







 文章介绍了如何利用Qwen1.5-7B大模型和阿里云PAI平台的DSW服务进行算力支持,通过SFT数据集的扩展和微调提升解题能力。同时探讨了多种技术手段,如代码模型、强化学习、ReActprompting等,以及前后端开发部署策略。
文章介绍了如何利用Qwen1.5-7B大模型和阿里云PAI平台的DSW服务进行算力支持,通过SFT数据集的扩展和微调提升解题能力。同时探讨了多种技术手段,如代码模型、强化学习、ReActprompting等,以及前后端开发部署策略。
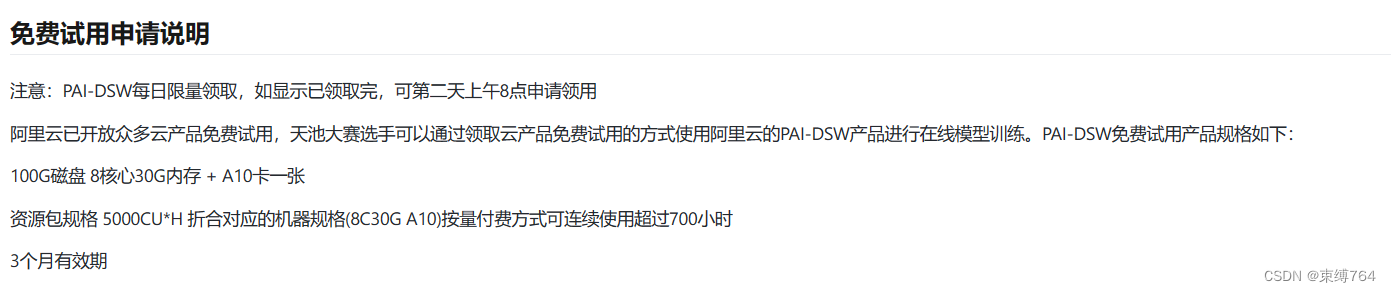
算力平台
项目采用Qwen1.5-7B-chat,LoRa训练要求20G显存左右,故试采用阿里云PAI平台DSW服务,配合魔搭生态便于微调。
SFT数据集
使用现有大模型对搜集的数据集针对小学数学题题型与知识点进行分类,以适用于项目的特定任务。
解题能力提升可选方案
1.多次解答选取最佳答案。
2.扩大有监督微调(SFT)数据集,随着 SFT 数据的增多,模型生成正确答案的可靠性显著提升。
3.使用合成数据,可以有效地扩大 SFT 数据集。利用 现有大模型生成了合成的数学问题与解题过程,并通过简单的验证提示词来确保问题的质量。
4.定义了 Pass@N 和 PassRatio@N 评测指标,意图分别测评模型的 N 次输出中,是否能够输出正确答案(表示模型潜在的数学能力),以及正确答案的所占比例(表示模型数学能力的稳定性)。
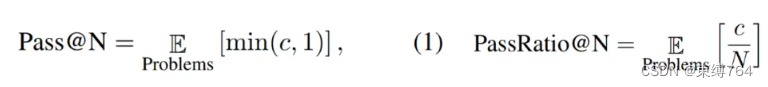
5.基于代码模型打造,无论是在两阶段训练还是一阶段训练设置下,代码训练相比于通用数据训练都可以提升模型的数学能力。
6.构建中英文数学指导监督微调(SFT)数据集,其中包括CoT、PoT和工具集成推理等三种格式。
7.数学和代码混合预训练有助于数学推理(w/ Tool Use)和代码生成能力(HumanEval)的协同提升。
8.强化学习(RL)阶段使用了一种名为“基于组的相对策略优化”(Group Relative Policy Optimization ,GRPO)的高效算法。
9. ReAct prompting意图将外部工具结合到语言模型的推理过程中。具体而言就是让模型生成问题解决推理轨迹的同时,在推理(Reasoning)中能够利用工具(Action)如搜索引擎等来实现与外部世界的交互,以获取实时的,相对可靠的额外信息(Observation)来辅助推理。通过推理轨迹生成和实际行动相结合,可提高语言模型的决策可解释性和可信度。例如RAG技术。
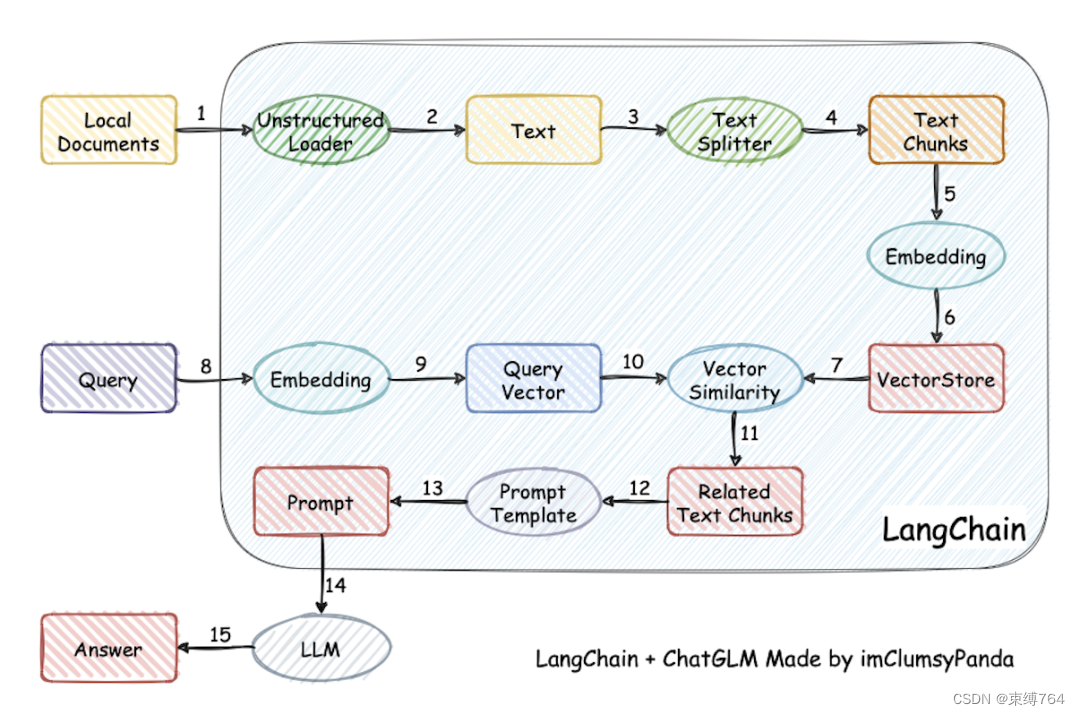
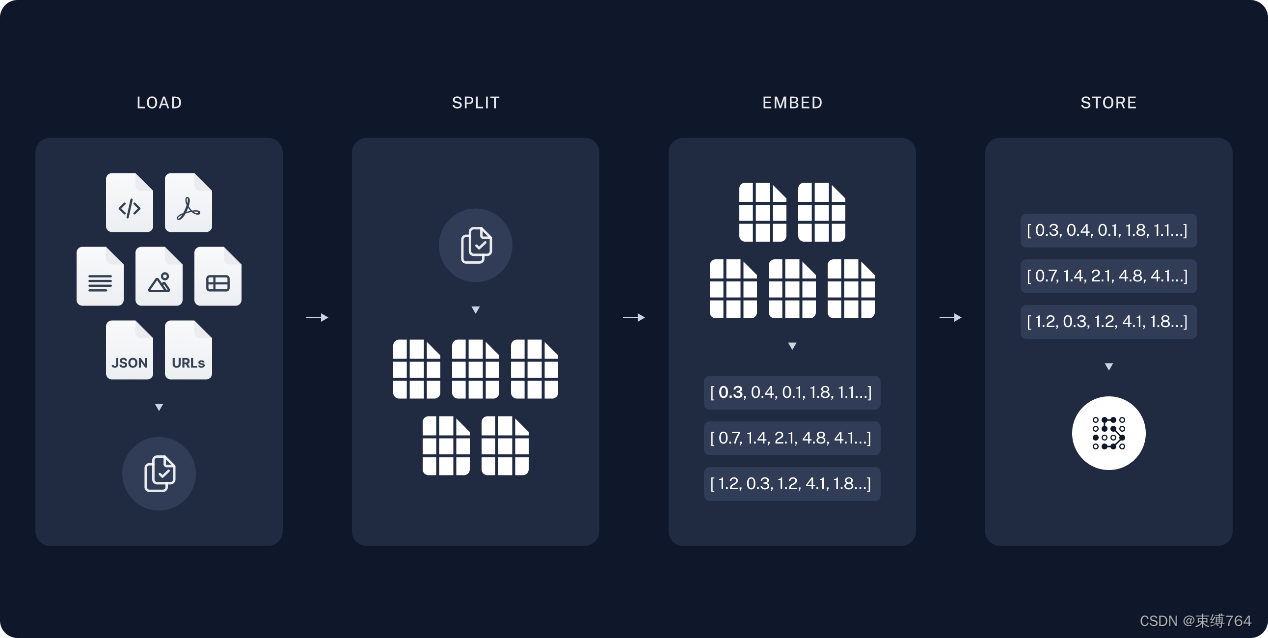
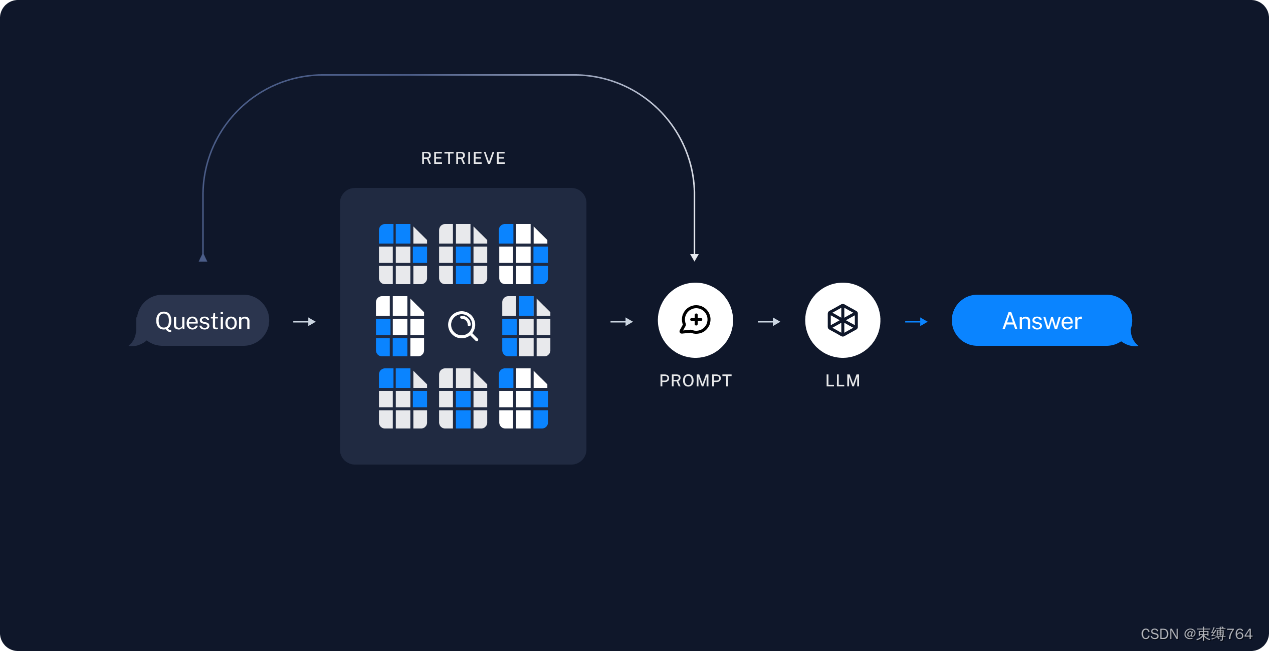
前后端开发
使用阿里云PAI-EAS服务部署模型在线推理,向web应用提供API
后端使用LangChain和Spring Boot框架,构建强大的应用程序
前端使用VUE框架
参考:
LLaMA-2-7B数学能力上限已达97.7%?Xwin-Math利用合成数据解锁潜力 - 知乎
7B开源数学模型干翻千亿GPT-4,中国团队出品_澎湃号·湃客_澎湃新闻-The Paper


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









