







Sanity-Checking Pruning Methods: Random Tickets can Win the Jackpot
健全性检查修剪方法:随机门票可以赢得头奖

摘要:
网络修剪是一种以最小的性能降级来减少测试时间计算资源需求的方法。剪枝算法的传统智慧建议:(1)剪枝方法利用来自训练数据的信息来寻找好的子网络;(2)修剪网络的架构对于良好的性能至关重要。在本文中,我们对最近的几种非结构化剪枝方法进行了上述信念的健全性检查,令人惊讶地发现:(1)一组旨在寻找随机初始化网络的良好子网络的方法(我们称之为“初始票证”),几乎没有利用来自训练数据的任何信息;(2)对于这些方法得到的剪枝网络,在保持每层保留权重总数不变的同时,随机改变每层保留权重,不会影响最终性能。这些发现启发我们为每一层选择一系列简单的独立于数据的修剪比率,并相应地随机修剪每一层以获得一个子网(我们称之为“随机票证”)。实验结果表明,与现有的"初始票证"相比,我们的零触发随机票证的性能更好或达到类似的性能。此外,我们确定了一个现有的修剪方法,通过了我们的健全性检查。我们将随机票据中的比率与该方法进行了混合,并提出了一种称为“混合票据”的新方法,实现了进一步的改进。
总结
Sanity-Checking Pruning Methods: Random Tickets can Win the Jackpot /Code
文章对于之前剪枝工作进行两点总结:(1)剪枝算法是通过从训练数据集中获取信息,来寻找好的子网络结构。(2)好的网络结构对于模型性能是至关重要的。该文章通过设计sanity-checking实验对上面两点结论进行检验。
结果发现:(1)剪枝算法在寻找好的网络结构时,很难从训练集获取有效信息。(2)对于被剪枝网络结构,改变每层权重连接位置但是保持总体权重数量和数值不变,模型精度不变。这一结果反驳了上述总结第二点。由此,得出结论只有网络层的连接数或者压缩率才是真正影响模型性能的因素。这些发现促使作者,利用与数据集无关的每一层剪枝比例,在每一层去随机减去模型权重,获得“intial ticket”与上述方法获得“intial ticket”效果类似。
原文链接:https://blog.csdn.net/fourteen_zhang/article/details/111413240
一:引言
深度神经网络在超参数化领域取得了巨大的成功[2,7,8,35,44]。然而,过度参数化也会导致过多的计算和内存需求。为了缓解这种情况,网络修剪[6,14,15,22,33]已被提议作为一种有效的技术,以最小的性能降级来减少资源需求。以再训练[14]为例,修剪方法的一个典型行可以描述如下:首先,使用修剪方法找到原始网络的子网(我们称之为“修剪步骤”),然后,重新训练这个子网以获得最终修剪的网络(我们称之为“再训练步骤”)。(图1)。不同的修剪方法主要通过寻找子网的不同标准、分配给子网的不同权重和再训练方案来区分。

图1:获得最终修剪网络的典型管道。第一步是(通常)依赖于数据的修剪步骤,它找到原始网络的子网。第二步是再训练步骤,训练子网以实现与整个网络相比最小的性能下降。我们的健全性检查应用于在修剪步骤中使用的数据和在修剪步骤中获得的子网的分层结构,即每层中的连接。
一般来说,这种修剪程序背后有两个共同的信念。首先,据信修剪方法在修剪步骤中利用来自训练数据的信息来找到好的子网络。因此,只有少数数据无关的剪枝方法[34],这些方法是否能获得与流行的数据相关剪枝方法相似(甚至更好)的性能尚不清楚。第二,据信修剪网络的架构对于获得具有良好性能的最终修剪网络至关重要[14]。因此,剪枝文献中的大多数论文通常使用“随机剪枝”,即根据剪枝比例随机选择一定数量的权重/神经元进行剪枝,作为弱基线来表明剪枝方法优于琐碎的随机架构。然而,我们质疑这两种信念是否真的成立。为了评估它们,我们提出了两组健全性检查方法,检查在修剪步骤中使用的数据和被修剪网络的结构对于非结构化修剪方法的被修剪网络的最终性能是否是必不可少的(参见第2.2节)
为了评估对数据的依赖性,我们建议在修剪步骤中破坏数据,同时在再训练步骤中使用原始数据,并查看使用破坏的数据修剪的子网是否可以获得与使用真实数据修剪的子网相似的性能。为了测试被修剪的子网的结构的重要性,我们引入了一种新的对网络结构的攻击,我们称之为分层重排。这种攻击重新排列了神经元层的所有连接,因此完全破坏了修剪步骤中获得的结构。值得注意的是,在应用分层重排后,每个层中保留的权重数量保持不变。相反,如果我们重新排列整个子网中的连接,得到的子网基本上与通过随机修剪获得的子网相同。我们请读者参考图1,了解我们在哪里部署健全性检查。
然后,我们在ICLR 2019年和2020年最近的四篇论文中对修剪方法进行了理智检查[9,23,37,41]。我们首先将这些方法找到的子网络分为“初始票证”,即重新训练前的权重设置为初始化时的权重(这一概念与[9]中的“获胜票证”相同),以及“部分训练票证”,即重新训练前的权重设置为来自预处理过程中间的权重4(形式定义见第4.1节,图示见图2)。“彩票假说(LTH)”[9]突出了“初始票”的有效性,“部分训练票”的方法对[9]中的原始方法做了一些修改。
我们表明,上述两种信念对于“初始票”来说不一定都是正确的。具体来说,即使通过在修剪步骤中使用损坏的数据或重新排列初始票据层来获得子网络,也可以训练子网络以获得与初始票据相同的性能。这一令人惊讶的发现表明,真实数据对于这些方法来说可能不是必需的,并且被修剪的网络的体系结构对最终性能的影响可能有限。
受健全性检查结果的启发,我们建议为每一层选择一系列简单的与数据无关的修剪比率,并相应地随机修剪每一层,以在初始化时获得子网(我们称之为“随机票证”)。这种零触发方法超越了初始化时的单触发修剪方法[23,41]。具体来说,我们的随机票是在没有任何预处理优化或任何数据相关修剪标准的情况下绘制的,因此我们节省了修剪的计算成本。实验结果表明,与现有的所有"初始票证"相比,我们的零触发随机票证的性能更好或达到类似的性能。尽管我们只尝试了一些简单形式的剪枝比率,没有进行太多的调整,但随机票的成功进一步表明,我们的分层比率可以作为神经架构搜索的紧凑搜索空间[4,25,36,47,48]。
此外,我们还发现ICLR 2020 [37]中一种非常新的修剪方法,用于获取“部分训练门票”可以通过我们的心智检查。然后,我们将设计随机票证的见解与部分训练的票证进行混合,并提出了一种称为“混合票证”的新方法。实验结果表明,该混合票可以实现对部分训练票的进一步改进。
总之,我们的结果主张重新评估现有的修剪方法。我们的健全性检查也启发我们设计独立于数据和更有效的剪枝算法。
二:准备工作
2.1符号
我们使用 D = { x i , y i } i = 1 n D = \{xi, yi\}_{i=1}^{n} D={xi,yi}i=1n来表示训练数据集,其中 x i x_i xi表示样本, y i y_i yi表示标签。我们考虑一个具有L层的神经网络,用于D上的分类任务。我们使用向量 W l ∈ R m l W_l∈R^{m_l} Wl∈Rml表示L层中的权重,其中 m l m_l ml是L层中的权重数。然后网络可以表示为 f ( W 1 , ⋅ ⋅ ⋅ , W L ; x ) f(W_1,···,W_L;x) f(W1,⋅⋅⋅,WL;x)其中x是网络的输入。分类的目标是在网络和目标标签的输出上最小化误差函数,即 ∑ i = 1 n l ( f ( W 1 , ⋅ ⋅ ⋅ , W L ; x i ) , y i ) \sum{_{i=1}^n}l(f(W_1,···,W_L;x_i),y_i) ∑i=1nl(f(W1,⋅⋅⋅,WL;xi),yi),并且在测试集上测量性能。
2.2 非结构化修剪(修剪单个权重)
网络修剪方法的一个主要分支是非结构化修剪,它可以追溯到最优脑损伤[22]和最优脑外科医生[16],它们基于损失函数的Hessian修剪权重。最近,[13]提出用小幅度修剪网络权重,并将修剪方法结合到“深度压缩”管道中以获得有效的模型。为非结构化剪枝提出了其他几个标准和设置[6,31,39]。除了非结构化修剪之外,还有结构化修剪方法[1,20,21,24,26,29,42],它们在卷积通道或更高粒度的级别上进行修剪。本文主要研究非结构化剪枝。非结构化剪枝可以看作是一个在权重上寻找一个掩码的过程,该掩码决定了要保留的权重。从形式上来说,我们给出以下定义进行清晰的描述:
掩码。我们使用 c l ∈ { 0 , 1 } m l c_l∈\{0,1\}^{m_l} cl∈{0,1}ml来表示 w l w_l wl上的掩码。那么修剪后的网络由 f ( c 1 ⊙ w 1 , ⋅ ⋅ ⋅ , c L ⊙ w L ; x ) f (c_1⊙w1,···,c_L⊙w_L;x) f(c1⊙w1,⋅⋅⋅,cL⊙wL;x)。
稀疏性和保持率。修剪网络的稀疏度p计算为 p = 1 − ∑ l = 1 L ∣ ∣ c l ∣ ∣ 0 ∑ l = 1 L m l p = 1-{{\sum{_{l=1}^L}||c_l||_0}\over{\sum{_{l=1}^L}m_l}} p=1−∑l=1Lml∑l=1L∣∣cl∣∣0,其中k k0表示非零元素的数量。我们进一步将l层的“保持率”表示为 ∣ ∣ c l ∣ ∣ m l ||c_l||\over{m_l} ml∣∣cl∣∣。
2.3修剪管道和票证
在图1中,我们展示了一个典型的网络修剪流水线,其中我们首先修剪整个网络并获得一个子网,然后重新训练被修剪的子网。修剪和再训练的过程可以反复重复[13],这需要更多的时间。在本文中,我们重点关注一次性修剪[14],它不迭代管道。我们评估了最近提出的几种剪枝方法,这些方法可以使用“彩票假设”[9]中采用的“彩票”名称分类如下:
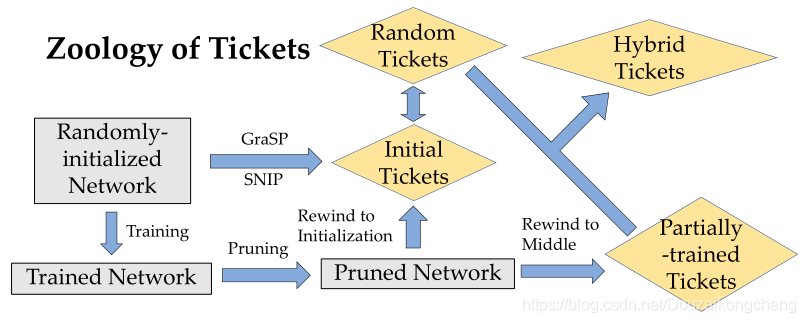
图2:本文考虑的门票生态。第2.3节介绍了初始票和部分培训票,第4.2节提出了随机票,第5.2节提出了混合票。
初始票证: 这类方法旨在找到随机初始化网络的一个子网络,我们称之为“初始票证”,它可以被训练以达到与原始网络相似的测试性能。初始票证包括初始化时的修剪[23,41]和[9]中提出的方法。
部分训练的票: 与初始票不同,部分训练的票是通过首先训练网络,修剪网络,然后将权重倒回到某个中间阶段来构建的[37]。通过[9]中的方法找到的初始票证可以被视为倒回到纪元0。
我们在图2中展示了这两种票证,以及我们建议的新票证,这些票证将在后面的章节中介绍。
三:健全性检查方法
在本节中,我们提出健全性检查方法,用于测试修剪方法的一些常见信念是否真的适用于最近提出的几种方法
3.1检查对数据的依赖
性流行的修剪方法通常利用修剪步骤中的数据来找到一个良好的修剪子网,该子网可以被训练为在相同的数据上执行与整个网络一样的操作(图1)。然而,没有明确的证据表明修剪步骤中使用的数据很重要。此外,从现有的少数与数据无关的剪枝方法[34]来看,也很难判断与数据无关的方法是否有可能获得与流行的与数据相关的剪枝方法相似的性能。因此,我们提出以下问题:
数据信息对于在修剪步骤中找到好的子网有用吗?
为了回答这个问题,我们引入了两种操作,使用随机标签和随机像素来破坏数据[44]。请注意,与[44]中使用这两种操作来演示超参数化网络是否可以收敛于坏数据不同,我们对修剪步骤中使用的数据应用这些操作,以检查损坏的数据是否仍然会导致好的子网。除了这些强破坏之外,我们还提供了一个较弱的检查,它只减少数据的数量,但不会破坏数据。具体来说,我们将这两种操作定义如下:

3.2检查被修剪网络的架构的重要性
在非结构化修剪中,被修剪子网的架构或神经元的连接长期以来被认为是使被修剪网络能够实现与原始网络相当的性能的关键[14]。因此,随机剪枝,即根据给定的稀疏度p随机选择 ( 1 − p ) ⋅ ∑ l = 1 L m l (1-p)·\sum{_{l=1}^L}m_l (1−p)⋅∑l=1Lml权重来保存,被广泛用作基线方法,以更仔细设计的标准来显示剪枝方法的有效性。
然而,我们怀疑被修剪的子网中的这些单独的连接是否是关键的,或者是否有任何中间因素决定被修剪的网络的性能。具体来说,我们回答以下问题:被修剪的子网的体系结构在多大程度上影响最终性能?
为了回答这个问题,我们提出了一种新的分层重排策略,该策略保留了每一层中保留权重的数量,但完全破坏了通过每一层的剪枝方法找到的网络结构(连接)。作为附加参考,我们还引入了一个弱得多的分层权重混洗操作,它只混洗未屏蔽的权重,但保持连接。
分层重排:得到修剪后的网络,即 f ( c 1 ⊙ w 1 , ⋅ ⋅ ⋅ , c L ⊙ w L ; x ) f (c_1⊙w1,···,c_L⊙w_L;x) f(c1⊙w1,⋅⋅⋅,cL⊙wL;x),我们将每一层的掩码 c l c_l cl独立地随机重排为$ \widehat{a}_l , 然 后 用 重 排 后 的 掩 码 ,然后用重排后的掩码 ,然后用重排后的掩码f (\widehat{c}_1⊙w1,···,\widehat{c}_L⊙w_L;x)$。我们在附录a中给出了该操作的说明。
分层权重混洗:分层权重不会改变遮罩,但会独立混洗每个层中未遮罩的权重。
有了上面的方法,我们就可以对现有的修剪方法进行健全性检查了。
四:案例研究:初始票证
在本节中,我们将对第2.3节中定义的“初始票证”进行健全性检查。令人惊讶的是,我们的结果表明,当在修剪步骤中使用包括随机标签和随机像素的损坏数据时,重新训练的“初始票证”的最终性能不会下降。此外,分层重排也不影响“初始票证”的最终性能。这一发现进一步启发我们设计一种零镜头剪枝方法,称为“随机票”。
4.1初始票证未能通过健全性检查
我们对最近提出的三种可归类为“初始票证”的剪枝方法进行了实验。我们首先简要描述这些方法:
- SNIP [23]和GraSP [41]:这两种方法在初始化时通过使用不同的标准找到掩码来修剪网络。具体来说,SNIP利用连接敏感度的概念作为权重对损失重要性的度量,然后移除不重要的连接。GraSP旨在通过最大化被修剪的子网的梯度来保持通过网络的梯度流。这些方法的优点是,与需要预处理的方法相比,它们可以通过在初始化时修剪来节省训练时间[13]。
- 彩票(LT) [9]:彩票的剪枝过程遵循一个标准的三步流水线:首先训练一个完整的网络,使用基于幅度的剪枝[13]获得彩票的体系结构,并将权重重置为初始化值以获得初始彩票。6
在获得初始票后,我们用标准方法对它们进行训练,并评估最终模型的测试精度。在ResNet [19]和VGG [38]的整篇论文中,我们遵循标准的训练程序[17,23,41]。详细设置见附录b
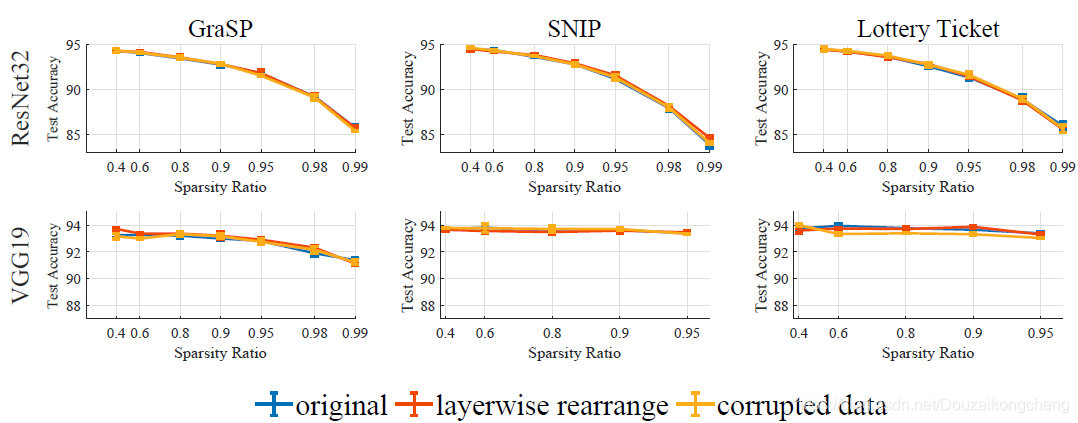
图3:CIFAR 10上的ResNet32和VGG19的初始票证的健全性检查。
为了健全检查这三种方法并回答第3节中提出的激励性问题,我们应用了工具箱中最强的两种检查。
我们首先检查修剪过程是否可以利用训练数据上的信息。为了实现这个目标,我们在修剪步骤中使用了第3节中的随机标签和随机像素损坏的组合。然后我们在原始的CIF AR-10数据集上训练这些票。令人惊讶的是,由损坏的数据集生成的所有初始票据的行为与最初挑选的票据一样好(图3)。
给定对修剪步骤中使用的数据的弱依赖性,我们接着研究初始票据的架构(神经元之间的连接)是否重要。然后我们应用我们的分层重排攻击,这完全消除了每个层中学习的连接对初始票证的依赖。我们发现,当应用分层重排攻击时,初始票证的性能没有下降(图3)。这与修剪结构对于获得性能良好的子网至关重要的观点相矛盾。8我们还在CIFAR-100数据集上进行了实验。结果推迟到附录e
4.2随机门票赢得大奖
初始票证的健全性检查结果表明:
-
数据对于找到好的初始票证可能并不重要。
-
初始标签中各层神经元的连接可以完全重新排列,而不会有任何性能下降,这表明只有每层中剩余连接的数量或保持率(回想第2.2节中的定义)才是重要的。
基于这些观察,我们只需要找到一系列良好的保持率,并相应地随机修剪网络。我们把这个规则得到的子网称为“随机票”。如图2中的票证动物园所示,随机票证可以被视为一种特殊的初始票证,因为它们在初始化时使用权重。同时,对通过现有剪枝方法获得的初始票据应用分层重排可以将这些初始票据转换成随机票据,其中分层保留比由初始票据确定。
虽然我们可以通过上述方式从现有的初始票据中获得保留比率,但我们更愿意进一步直接设计一系列更简单但有效的保留比率。为了实现这个目标,我们首先研究了在VGG和ResNet架构上使用GraSP、SNIP和彩票获得的初始彩票的比率。从这些初始票据中,我们提取了以下保持比率的原则,这些原则可以带来良好的最终性能:
表1:在CIFAR-10和CIFAR-100数据集上测试修剪后的VGG19和ResNet32的准确性。在整篇论文中,粗体数字表示平均准确度在最佳置信区间内。
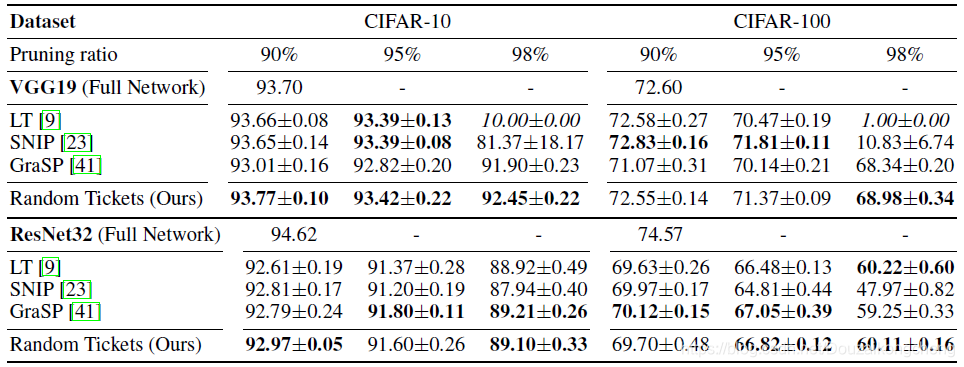
表2:修剪后的VGG19和ResNet32在Tiny-Imagenet数据集上的测试精度。
保持率随深度而降低。对于VGG和ResNet上的所有这些方法,我们观察到初始票据的保持率具有较深层的保持率较低的共同行为,即保持率作为深度的函数而衰减。此外,对于所有三种算法,VGG的保持率比ResNet衰减得更快。9我们还观察到,除了层内保持率下降的总体趋势之外,一些特殊层中的保持率表现不同。例如,ResNet中下采样层的保持比明显大于它们的相邻层。
智能比率。基于这些观察,我们提出了smart-ratio,一系列采用简单递减函数形式的保持比率。具体来说,对于一个L层ResNet,对于任何稀疏性p,我们将线性层的保持比设置为0.3,并让给定层L,即pl(第2.2节)的保持比与 ( L − l + 1 ) 2 + ( L − l + 1 ) (L-l+1)^2+(L-l+1) (L−l+1)2+(L−l+1)成比例。对于VGG,我们用 l 2 l^2 l2除 ( L − l + 1 ) 2 + ( L − l + 1 ) (L-l+1)^2+(L-l+1) (L−l+1)2+(L−l+1)以获得更快的下降。详情见附录三
我们注意到,我们只是通过尝试一些递减函数来选择我们的比率,而没有仔细调整,但是已经获得了良好的性能。我们还对上升保持率和不同速率的下降保持率进行消融研究。实验结果表明,保持率的下降顺序和下降速率对随机票的最终性能至关重要。这部分解释了为什么除了使用定制的层宽比之外,在整个网络上随机修剪的基线通常表现不佳。由于篇幅限制,我们将详细的消融研究放在附录中。此外,我们指出,随着良好的保持率产生良好的子网络,人们可以使用保持率作为神经架构搜索的紧凑搜索空间,这可能是一个有趣的未来方向。
在CIFAR-10/CIFAR-100和Tiny-Imagenet数据集上的测试精度如表1和表2所示。据报道,我们的智能比率随机票在几个基准和稀疏性上超过了几个精心设计的方法。我们注意到,当稀疏度很高时,当使用SNIP或LT时,一些层可能只保留很少的权重,因此测试精度显著下降[17]。最近[40]也观察到这种现象,提出了一种无数据的剪枝方法,能够避免整层崩溃。
六:结论和讨论
在本文中,我们针对非结构化剪枝方法提出了几种健全性检查方法(第3节),这些方法测试在剪枝步骤中使用的数据以及剪枝后的体系结构是否子网对于最终性能至关重要。我们发现,一种被分类为“初始票证”(第2.3节)的修剪方法很难利用来自数据的任何信息,因为随机改变由这些方法逐层获得的子网的保留权重不会影响最终性能。这些发现启发我们设计了一种称为“随机票据”的零触发数据无关剪枝方法,与初始票据相比,该方法的性能更好或达到类似的性能。我们还识别了一种通过我们的健全性检查的现有剪枝方法,并将随机票据与该方法进行杂交,提出了一种新的方法,称为“混合票据”,该方法实现了进一步的改进。我们的发现为重新思考剪枝算法成功的关键因素带来了新的见解。
此外,一个并发和独立的工作[11]得到了与我们的分层重排健全性检查相似的结论。作为对我们结果的补充,在ImageNet上[11]中的结果表明我们的发现可以推广到大规模数据集。我们的两个作品都提倡严格检查未来修剪方法的合理性,并仔细研究在训练早期修剪的机会。















 3930
3930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









