






背景及基本信息
背景
毕设需要在单片机上部署轻量化的深度学习模型,在查看了一篇文章采用STM32L4R5部署Unet模型后,尝试自己摸索部署的流程。
在某宝搜寻STM32L4R5关键字后,有如下的商品符合。
不开票价格为150元。

基本信息
在STM32官网确认一下板子的信息,STM32L4R5ZI,Flash为2M,Ram为640k。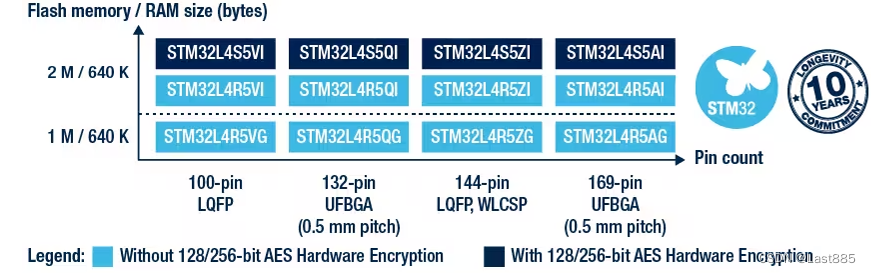
别的信息如下:

环境搭建
看了网上的教程,基本上可以总结为如下两类:
1.STM32CubeMX与KEIL搭配
STM32CubeMX
这个软件是用来生成STM32单片机项目文件的,里面可以选择各种插件包,编辑时钟等操作。
下载地址:
https://www.st.com/en/development-tools/stm32cubemx.html
下载完成后注意下载板子对应的包,或者在选择板子后应该会自动下载。
KEIL
用来打开STM32CubeMX创建的工程文件的IDE,可以编辑编译脚本文件。并编译写入板子中。
根据网上的经验,常用这个产品,别的暂时还没有时间去摸索。
安装一路点即可,没啥需要注意的。
安装后打开界面下载相关的包即可使用,本人用的是STM32CubeIDE进行,感兴趣的可以去搜一下比较老的经验分享,基本都是使用KEIL编译写入的。
2.STM32CubeIDE
这个软件结合了项目的代码生成,烧录一条龙,综合体验来说比较好。推荐使用这个。
下载地址:
https://www.st.com/en/development-tools/stm32cubeide.html
本文使用的版本为1.15.1
下载完成后直接安装,没啥需要特别注意的。不过我为了方便管理和查找,我设置安装目录为D盘,目录结构如下:
![]()
模型介绍
根据网上的教程,用的较多的是这个HAR-CNN-Keras。
https://github.com/Shahnawax/HAR-CNN-Keras
数据结构如下: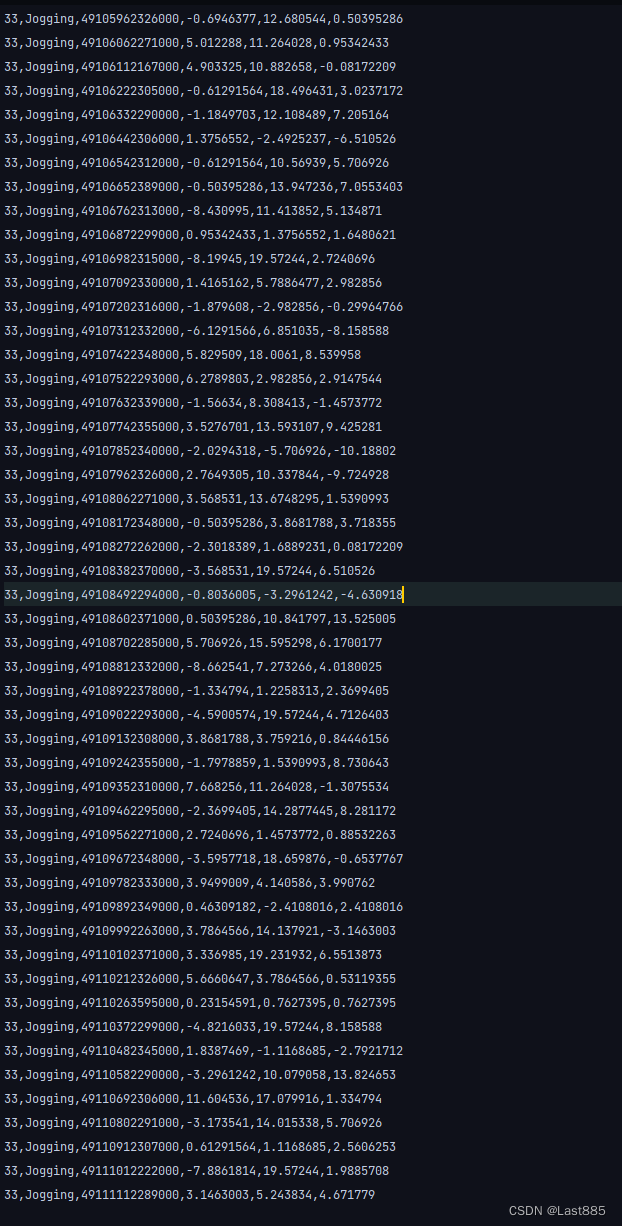
从左到右依次是实验者的编号(33)。活动类型(Jogging,慢跑)。时间戳,单位为ns。4-6列分别为加速器传感器x,y,z轴测量值。
活动类型共6种,Downstairs, Upstairs, Jogging, Sitting, Standing, Walking.
模型输入:6个为一组的数据
模型输出:一个形状为 (num_samples, num_classes) 的数组,其中 num_samples 是输入样本的数量,num_classes 是活动类别的数量。 每一行表示一个样本的预测结果,包含各个类别的概率值。 使用 softmax 激活函数,输出的每个值表示该样本属于某个类别的概率。
创建工程文件
打开STM32CubeIDE软件,点File→New→STM32 Project
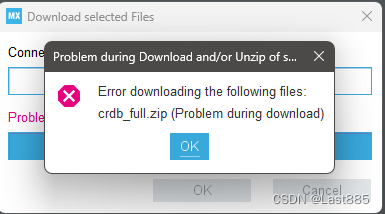
可能遇到这个问题,暂时没找到解决方案,但是不影响后续使用。
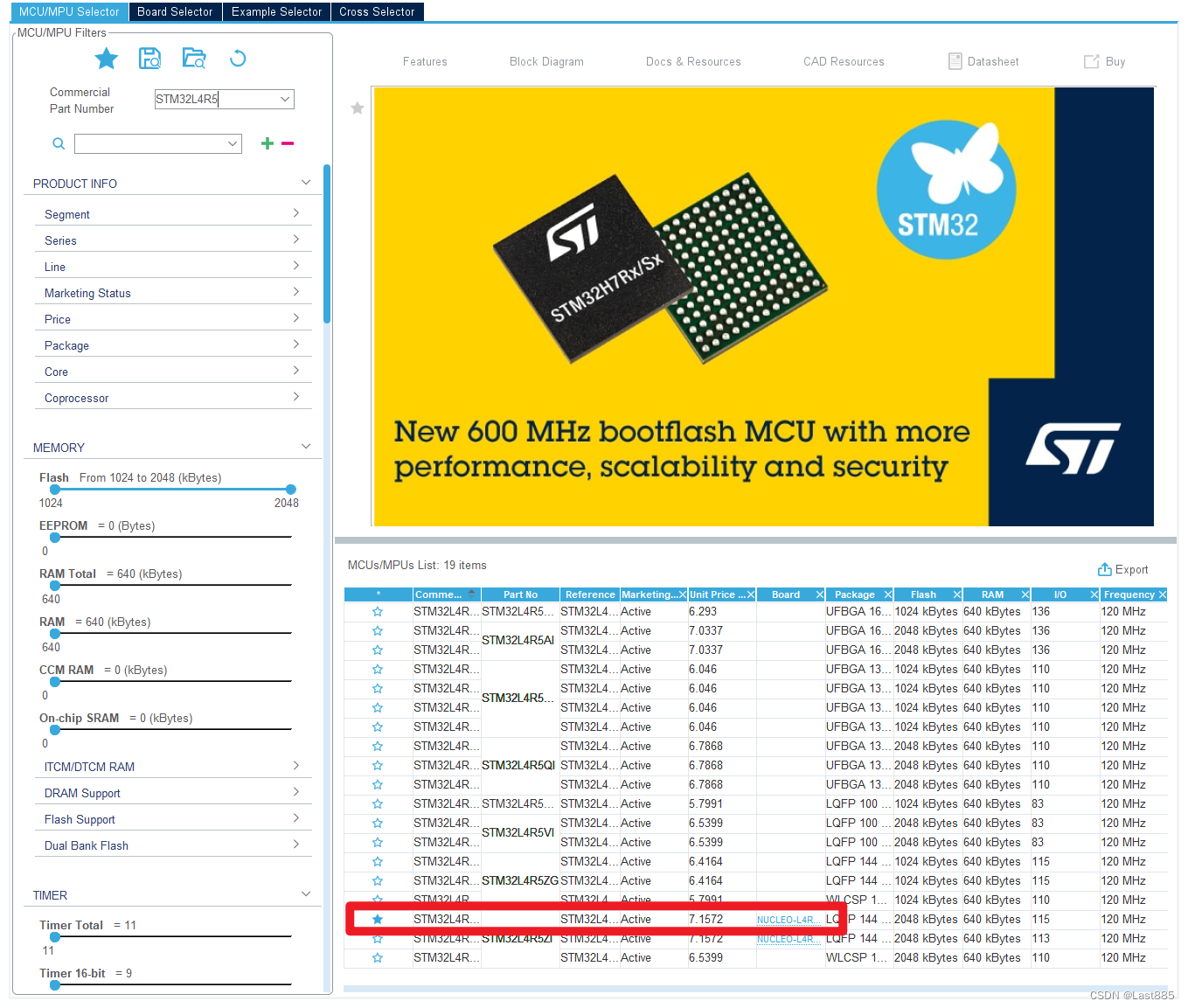
在MCU/MPU Selector中找到开发板
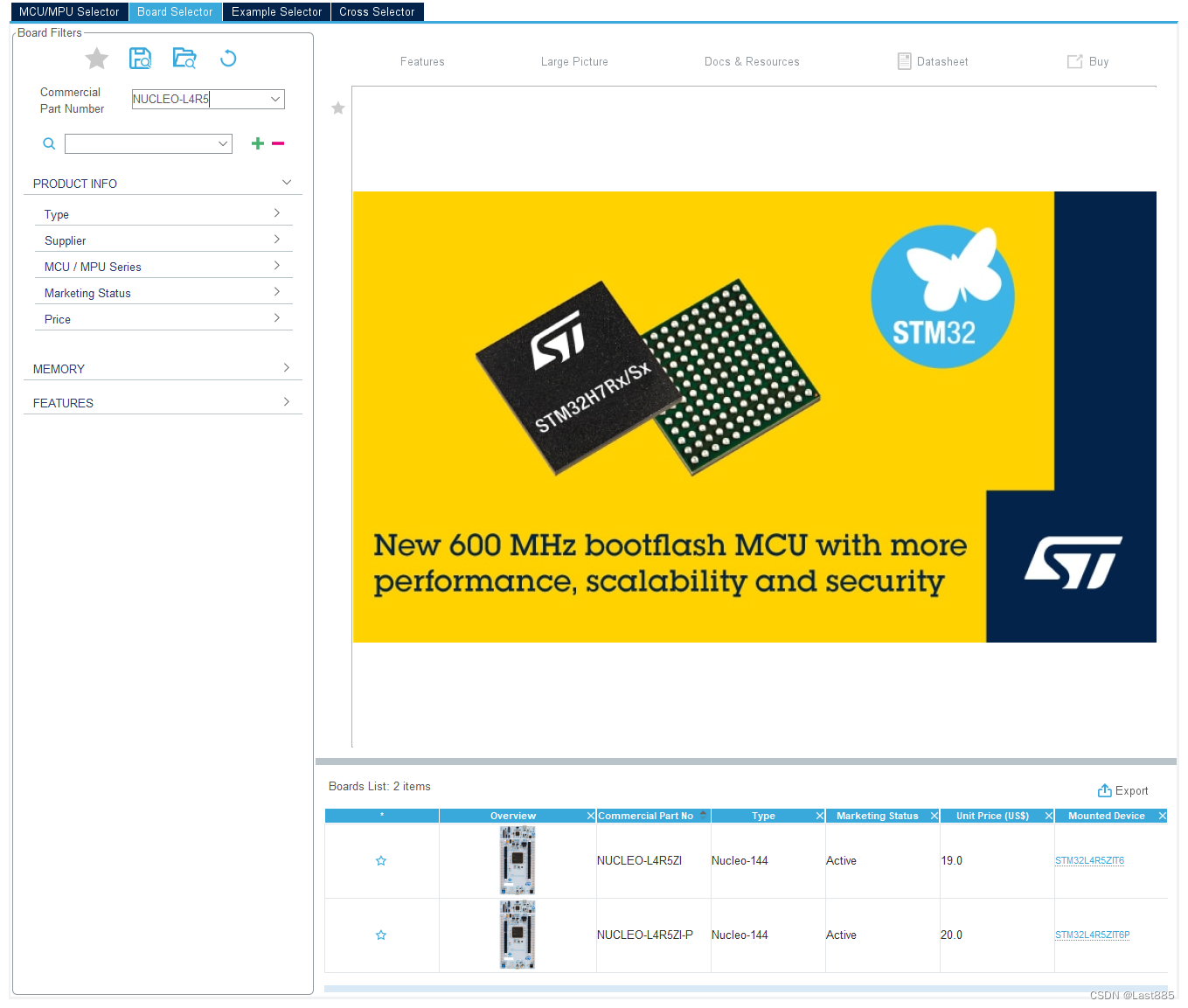
或者在Board Selector中搜索
选中开发板,点Next,项目命名,点Finish。
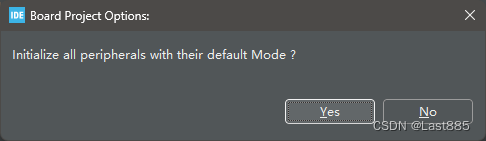
弹出如下界面,点Yes即可。
出现如下项目结构,主要用到的就是这个ioc文件
进入ioc文件后,第一件事是,找到X-Cube-AI。
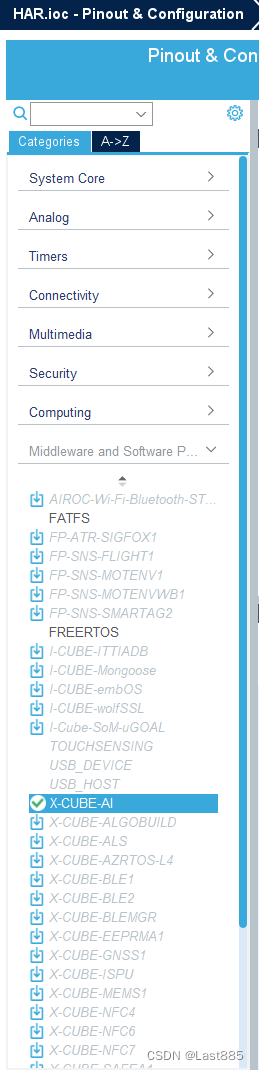
两个版本的X-CUBE-AI
For 9.0.0
第一次接触STM32CubeIDE比较晚,X-CUBE-AI包版本为9.0.0。
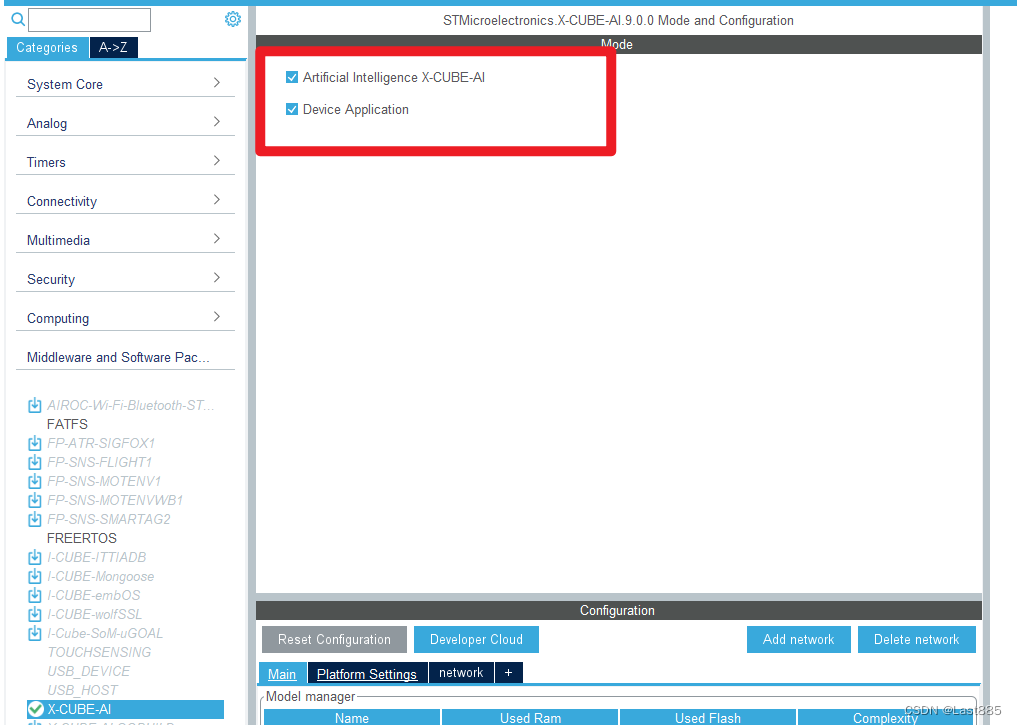
勾选如下:

点OK。
勾选X-CUBE-AI后,这两项默认开启。
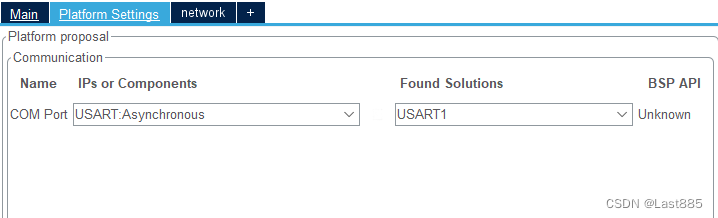
在Platform Settings中设置引脚,
然后要添加网络,导入下载的模型。这里我选择了Compression为High。
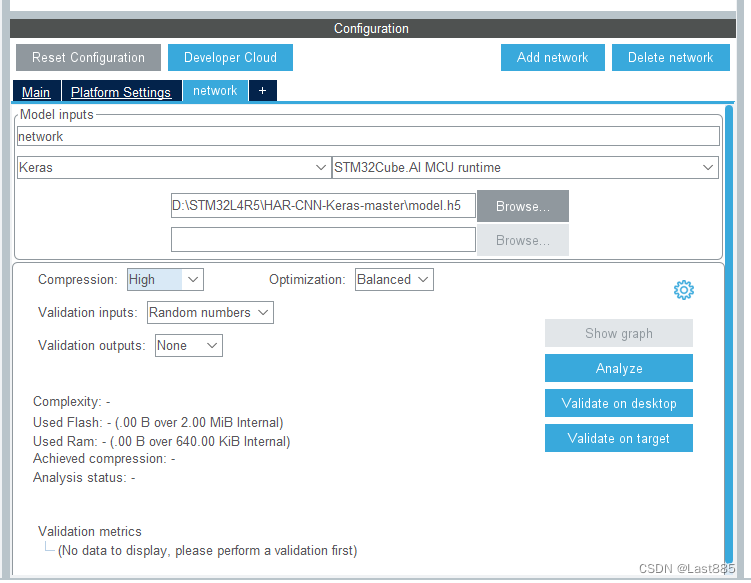
点Analyze分析模型,可能会出现一个错误,
[AI:network] LOAD ERROR: [Errno 13] Permission denied: 'C:\\Users\\\udcba\udcce\\.stm32cubemx\\network_output\\network_analyze_report.txt'这是由于报告文件路径有中文,需要更改路径。
点Show graph上面的齿轮,修改路径,不能有中文。
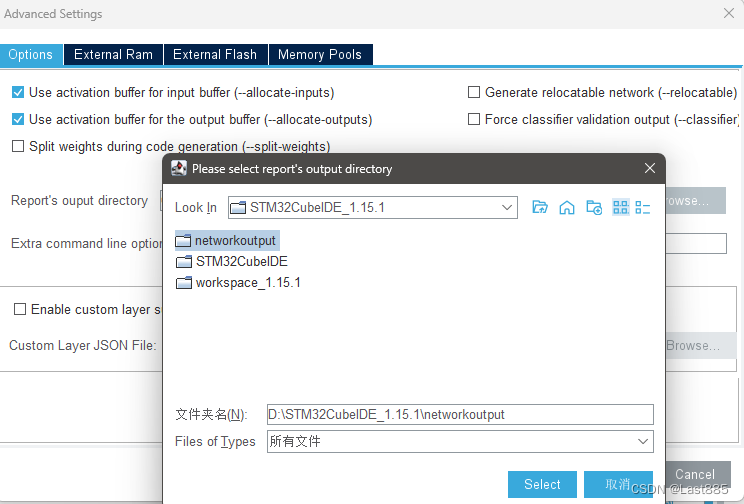
为了方便管理,我放在了和IDE同一个文件夹下。
查看压缩情况,这里有个很重要的问题要说明。
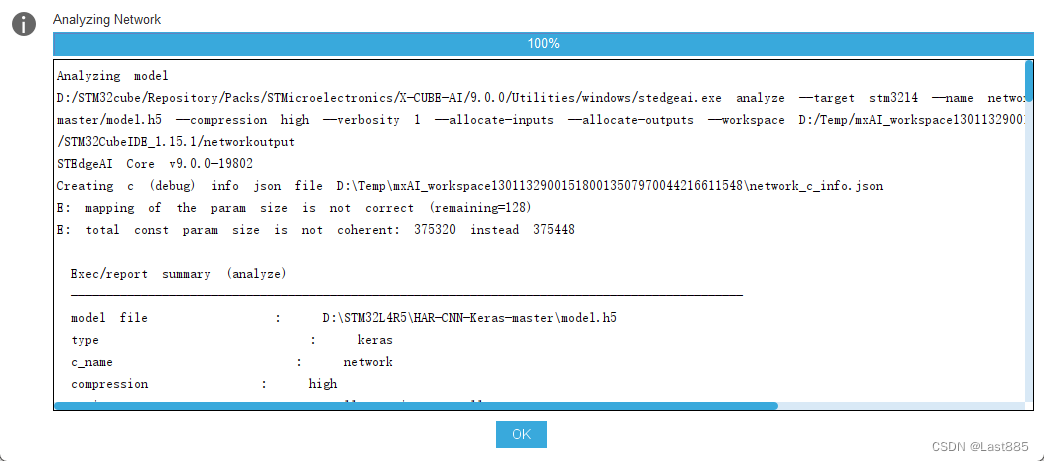
参数不匹配的问题,在分析模型时,注意看有没有,此处选的压缩为High,从压缩结果来看,压缩的效果很好。
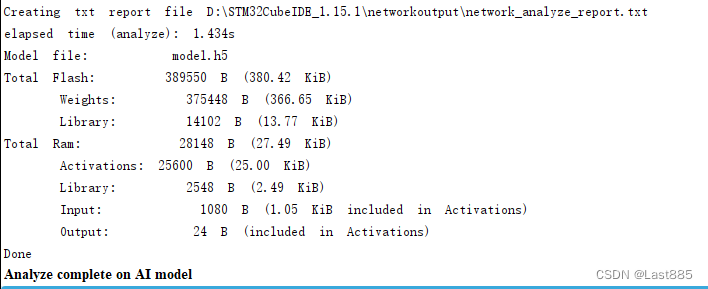
但实际上后续会有问题,参数不匹配的情况下,虽然能进行Validate on desktop,也能正常验证。
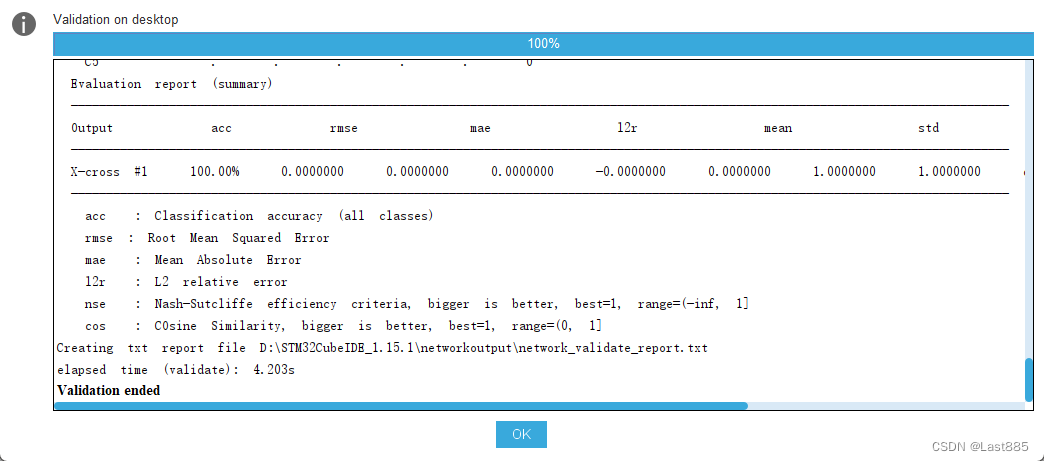
我们先往下走,点时钟配置,点这个转弯的箭头,自动配置时钟。
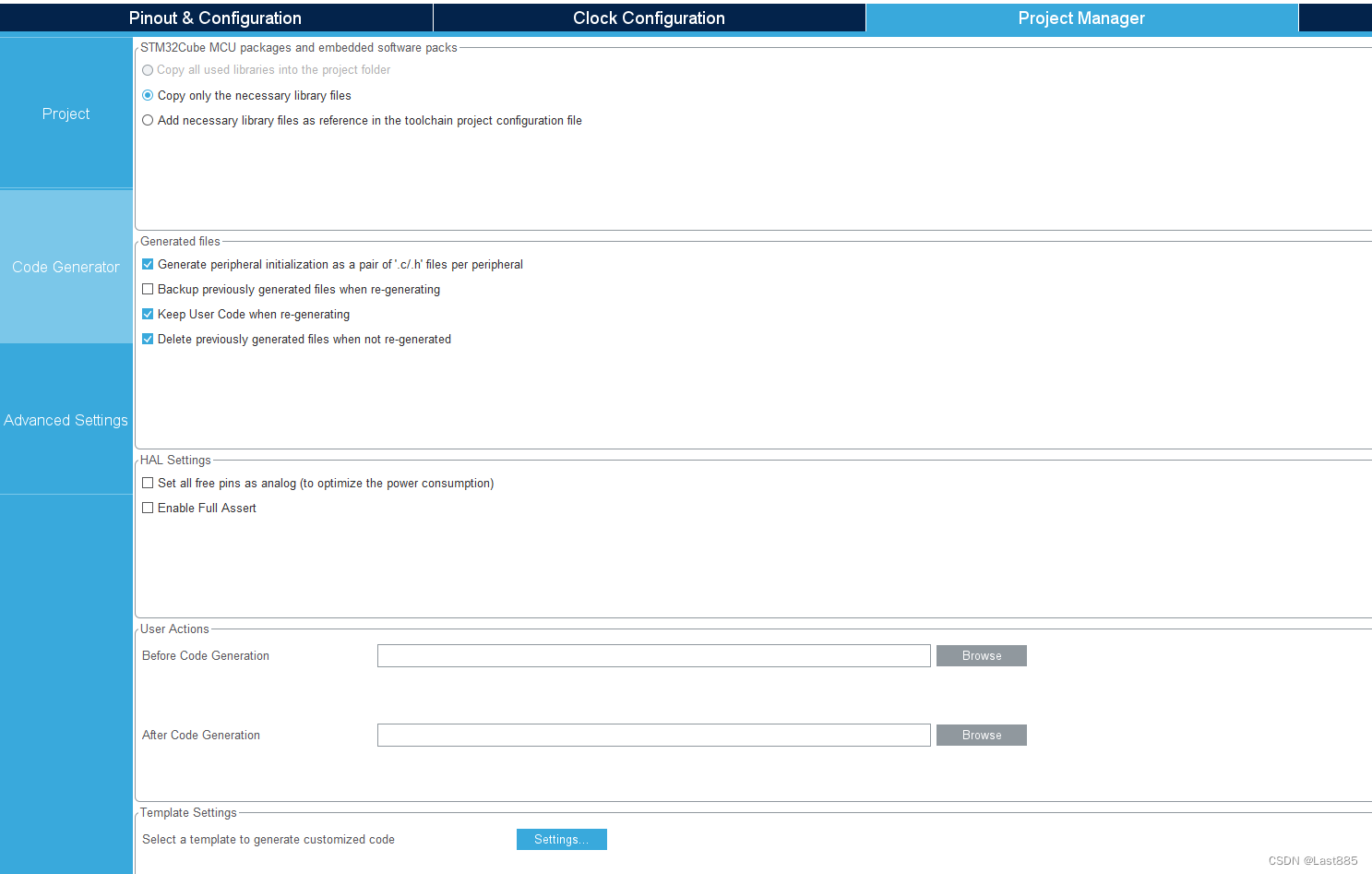
在Project Manager中设置如下
然后在上方快捷栏中找到带把的齿轮,进行代码生成。

右击Project Explorer中项目的最高级文件,Build Project
然后在Console窗口看看有没有errors。
这里可能会有Warnings。可以不管,想管的话参考下面这篇:
https://github.com/candle-usb/candleLight_fw/issues/164
然后进行烧录,点这个类似播放键的。

这里我是用的是NUCLEO-L4R5ZI,使用MicroUSB与板子连接即可烧录。
烧录完成如下:
回到刚才想提到的那个问题,编译烧录到Validate on target时会报错,
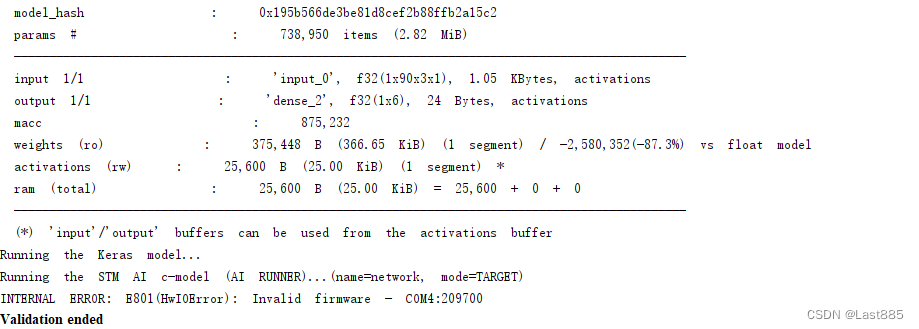
开始我在最后这个Error这里苦寻很久,检查和别人的日志发现了问题,就是这个参数量不匹配,无法在目标上验证。
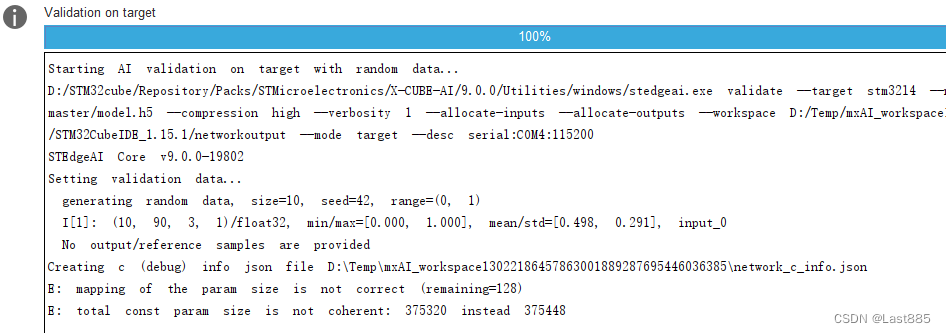
这里我调整了压缩等级,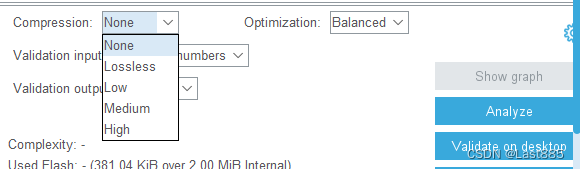
经过试验,Low Medium High三种压缩下,没有超过Complexity的阈值,但是都出现了参数不匹配的情况。
在None和Lossless的情况下,没有报出参数量不匹配。但是闪存爆了。
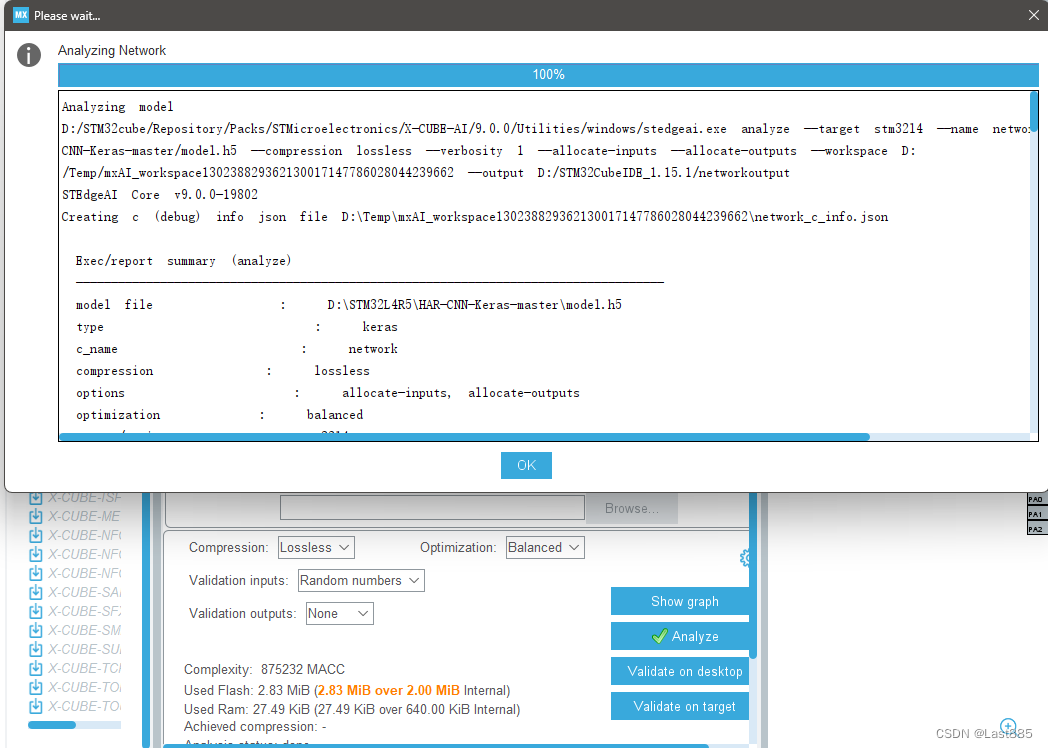
可能是X-CUBE-AI本身的问题,希望有知道如何解决的兄弟分享一下心得。
For 7.0.0
回去看了一下老的教程,普遍在用7.x.x的,不过这个老的X-CUBE-AI支持的Keras版本有限,不能大于2.5.0。
重复上面的步骤,不过选择版本为7.0.0

这里使用后就发现不同,9.0.0的压缩选项是形容词,这里7.0.0给的是具体的倍数,
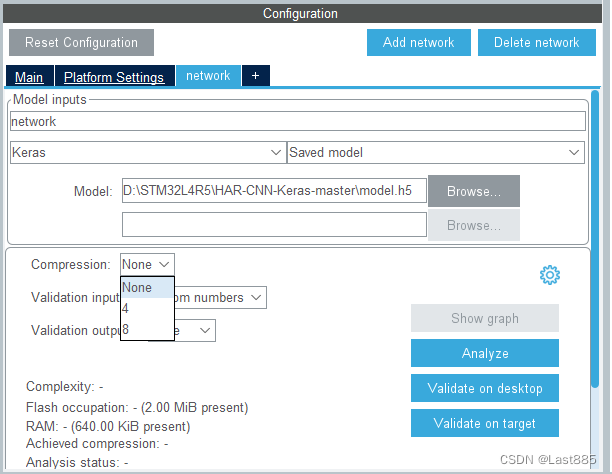
这里我选择8倍,看看效果。

没有提示参数量不匹配,实际压缩倍率为7.88。
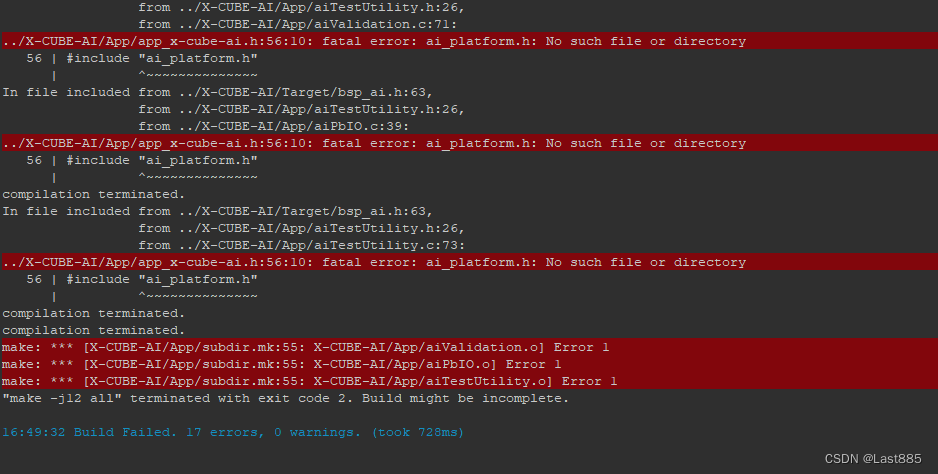
生成代码后编译,17个错误,现在正在解决这个问题。
后话
由于毕设需求,7.0.0版本遇到的问题得暂时放一放,先用9.0.0的往下进行,目的是通过将测试jpg图片传入单片机进行模型预测,将语义分割结果返回到电脑上,看看压缩后的预测效果和在桌面端未压缩的区别,后续做出来后会及时更新分享。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









