







前言
hi~大家好呀,欢迎来到我的MySQL笔记系列。
本篇笔记主要记录经过DDLSQL语句实现对数据库结构的创建和表的结构的创建后,现在需要对表内所包含的数据进行操作,所以涉及到了DMLSQL语句,并且整理为CRUD:创建、读取、更新、删除。
我的前几篇MySQL笔记~

目录
准备库表结构
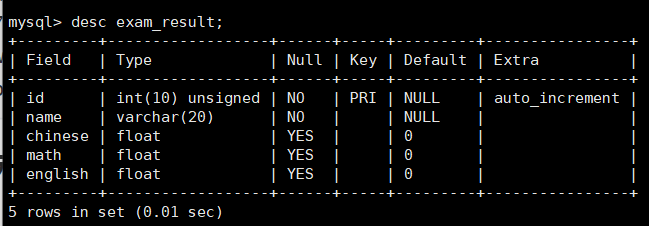
在正式进入学习之前,根据之前的知识,我们首先创建出test2_db这个数据库,使用此数据库创建表exam_result,此表结构具体如下:
然后我们正式进入对CRUD - DMLSQL语言的学习~
一、Create创建数据
对于一个表,首先自然需要数据,需要数据的话就必须先插入。
1.单/多列正常插入
针对于常规情况下的插入,我们有如下语法进行使用:
-- 单/多列正常插入
insert [into] table_name
[(column[, column.....])]
values (value_list)[, (value_list)......];
-- value_list = value[, value......]
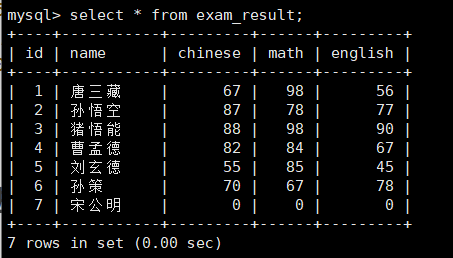
现在,我们对于表exam_result表插入一个记录:唐三藏,语文:67,数学:98,英语:56。
insert into exam_result(name, chinese, math, english) values('唐三藏', 67, 98, 56);多列正常插入:我们插入多列数据,数据信息如下:
('孙悟空', 87, 78, 77),
('猪悟能', 88, 98, 90),
('曹孟德', 82, 84, 67),
('刘玄德', 55, 85, 45),
('孙策', 70, 67, 78),
('宋公明', 0, 0, 0);
insert exam_result(name, chinese, math, english) values
('孙悟空', 87, 78, 77),
('猪悟能', 88, 98, 90),
('曹孟德', 82, 84, 67),
('刘玄德', 55, 85, 45),
('孙策', 70, 67, 78),
('宋公明', 0, 0, 0);
结果如下图所示:
现在,为了演示后续步骤,我们可以选择讲name设置为唯一键。
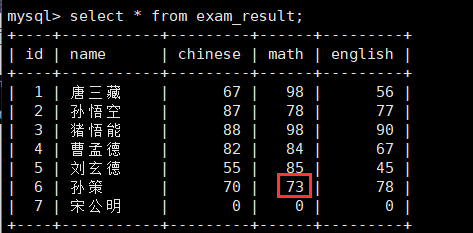
alter table exam_result modify name varchar(20) NOT NULL unique COMMENT '同学姓名';如果我们继续插入一个insert into exam_result(name, chinese, math, english) values ('孙策', 70, 73, 78);会不会出现问题呢?(注意math的67变了)
自然会出现问题,因为表结构中name属性是唯一键的属性,会插入失败。
如果对于像主键和唯一键这样的冲突的话,我们就进行更新操作就可以使用如下的语法:
2.插入失败就进行更新
-- 如果插入失败就进行更新
insert ...... on duplicate key update
column = value[, column = value......];那么,上面的插入语句就可以这样写:insert into exam_result(name, chinese, math, english) values ('孙策', 70, 73, 78) on duplicate key update math=73;
也就是说,如果没有冲突,那么就是正常的插入,返回的修改信息中就是1rows,如果冲突了,更新的内容不同,那么修改信息就是2rows,如果冲突并且更新内容相同,返回就是0rows。

那么,现在我想插入一条:insert into exam_result(name, chinese, math, english) values('宋公明', 75, 65, 30);自然会冲突的,实际上还有另一种方法除开上面如果冲突就更新的策略。
冲突就替换。
3.替换
-- 替换
replace into .....;如果插入的存在主键或者唯一键的冲突,那么会讲原来的记录删掉,替换为当前的记录。这一种使用比第二种使用更加简洁并且广泛。
所以,我们讲插入宋公明那条讲insert换成replace即可。
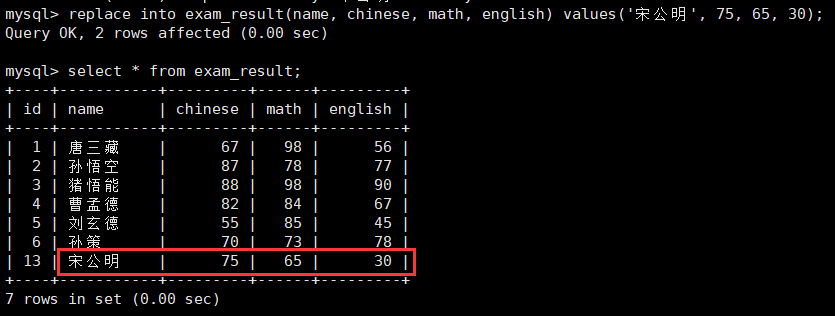
同理,rows=2表示存在冲突,发生了删除后替换;rows=0表示不存在冲突,不会发生替换。
那么现在我们插入了一批上述的数据,如果想根据不同的条件进行查询的话,该如何进行查询呢?这就要涉及DMLSQL的查询阶段了。
二、Retrieve读取数据
本篇博客查询只涉及单表查询,复合查询后续会讲~
1.select 列查询
-全列查询
当我们需要查看表中记录的每一个属性的时候,就可以使用全列查询,*表示全部。
select * from table_name;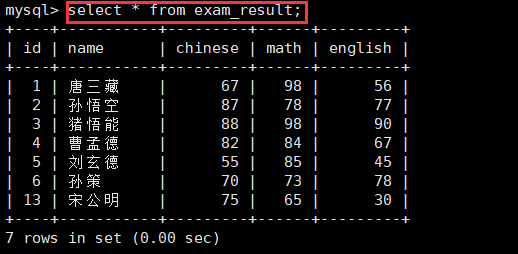
但是,使用全列查询的时候,需要注意如下几点:
1.由于当前的数据量小,是可以进行全列查询的。
2.当数据越多,那么查询的数据量就会越来越大
3.后续可能影响到索引的使用。
所以,数据量大的情况下不建议使用 * 进行全列查询。
-指定列查询
如果我们想查询数据只是指定的属性的话,可以进行指定列查询,并且顺序不用遵守原表的顺序。
select column[, column......] from table_name;比如我以name、id、math的顺序查询exam_result表。
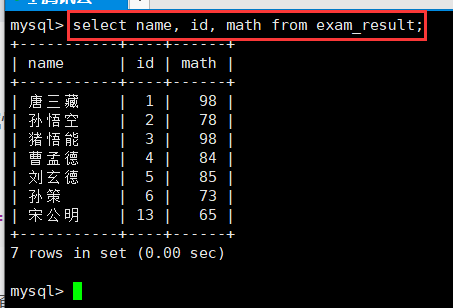
-查询字段为表达式
在之前,我们知道select在sql中查询功能强大,甚至能计算表达式的值:
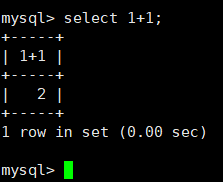
那么,如果以当前表中可以计算的属性值,能否作为表达式进行表达出来呢?(需要注意,表达式似乎是横向的计算每个记录中的值)
select [expression(column)] from table_name;比如,我们利用表达式查询每个学生的成绩总和。
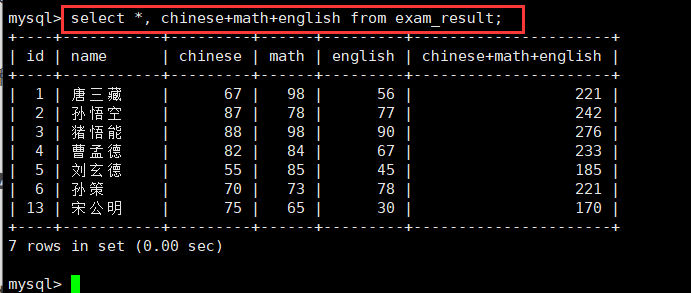
-查询属性重命名
另外,对于我们使用select查询表,属性我们都可以进行重命名显示出来。格式如下:
select column [as] newcolumn [, expression(cloumn) [as] newcolumn...]
from table_name; 比如将上面的英文属性以及表达式的属性名转化为中文进行select出来:
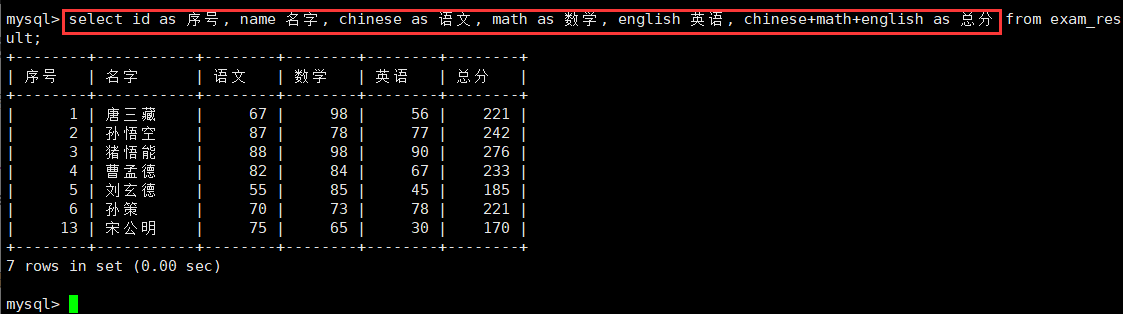
-结果去重
当然,在查询过程中,如果查询结果的记录中存在重复项,我们可以使用如下的格式进行去重操作:
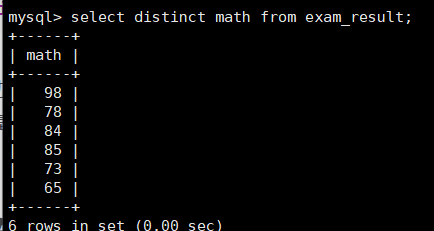
select [distinct] column from table_name;需要注意,加上distinct条件,会根据查询列的每个记录检查是否重复,存在重复项就会去去重,需要注意式基于记录整个来说的。
比如math中存在重复的成绩,我们可以利用distinct进行去重~
综上,针对于select列查询,有如下形式:
a、* 或者 指定列查询。column
b、select 后面可以跟着表达式。expression
c、表达式和属性均可以重命名。as
d、支持去重操作。distinct
2.where 条件查询
之前,我们只是针对查询每个记录的不同属性(列)进行查询。那么我们如果要针对记录进行限定呢?那么这个时候就需要where关键字进行限定条件查询了。
那么在限定的条件中,好比程序语言中的if中的()内的内容一样,我们需要一些逻辑符号和符号进行限制条件:
运算符:
| 运算符 | 说明 |
|---|---|
| >,>=,<,<= | 大于,大于等于,小于,小于等于 |
| = | 等于,无法比较NULL |
| <=> | 等于,可以比较NULL |
| !=,<> | 不等于 |
| between a and b | 匹配范围[a, b] |
| in(选项1, ......) | 匹配选项 |
| is null | 是null |
| is not null | 不是null |
| like | 模糊匹配,'%'表示多个(或者0个)字符,'_'表示单个字符 |
逻辑运算符:
| 运算符 | 说明 |
|---|---|
| and | 逻辑与 |
| or | 逻辑或 |
| not | 逻辑非 |
下面,针对上面条件限定的运算符,进行where使用条件限定记录的举例:
1.英语不及格的同学:<运算符
select name, english from exam_result where english < 60;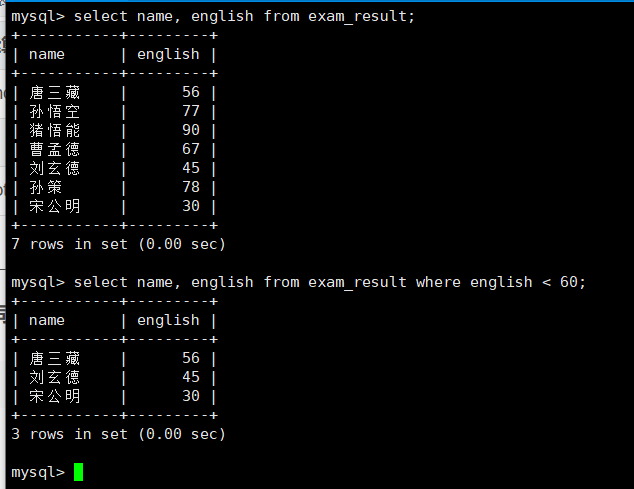
2.数学成绩在[80, 90]分的同学:<= >= and between
select name, math from exam_result where math >= 80 and math <= 90;
select name, math from exam_result where math between 80 and 90;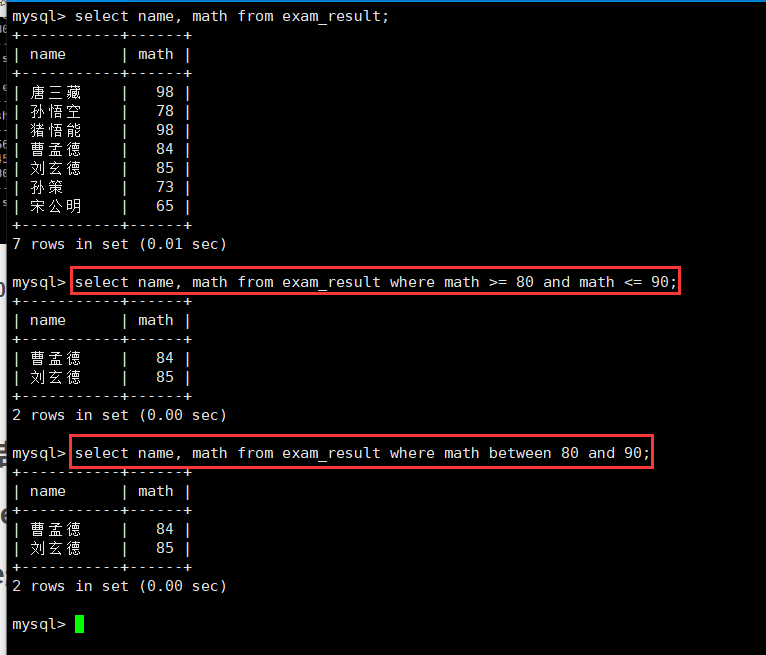
3.数学成绩是58或者59,或者98或者99的同学和成绩:or in
select name, math from exam_result where math=58 or math=59 or math=98 or math=99;
select name, math from exam_result where math in (58, 59, 98, 99);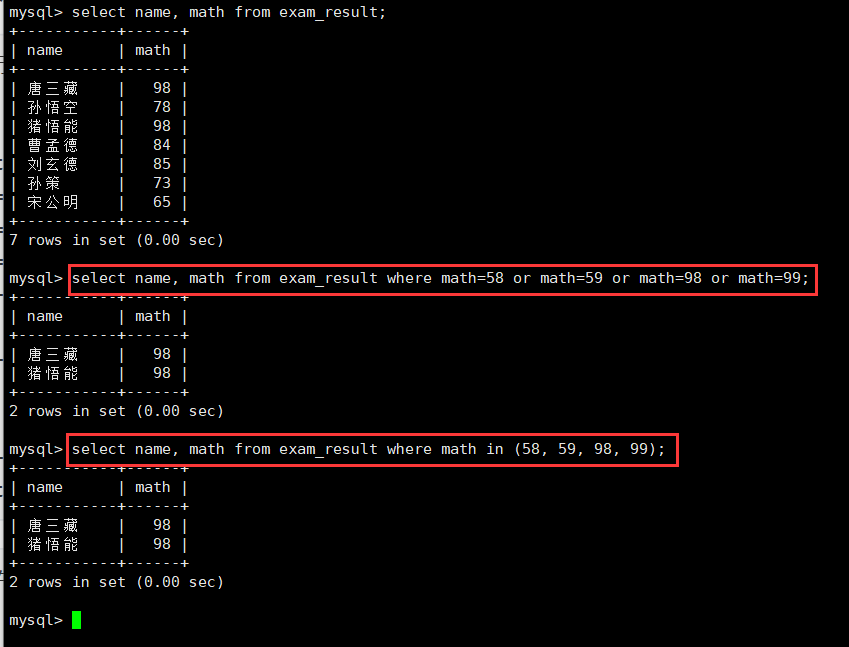
4.姓孙的同学和孙某同学:like-%,_
select name from exam_result where name like '孙%';
select name from exam_result where name like '孙_';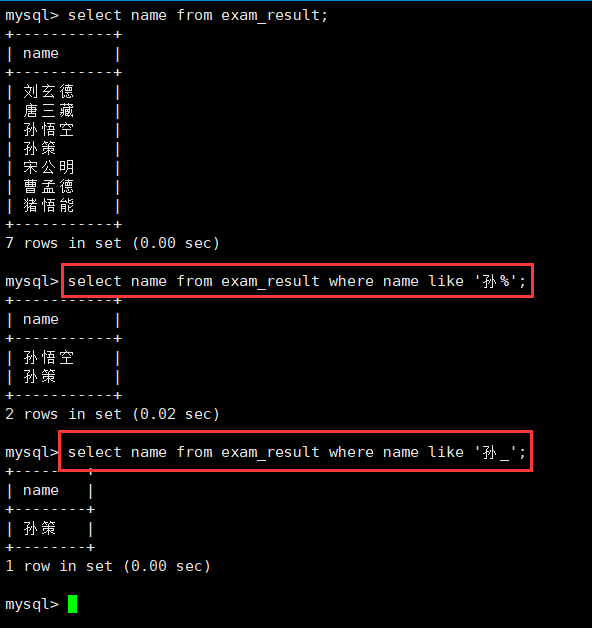
5.数学成绩好于英语成绩的同学:> 左右两边均为属性
select name, math, english from exam_result where math > english;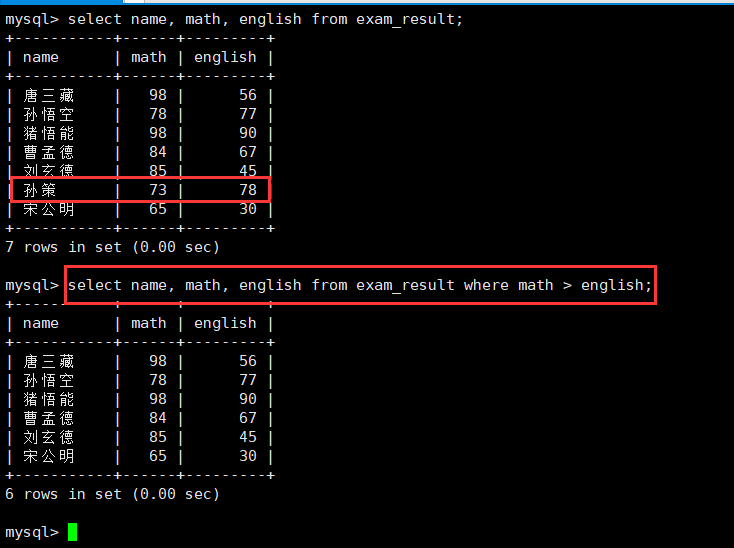
6.总分在200分以下的同学:使用表达式,别名
select name, chinese+math+english as 总分 from exam_result where chinese+math+english < 200;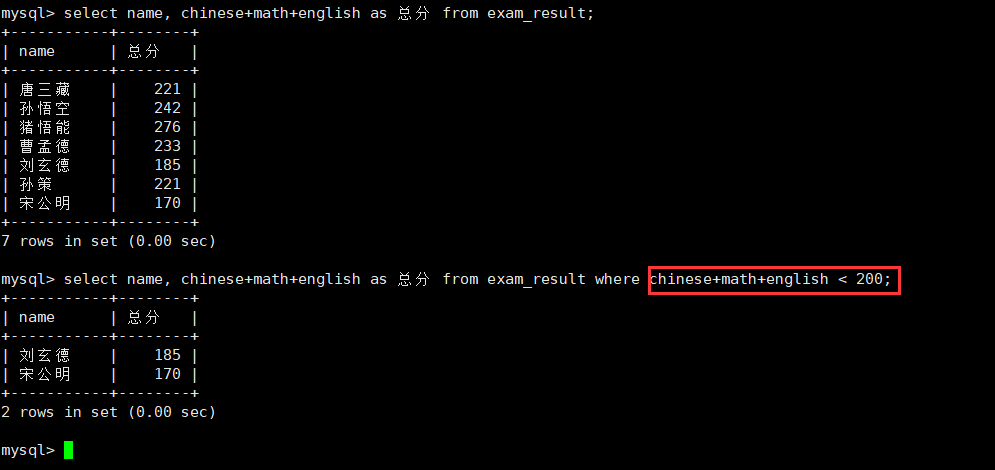
首先我们可以看到在where子句中是可以使用表达式的。那么我们重命的名字是否可以作为where子句呢?

很显然,报错了。这是因为where从句中找不到列'总分'。
理解where在select中的执行顺序
比如,一个查询sql语句如下:
select column [as newcolumn] from table_name where cond; 执行的流程如下:
1.首先from找到table_name,
2.找到这张table_name后,根据where中的cond条件筛选出合适的记录。
3.然后将记录根据column拿出来。
而重命名的时候,就是在根据column拿出来的时候,所以上述的报错自然where就从表中找不到此列了。
3.结果排序
那么,现在我们筛选出了一批记录,并且按照指定的列进行显示出来了。如果里面存在数据能够排序的话,那么我们能不能使用sql语法进行排序呢?
select [distinct] column [as newcolumn] [...]
from table_name [where cond] order by column [asc | desc] [, column [asc | desc] ...];其中,升序ascending简写为asc,并且默认为升序排序。
降序descending简写为desc,可以依据column属性进行降序排列筛选后的一批记录。因为涉及到排序比较,所以此属性一定是可以进行比较的。
如果没有order by子句的查询的话,返回的顺序是未定义的,不可依赖此顺序。
下面还是以exam_result表中的数据进行举例。
1.同学及数学成绩,按数学成绩升序显示:order
select name, math from exam_result order by math; -- 默认asc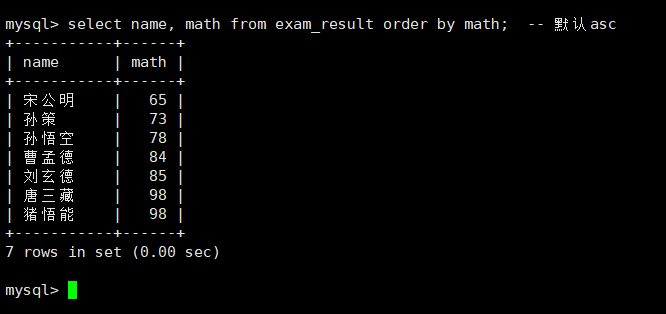
2.插入NULL值,观察NULL值排序:order
我们为这个表插入一个各科成绩为空的学生,然后继续1的升序和降序查询。
insert into exam_result(name, chinese, math, english) values ('张三', NULL, NULL, NULL); -- 插入数据
select name, math from exam_result order by math asc; -- 升序
select name, math from exam_result order by math desc; -- 降序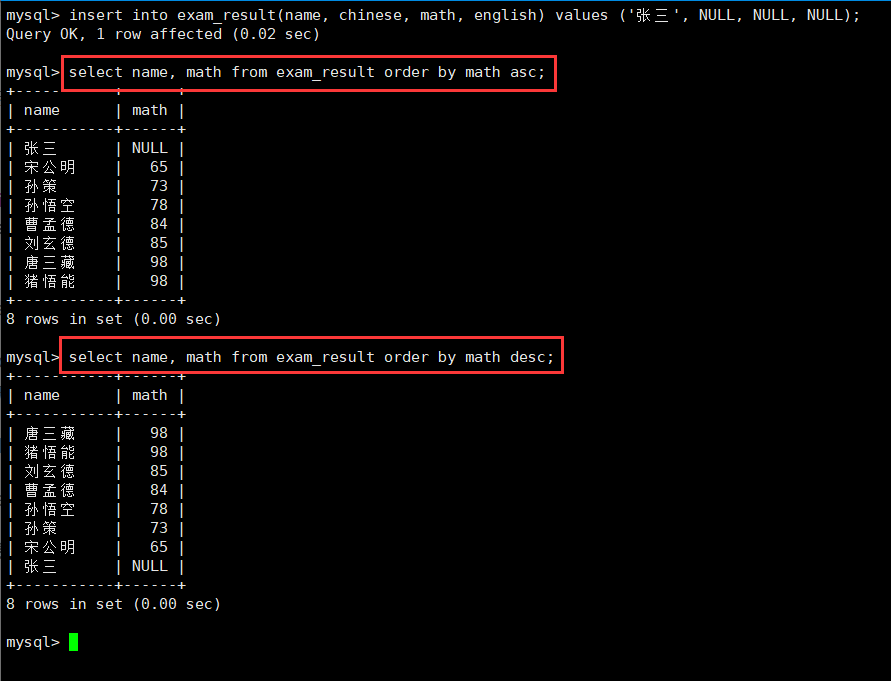
可以发现,NULL值参与排序,并且设定为最小,asc升序在最前面,desc降序在最后。
3.查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示:order 多个column
select name, chinese, math, english from exam_result order by math desc, english asc, chinese asc;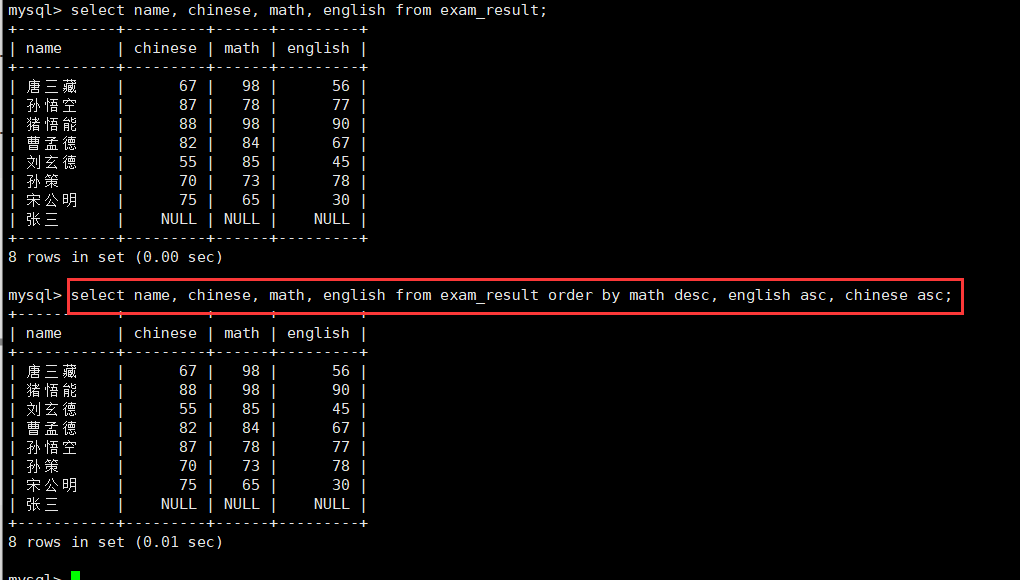
4.查询同学总分,由高到低:表达式 as order
select name, chinese+math+english as 总分 from exam_result order by 总分 desc;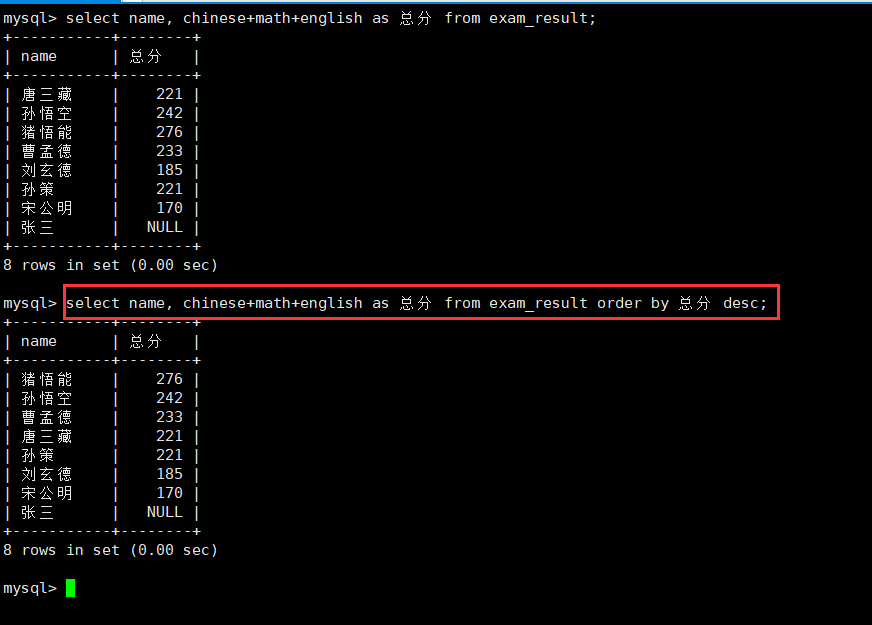
可以发现,在order by后面是可以用到属性的重命名的。在之前,wherer后面是无法使用重命名因为和执行顺序有关。
这里自然也是如此。排序自然也是对结果进行排序才有效。所以order by的执行顺序是等到筛选完记录并且按需拿出的时候进行排序的,是相对靠后的。
5.查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示:order、where
select name, math from exam_result
where name like '孙%' or name like '曹%'
order by math desc;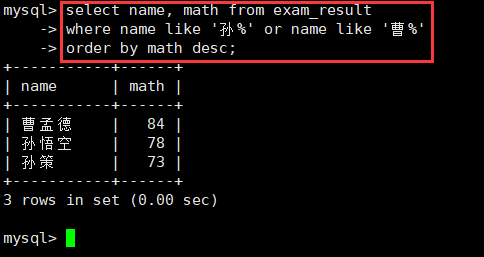
4.筛选分页结果
对于结果来说,除了排序,我们还能筛选指定的记录个数。
select [column ...] from table_name
where [cond] [order by ...] [limit n | b, n | n offset s];limit能够从筛选的结果中指定多少行进行显示。
limit n:从第一行开,筛选n行。
limit b, n:从b行开始,筛选n行。
limit n offset s:从s行开始,筛选n行。
注意,起始位置为0.和程序中下标的起始位置一致,不是1哦~
下面还是用我们的exam_result表进行举例:从原表的第一行记录开始,提取四行数据出来,以limit三种方式进行提取:
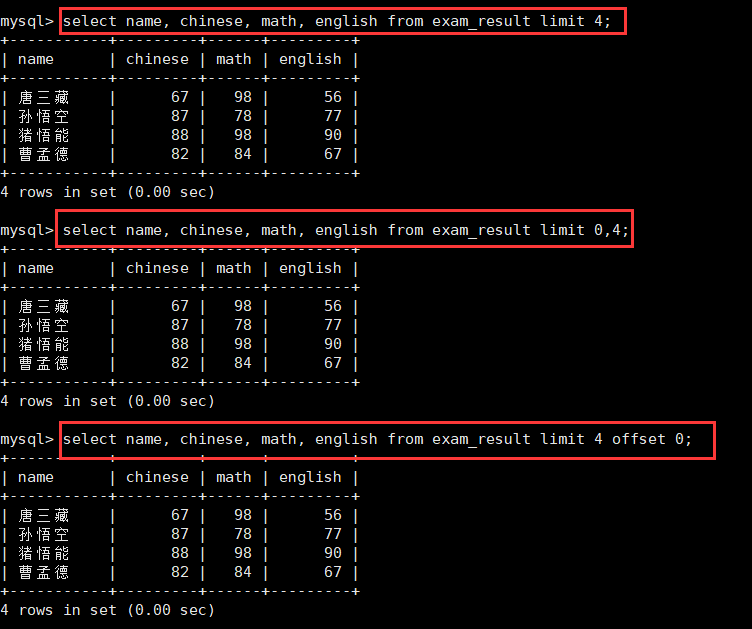
需要注意,limit执行顺序是在order by后执行的,也就是说limit实际是显示结果做的最后一步。
对于select单表不分组查询在这里先不总结,在后面的分组查询中进行综合总结。
三、Update更新数据
如果我们需要对记录进行修改,那么就需要用到dmlsql中的update关键字进行更新数据。
update table_name
set column = expr [, column = expr ...]
[where ...] [order by ...] [limit ...]set部分是修改部分。where用于筛选指定的记录进行修改。语法和select一致。
需要注意的是,由于是数据操纵语言,所以只能修改表内的数据。
下面是以表exam_result进行的示例:
1.将孙悟空同学的数学成绩变更为 80 分:修改单个值
update exam_result set math=80 where name='孙悟空';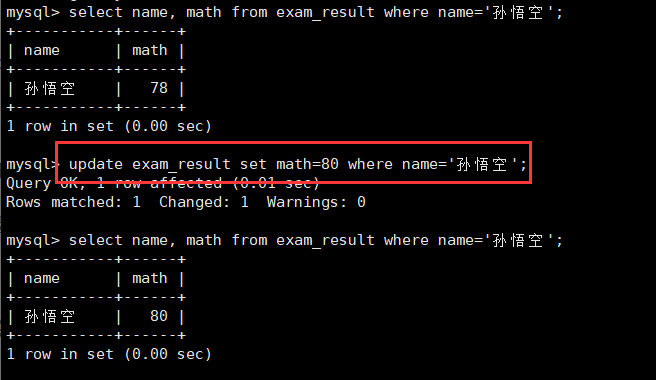
2.将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分:修改多个值
update exam_result set math=60, chinese=70 where name='曹孟德';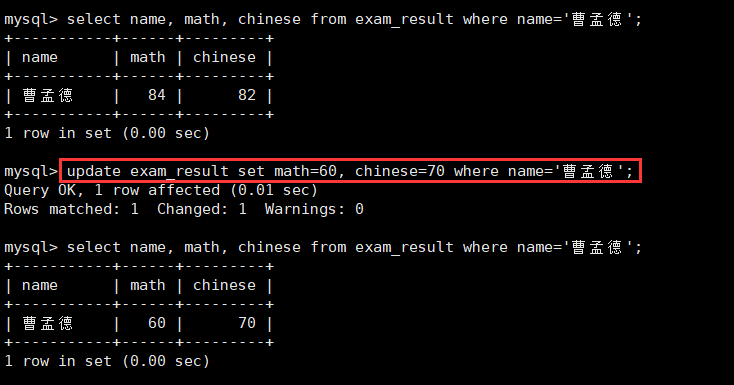
3.将总成绩倒数前三的 3 位同学的数学成绩加上 30 分:修改多个记录
首先将张三记录删除。然后进行查询:
delete from exam_result where name='张三';
update exam_result set math=math+3 order by math+chinese+english asc limit 3;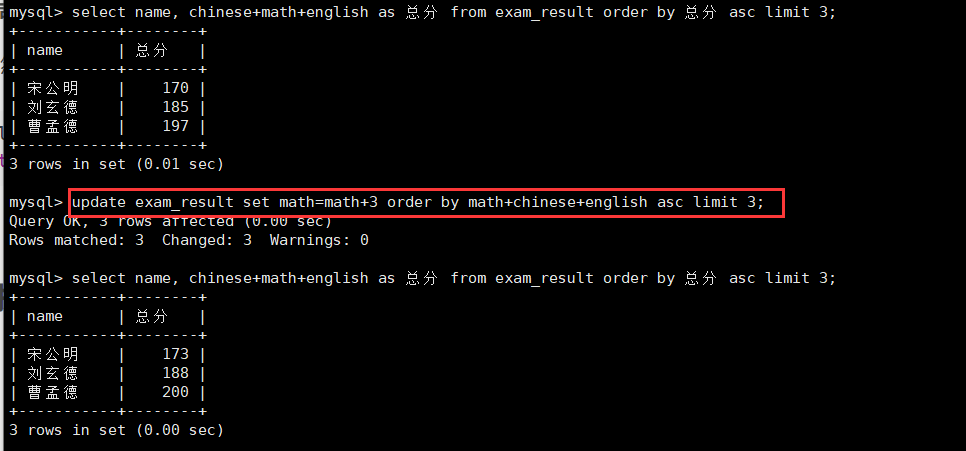
四、Delete删除数据
删除数据很简单,只要根据where条件找到指定的记录进行删除即可。dmlsql语句中用delete作为关键字。
delete from table_name
[where cond] [order ...] [limit ...];下面仍然以exam_result表为例,只不过我们先进行以下备份(备份在插入查询数据会讲,这里使用一下)
create table exam_result2 like exam_result; -- 创建相同结构的表DDL
insert into exam_result2 select * from exam_result; -- 插入查询数据,备份完毕DML1.删除孙悟空同学的考试成绩
delete from exam_result where name='孙悟空';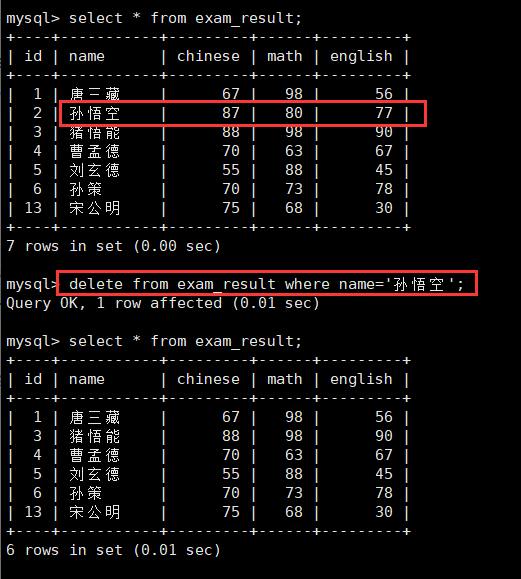
2.删除整张表的数据:
删除整个表的数据很简单:
delete from exam_result;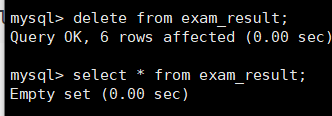
但是注意,删除数据delete属于DML数据操纵语言,所以并不会对表结构进行修改,说直白点,如果这里存在id属性auto_increment自增长,其字段是不会被删除的。
show create table exam_result\G 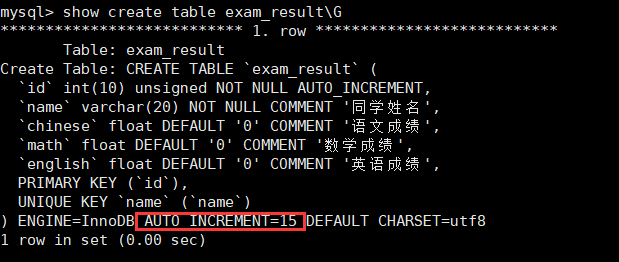
那么存不存在可以修改表数据又能清空的呢?(真正意义上的清空)
截断表
truncate [table] table_name;需要注意:
1.truncate只能对整张表作用,并不能像delete那样可以单个操作。
2.实际上 MySQL 不对数据操作,所以比 delete更快,但是truncate在删除数据的时候,并不经过真正的事物,所以无法回滚 。
3.会重置auto_increment项。

此时可以看到,表结构中的auto_increment项也被清理了。
五、插入查询数据
插入查询结果就和我们之前备份exam_result表为exam_result2表那样。insert入表结构一致的数据即可:
insert into table_name [(column[, column...])] select ...下面创建一个练习表,引入插入查询数据。比如创建表test_vb;结构为id int和name varchar(20),插入数据1 'a',2 'b', 3 'c'各三次。现在实现删除表中的重复记录,原本表需要保留一份。
-准备工作:
create table test_vb( id int, name varchar(20));
insert into test_vb values
(1, 'a'),(1, 'a'),(1, 'a'),
(2, 'b'),(2, 'b'),(2, 'b'),
(3, 'c'),(3, 'c'),(3, 'c');创建相同结构的表
语法:
create table new_table like table_name;现在创建和test_vb结构相同的表,如下:
create table new_test_vb like test_vb;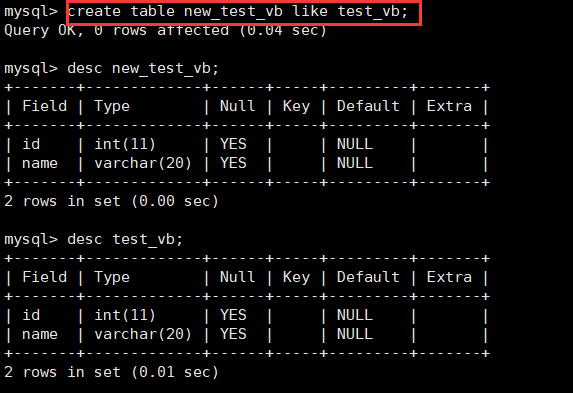
-插入查询的去重数据:
insert into new_test_vb select distinct * from test_vb;-重命名表:
重命名操作在Linux下是mv指令。我们知道MySQL数据库中一张表就是一个文件,所以对其进行重命名就是类似mv操作,mv操作是原子的。
重命名可以使用DDL中的修改关键字alter进行操作:
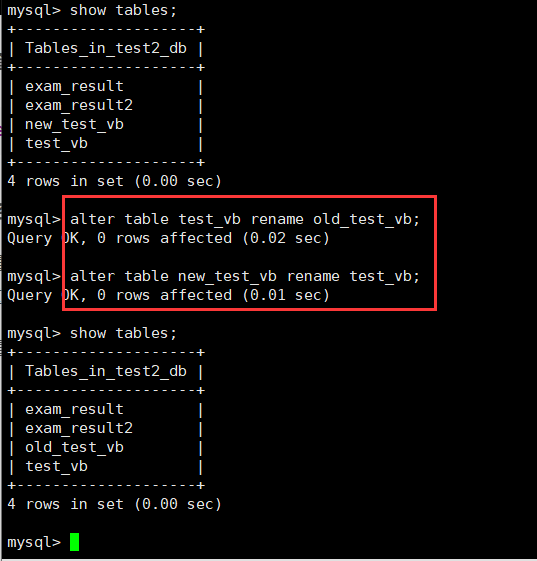
也可以使用rename table [table to newtable] [, ....];操作进行重命名。
-结果:
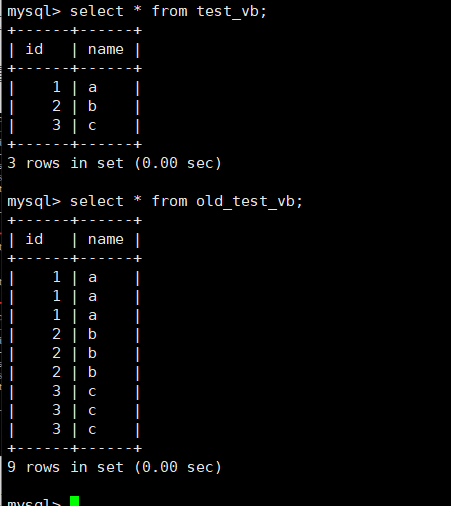
六、聚合函数
根据前面的select查询语句中的表达式,统计的是记录中行方向上的数据。
但是对于查询的一批数据来说,对于一个属性上的每个记录的所有值能不能进行一个统计呢?此时就存在了聚合函数这一说。
聚合:
聚合统计一定是直接或者间接统计列方向的某些数据。-一定是相同属性的,并且一定是一批的记录。
表达式一般就是行方向的统计数据。聚合统计是在统计完数据后进行使用的,所以都会等select查询筛选后,然后进行聚合函数的使用。
聚合函数说明:
| 函数 | 说明 |
|---|---|
| count([distinct] excpr) | 统计查询结果存在多少条记录 |
| sum(excpr) | 将每个记录的表达式对应的值累加 |
| avg(excpr) | 计算每个记录对应表达式的所有值的平均数 |
| max(excpr) | 计算每个记录对应表达式的最大值 |
| min(excpr) | 计算每个记录对应表达式的最小值 |
下面,我们使用之前备份的exam_result2表进行下面的测试实验:
首先插入一条张三的学生数据,成绩均为空。insert into exam_result(name, chinese, math, english) values ('张三', NULL, NULL, NULL);
1.统计当前成绩表中的学生个数:count
-使用属性进行统计
select count(*) as 个数 from exam_result2;
select count(name) as 个数 from exam_result2;
......-使用表达式进行统计
因为select 后面跟上任何一个表达式都会和记录进行拼接。比如:
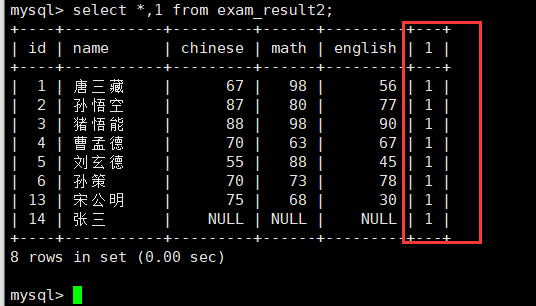
所以我们直接查询1也是可以的。
select count(1) as 个数 from exam_result2;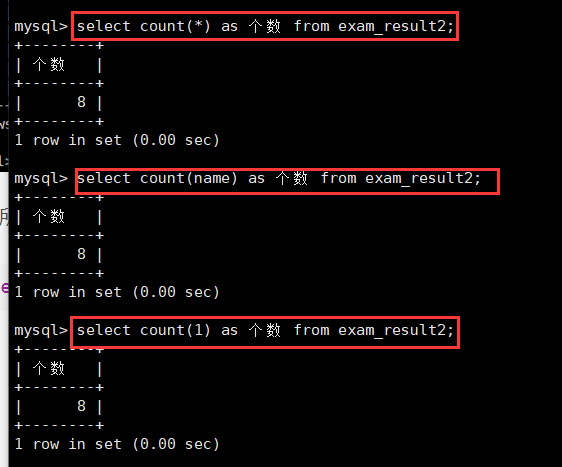
2.查询语文成绩的参与人数:count、null不纳入结果
select count(chinese) as 语文成绩有效个数 from exam_result2;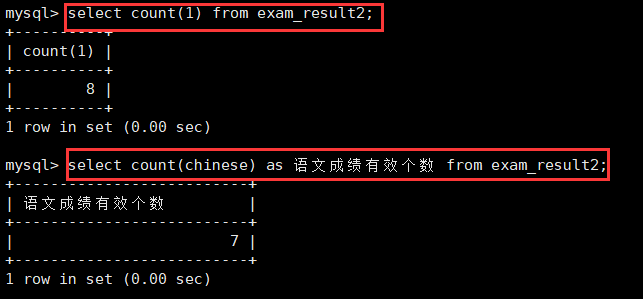
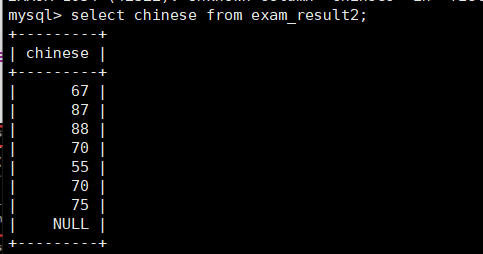
综上,可以发现chinese属性中存在数据为null的情况,count或者聚合函数均对null是不纳入统计的,所以一个为7一个为8了。
3.统计本次考试数学分数个数(排除重复项):count([distinct] ...)
因为要排除重复项。那么实际上筛选完并且根据select指定属性投影的时候就需要进行distinct进行去重操作。
在聚合函数内部就是之前进行select的操作。根据select的语法对属性进行操作就是在这里进行操作的。所以在括号里加上distinct就能排除掉重复的元素从而进行统计总数了。
select count(distinct math) from exam_result2;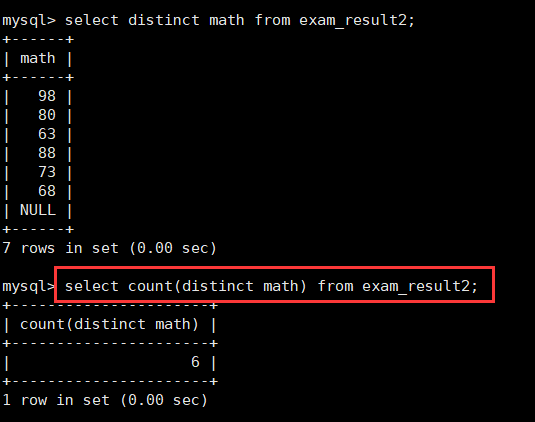
4.统计数学成绩总分:sum
select sum(math) as 数学总分 from exam_result2;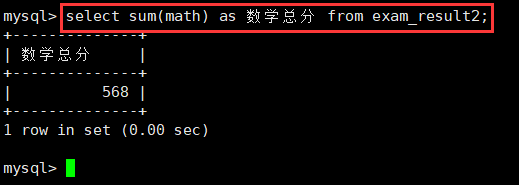
5.统计每个同学总分的平均分:avg
select avg(chinese+math+english) as 平均总分 from exam_result2;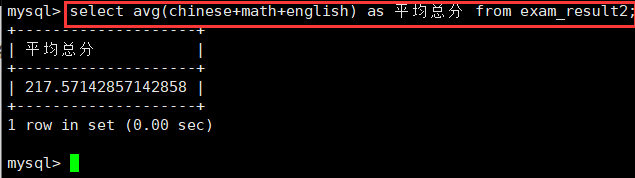
6.返回英语最高分:max
select max(english) from exam_result2;7.返回大于70分以上的数学最低分:where min
select min(math) from exam_result2 where math > 70; 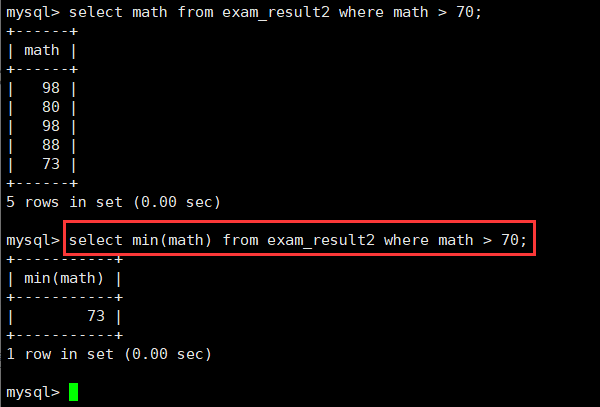
七、group by分组查询
有些时候,对于一张表,我们需要分为几张表通过聚合函数进行查询。好比一张成绩表中很多班的学生都在一起,我们就可以根据每个班分为几张表进行统计数据。
所以这个时候就需要分组查询进行控制。
select [distinct] column from table_name
[where expression(column)]
[group by col [, col...]] [having expression(col)]
[order by column [asc | desc] [, column...]] [limit ...];其中,col表示依据此属性进行分组的依据。这样,col相同的就会被分到同一组里(同一张表)。
如果是分组查询,那么在select的属性限制中就必须是其中的聚合函数,如果单独的属性就必须是col包含的属性。
另外,对于select 查询的聚合属性的值(分组查询就是对每个子表进行聚合统计后,根据其指定的col不同合并到一张表中)也可以进行一个筛选,这个时候就需要用到having关键字。
下面我们正式开始介绍group by之前,先将一个经典测试表导入到数据库中,方便我们进行后续的测试。
准备Oracle 9i经典测试表:
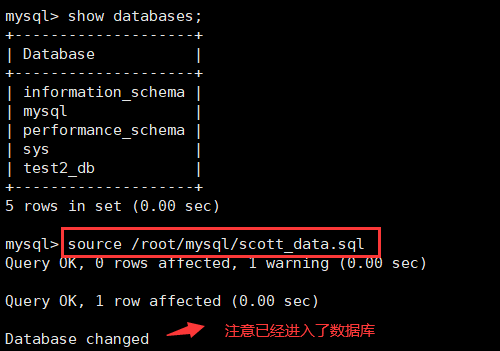
文件下载地址:scott_data.sql
文件下载好本地后,进入mysql,利用source命令进行恢复数据库,就可以得到scott数据库了:
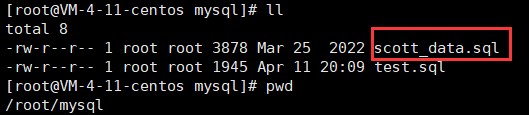
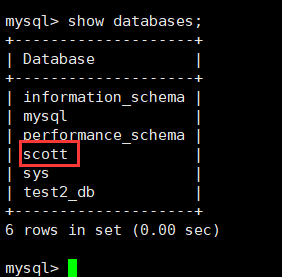
此时表内准备好了三张表:
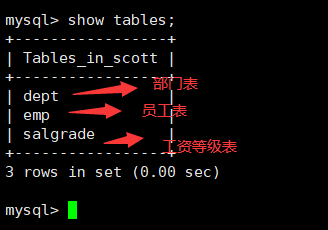
其中,dept是部门表,存在部门编号,部门名称,和部门所在地点。其中部门编号不可为空并且设置了zerofill;emp是员工表,存在雇员编号,雇员姓名,雇员职位,雇员领导编号,雇佣时间(datetime),工资月薪,奖金,部门编号。编号均为zerofill,雇员编号不可为null;salgrade为工资等级表,包括等级,此等级最低和最高工资,类型均为int。
当然,上面表中存在很多约束条件(key)没有进行添加,会在我们后续的测试表中不断的进行添加测试哦~
准备工作做好后,开始分组查询。
现在,我们对表emp进行如下的查找:
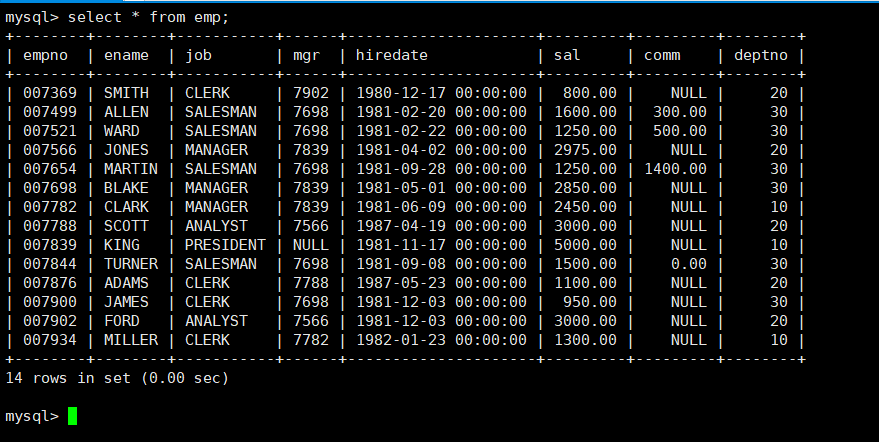
1.显示每个部门的平均工资:group by
我们要每个部门的平均工资,自然需要聚合函数。但是由于每个部门是混在一起的,所以我们可以根据deptno(部门编号)进行分组查询,根据每个组的工资平均值以及他们的部门编号重新组合为一张表显示出来即可:
select deptno 部门编号,avg(sal) as 平均工资 from emp
group by deptno;
2.显示每个部门的每个职位的平均工资:group by
和上面类似,只不过还需要进行一次分组(先分组为每个部门,然后再从每个部门中根据职位分组)。
select deptno 部门编号, job 工作职位, avg(sal) 平均工资 from emp
group by deptno, job;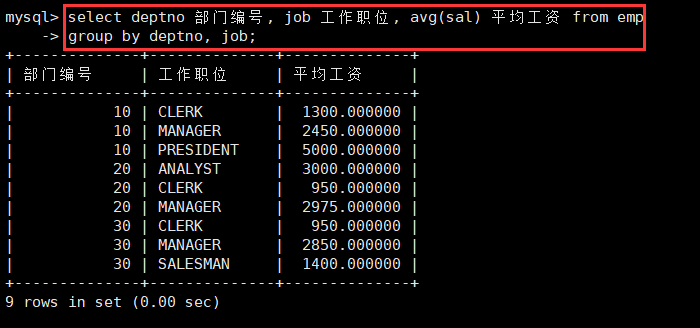
3.显示平均工资低于2000的部门和其平均工资:group by,having
需要对分组查询的聚合结果进行筛选即可:
select deptno 部门编号,avg(sal) 平均工资 from emp
group by deptno
having 平均工资 < 2000;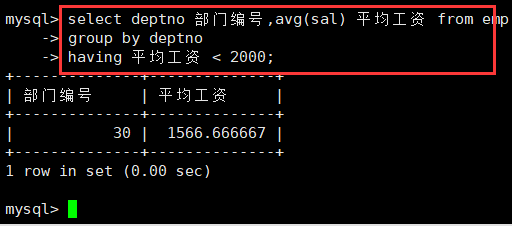
注意到as重命名后having也是可以使用的。因为where是根据from拿到的表进行筛选所以无法使用重命名,但是where筛选过后,就可以使用重命名了。
4.统计工资超过1000的所有人的每个部门、并且低于2000块钱的平均工资:where、group by、having
首先认真分析一下题目。因为工资超过1000就是再原表的基础上进行操作的,所以自然拿到emp表首先进行where筛选即可,其次是每个部门,那么就要group by进行分组以及依据分组的聚合结果having筛选低于2000平均工资的部门。
select deptno 部门编号, avg(sal) 平均工资 from emp
where sal > 1000
group by deptno
having 平均工资 < 2000;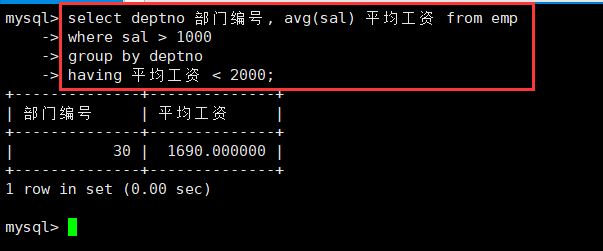
针对于分组查询和having的使用,需要注意:
1.group by是通过分组这样的手段,为未来进行聚合统计提供基本的功能支持(group by 配合聚合统计使用的)
2.group by后面跟的都是分组的字段,只有在group by后面出现的字段在聚合统计的时候在select中才能出现。
3.where条件和having不是对立的,是互相补充的。having通常用于完成了聚合统计,然后进行筛选的。where通常是在表中数据初步被筛选的时候,要起效果的。--原表操作。
select简单总结:
在单表查询的前提下,我们将DML数据操纵语言基本了解完毕。但是后续还会涉及到多表联动查询的场景。
就现在一个完整的select语句,我们可以大致归纳出它的一个执行流程:
1.首先通过from找到要查询的单表。
2.找到后通过where针对表中的属性进行限制筛选出一批元组(记录)。
3.根据这一批元组中的某种属性,将相同的分在一起,实现分组操作。
4.对分组的结果进行筛选。
5.然后将最终的结果根据select指定的属性或者表达式显示出来。(对于分组操作,如果单个属性显示必须是group by所依赖的属性)
6.去重操作。
7.排序记录。
8.显示某些记录。
综上,实际上就是:
from -> where->group by->having->select ->distinct->order by->limit















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









