







一、问题描述
矩阵LU分解是一种重要的数值线性代数运算方法,广泛应用于科学计算、工程问题和数据分析等领域。LU分解的背景可以追溯到高斯消元法,它是一种常用的线性方程组求解方法。高斯消元法将线性方程组的系数矩阵通过行变换转化为上三角形式,然后通过回代求解得到方程组的解。然而,高斯消元法的计算量较大,尤其对于大规模的线性方程组,计算效率较低。
为了提高计算效率,LU分解应运而生。它将线性方程组的系数矩阵分解为一个下三角矩阵L和一个上三角矩阵U的乘积,即A = LU。
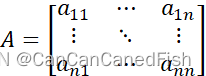
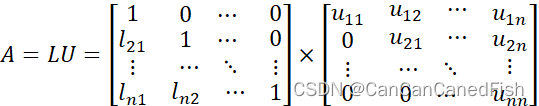
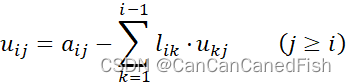

LU分解的优势在于一次分解后可以重复使用,从而在解决多个线性方程组时提高计算效率。此外,LU分解还可以简化解线性方程组、矩阵求逆、特征值计算和奇异值分解等问题的求解过程。
在实际应用中,LU分解通常与其他数值算法结合使用。例如,在求解线性方程组时,可以通过LU分解将系数矩阵分解为L和U,并利用这个分解形式来快速求解多个右端向量的解。对于矩阵求逆,可以通过LU分解将矩阵分解为L和U,并利用这个分解形式来快速求解多个右端向量的解。对于矩阵求逆,可以通过LU分解将矩阵分解为L和U,并利用这个分解形式来快速计算矩阵的逆。
二、平台说明
1.硬件
使用的服务型号为:HUAWEI TaiShan 200服务器(型号2280)。TaiShan 200服务器是基于华为鲲鹏920处理器的数据中心服务器,是2U 2路机架服务器,支持2路处理器,处理器规格为32核2.6GHz。
以12块硬盘配置为例的外观图如图2-1所示。服务器整体外观图如图2-2所示。


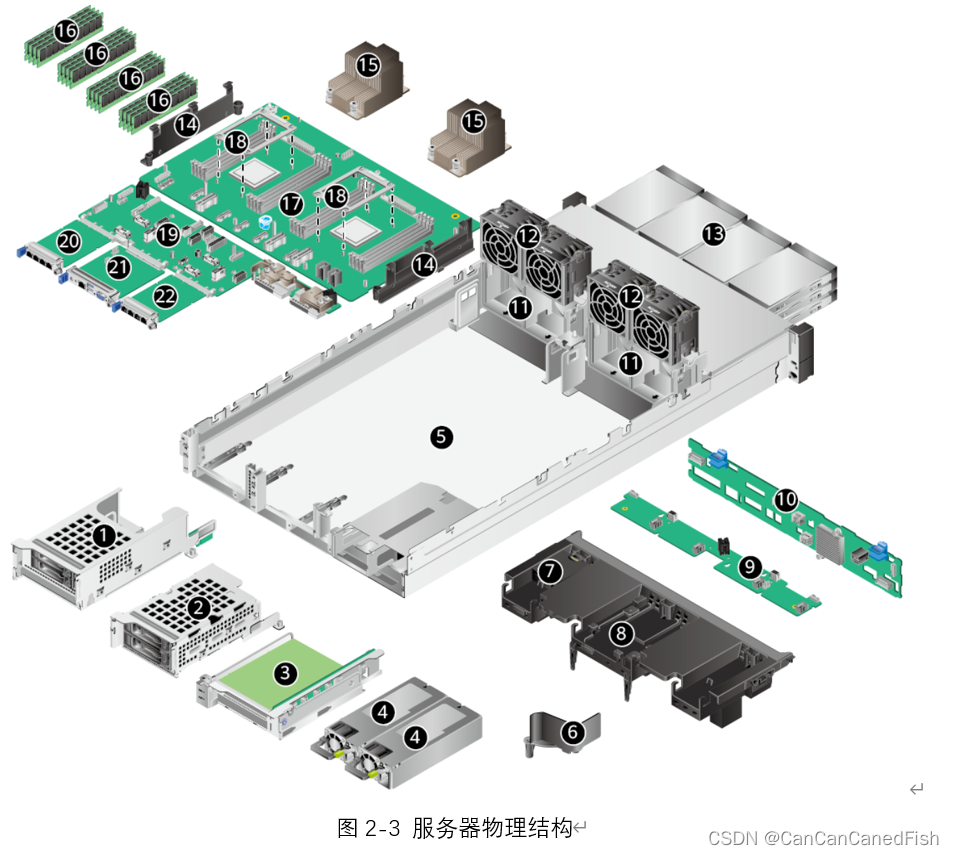
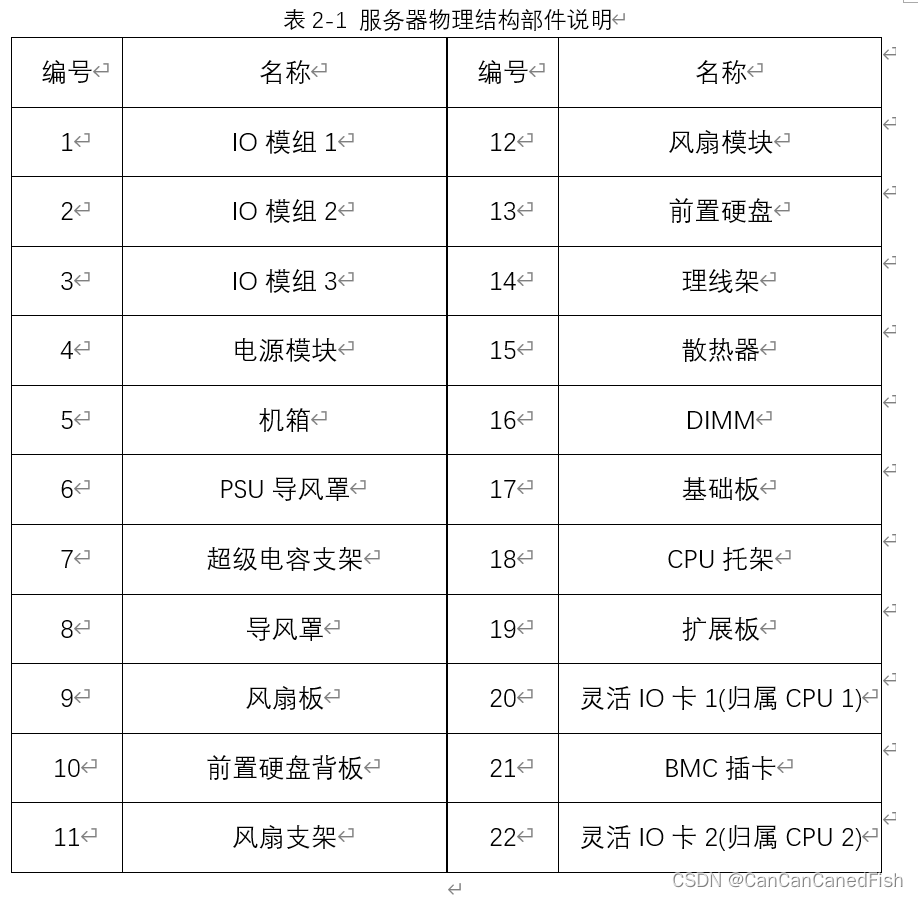
以12盘配置为例的服务器的物理结构如图2-3所示,部件说明如表2-1。
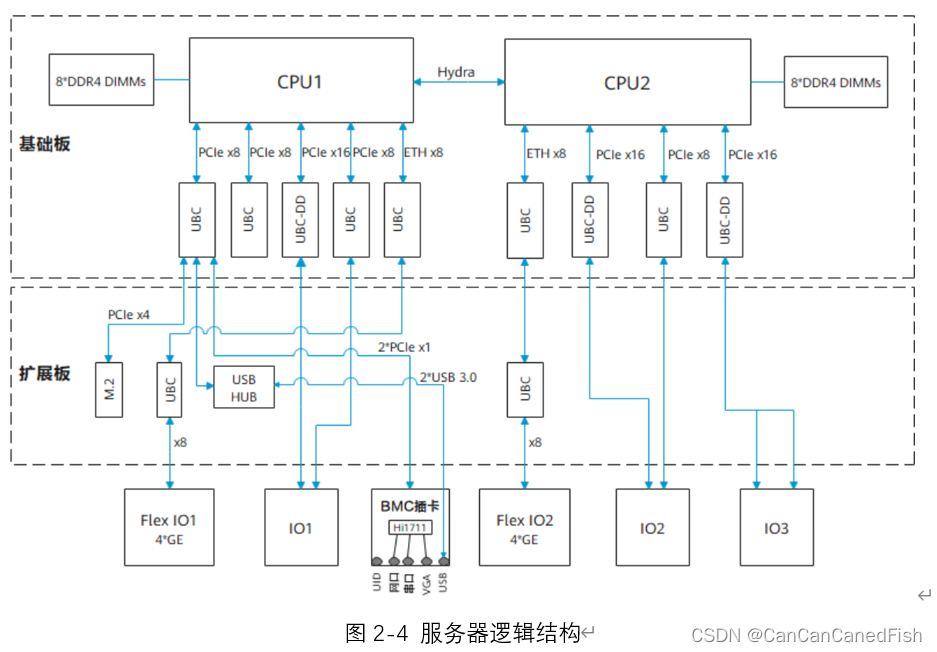
服务器支持Hi1711 BMC插卡,可外出VGA、管理网口、串口、USB Type-C等管理接口,其逻辑结构如图2-4所示。
该服务器支持华为自研的、面向服务器领域的64 bits高性能多核鲲鹏920处理器,内部集成了DDR4、PCIe 4.0、GE等接口,提供完整的SOC功能。单台服务器支持2个处理器,单个处理器最大支持32个内核,能够最大限度地提高多线程应用的并发执行能力。支持多种灵活的硬盘配置方案,提供了弹性的、可扩展的存储容量空间,满足不同存储容量的需求和升级要求。支持灵活插卡,可提供多种以太网卡接口能力。最多可支持8个PCIe 4.0 x8的标准扩展槽位。
擅于面向互联网、分布式存储、云计算、大数据、企业业务等领域,具有高性能计算、大容量存储、低能耗、易管理、易部署等优点。
2.软件
操作系统内核信息:

操作系统版本信息:

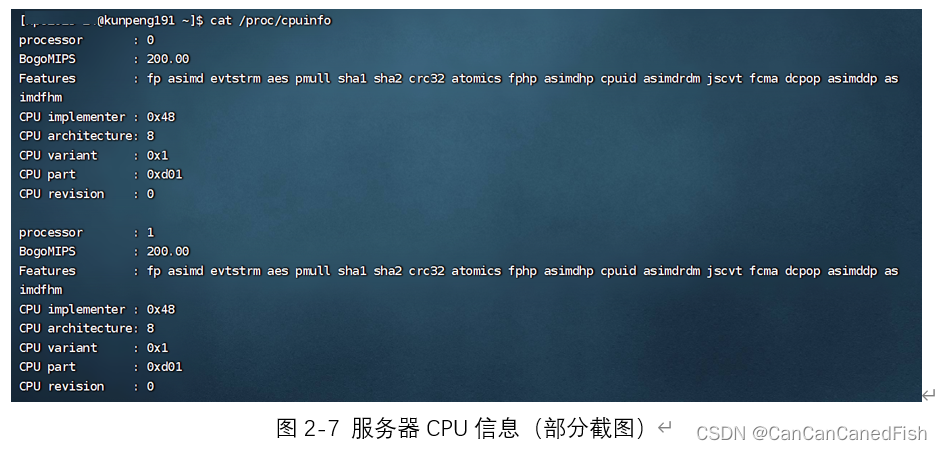
查看CPU详细信息:
查看服务器内存:

三、算法流程图
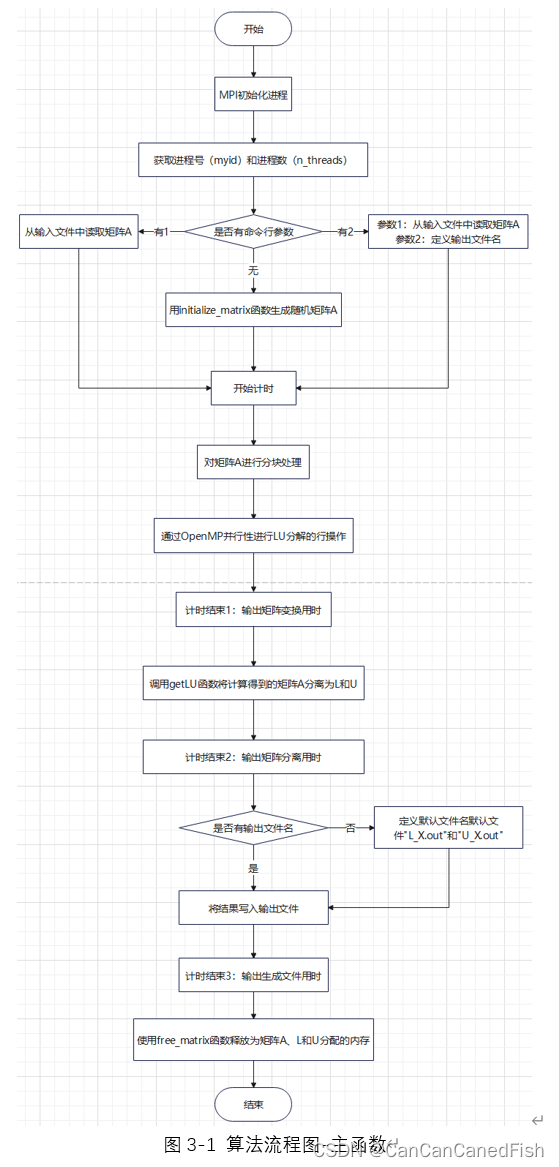
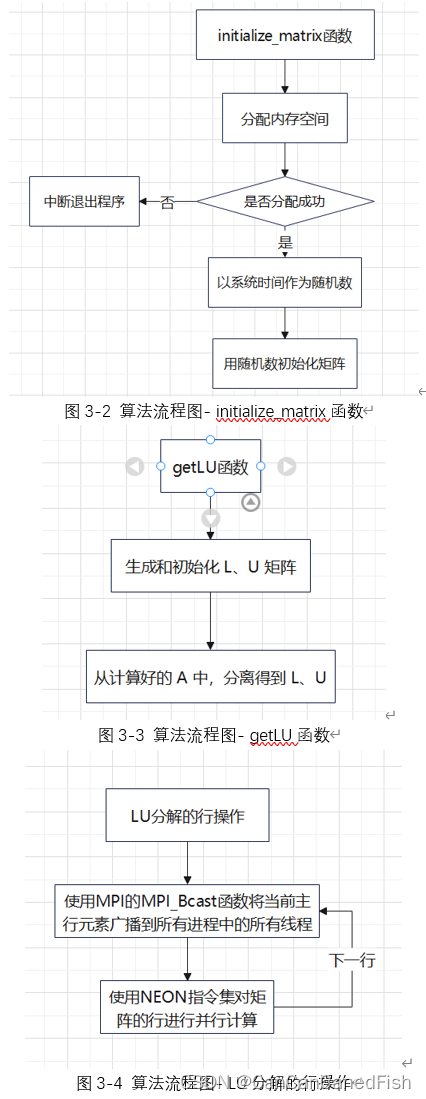
四、代码中的关键并行性
1、MPI并行性:通过MPI_Init()和MPI_Comm_size()函数初始化进程,并使用MPI_Comm_rank()函数获取进程的排名。然后,在主循环中,使用MPI_Bcast()函数将主行元素广播给其他进程,以实现并行计算和通信。
2、OpenMP并行性:通过#pragma omp parallel和#pragma omp for指令实现了OpenMP并行化。在主循环中,使用#pragma omp parallel创建多个线程,然后使用#pragma omp for并行执行对于矩阵进行初等变换的二重循环。这样可以在每个线程上并行处理行操作,加速LU分解的计算过程。
3、NEON指令集并行性:在使用NEON指令集进行计算的部分,通过使用SIMD指令(如vld1q_f32、vmlsq_f32和vst1q_f32),可以在每个迭代步骤中同时处理多个浮点数值,从而实现向量化并行计算。
通过MPI并行性、OpenMP并行性和NEON指令集并行性的结合,该代码能够同时充分利用多个进程、多个线程和向量化处理多个数据,从而加速LU分解的计算过程。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









