







前言:数据库分为库和表,库包括表
1.库操作
1.新增库(create)
2.查看所有的数据库(show)
3.更新数据库(alter)
4.删除数据库(drop)
2.表操作
3.表内操作
1.检索(SELECT )
2.增加(INSERT INTO VALUE)
3.删除(DELETE FROM TABLE)
4.更新(UPDATE TABLE SET )
5.分页(LIMIT A OFFSET B)
TIPS:
前言:数据库分为库和表,库包括表
1.库操作
1.新增库(create)
库选项:用来约束数据库,分为两个选项:字符集设定和校对集设定
字符集设定:charset/character set 具体字符集(数据存储的编码格式);常用的字符集:GBK和utf8
校队集设定:collate 具体校队集(数据比较的规则)
create database 数据库名字 [库选项];
2.查看所有的数据库(show)
show database;
show databases like 'pattern'; --pattern是匹配模式
%:表示匹配多个字符
_:表示匹配单个字符
show create databases; 查看数据库的创建语句 就是返回创建时候的语句
3.更新数据库(alter)
数据库的名字不可修改,数据库的修改仅限选项:字符集和校对集
alter databases name [];
4.删除数据库(drop)
drop database 数据库的名字;
2.表操作
新增数据表(create)
- database 数据库名.表名()
- database A.B(
ID VARCHAR(10),
AGE INTT
)CHARSET UTF8;
查看数据表表(show)
- 查看所有表:show tables;
2.查看部分表(模糊匹配):show tables like ‘pattern’;
3.查看表的创建语句:show create table 表名;
4.查看表结构:查看表中的字段信息
desc columns from 表名;
describe columns from 表名;
show columns from 表名;
desc/describe/show columns from 表名;
修改数据表
表本身
修改表名(rename)
-
- rename table 老表名 to 新表名
- 2.修改表选项:字符集,校队集和存储引擎(alter)
-
- table 表名 表选项 [=] 值; --其中[]表示其中的内容可以省略。
3.删除表(drop)
删除数据表
drop table 表名1,表名2....; --可以一次性删除多张表
2.修改字段
新增
- table 表名 add [column] 字段名 数据类型 [列属性][位置];
修改
alter table 表名 modify 字段名 数据类型 [属性][位置];
重名
alter table 表名 change 旧字段 新字段名 数据类型 [属性][位置];
删除
alter table 表名 drop 字段名;
3.表内操作
1.检索(SELECT )
SELECT *
FROM A
JOIN B ON A.ID=B.ID
WHERE A.ID=1883
GROUP BY A.NAME
HAVING NAME='ljh'
ORDER BY A.NUMBER
2.增加(INSERT INTO VALUE)
INSERT INTO A() VALUE ()
INSERT INTO A() SELECT A
3.删除(DELETE FROM TABLE)
DELETE FROM A WHERE
4.更新(UPDATE TABLE SET )
UPDATE A() SET WHERE
5.分页(LIMIT A OFFSET B)
SELECT *
FROM A
LIMIT 3 OFFSET 0;
/*将所有数据 分成 每页三份 并且显示 第0页*/
TIPS:
多表查询和连接查询有什么区别?
- 多表相当于几张表一起查询相同符合条件的结果,最后结果集进行交集。但是会引起笛卡尔积的问题。而连接查询是先将表连接成一张表在进行查询。
GROUP BY 和 HAVING 的区别是?
-
- GROUP BY 子句用于将筛选出来的数据按照一个或多个列的值进行分组,生成多个分组,每个分组包含相同值的行。 这允许您对数据进行分类或分组,以便后续的汇总操作。
- HAVING 子句用于对 GROUP BY 分组后的数据进行条件筛选。具体地说,它允许您对每个分组应用条件,只保留那些满足条件的分组。这就是对分组级别的筛选,通常用于对聚合函数结果的分组进行进一步的筛选或过滤。
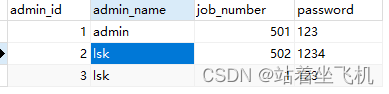

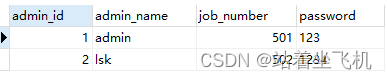
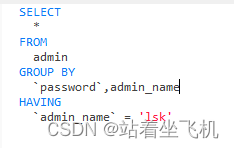

所以, GROUP BY 用于数据的初步分组,而 HAVING 用于对这些分组进行进一步的筛选和过滤,通常涉及到聚合函数的结果。这使得 SQL 查询非常灵活,能够进行复杂的数据分析和统计操作。
3.JOIN系列有哪些?
INNER JOIN 或 JOIN:内连接,合并匹配的行。
LEFT JOIN 或 LEFT OUTER JOIN:左连接,合并左表的所有行和匹配的右表行。
RIGHT JOIN 或 RIGHT OUTER JOIN:右连接,合并右表的所有行和匹配的左表行。
FULL JOIN 或 FULL OUTER JOIN:完整外连接,合并左表和右表的所有行,包括未匹配的行。
CROSS JOIN:笛卡尔积操作,返回两个表的所有可能组合,不需要连接条件。
#多表连接
SELECT orders.order_id, customers.customer_name, products.product_name
FROM orders
JOIN customers ON orders.customer_id = customers.customer_id
JOIN order_details ON orders.order_id = order_details.order_id
JOIN products ON order_details.product_id = products.product_id;
上述除了cross join都需要连接条件像是full join这种包括未匹配的行的就会使用null来进行填充
4.join中如何区分那个是左表那个是右表?
from下面跟left那么from就是左表跟right就是右表(这是博主自己记录的野方法hhh)
5.表连接还有什么方法?
常见的 SQL 查询中的条件连接
WHERE orders.customer_id = customers.customer_id)
UNION 操作 : UNION 允许合并两个具有相同列的查询结果。虽然它通常用于合并行,但也可以用于合并表。
SELECT customer_id, customer_name
FROM customers
UNION
SELECT supplier_id, supplier_name
FROM suppliers;
WITH 子句(Common Table Expressions):使用 WITH 子句可以为一个查询定义一个临时表,然后在主查询中引用它。这对于在多个地方使用相同的子查询非常有用。
WITH CustomerOrders AS (
SELECT customer_id, order_date
FROM orders
)
SELECT customer_name, order_date
FROM customers
JOIN CustomerOrders ON customers.customer_id = CustomerOrders.customer_id;















 5779
5779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









