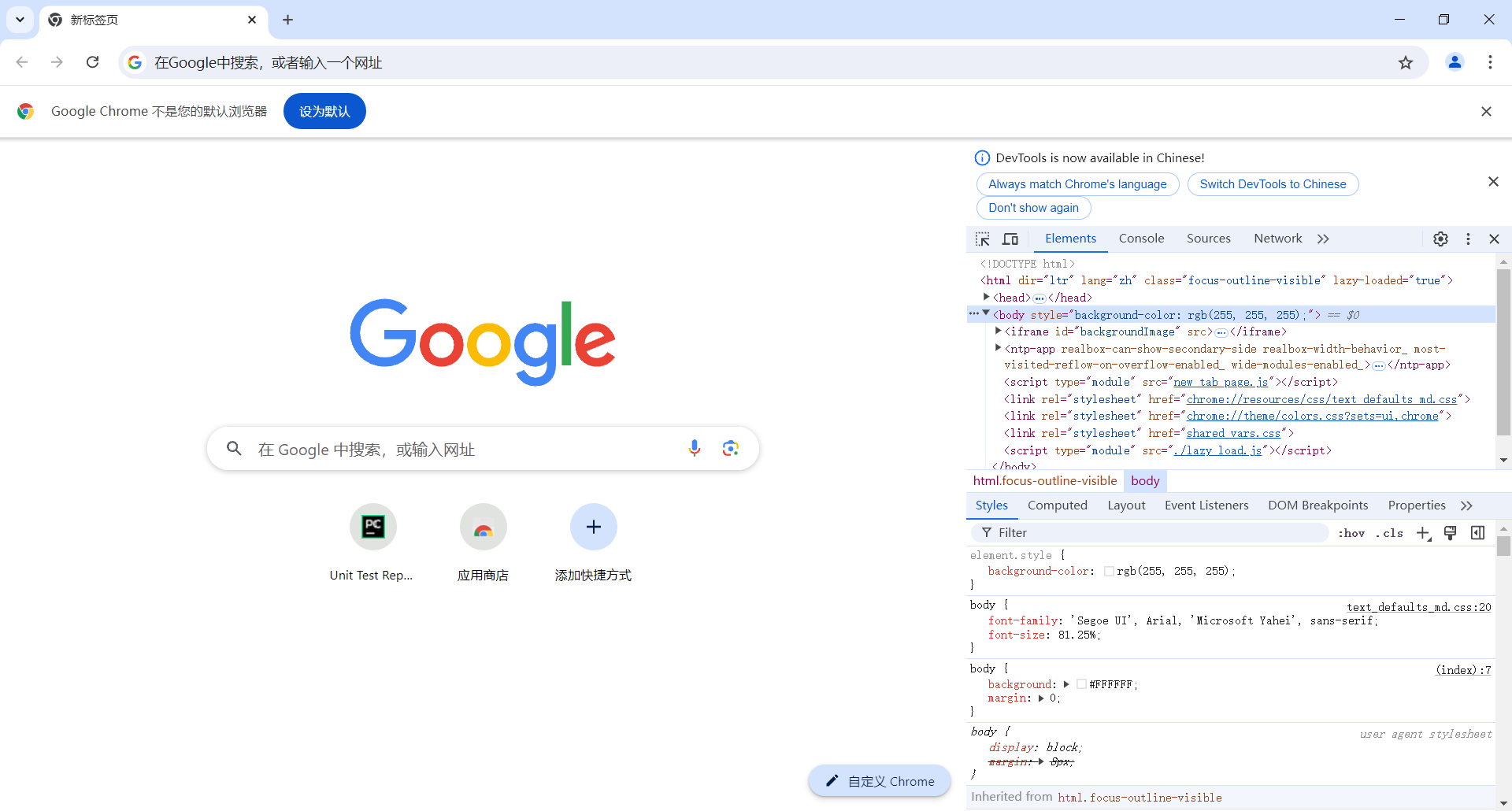
三、定位元素依赖因素
1).标签名
2).属性
3).层级
4).路径
四、元素定位方式
4.1.id定位
1).说明:id定位就是通过元素的id属性来定位元素,HTML规定id属性在整个HTML文档中必须是唯一的
2).前提:元素有id属性
3).id定位方法:element=driver.find_element(By.lD,id)
4).代码实现步骤
4.1).导包
4.2).获取浏览器驱动对象
4.3).打开url
4.4).查找对应的对象
# 导包
from selenium import webdriver
from time import sleep
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 获取浏览器对象
chromedriver_path = r"C:\Program Files\Google\Chrome\Application\chromedriver.exe"
service = Service(executable_path=chromedriver_path)
driver = webdriver.Chrome(service=service)
def main():
# 打开页面
driver.get("网页地址")
# # 查找用户名元素
# # 已过时
# # username = driver.find_element_by_id("username1")
# # 推荐使用
# username = driver.find_element(By.ID, "username1")
#
# # 查找密码元素
# # 已过时
# # password = driver.find_element_by_id("password")
# # 推荐使用
# password = driver.find_element(By.ID, "password")
#
# # 用户名输入admin send_keys("内容")
# username.send_keys("admin")
#
# # 密码输入123456
# password.send_keys("123456")
# 查找元素和输入可以合为一步
driver.find_element(By.ID, "username1").send_keys("admin")
driver.find_element(By.ID, "password").send_keys("123456")
# 睡眠3秒钟
sleep(3)
# 关闭浏览器
driver.quit()
if __name__ == '__main__':
main()4.2.name定位
1).说明:name定位就是根据元素name属性来定位元素,HTML文档中name的属性值是可以重复的
2).前提:元素有name属性
3).name定位方法:element=driver.find_element(By.NAME,name)
4).代码实现步骤
4.1).导包
4.2).获取浏览器驱动对象
4.3).打开url
4.4).查找对应的对象
# 导包
from selenium import webdriver
from time import sleep
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 获取浏览器对象
chromedriver_path = r"C:\Program Files\Google\Chrome\Application\chromedriver.exe"
service = Service(executable_path=chromedriver_path)
driver = webdriver.Chrome(service=service)
def main():
# 打开页面
driver.get("网页地址")
# # 查找用户名元素
# # 已过时
# # username = driver.find_element_by_name("username")
# # 推荐使用
# username = driver.find_element(By.NAME,"username")
#
# # 查找密码元素
# # 已过时
# # password = driver.find_element_by_name("command")
# # 推荐使用
# password = driver.find_element(By.NAME, "command")
#
# # 用户名输入admin send_keys("内容")
# username.send_keys("admin")
#
# # 密码输入123456
# password.send_keys("123456")
# 查找元素和输入可以合为一步
driver.find_element(By.NAME, "username").send_keys("admin")
driver.find_element(By.NAME, "command").send_keys("123456")
# 睡眠3秒钟
sleep(3)
# 关闭浏览器
driver.quit()
if __name__ == '__main__':
main()4.3.class_name定位
1).说明:clasS_name定位就是根据元素class属性来定位元素,HTML通过使用class来定义元素的样式
2).前提:元素有class属性
3).注意:如果class有多个属性值,只能使用其中一个
4).class_name定位方法:element= driver.find_element(By.CLASS_NAME,class_name)
5).代码实现步骤
5.1).导包
5.2).获取浏览器驱动对象
5.3).打开url
5.4).查找对应的对象
# 导包
from selenium import webdriver
from time import sleep
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 获取浏览器对象
chromedriver_path = r"C:\Program Files\Google\Chrome\Application\chromedriver.exe"
service = Service(executable_path=chromedriver_path)
driver = webdriver.Chrome(service=service)
def main():
# 打开页面
driver.get("网页地址")
# # 查找用户名元素
# # 已过时
# # username = driver.find_element_by_class_name("text")
# # 推荐使用
# username = driver.find_element(By.CLASS_NAME,"text")
#
# # 查找密码元素
# # 已过时
# # password = driver.find_element_by_class_name("textarea")
# # 推荐使用
# password = driver.find_element(By.CLASS_NAME, "textarea")
#
# # 用户名输入admin send_keys("内容")
# username.send_keys("admin")
#
# # 密码输入123456
# password.send_keys("123456")
# 查找元素和输入可以合为一步
driver.find_element(By.CLASS_NAME, "text").send_keys("admin")
driver.find_element(By.CLASS_NAME, "textarea").send_keys("123456")
# 睡眠3秒钟
sleep(3)
# 关闭浏览器
driver.quit()
if __name__ == '__main__':
main()4.4.tag_name定位(了解)
1).说明
1tag_name定位介绍通过标签名来定位
1.2).HTML本质介绍由不同的tag组成,每一种标签一般在页面中会存在多个,所以不方便进行精确定位
1.3).一般很少使用
2).tag_name定位方法:element =driver.find_element(By.TAG_NAME,tag_name)
3).注意:如果存在多个相同标签,则返回符合条件的第一个标签
4).代码实现步骤
4.1).导包
4.2).获取浏览器驱动对象
4.3).打开url
4.4).查找对应的对象
"""
需求:
使用tag_name定位方式,输入用户ID为admin
方法:
element =driver.find_element(By.TAG_NAME,tag_name) #定位元素方法
"""
# 导包
from selenium import webdriver
from time import sleep
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 获取浏览器对象
chromedriver_path = r"C:\Program Files\Google\Chrome\Application\chromedriver.exe"
service = Service(executable_path=chromedriver_path)
driver = webdriver.Chrome(service=service)
def main():
# 打开页面
driver.get("网页地址")
# # 查找用户ID元素
# # 已过时
# # username = driver.find_element_by_tag_name("input")
# # 推荐使用
# username = driver.find_element(By.TAG_NAME,"input")
# 查找元素和输入可以合为一步
driver.find_element(By.TAG_NAME, "input").send_keys("admin")
# 睡眠3秒钟
sleep(3)
# 关闭浏览器
driver.quit()
if __name__ == '__main__':
main()4.5.link_text定位
1).说明:定位超链接标签
2).link_text定位方法:element=driver.find_element(By.LINK_TEXT,"标签内容”)
3).注意
3.1).只能定位a标签
3.2).link_text定位元素内容必须全部匹配(没有全部匹配会报错)
4).代码实现步骤
4.1).导包
4.2).获取浏览器驱动对象
4.3).打开url
4.4).查找对应的对象
"""
需求:
使用link_text定位方式,点击百度页面的新闻a标签
方法:
element =driver.find_element(By.LINK_TEXT, "标签里的内容") #定位元素方法
"""
# 导包
from selenium import webdriver
from time import sleep
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 获取浏览器对象
chromedriver_path = r"C:\Program Files\Google\Chrome\Application\chromedriver.exe"
service = Service(executable_path=chromedriver_path)
driver = webdriver.Chrome(service=service)
def main():
# 打开页面
driver.get("https://baidu.com/")
# 查找元素并点击可以合为一步
driver.find_element(By.LINK_TEXT, "新闻").click()
# 睡眠3秒钟
sleep(3)
# 关闭浏览器
driver.quit()
if __name__ == '__main__':
main()4.6.partial_link_text定位
1).说明:定位超链接标签
2).partial_link_text定位方法:element=driver.find_element(By.PARTIAL_LINK_TEXT,模糊内容")
3).注意
3.1).只能定位a标签
3.2).partial_link_text定位元素的内容可以为模糊部分值,但是必须能代表唯一性
3.3).没有唯一代表,默认操作符合条件的第一个元素
4).代码实现步骤
4.1).导包
4.2).获取浏览器驱动对象
4.3).打开url
4.4).查找对应的对象
"""
需求:
使用partial_link_text定位方式,点击百度页面的新闻a标签
方法:
element =driver.find_element(By.PARTIAL_LINK_TEXT, "模糊内容") #定位元素方法
"""
# 导包
from selenium import webdriver
from time import sleep
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 获取浏览器对象
chromedriver_path = r"C:\Program Files\Google\Chrome\Application\chromedriver.exe"
service = Service(executable_path=chromedriver_path)
driver = webdriver.Chrome(service=service)
def main():
# 打开页面
driver.get("https://baidu.com/")
# 查找元素并点击可以合为一步
driver.find_element(By.PARTIAL_LINK_TEXT, "新").click()
# 睡眠3秒钟
sleep(3)
# 关闭浏览器
driver.quit()
if __name__ == '__main__':
main()4.7.XPath
1).说明
1.1).XPath即为XMLPath的简称,它是一门在XML文档中查找元素信息的语言
1.2).HTML可以看做是XML的一种实现,所以Selenium用户可以使用这种强大的语言在Web应用中定位元素
1.3).XML:一种标记语言,用于数据的存储和传递,后缀.xml结尾
2).XPath的定位方法:element = driver.find_element(By.XPATH, xpath)
3).XPath常用定位策略
3.1).路径-定位
1.绝对路径:从最外层元素到指定元素之间所有经过元素层级的路径
(1).绝对路径以/html根节点开始,使用/来分隔元素层级;如:/html/body/div/fieldset/p[1]/input
(2).绝对路径对页面结构要求比较严格,不建议使用
(3).语法:以单斜杠开头逐级开始编写,不能跳级,如:/html/body/div/p[1]/input
2.相对路径:匹配任意层级的元素,不限制元素的位置
(1).相对路径以//开始,后面跟元素名称
(2).格式://input或者//*---->//input[@id='password'](路径+属性)
(3).语法:以双斜杠开头,双斜杠后边跟元素名称,不知元素名称可以使用*代替,如://input
3.2).利用元素属性-定位----->此方法不行就使用(路径+属性)
1.语法:在XPath中,所有的属性必须使用@符号修饰,如://*[@id="id值]
3.3).属性与逻辑结合-定位
1.语法://*[@id="id值’and@属性='属性值]
3.4).层级与属性结合-定位
1.语法://*[@id=父级id属性值']/input
3.5).提示
1.一般使用指定标签名称,不使用*代替,效率比较慢
2.无论是绝对路径和相对路径,/后面必须为元素的名称或者*
3.扩展:在企业中,一般使用相对路径
4).代码
"""
使用绝对路径定位谷歌搜索框,并输入:csdn
暂停两秒钟
点击打开第一个csdn官网
"""
# 导包
from selenium import webdriver
from time import sleep
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 获取浏览器对象
chromedriver_path = r"C:\Program Files\Google\Chrome\Application\chromedriver.exe"
service = Service(executable_path=chromedriver_path)
driver = webdriver.Chrome(service=service)
def main():
# # 打开页面
# driver.get("https://baidu.com/")
#
# 使用绝对路径定位谷歌搜索框,并输入:csdn 绝对路径
driver.find_element(By.XPATH, "/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input").send_keys("csdn")
driver.find_element(By.XPATH, "/html/body/div[1]/div[1]/div[5]/div/div/form/span[2]/input").click()
# # 睡眠2秒钟
# sleep(2)
#
# # 点击打开第一个csdn官网 相对路径
driver.find_element(By.XPATH, "//*[@id='1']/div/div[1]/h3/a[1]").click()
# # 关闭浏览器
# driver.quit()
# 打开页面
driver.get("网页地址")
# 使用逻辑结合定位到提交按钮
driver.find_element(By.XPATH, "//input[@class = '提交' and @type = 'submit']").click()
# 使用层级定位用户名并输入你好
driver.find_element(By.XPATH, "//p[@id='p1']/input").send_keys("你好")
if __name__ == '__main__':
main()
5).扩展
5.1).//*[text()="xxx"]---->定位文本内容是xxx的元素
1.提示:一般适合p标签、a标签
5.2).//*[contains(@attribute,xxx')]----->定位属性中含有xxx的元素(移动端测试常用)
1.attribute是属性名,如type、name..
2.contains是关键字不可更改
5.3).//*[starts-with(@attribute,xxx')]--->定位属性以xxx开头的元素
1.attribute是属性名,如type、name..
2.starts-with是关键字不可更改
6).浏览器获取XPath路径


4.8.CSS
1).说明
1.1).CSS(Cascading StyleSheets)是一种语言,它用于描述HTML元素的显示样式
1.2).在CSS中,选择器是一种模式,用于选择需要添加样式的元素
1.3).在Selenium中也可以使用这种选择器来定位元素
2).提示
2.1).在selenium中推荐使用CSS定位,因为它比XPath定位速度要快
2.2).css选择器语法非常强大,且语法比XPath简单
3).CSS定位方法
3.1).element =driver.find_element(By.CSS_SELECTOR,csS_selector)
4).CSS定位常用策略(方式)
4.1).id选择器
1.前提:元素必须有id属性
2.说明:根据元素id属性来选择
3.格式:#id,例如:#userA<选择id属性值为userA的元素>
4.2).class选择器
1.前提:元素必须有class属性
2.说明:根据元素class属性来选择
3.格式:.class,例如:.telA<选择器class属性值为telA的所有元素>
4.3).元素选择器
1.说明:根据元素的标签名进行选择
2.格式:element,例如:input<选择所有input元素>
4.4).属性选择器
1.格式:[属性名="属性值]例如:[name="kw]
4.5).层级选择器
1.格式:
(1).p>input父级元素>子级元素
(2).p input父级元素子级元素
2.提示:>与空格的区别,>后面必须为直接子元素,空格则不用
5).代码
# 导包
from selenium import webdriver
from time import sleep
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 获取浏览器对象
chromedriver_path = r"C:\Program Files\Google\Chrome\Application\chromedriver.exe"
service = Service(executable_path=chromedriver_path)
driver = webdriver.Chrome(service=service)
def main():
# 打开页面
driver.get("https://baidu.com/")
# 百度搜索框 id选择器
driver.find_element(By.CSS_SELECTOR, "#kw").send_keys("美团")
# 百度一下按钮 class选择器
driver.find_element(By.CSS_SELECTOR, ".bg.s_btn").click()
# 百度搜索框 属性选择器
driver.find_element(By.CSS_SELECTOR, "[id='kw']").send_keys("招")
# 百度搜索框 元素选择器和属性选择器结合
driver.find_element(By.CSS_SELECTOR, "input[id='kw']").send_keys("聘")
# 百度一下按钮 层级选择器和属性选择器结合
driver.find_element(By.CSS_SELECTOR, "span>input[class='bg s_btn']").click()
# 睡眠3秒钟
sleep(3)
# 关闭浏览器
driver.quit()
if __name__ == '__main__':
main()6).CSS扩展(了解)
6.1).[属性名^='指定字母]--->属性以指定字母开头的元素
6.2).[属性名$='指定字母]--->属性以指定字母结束的元素
6.3).[属性名*='指定字母]--->属性包含指定字母的元素
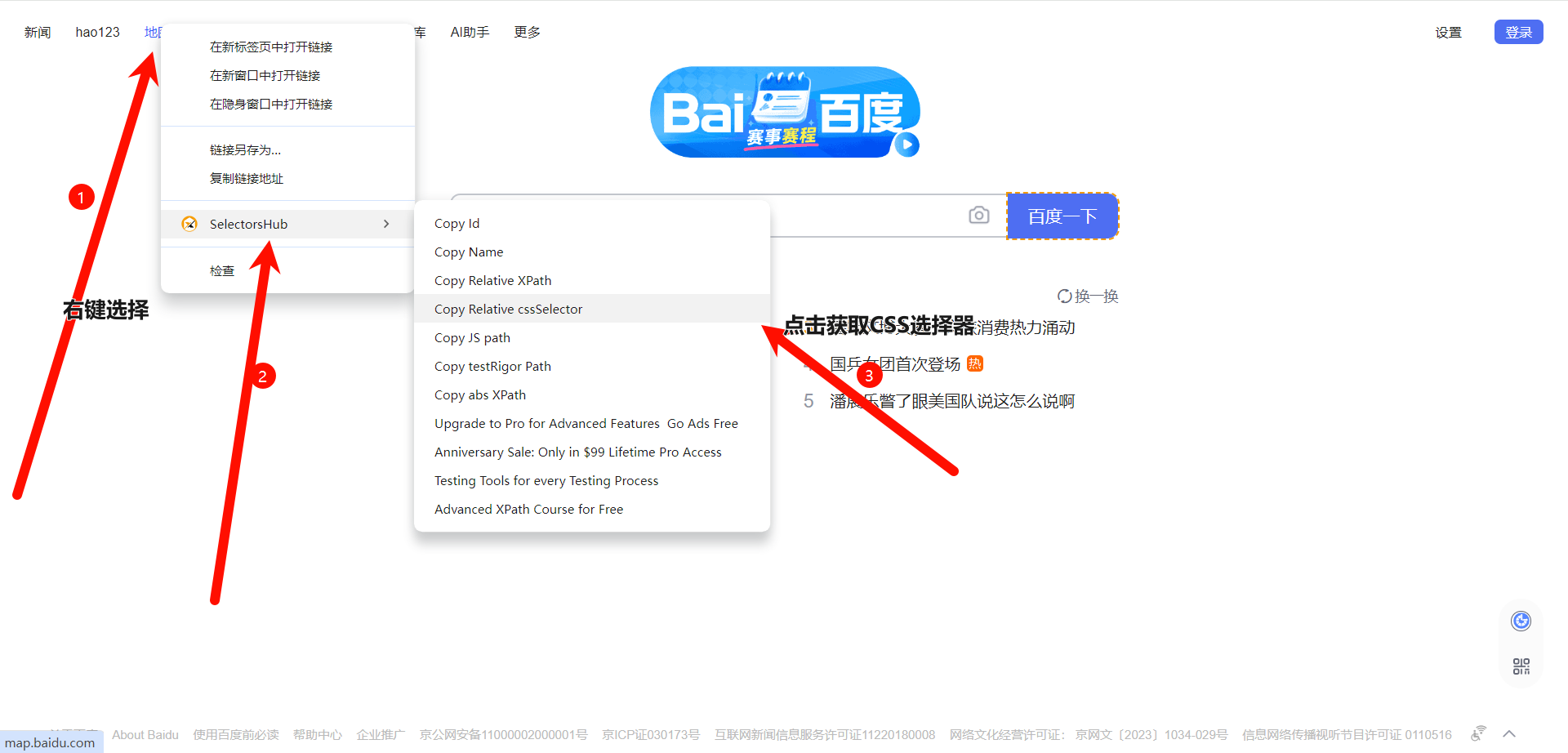
7).浏览器获取CSS路径
7.1).SelectorsHub下载此插件

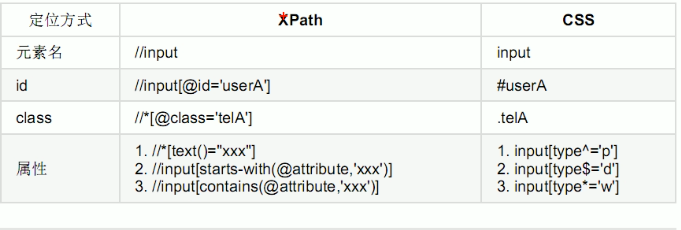
8).XPath与CSS类似功能对比
9).定位一组元素
9.1).方法:driver.find_elements(By.XXxX,XXXx)
9.2).返回结果:类型为列表,要对列表进行访问和操作必须指定下标或进行遍历
五、常用方法
5.1.输入方法
1).send.keys("输入内容")
5.2.退出浏览器驱动
1).driver.quit()
5.3.打开url
1).driver.get(url)
5.4.导包
1).from selenium import webdriver
2).from selenium.webdriver.chrome.service import Service
3).from selenium.webdriver.common.byimport By
5.5.获取浏览器驱动对象
1).driver=webdriver.Chrome(service=service)
六、今日学习思维导图


















 102
102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









