







🚀 优质资源分享 🚀
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |
| 💛Python量化交易实战💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
1.概述
Kafka系统的灵活多变,让它拥有丰富的拓展性,可以与第三方套件很方便的对接。例如,实时计算引擎Spark。接下来通过一个完整案例,运用Kafka和Spark来合理完成。
2.内容
2.1 初始Spark
在大数据应用场景中,面对实时计算、处理流数据、降低计算耗时等问题时,Apache Spark提供的计算引擎能很好的满足这些需求。Spark是一种基于内存的分布式计算引擎,其核心为弹性分布式数据集(Resilient Distributed Datasets简称,RDD),它支持多种数据来源,拥有容错机制,数据集可以被缓存,并且支持并行操作,能够很好的地用于数据挖掘和机器学习。Spark是专门为海量数据处理而设计的快速且通用的计算引擎,支持多种编程语言(如Java、Scala、Python等),并且拥有更快的计算速度。
提示:
据Spark官方数据统计,通过利用内存进行数据计算,Spark的计算速度比Hadoop中的MapReduce的计算速度快100倍左右。
另外,Spark提供了大量的库,其中包含Spark SQL、Spark Streaming、MLlib、GraphX等。在项目开发的过程当中,可以在同一个应用程序中轻松地组合使用这些类库,如下图所示:
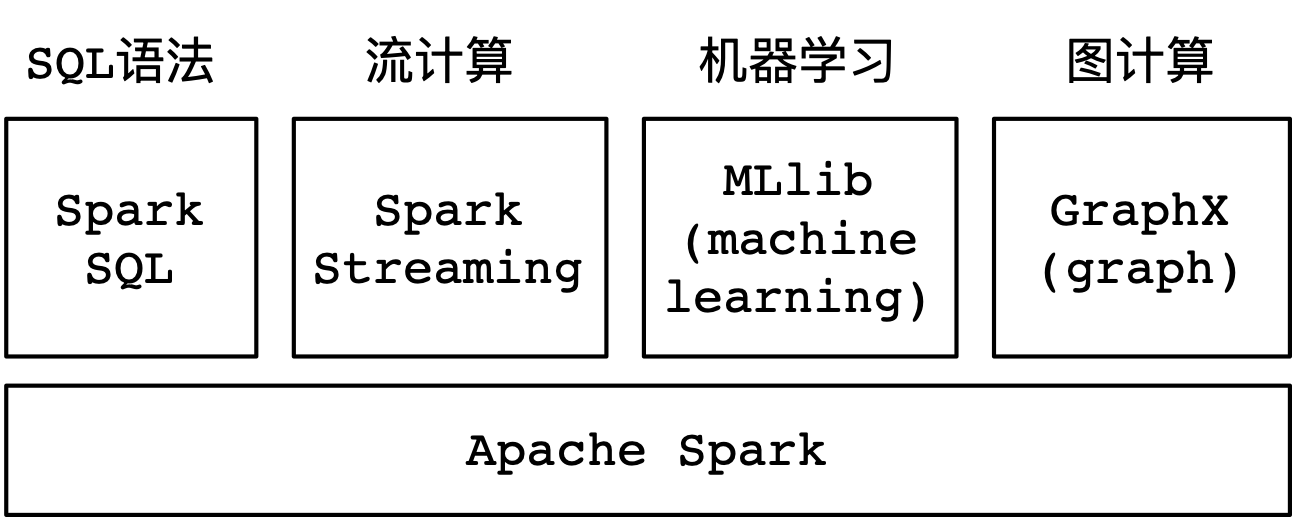
2.2 Spark SQL
Spark SQL是Spark处理结构化数据的一个模块,。与Spark的RDD应用接口不同,Spark SQL提供的接口更加偏向于处理结构化的数据。在使用相同的执行引擎时,不同的应用接口或者编程语言在做计算时都是相互独立的,。这意味着,用户在使用时,可以很方便的地在不同的应用接口或编程语言之间进行切换。Spark SQL很重要的一个优势就是,可以通过SQL语句来实现业务功能,。Spark SQL可以读取不同的存储介质,例如Kafka、Hive、HDFS等。在使用编程语言执行一个Spark SQL语句时,执行后的结果会返回一个数据集,用户可以通过使用命令行、JDBC、ODBC的方式与Spark SQL进行数据交互。
提示:
JDBC是一个面向对象的应用程序接口,通过它可以访问各类关系型数据库。
ODBC是微软公司开放服务结构中有关数据库的一个组成部分,它制定并提供了一套访问数据库的应用接口。
2.3 Spark Streaming
Spark Streaming是Spark核心应用接口的一种扩展,它可以用于进行大规模数据处理、高吞吐量处理、容错处理等场景。同时,Spark Streaming支持从不同的数据源中读取数据,并且能够使用聚合函数、窗口函数等这类复杂算法来处理数据。处理后的数据结果可以保存到本地文件系统(如文本)、分布式文件系统(如HDFS)、关系型数据库(如MySQL)、非关系型数据库(如HBase)等存储介质中。
2.4 MLlib
MLlib是Spark的机器学习(Machine Learning)类库,目的在于简化机器学习的可操作性和易扩展性。MLlib由一些通用的学习算法和工具组成,其内容包含分类、回归、聚类、协同过滤等。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1613
1613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









