







目录
二、Combined Worksharing Construct: for/Sec-tion
三、Synchronous Construct: barrier/critical/ato-mic
一丶Parallel Construct
1. #include<omp.h>
2. #include<stdio.h>
3. int main()
4. {
5. int id, numb;
6. omp_set_num_threads(3); //此行为可注释行,进行注释调试对比
7. #pragma omp parallel private(id, numb)
8. {
9. id = omp_get_thread_num();
10. numb = omp_get_num_threads();
11. printf("I am thread % d out of % d \n", id, numb);
12. }
13. return 0;
14. }


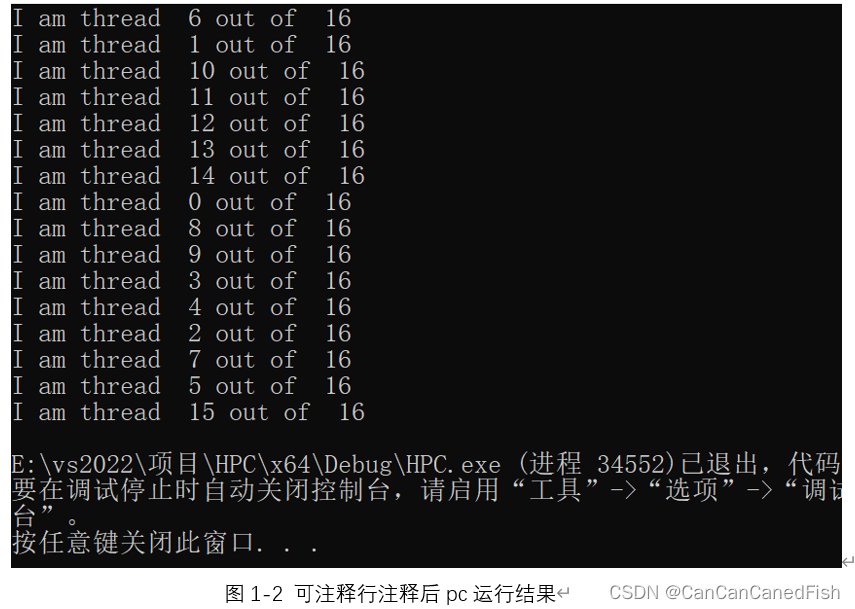

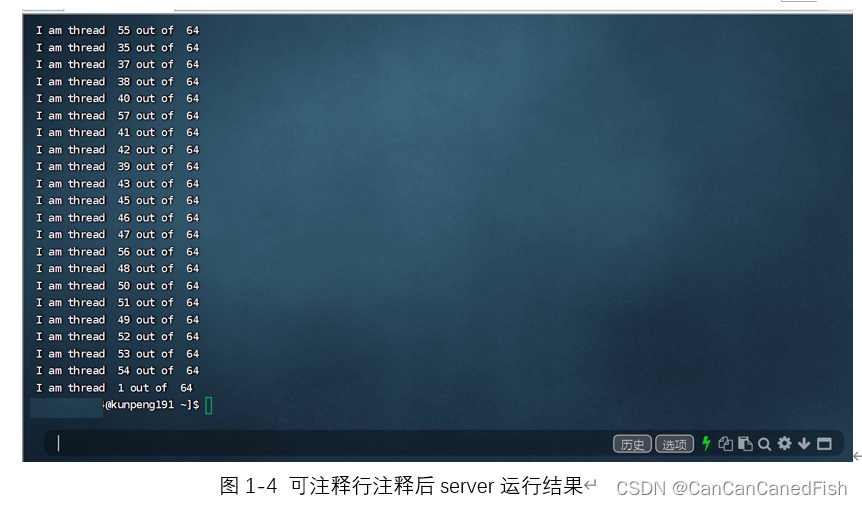
parallel construct会创造一组线程,线程数可以通过指令‘omp_set_num_threads();’来指定,如果不加这行代码,则为电脑cpu默认的线程数。每个线程并行执行一组隐式任务,任务由“#pragma omp parallel private(id, numb){ }”大括号里的代码定义。
本代码运行输出显示:y行的“I am thread x out of y”,x为第几个线程,y为总线程数。当注释掉可注释行代码‘omp_set_num_threads();’时,y为电脑的cpu的线程数(本人pc电脑端线程数为16,华为泰山服务器线程数为64);不注释掉可注释行代码时,y为设定的线程数,本代码为3。由于是并行执行,所以每个线程工作的输出时同时进行的,输出在屏幕上的结果没有一定确定的先后次序。
二、Combined Worksharing Construct: for/Sec-tion
//(1) parallel for
1. #include<omp.h>
2. #include<stdio.h>
3. int main()
4. {
5. #pragma omp parallel for//平均分配线程执行任务
6. for (int i = 0; i < 10; i++) {
7. printf("No.%d iteeration by thread %d\n", i, omp_get_thread_num());
8. }
9. printf("\n");
10. return 0;
11. }
//(2) parallel section
1. #include <stdio.h>
2. #include <omp.h>
3. int main() {
4. #pragma omp parallel sections//每一个线程执行一个section的任务
5. {
6. #pragma omp section
7. for (int i = 0; i < 5; ++i) {
8. printf("section i: iteration %d by thread No.%d\n", i, omp_get_thread_num());
9. }
10. #pragma omp section
11. for (int j = 0; j < 5; ++j)
12. {
13. printf("section j: iteration %d by thread No.%d\n", j, omp_get_thread_num());
14. }
15. }
16. printf("\n");
17. return 0;
18. }
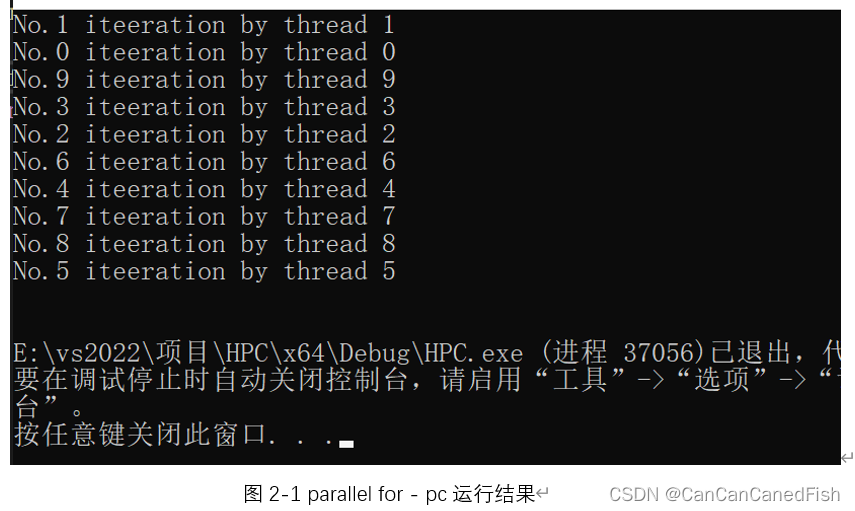
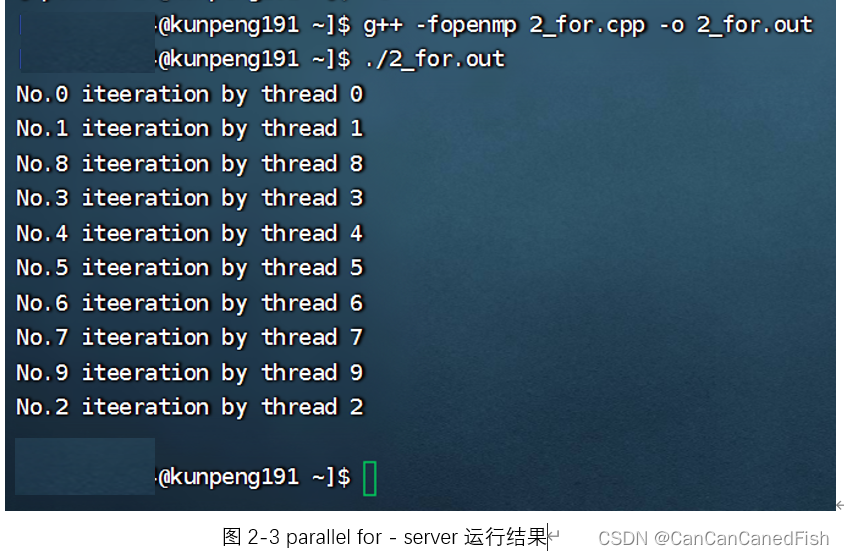

parallel for会将需要执行的任务平均分配给每一个线程,所有线程领到任务后开始并行执行,所以输出到屏幕的次序仍然是不定的。当设定的任务数大于可用线程数时,仍然会平均分配任务,但是会有若干线程有多份任务需要顺序执行,因此设定任务数时需要考虑可用线程数,以免造成线程分配的工作压力过大。
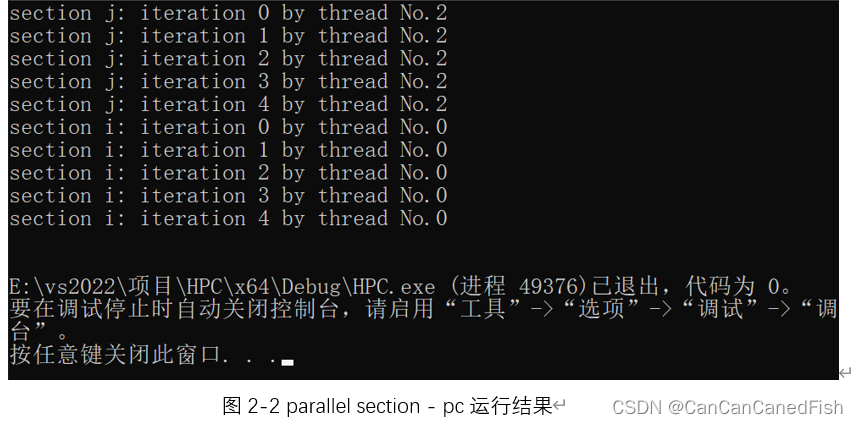
parallel section会将每个section下的任务设定为一块,并且将每个section平均分配给一个线程进行执行,分配原理同parallel for。每个线程在执行section中的任务内容时会顺序进行执行。
三、Synchronous Construct: barrier/critical/ato-mic
//(1) barrier
1. #include<omp.h>
2. #include<stdio.h>
3. int main()
4. {
5. omp_set_num_threads(3);
6. #pragma omp parallel
7. {
8. for (int i = 0; i < 3; ++i)
9. {
10. printf("loop i : iteration %d by thread No. %d\n", i, omp_get_thread_num());
11. }
12. #pragma omp barrier//前面工作做完再开始后面的工作
13. for (int j = 0; j < 3; ++j)
14. {
15. printf("loop j : iteration %d by thread No. %d\n", j, omp_get_thread_num());
16. }
17. }
18. return 0;
19. }
//(2) critical
1. #include<omp.h>
2. #include<stdio.h>
3. int main()
4. {
5. int x;
6. x = 0;
7. #pragma omp parallel shared(x)
8. {
9. #pragma omp critical//可以让并行的指令顺序化进行
10. x = x + 1;
11. }
12. printf("x=%d\n",x);
13. return 0;
14. }
//(3) atomic
1. #include<omp.h>
2. #include<stdio.h>
3. int main()
4. {
5. int x;
6. x = 0;
7. #pragma omp parallel shared(x)
8. {
9. #pragma omp atomic//原子构造,实现顺序化,但只能对一个数值
10. x++;
11. }
12. printf("x=%d\n", x);
13. return 0;
14. }
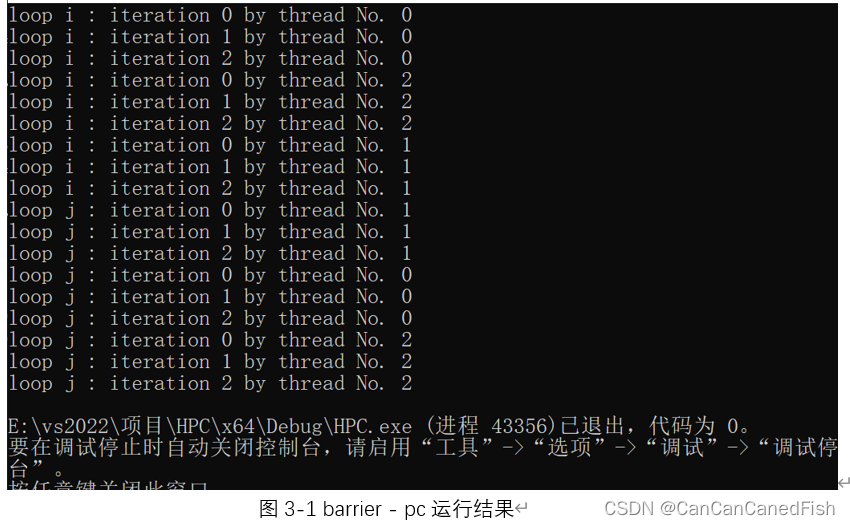

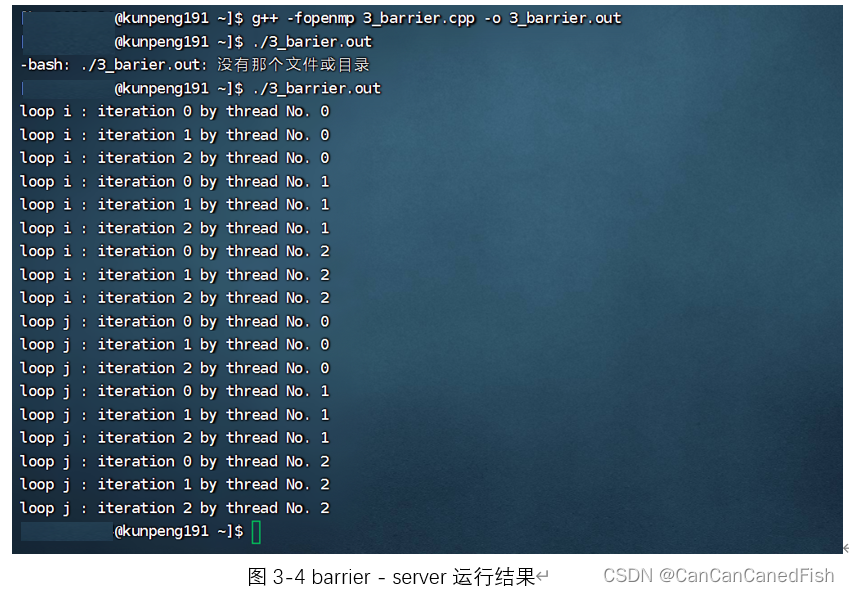

barrier的用途是在其出现在位置设置一个截断,在barrier之前的程序没有执行完毕时,其后的程序无法开始执。本代码中,barrier出现之前的任务执行完毕之后才开始执行barrier之后的任务,其前后两部分分别的执行情况同parallel for,即将任务平均分配给若干个线程同时进行。
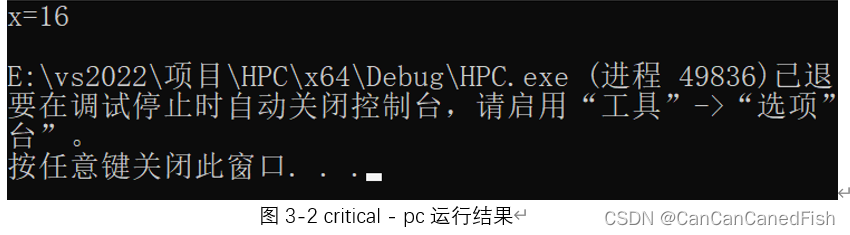
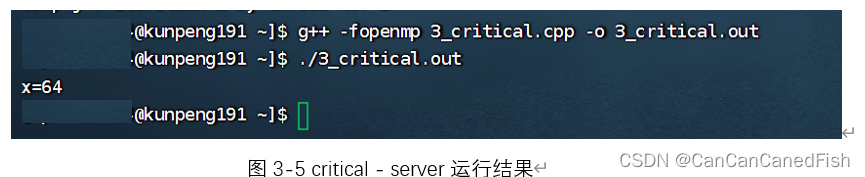
critical是将其块内的程序设定为只能由一个线程执行,atomic是以原子化的方式访问其下的内容。二者的相同之处是均可以将并行执行的指令程序调整为只有一个线程来做的顺序执行,但是由于只有一个线程来运行,此时需要注意运行时间。二者的不同之处在于前者可以将其下的{ }中的内容作为一个块来进行顺序执行,而后者只能将其后的一个指令原子化(如x++可以,而x=x+1则不合法),从而实现顺序化执行。此时由于未手动设置可用线程数,程序由cpu默认线程数进行执行,本电脑为16线程则输出结果为x=16,而华为泰山服务器线程数为64则输出结果为x=64。
四、reduction clause
1. #include<omp.h>
2. #include<stdio.h>
3. static long num_steps = 100000;
4. double step;
5. #define NUM_THREADS 2
6. int main()
7. {
8. int i, id;
9. double x, pi, sum = 0.0;
10. step = 1.0 / (double)num_steps;
11. omp_set_num_threads(NUM_THREADS);
12. #pragma omp parallel private(x,i,id) reduction(+:sum)
13. for (i = 1; i <= num_steps; i++)
14. {
15. id = omp_get_thread_num();
16. for (i = id + 1; i <= num_steps; i = i + NUM_THREADS)
17. {
18. x = (i - 0.5) * step;
19. sum = sum + 4.0 / (1.0 + x * x);
20. }
21. }
22. pi = step * sum;
23. printf("pi=%lf\n", pi);
24. return 0;
25. }

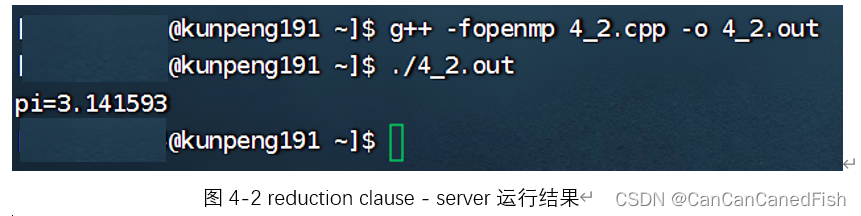
reduction的作用是避免多个线程同时操作同一个变量导致出现错误的情况。以本代码为例,其使用方式是:reduction(+:sum),表示在每个线程进行并行执行运算任务的时候,在其中将全局变量sum进行拷贝,并在其中使用拷贝后的变量sum,这样每个线程在使用sum执行运算的时候就使用的的是不同的sum了,不会再产生数据冲突等问题,在运行结束后再将每个拷贝出来的sum加和到全局sum中,得到正确结果(本代码为模拟积分求出Π的值)。
reduction中的+是一个运算符,表示如何进行规约操作,所谓规约操作简单说来就是多个数据逐步进行某种操作最终得到一个不能够再继续进行规约的数据。本代码中的+即表示规约操作为将所有线程中的sum加和到一起。
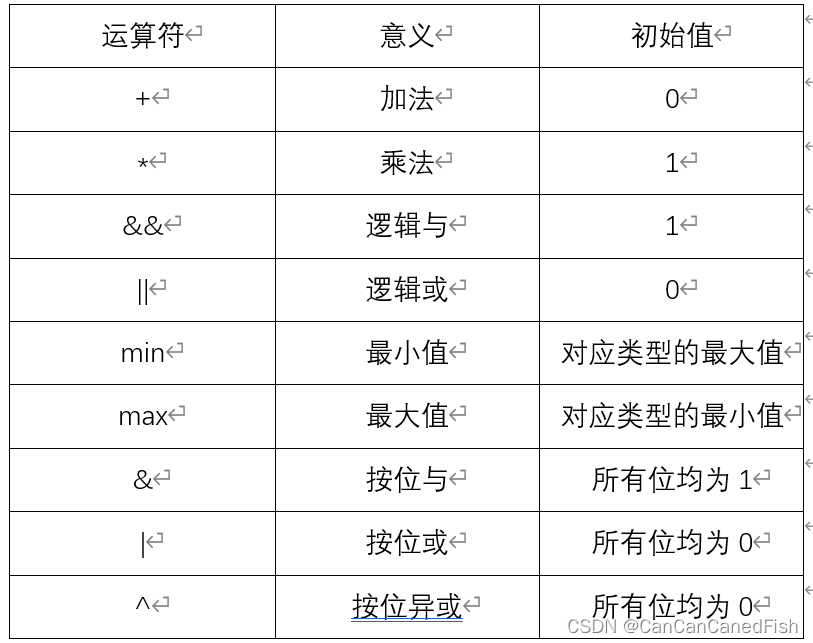
reduction中的操作符有多种,表示不同的规约操作,而每种不同的规约操作也都需要全局变量有一个初始值以保证操作正确。














 1184
1184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









