






基于连接灵敏度的显著性标准,该标准为给定任务识别网络中结构上重要的连接,这消除了预训练和复杂的修剪计划的需要,同时使其对架构变化具有健壮性。
一、特性
1.简单。由于网络在训练前修剪一次,因此不需要预训练和复杂的修剪计划,没有额外的超参数,一旦修剪,稀疏网络的训练是按照标准的方式进行的。
2.技术全面,用途广泛的。 由于显著性标准选择了结构上重要的连接,因此它对架构变化具有鲁棒性。因此,该方法适用于各种架构,包括卷积,残差,循环网络,无需修改。
3.可解释的。用一小批数据一次性确定重要的连接,通过改变这个用于修剪的小批处理,我们的方法使我们能够验证保留的连接对于确实是必要的。
二、将神经网络剪枝表述为一个优化问题
给定数据集D = { }
, 稀疏度
神经网络剪枝可以写成如下约束优化问题:
s.t
为标准损失函数,w为神经网络的参数集,m为参数总数,
为标准L0范数
为了衡量每个连接的重要性而不依赖于其权重,因此我们引入辅助指标变量表示参数
的连通性,稀疏度
,(1)式可以修改为
与一式相比,我们将网络中可学习参数的数量增加了一倍,直接优化二式更加困难,由于我们已经将连接的权重(w)与连接(c)是否存在分开,我们可能通过测量每个连接对损失函数的影响来确定每个连接的重要性。例如的值表示连接j在网络中是活跃的(
)还是被修剪的
,可以尝试测量两者损耗的差异,保持其他参数不变,去除连接j的效果可以用一下公式来表示:
是元素j的指示向量(除索引j为1外,其他地方都为0),1是m维的向量。
事实上计算对每个
是非常昂贵的,需要遍历m+1此数据集,事实上由于c是二进制的,所以L对于c是不可微的,
试图在这个离散设置中测试连接j对损失函数的影响,因此,我们可以将
近似为L对
的导数,我们将其表示为
事实上是
的无穷小版本,它度量的是L相对于
从
的无穷小变化的变化率。这可以在一次使用自动微分的向前向后传递中有效地计算。一次对所有的j进行计算,这个公式可以看作是用一个乘法因子
扰动权重
,并测量损失的变化。不要将
与关于权重的梯度
混淆,其中损失的变化是根据权重
的加法来测量的。
值得注意的是,我们发现体系结构中重要的连接,这样我们就可以一次性修剪不重要的连接,将修剪过程从迭代优化周期中分离出来。因此我们以导数的大小作为显著性判断依据,如果导数的幅度很高(绝对值),这本质上意味着连接
对损失有相当大的影响,并且必须保留它以允许在
上学习。基于此假设,我们将连接灵敏度定义为导数的归一化幅度:
灵敏度计算完成后,只保留连接,其中
表示所需的非零权重的数量。准确的说,指标变量c设置如下:
其中是向量中第
大元素,
是指标函数,为了保留正确的
连接,可以任意的断开连接。
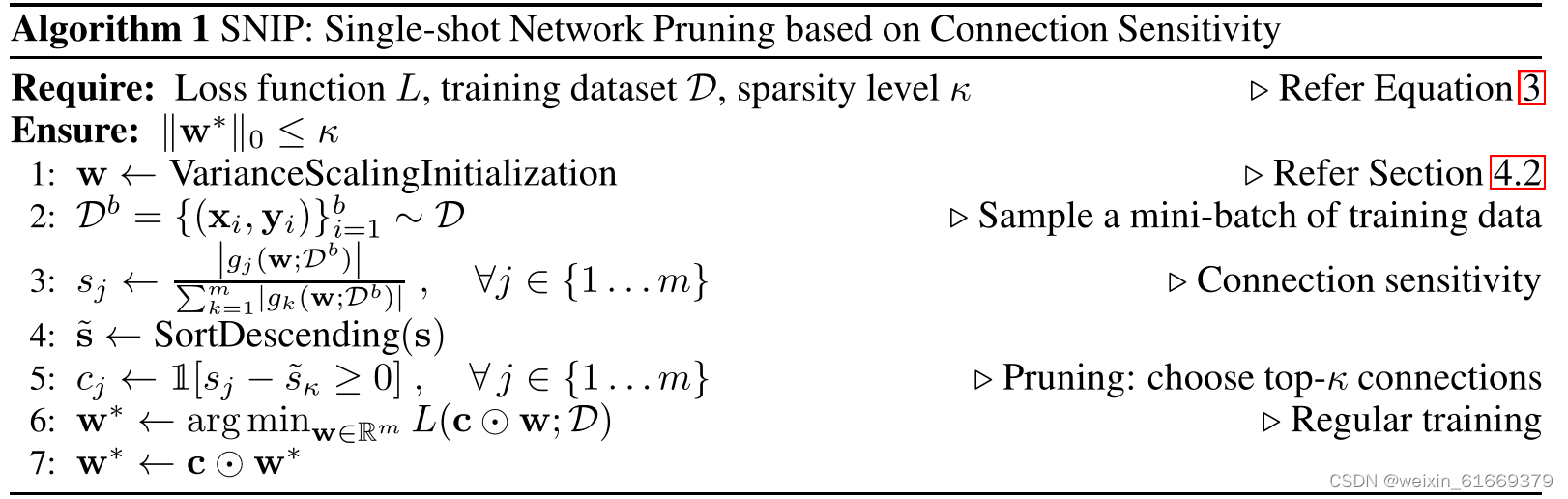
三、原文算法思路如下:
四、初始化时的单发修剪
倡导使用方差缩放方法来初始化权重,以便在整个网络中方差保持相同,通过确保这一点,我们表明,在初始化时计算的显著性度量对架构的变化具有鲁棒性
五、部分代码(pytorch版-摘录-非原创代码)
def SNIP(net, keep_ratio, train_dataloader, device):
inputs, targets = next(iter(train_dataloader))
inputs = inputs.to(device)
targets = targets.to(device)
net = copy.deepcopy(net)
for layer in net.modules():
if isinstance(layer, nn.Conv2d) or isinstance(layer, nn.Linear):
# 给模块添加一个权重掩码参数,初始值为全1张量
layer.weight_mask = nn.Parameter(torch.ones_like(layer.weight))
# 用Xavier初始化权重
nn.init.xavier_normal_(layer.weight)
# 不需要计算权重的梯度
layer.weight.requires_grad = False
if isinstance(layer, nn.Conv2d):
#用snip_forward_conv2d函数替换原来的前向方法
layer.forward = types.MethodType(snip_forward_conv2d, layer)
if isinstance(layer, nn.Linear):
#用snip_forward_linear函数替换原来的前向方法
layer.forward = types.MethodType(snip_forward_linear, layer)
# 计算梯度但不更新
net.zero_grad()
outputs = net.forward(inputs)
loss = F.nll_loss(outputs, targets)
loss.backward()
#创建一个空列表,用于存储每个层权重掩码梯度的绝对值
grads_abs = []
for layer in net.modules():
if isinstance(layer, nn.Conv2d) or isinstance(layer, nn.Linear):
grads_abs.append(torch.abs(layer.weight_mask.grad))
# 将列表中所有张量展平并拼接成一个一维张量
all_scores = torch.cat([torch.flatten(x) for x in grads_abs])
# 计算该张量所有元素之和作为归一化因子
norm_factor = torch.sum(all_scores)
# 将该张量除以归一化因子
all_scores.div_(norm_factor)
#根据保留比例计算要保留的连接数目
num_params_to_keep = int(len(all_scores) * keep_ratio)
#从归一化梯度中选出最大的k个作为阈值
threshold, _ = torch.topk(all_scores, num_params_to_keep, sorted=True)
# 取阈值中最小的一个作为可接受分数
acceptable_score = threshold[-1]
keep_masks = []
for g in grads_abs:
# 将该层归一化梯度大于等于可接受分数的位置设为1,否则设为0,并添加到列表中
keep_masks.append(((g / norm_factor) >= acceptable_score).float())
# 打印保留掩码中所有1的个数,即保留连接的个数
print(torch.sum(torch.cat([torch.flatten(x == 1) for x in keep_masks])))
#返回保留掩码列表
return(keep_masks)def apply_prune_mask(net, keep_masks):
"""
这几行代码使用filter函数和lambda表达式来筛选出net中所有可以被剪枝的层,也就是卷积层或全连接层。这样做是为了确保每一层和对应的保留掩码能够一一匹配。筛选出来的层被存储在prunable_layers变量中。
"""
prunable_layers = filter(
lambda layer: isinstance(layer, nn.Conv2d) or isinstance(
layer, nn.Linear), net.modules())
"""
这一行使用zip函数和for循环来遍历prunable_layers和keep_masks中的元素,每次取出一对层和保留掩码,分别赋值给layer和keep_mask变量
"""
for layer, keep_mask in zip(prunable_layers, keep_masks):
# 这一行使用assert语句来检查layer的权重形状是否与keep_mask的形状相同,如果不同则抛出异常。
assert (layer.weight.shape == keep_mask.shape)
"""
这几行代码定义了一个内部函数,名为hook_factory,它接受一个参数:keep_mask。它的作用是返回一个钩子函数(hook),用于在反向传播时将梯度乘以保留掩码。由于Python的晚绑定机制,如果直接在循环中定义钩子函数,则所有的钩子函数都会获取最后一个保留掩码。通过另外定义一个工厂函数来返回钩子函数可以避免这个问题"""
def hook_factory(keep_mask):
def hook(grads):
return grads * keep_mask
return hook
"""
这一行代码实现了剪枝的第一步:将被删除的权重设为零。具体做法是使用索引操作来选取layer.weight.data中与keep_mask相对应且值为0的元素,并将它们赋值为0.注意这里只处理了权重而没有处理偏置(bias)。"""
layer.weight.data[keep_mask == 0.] = 0.
"""
这一行代码实现了剪枝的第二步:确保被删除权重的梯度始终为零。具体做法是使用register_hook方法来给layer.weight注册一个钩子函数(hook),该钩子函数由前面定义好的hook_factory根据当前的keep_mask生成。"""
layer.weight.register_hook(hook_factory(keep_mask))def train():
writer = SummaryWriter()
net, optimiser, lr_scheduler, train_loader, val_loader = cifar10_experiment()
"""
这一行代码使用SNIP算法对神经网络模型进行预训练剪枝,也就是在训练之前就删除一些不重要的权重或节点。SNIP算法接受四个参数:net是要被剪枝的模型,0.05是剪枝率,表示要保留5%的权重或节点,train_loader是用于计算权重重要性的数据加载器,device是运行设备(CPU或GPU)。SNIP算法返回一个列表,包含了每一层的保留掩码(keep_mask)。"""
keep_masks = SNIP(net, 0.05, train_loader, device) # TODO: shuffle?
"""
这一行调用了前面定义好的apply_prune_mask函数,将保留掩码应用到神经网络模型上,实现剪枝效果。
"""
apply_prune_mask(net, keep_masks)
"""
这一行使用ignite库提供的create_supervised_trainer函数创建了一个训练器对象(trainer),它接受四个参数:net是要被训练的模型,optimiser是优化器对象,F.nll_loss是损失函数对象(负对数似然损失),device是运行设备。训练器对象可以执行训练循环,并在每次迭代后更新模型参数。
"""
trainer = create_supervised_trainer(net, optimiser, F.nll_loss, device)
"""
这一行使用ignite库提供的create_supervised_evaluator函数创建了一个评估器对象(evaluator),它接受三个参数:net是要被评估的模型, {‘accuracy’: Accuracy(), ‘nll’: Loss(F.nll_loss)} 是一个字典, 表示要计算哪些指标,并给出相应的指标对象, device 是运行设备。 评估器对象可以执行评估循环,并在每次迭代后计算指标值。"""
evaluator = create_supervised_evaluator(net, {
'accuracy': Accuracy(),
'nll': Loss(F.nll_loss)
}, device)
# 这一行创建了一个ProgressBar对象(pbar),用于在控制台显示训练进度条
pbar = ProgressBar()
#这一行将ProgressBar对象附加到训练器对象上,使得在每次迭代时更新进度条
pbar.attach(trainer)
@trainer.on(Events.ITERATION_COMPLETED)
def log_training_loss(engine):
lr_scheduler.step()
iter_in_epoch = (engine.state.iteration - 1) % len(train_loader) + 1
if engine.state.iteration % LOG_INTERVAL == 0:
engine.state.output))
writer.add_scalar("training/loss", engine.state.output,
engine.state.iteration)
"""
这几行代码定义了一个函数,名为log_epoch,并使用@trainer.on(Events.EPOCH_COMPLETED)装饰器将其注册到训练器对象上,使得在每个训练周期结束时执行该函数。该函数的作用是使用评估器对象在验证集上运行评估循环,并获取评估结果中的平均准确率(avg_accuracy)和平均损失值(avg_nll),然后将它们写入TensorBoard中,并使用writer.add_scalar方法将其分别写入"validation/loss"和"validation/accuracy"标签下。"""
@trainer.on(Events.EPOCH_COMPLETED)
def log_epoch(engine):
evaluator.run(val_loader)
metrics = evaluator.state.metrics
avg_accuracy = metrics['accuracy']
avg_nll = metrics['nll']
writer.add_scalar("validation/loss", avg_nll, engine.state.iteration)
writer.add_scalar("validation/accuracy", avg_accuracy,
engine.state.iteration)
trainer.run(train_loader, EPOCHS)
writer.close()















 5165
5165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









