






Spark 是一个在大数据开发中非常常用的组件。可以用于 Kafka 的生产者,也可以用于Spark 的消费者。
一、环境准备
1)Scala 环境准备
2)Spark 环境准备
(1)创建一个 maven 项目 spark-kafka
(2)在项目 spark-kafka 上点击右键,Add Framework Support=》勾选 scala
(3)在 main 下创建 scala 文件夹,并右键 Mark Directory as Sources Root=>在 scala 下创
建包名为 com.atguigu.spark
(4)添加配置文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.hadoop</groupId>
<artifactId>spark-kafka</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>spark-kafka</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
</project>
(5)将 log4j.properties 文件添加到 resources 里面,就能更改打印日志的级别为 error
log4j.rootLogger=error, stdout,R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%5L) : %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=../log/agent.log
log4j.appender.R.MaxFileSize=1024KB
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%6L) : %m%n二、Spark 生产者
(1)在 com.atguigu.spark 包下创建 scala Object:SparkKafkaProducer
package com.hadoop.spark
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.kafka.common.serialization.StringSerializer
import java.util.Properties
/**
* @author codestart
* @create 2023-07-11 10:10
*/
object SparkKafkaProducer {
def main(args: Array[String]): Unit = {
// 0 kafka 配置信息
val properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer]);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer]);
// 1 创建 kafka 生产者
val producer = new KafkaProducer[String, String](properties);
// 2 发送数据
for (i <- 1 to 5) {
producer.send(new ProducerRecord[String, String]("first", "hadoophhjkasdf" + i));
}
// 3 关闭资源
producer.close();
}
}
(2)启动 Kafka 消费者
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
(3)执行 SparkKafkaProducer 程序,观察 kafka 消费者控制台情况
三、Spark 消费者
(1)添加配置文件
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.0.0</version>
</dependency>
(2)在 com.atguigu.spark 包下创建 scala Object:SparkKafkaConsumer
package com.hadoop.spark
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
/**
* @author codestart
* @create 2023-07-11 10:51
*/
object SparkKafkaConsumer {
def main(args: Array[String]): Unit = {
//1、初始化上下文环境
val conf = new SparkConf().setMaster("local[*]").setAppName("spark-kafka")
val ssc = new StreamingContext(conf, Seconds(3))
//2、消费数据
//定义 Kafka 参数:kafka 集群地址、消费者组名称、key 序列化、value 序列化
val kafkaPara = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.GROUP_ID_CONFIG -> "hadoop"
)
//读取 Kafka 数据创建 DStream
val KafkaDStream = KafkaUtils.createDirectStream[String,String](ssc,
LocationStrategies.PreferConsistent, //优先位置
ConsumerStrategies.Subscribe[String, String](Set("first"), kafkaPara) // 消费策略:(订阅多个主题配置参数)
)
//将每条消息的 KV 取出
val value = KafkaDStream.map(record => record.value())
value.print()
//7.开启任务
ssc.start()
ssc.awaitTermination()
}
}
(3)启动 SparkKafkaConsumer 消费者
(4)启动 kafka 生产者
bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first
(5)观察 IDEA 控制台数据打印
报错:Timeout of 60000ms expired before the position for partition first-5 could be determined(已解决,主要的是换一个每个分区有leader的topic)
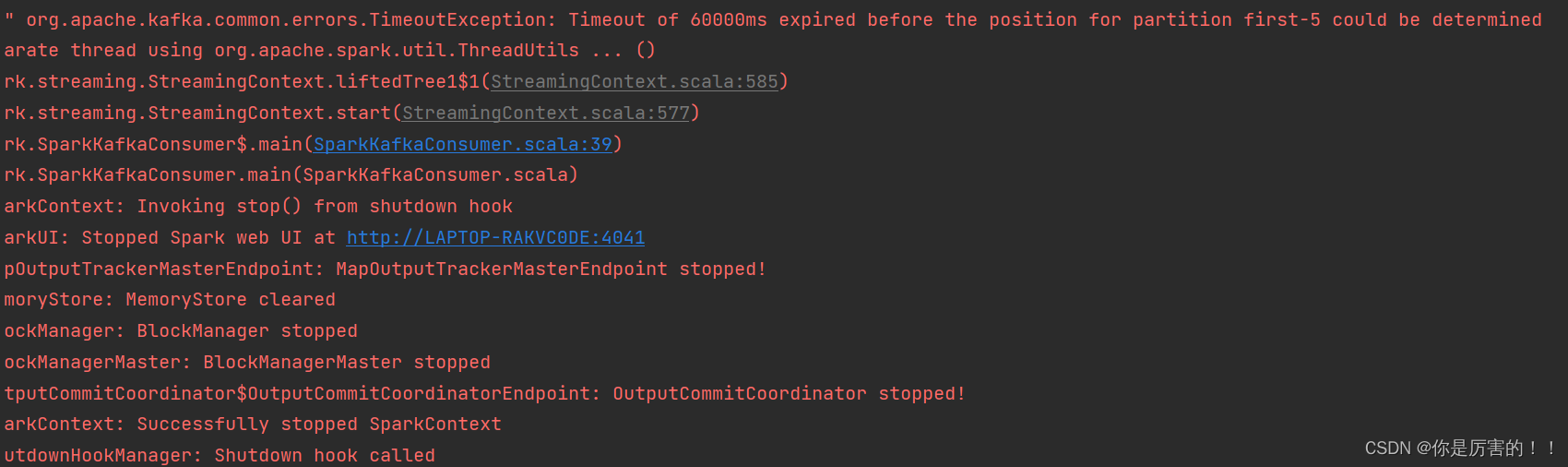
原因:与kafka的分区连接不上,就是分区缺少leader,无法进行通信,故出现这个原因。
所以需要重新订阅topic,使SteamingContext能与topic的每一个分区进行通信,这样才不会报错连接不上。















 3270
3270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









